Oracle-SQL
Oracle-SQL
-
- SQL常识
-
-
- PLSQL安装
- SQL分类
- SQL的编写顺序
- SQL的执行顺序
-
- 学习Oracle的注意事项
- Oracle数据库的体系结构
- Oracle内置表
-
-
- 虚表
-
- 基本查询
-
-
- 按列查询
- 给查询的列起别名
- 消除重复的数
- sql的四则运算
- 字符串连接查询
-
- 条件查询
- 练一练(emp):
- 排序
- 事务
-
-
- 事务的特性
- 事务的并发操作
-
- 条件表达式
- 分组
-
-
- where 和 having 的区别
-
- 多表内连接查询
- 左右外连接查询
- 子查询
-
-
- 单行子查询
- 多行子查询
- 关联子查询和非关联子查询
-
- 值变字段
-
-
- exists的用法
-
- 视图
-
-
- 视图的作用
-
- 同义词
- rownum
-
-
- 分页
-
- rowid
- 集合运算
-
-
- 并集运算
- 差集运算
- 集合运算中的注意事项
-
- 表空间
- 创建用户
- 创建表
- 复制表
- 修改表
- 删除表格
- 约束
-
-
- 外键约束
-
-
- 删除表
-
-
- 插入数据
- 更新数据
- 删除数据
-
-
- delete与truncate的区别
-
- 序列
- 个人项目经验总结
- 递归查询
- 查看表格之前的版本以及Drop表的恢复
- oracle数据库在Linux系统下启动关闭
- DBLINK(不推荐使用)
- Oracle与操作系统时间不一致问题
- Oracle之有修改无新增
- 导出dmp
- Oracle中的特殊表
-
-
- 用户查询
- 表空间文件查询
- 查询会话
- 查询被锁住的对象
- 查询表
- 查询视图
- 系统参数
-
SQL常识
PLSQL安装
PLSQL安装教程
SQL分类
-
DDL数据定义语言,修改表结构alter、create、drop -
DML数据操作语言,操作表中数据--有事务,可恢复 insert、update、delete --没有事务,不可恢复 truncate -
DCL权限控制语言grant -
DQL数据查询语言select
SQL的编写顺序
SQL的执行顺序
学习Oracle的注意事项
从 mysql 转移到 Oracle 需要注意以下几点:
- 创建表的时候需要注意表名和列名都要大写,因为
Oracle在执行sql后会自动将sql转为大写,如果你定义的表里的字段或表名称为小写,sql将找不到这个表或列(表中的数据不在此列,可以小写) - 注意
Oracle的保留字,Oracle提供了大量的保留字,包括user,uid等,也就是说在Oracle中我们不能创建user表,也不能创建uid列,否则你会惊讶的发现你的sql语句不报错,但却无法产生任何执行结果!
Oracle保留字点击查看
Oracle数据库的体系结构
- 数据库:
database - 实例:
默认:orcl - 数据文件:
dbf - 表空间
- 用户
关系: 一个数据库通常情况下有一个实例(可以有多个),一个实例可以创建多个表空间,每一个表空间对应一个用户,表格中数据量的单位是数据文件
Oracle和Mysql的区别: oracle是多用户,Mysql是单用户,Mysql创建一个数据库然后会创建相应的表格,Oracle创建一个用户,相对应会创建一个表空间,由用户去创建表
Oracle内置表
虚表
Oracle 提供了一张虚表 dual,主要是用来补齐语法结构的
demo
执行下面的sql会报错 FROM keyword not found where expected(在Mysql下可以执行成功!)
select 1+1;
如果添加虚表就不会报错
select 1+1 from dual;
基本查询
按列查询
#查询所有
select * from 表名
#查询某一列
select 列名 from 表名
#查询多列(列名可以重复)
select 列名1,列名2 from 表名
给查询的列起别名
注意:别名中不能有特殊字符或者关键字,列如空格、%,如果有就给别名加""双引号,一般情况下,除了别名用 "",其他都是用 ''
select 列名1 as 别名1,列名2 as 别名2 from 表名
select 列名1 别名1,列名2 别名2 from 表名
select name 姓名,age 年龄,hobby "爱 好" from T_TABLE_NAME;
消除重复的数
#单列去除重复
select distinct 列名 from 表名
#多列去除重复,必须列名1和2都一样才能去除
select distinct 列名1,列名2 from 表名
sql的四则运算
注意:null值,代表不确定的、不可预知的内容,不可以做四则运算!
#nvl函数作用是当这个列的值为null,则让其等于0(参数2)
select nvl(列名,0)+2 from 表名
select nvl(列名,0)-2 from 表名
select nvl(列名,0)*2 from 表名
select nvl(列名,0)/2 from 表名
字符串连接查询
在mysql中,使用逗号连接字符串:
select concat(name,'的名字') from 表名
查询结果:
小明的名字
有一定的局限性,concat只能传入两个参数,如果想要多个参数拼接,则需要嵌套,很麻烦
在Oracle中,可以使用||进行字符串拼接,可以拼接任意个字符串:
select '编号是:'|| empno || '的雇员姓名是:' || ename from 表名
条件查询
比较运算符:
| 操作符 | 含义 |
|---|---|
| = | 等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| <> | 不等于(!=) |
| between … and … | 在两个值之间(包含边界) |
| IN(set) | 等于列表中的一个值 |
| like | 模糊查询 _ 匹配单个字符, %匹配多个字符 |
| is NULL | 空值 |
| 逻辑运算符: | |
| 操作符 | 含义 |
| – | – |
| and | 逻辑并 |
| or | 逻辑或 |
| not | 逻辑否 |
练一练(emp):
-
查询每月能获得奖金
comm的雇员
分析:0表示这个人有拿到奖金的机会,null表示连能拿奖金的机会也没有,所以用is not nullselect * from emp where comm is not null -
查询工资
sal大于1500且有奖金领取的员工select * from emp where comm is not null and sal > 1500 -
查询工资大于
1500或者有奖金的雇员select * from emp where comm is not null or sal > 1500 -
查询工资不大于
1500和没有奖金的人select * from emp where comm is null and sal <= 1500 -
查询基本工资大于
1500但小于3000的全部雇员select * from emp where sal between 1500 and 3000 select * from emp where sal > 1500 and sal < 3000 -
查询
2001-1-1到2001-10-1入职的雇员(入职时间hiredate)select * from emp where hiredate between 1-1月-2001 and 1-10月-2001 -
查询雇员名字(
ename)叫smith的员工(注意:oracle中查询条件的值区分大小写)select * from emp where ename = 'smith' -
查询雇员编号
empno是7369,7499,7521的雇员具体信息select * from emp where empno = 7369 or empno = 7499 or empno = 7521 select * from emp where empno in (7369,7499,7521) -
查询雇员名字第二个字是
M的员工信息select * from emp where ename like '_M%' -
查询雇员名字中带有
M的员工信息select * from emp where ename like '%M%' -
查询编号不是
7369的员工信息select * from emp where empno != 7369 select * from emp where empno <> 7369 -
查询员工姓名中,包含
%的员工信息
escape 告诉Oracle这个 / 是一个转义字符,注意加 \ 可能会报错,我就遇到过,我也不知道为什么,不过网上大多的帖子都表示这个 \ 可以,有知道原因欢迎下方评论留言!select * from emp where ename like '%/%%' escape '/';
排序
注意: 排序的列的类型最好是 number 类型,否则很有可能会出现如下错误(按照第一个数字的大小排序,第一个相同再按照第二个,以此类推,这是 varchar2 的排序方式):
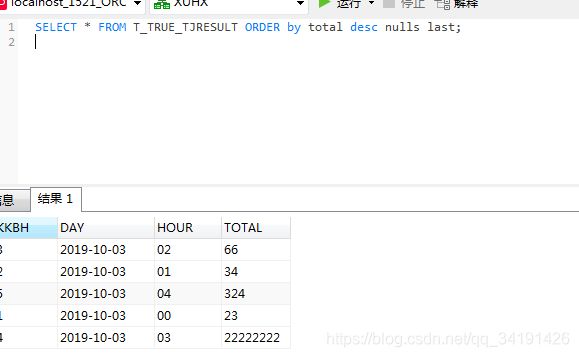
解决办法:
-
创建表的时候确定这个列的数据类型就是
number类型就设置为number类型 -
已经创建了可以使用
TO_NUMBER函数强转为number类型再排序SELECT * FROM T_TABLE_NAME ORDER by TO_NUMBER(total) desc nulls last;
升序查询:
select * from 表名 order by 参照属性;
select * from 表名 order by 参照属性 asc;
降序查询:
注意: 降序指大的放最前面,小的放最后面,但是Oracle默认null放在最前面,而我们所理解的null是最小的,比0还小,应该放最后面,所以应该设置一下
select * from 表名 order by 参照属性 desc nulls last;
多排序字段之间使用,隔开
select * from 表名 order by 参照属性1 desc , 参照属性2 asc
事务
事务是指是程序中一系列严密的逻辑操作,而且所有操作必须全部成功完成,否则在每个操作中所作的所有更改都会被撤消。
事务的特性
- 原子性:操作这些指令时,要么全部执行成功,要么全部不执行。只要其中一个指令执行失败,所有的指令都执行失败,数据进行回滚,回到执行指令前的数据状态。
- 一致性:事务的执行使数据从一个状态转换为另一个状态,但是对于整个数据的完整性保持稳定。
- 隔离性:隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
- 持久性:当事务正确完成后,它对于数据的改变是永久性的。
事务的并发操作
事务的并发操作可能会导致以下几个现象,这些现象都是在同一个事务里面操作才会出现这种现象:
- 脏读:读未提交,一个事务读取了另外一个事务改写还没有提交的数据。
- 不可重复读:一个事务进行相同条件查询连续的两次或者两次以上,每次结果都不同。
- 幻读:和不可重复读差不多
解决这些现象的办法:设置事务的隔离级别
read uncommitted,读未提交,设置后可以读到人家未提交的数据read committed,读已提交,设置后就可以避免脏读,读不到人家未提交的数据了repeatable read,可以重复读,这个设置后可以避免重复读serializable,串行化(悲观锁),这个设置后就不存在事务的并发操作了,也就不会有上面的现象了
条件表达式
格式:
--通用写法,mysql和Oracle都可以使用
select
case 字段名
when 值1 then 值
when 值2 then 值
else
默认值
end
from 表名;
--Oracle专用写法
select decode(字段名,值1,值,值2,值,默认值)from 表名;
分组
select 分组的条件,分组之后的操作 from 表名 group by 参照属性 having 条件
demo:
分组统计所有部门的平均工资,并找出平均工资大于1500的部门(部门编号:deptno,工资:sal)
select deptno,avg(sal) from emp group by deptno having avg(sal) > 1500;
where 和 having 的区别
where后面不能接聚合函数,可以接单行函数having是在group by之后执行,可以接聚合函数
多表内连接查询
-
笛卡尔积
例如:查询员工表emp和部门表deptselect * from emp,deptemp:14条数据
dept:4条数据
查询结果记录:14 × 4 = 56 -
连接查询
隐式内连接:--格式: select * from 表1,表2 where 条件 --demo select * from emp,dept where emp.deptno = dept.deptno select * from emp e,dept d where e.deptno = d.deptno显示内连接:
--格式: select * from 表1 (inner) join 表2 on 条件 --demo select * from
左右外连接查询
--左外连接:左表中所有记录都查询出来,如果右表没有记录则显示为空
select * from 左表名1 left (outer) join 右表名2 where 条件
select * from 左表1 左,右表2 右 where 左.字段 = 右.字段(+);
--右外连接:右表中所有记录都查询出来,如果左表没有记录则显示为空
select * from 左表名1 right (outer) join 右表名2 where 条件
select * from 左表1 左,右表2 右 where 左.字段(+) = 右.字段;
子查询
- 子查询在主查询之前完成
- 子查询的结果会被主查询使用
单行子查询
单行子查询只返回一条记录
例如:
-
查询出比雇员
7654的工资sal高,同时从事和7788一样的工作job的员工select * from emp where emp.sal > (select sal from emp where empno = 7654) and emp.job = (select job from emp where empno = 7788) -
查询每个部门的最低工资和最低工资的雇员和部门名称
select d.name,e.minsal,e.ename from dept d,(select min(sal) minsal,ename,deptno from emp group by deptno)e where d.deptno = e.deptno
多行子查询
多行子查询返回多条记录
注意: 多行子查询的 in 条件里面不能有空值,所以我们需要对空值进行过滤。
例如:
查询不是老胡的员工
select * from emp where empno not in(select empno from emp where eboss = '老胡' and empno is not null)
关联子查询和非关联子查询
- 非关联子查询指子查询可以脱离外部查询独立运行
例如上面查询不是老胡的员工 - 关联子查询指子查询不可以脱离外部查询独立运行
关联子查询的基本逻辑
对于外部返回的每一行数据,内部查询都要执行一次,意思就是说外部查询的每一行数据都会传递一个值给子查询,然后子查询为每一行数据执行一次并返回它的记录。
demo
查询员工工资大于其部门平均工资的员工信息
关联查询的详细介绍select * from emp e where sal > (select avg(sal) from emp e2 group by deptno having e.deptno = e2.deptno);
值变字段
demo:
表格如下:
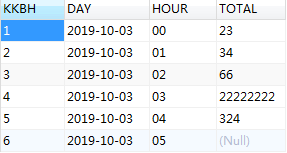
如何将上述表格处理变成如下图的结果:
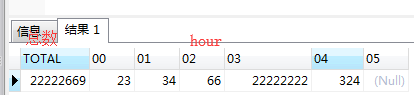
思路分析:
-
查询
hour,和totalSELECT HOUR,TOTAL FROM T_TABLE_NAME; -
给
hour的值用total替换,并起别名为hour,使用sum聚合函数去除空值SELECT sum(CASE t.HOUR WHEN '00' THEN t.total END) "00", sum(CASE t.HOUR WHEN '01' THEN t.total END) "01", sum(CASE t.HOUR WHEN '02' THEN t.total END) "02", sum(CASE t.HOUR WHEN '03' THEN t.total END) "03", sum(CASE t.HOUR WHEN '04' THEN t.total END) "04", sum(CASE t.HOUR WHEN '05' THEN t.total END) "05" FROM (SELECT HOUR,TOTAL FROM T_TABLE_NAME) t; -
拼接总数
SELECT sum(t.TOTAL) total,sum(CASE t.HOUR WHEN '00' THEN t.total END) "00", sum(CASE t.HOUR WHEN '01' THEN t.total END) "01", sum(CASE t.HOUR WHEN '02' THEN t.total END) "02", sum(CASE t.HOUR WHEN '03' THEN t.total END) "03", sum(CASE t.HOUR WHEN '04' THEN t.total END) "04", sum(CASE t.HOUR WHEN '05' THEN t.total END) "05" FROM (SELECT HOUR,TOTAL FROM T_TABLE_NAME) t;
exists的用法
exists是用来判断子查询的结果是否为空,空则返回false,否则true
例如:
查询有员工的部门:
select * from dept where exists(select * from emp where emp.deptno = dept.deptno)
视图
视图是对查询结果的封装,视图里面所有的数据都是来自原表,视图本身不存储数据
视图的作用
- 能够封装复杂的查询结果
- 能屏蔽表中的细节
--格式
create or replace view 视图名称 as 查询语句 with read only;
-demo
create or replace view view_test1 as
SELECT sum(t.TOTAL) total,
sum(CASE t.HOUR WHEN '00' THEN t.total END) "00",
sum(CASE t.HOUR WHEN '01' THEN t.total END) "01",
sum(CASE t.HOUR WHEN '02' THEN t.total END) "02",
sum(CASE t.HOUR WHEN '03' THEN t.total END) "03",
sum(CASE t.HOUR WHEN '04' THEN t.total END) "04",
sum(CASE t.HOUR WHEN '05' THEN t.total END) "05"
FROM (SELECT HOUR,TOTAL FROM user_name.T_TABLE_NAME) t with read only;
select * from view_test1;
同义词
相当于给一个标志符起别名
--格式
create synonym 同义词 for 标志符
--demo1:给表起别名
create synonym aaa for user_name.T_TABLE_NAME;
select * from aaa;
--demo2:给视图起别名
create or replace view view_test1 as select * from user_name.T_TABLE_NAME;
create synonym bbb for view_test1;
select * from bbb;
rownum
demo:
找到员工表中工资最高的前三名
select rownum,t.* from (select * from emp where order by sal desc) t where rownum <= 3;
rownum:伪列,为Oracle自动生成的列,用来表示行号,默认起始值为1,rownum作为条件判断时不要有 >= 的判断,否则查到的结果为空
分页
SELECT t.* FROM (SELECT ROWNUM as rownb,s.* FROM T_TRUE_TJRESULT s) t WHERE t.rownb BETWEEN 1 AND 3;
rowid
rowid:伪列,为Oracle自动生成的列,用来存放真实的物理地址
应用场景: 去除表中重复的记录
思路:求出表中名字相同的最小的rowid,以此rowid为条件查出大于这个rowid的记录,并删除。
DELETE FROM T_TABLE_NAME n1 WHERE ROWID > (SELECT MIN(ROWID) FROM T_TABLE_NAME n2 WHERE n1.KKMC = n2.KKMC);
集合运算
并集运算
-
去除重复的并集运算
SELECT * FROM T_TABLE_NAME WHERE TOTAL < 50 UNION SELECT * FROM T_TABLE_NAME WHERE TOTAL > 30 and TOTAL <100; -
不去除重复的并集运算
SELECT * FROM T_TABLE_NAME WHERE TOTAL < 50 UNION ALL SELECT * FROM T_TABLE_NAME WHERE TOTAL > 30 and TOTAL <100;
差集运算
--格式:
查询语句A minus 查询语句B
结果为A - A与B相同的部分
SELECT * FROM T_TABLE_NAME WHERE TOTAL < 50
MINUS
SELECT * FROM T_TABLE_NAME WHERE TOTAL > 30 and TOTAL <100;
集合运算中的注意事项
- 两个语句的列的类型要对应一致,最好含义一致
- 两个语句查询的列的数量要一致,如果不一致用
null值填充
表空间
通常我们新建一个项目的时候就会创建一个表空间,在表空间中创建用户,由用户来创建表
创建表空间:
create tablespace 表空间的名称 datafile '指定表空间存放路径\表空间的名称.dbf' size 指定表空间初始大小(单位m) autoextend on next 指定表空间存储满后每次自动增长得空间大小(单位m)
--demo
CREATE tablespace zhangsan datafile 'd:\zhangsan.dbf' SIZE 100m autoextend on next 10m;
查看表空间文件
select * from DBA_DATA_FILES where tablespace_name = '表空间的名称';
--demo
select * from DBA_DATA_FILES where tablespace_name = 'zhangsan';
添加表空间文件
alter tablespace 表空间名称 add datafile '表空间文件' size 50m autoextend on next 10m maxsize unlimited;
--demo
alter tablesapce zhangsan add datafile 'd:\zhangsan0001.dbf' size 50m autoextend on next 10m maxsize unlimited;
赋予表空间给对应的用户
alter user 用户名 quota unlimited on 表空间名;
删除表空间:
先执行下面的语句:
drop tablespace 表空间的名称;
--demo
drop tablespace zhangsan;
然后去磁盘对应路径删除表空间的 .dbf 文件
查询表空间使用率:
select a.tablespace_name,
round(maxbytes / 1024 / 1024 / 1024, 2) as "表空间文件大小上限(GB)",
round(total / 1024 / 1024 / 1024, 2) as "表空间文件大小(GB)",
round((total - free) / 1024 / 1024 / 1024, 2) as "表空间数据大小(GB)",
round((total - free) / maxbytes, 4) * 100 as "表空间使用率(%)"
from (select t1.tablespace_name, sum(t1.bytes) as free from dba_free_space t1 group by t1.tablespace_name) a,
(select t2.tablespace_name, sum(t2.bytes) as total, sum(t2.maxbytes) maxbytes from dba_data_files t2 group by t2.tablespace_name) b
where a.tablespace_name = b.tablespace_name order by "表空间使用率(%)" desc
查询表空间下各个元素(表、分区、索引…)的占用大小情况:
select a.segment_name,
round(sum(a.bytes) / 1024 / 1024 / 1024, 2) as "已使用(GB)",
a.segment_type,
b.table_name,
b.column_name,
c.table_name,
c.index_name
from dba_segments a
left join dba_lobs b on a.segment_name = b.SEGMENT_NAME
left join dba_indexes c on a.segment_name = c.index_name
--指定要查询的表空间名称
where a.tablespace_name = 'WEBSERVER' group by
a.segment_name,
a.segment_type,
b.table_name,
b.column_name,
c.table_name,
c.index_name
order by "已使用(GB)" desc
创建用户
create user 用户名 identified by 用户密码 default tablespace 指定该用户使用的表空间
--demo
CREATE USER zhangsan IDENTIFIED BY 123 DEFAULT tablespace zhangsan;
每一个创建的用户都是没有任何权限的,需要给用户赋予权限,oracle存在三种角色
| 角色 | 权限 | 赋予典型代表 |
|---|---|---|
connect |
|
授予最终用户 |
resource |
|
授予开发人员的 |
dba |
拥有全部权限,只有dba才可以创建数据库结构 | 管理员 |
赋予角色权限的sql语句:
grant 角色名 to 用户名
--demo
GRANT CONNECT to zhangsan;
如果给这个用户赋予dba的角色,就可以查看任何用户下面的表
GRANT dba to zhangsan;
--查看scott用户下的表
SELECT * FROM SCOTT.DEPT;
创建表
create table 表名(
字段名1 数据类型,
字段名2 数据类型,
字段名3 数据类型,
...
字段名n 数据类型
);
--demo
CREATE TABLE test1(
name VARCHAR2(100),
age NUMBER,
birthday DATE
)
oracle支持的数据类型:
| 数据类型 | 描述 |
|---|---|
varchar2(size) |
可变长度字符数据 |
char(size) |
定长字符数据 |
number(p,s) |
可变长数值数据,p为总长度,s为小数长度 |
date |
日期型数据 |
timestamp |
时间戳,比date类型更加精确 |
long |
可变长字符数据,最大可达2G,用来存字符,可以存放一本小说等大文件 |
clob |
字符数据,最大可达4G |
raw and long raw |
原始的二进制数据 |
blob |
二进制数据,可以存放一部电影等超大文件 |
bfile |
存储外部文件的二进制数据,最大可达4G |
ROWID |
行地址 |
复制表
--格式:
create table 表名 as 查询语句;
CREATE TABLE test3 as SELECT * FROM T_TABLE_NAME where 1=2;
注意: 复制表可以将表的结构数据都复制过来,但不会复制表的约束,如果不想复制数据,可以给查询语句加一个不成立的条件,使查询语句没有结果,就不复制数据,只会复制表结构了。
修改表
-
添加一个字段
--格式: alter table 表名 add(列名1 类型,列名2 类型 ...) --demo ALTER TABLE T_TABLE_NAME add phone VARCHAR2(11); ALTER TABLE T_TABLE_NAME ADD( mobile VARCHAR2(11), sex VARCHAR2(2) ); -
修改字段的数据类型
--格式: alter table 表名 modify(列名1 数据类型,列名2 数据类型 ...) --demo ALTER TABLE T_TABLE_NAME MODIFY sex VARCHAR2(4); -
修改字段的名称
--格式: alter table 表名 rename column 列名1 to 列名2; --demo ALTER TABLE T_TABLE_NAME RENAME COLUMN sex to gender; -
删除列
--格式: alter table 表名 drop column 列名; --demo ALTER TABLE T_TABLE_NAME DROP COLUMN BIRTHDAY; -
修改表名
--格式 rename 表名 to 重命名; --demo RENAME T_TABLE_NAME to T_TABLE_NAME1;
删除表格
--格式:
drop table 表名;
--demo
DROP TABLE T_TABLE_NAME;
约束
约束主要是用来约束表中数据的规则
oracle数据库包含的约束主要有:
| 约束 | 约束名称 |
|---|---|
primary key |
主键约束 |
Not Null |
非空约束 |
Unique |
唯一约束 |
foreign key |
外键约束 |
check |
检查性约束 |
| demo: |
CREATE TABLE T_TABLE_NAME(
stuid NUMBER primary key,
sname VARCHAR2(20) UNIQUE,
age NUMBER not null,
gender VARCHAR2(4) CHECK(gender in('男','女','人妖'))
);
外键约束
外键约束主要是用来约束从表中的记录,外键约束必须存在于主表中。
--添加外键约束的格式:
alter table 主表名 add foreign key(需要设置为外键的列名) references 从表(外键对应的列) ;
--demo
ALTER TABLE T_TABLE_NAME ADD foreign key(cno) references T_TABLE_NAME1(cid);
删除表
-
强制删除
当两个表有外键关联的时候无法随便删除表格,可以使用强制删除或者先删除外键约束,再删除表。(不建议使用)--强制删除 drop table 表名 cascade constraint; -
级联删除
--添加级联删除外键约束的格式: alter table 主表 add foreign key(需要设置为外键的列名) references 从表(与外键对应的列) on delete cascade; --demo ALTER TABLE product ADD foreign key(cno) references category(cid) on DELETE cascade; --级联删除 delete from 从表 where 外键对应的列 = 条件; --demo delete from T_TABLE_NAME where cid = 1;使用级联删除可以在删除从表中数据的同时,对应删除主表中的数据,不会该表数据库的结构(建议使用)。
插入数据
insert into 表名 (列名1,列名2,列名3...)values(值1,值2,值3...)
insert into 表名 values(值1,值2,值3...)
--使用子查询插入数据
insert into 表名 查询语句;
--demo
INSERT into T_TABLE_NAME SELECT * from T_TABLE_NAME1 where kkbh = 1;
更新数据
全局修改(慎用):
update 表名 set 列名1 = 值1,列名2 = 值2...
局部修改:
update 表名 set 列名1 = 值1,列名2 = 值2... where 修改条件
删除数据
全部删除(慎用):
delete from 表名
truncate table 表名;
局部删除:
delete from 表名 where 条件
delete与truncate的区别
delete属于DML,truncate属于DDLdelete逐条删除,truncate是先删除表再创建表- 因为
delete属于 DML ,所以delete支持事务操作,而truncate属于DDL,所以不支持事务操作,因此,delete删除的数据可以找回,但是truncate是永久删除,不能找回 truncate比delete的执行效率要高
序列
Oracle 的序列类似于 mysql 的 auto_increment 这种ID自动增长的形式
创建一个序列:
--格式:
create sequence 序列的名称
start with 从起开始
increment by 步长
maxvalue 最大值
minvalue 最小值
(no)cycle --是否循环
(no)cache 缓存数量
--demo
CREATE sequence seq_test1 start with 1 INCREMENT by 2 maxvalue 30 cycle cache 10;
从序列中获取值:
--currval:当前值,需要在调用 nextval 之后才能使用
--nextval:下一个值
--demo
select seq_test1.nextval from dual;
select seq_test1.currval from dual;
个人项目经验总结
--随机获取10条数据(用于多线程处理数据)
SELECT * FROM (SELECT * FROM T_TABLE_NAME ORDER BY DBMS_RANDOM.RANDOM() ) WHERE Rownum <= 10;
--根据指定字段条件统计(统计男女的个数和60岁以上男女的个数)
SELECT sex,count(case age when age > 60 then 1 else null end) oldSum,count(0) sum FROM T_TABLE_NAME GROUP BY sex
--去掉字符串中的数字(translate没有替换为空串的功能,所以需要在外面包裹一个replace)
select replace(translate('abc1234def678add590a','0123456789',' '),' ','') from dual
--多种字符串替换(把#替换为@;把%替换为.)
select translate('itmyhome#163%com', '#%', '@.') from dual
--删除重复数据
delete from T_TABLE_NAME where peopleId in (
--根据peopleId查出重复的数据
select peopleId from T_TABLE_NAME group by peopleId having count(peopleId) > 1)
and rowid not in (
--找到rowid最小的那条数据并保留
select min(rowid) from T_TABLE_NAME group by peopleId having count(peopleId) > 1)
--获取每个卡口最新的过车数据
select t.plateno,t.platecolor,t.cameraIndexcode,t.cameraName,t.passTime,t.targetpicurl,t.rankn from (select e.plateno,e.platecolor,e.cameraIndexcode,e.cameraName,e.passTime,e.targetpicurl,rank() over(partition by e.cameraIndexcode order by e.passTime desc,plateno desc) rankn from T_TABLE_NAME e) t where t.rankn = 1
--like 子查询
select * from T_TABLE_NAME s where exists(select 1 from Addresses a where instr(s.address,a.address) > 0)
--创建物化视图(每一天刷新一次)
create materialized view viewName refresh complete on demand start with sysdate next sysdate + 1 as (select * from T_TSET_WHB)
--创建物化视图(每一小时刷新一次)
create materialized view viewName refresh complete on demand start with sysdate next sysdate + 1/24 as (select * from T_TSET_WHB)
--创建物化视图(每一分钟刷新一次)
create materialized view viewName refresh complete on demand start with sysdate next sysdate + 1/24/60 as (select * from T_TSET_WHB)
--生成id
select sys_guid() from dual;
--将以逗号隔开的拆分成多行,方便查询,注意会产生重复,需要加个distinct去重
select distinct regexp_substr(dwDM,'[^,]+',1,level) dwDM,t.* from t connect by level <= regexp_count(dwDM,',') + 1
--根据某些字段将多行记录按照指定分隔符显示在同一行
select hphm,hpzl listagg(bklx,',') within group (order by hphm asc,hpzl asc,bklx asc) bklx from T_TABLE_NAME group by (hphm,hpzl)
--密码设置永不过期
ALTER PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED
递归查询
#查询当前记录以及它上面的每一级父ID
select id from T_TABLE_NAME start with id = '1212121' connect by prior pid = id
#查询当前记录以及它下面的每一级所有的子级ID
select id from T_TABLE_NAME start with id = '1212121' connect by prior id = pid
查看表格之前的版本以及Drop表的恢复
#查看表在2021-06-01 15:15:00时的版本,对于操作错误回滚已提交的事务有补救效果
select * from 表名 as of timestamp to_timestamp('2021-06-01 15:15:00','yyyy-MM-dd HH24:mi:ss');
#恢复删除的表
flashback table 表名 to before drop;
oracle数据库在Linux系统下启动关闭
#1 切换用户到oracle
[root@Centos100 ~] su - oracle
#2 查看监听状态
[oracle@Centos100 ~]$ lsnrctl status
The command completed successfully
#3 如果状态不是上面的状态,则需要启动监听
[oracle@Centos100 ~]$ lsnrctl start
#4 登录sqlPlus
[oracle@Centos100 ~]$ sqlplus /nolog
#5 使用sysdba身份登录
SQL> connect as sysdba
#6 启动
SQL> startup
#7 关闭
SQL> shutdown
#8 退出
SQL> exit
DBLINK(不推荐使用)
dbLink可以满足跨数据源之间的表与表之间关联查询
# 创建dbLink名为db39的连接,注意密码必须使用双引号
CREATE DATABASE LINK db39
CONNECT TO db31 IDENTIFIED BY "1"
USING '127.0.0.1:1521/orcl';
#跨数据源查询
select * from T_TABLE_NAME@db39
Oracle与操作系统时间不一致问题
Oracle 的时区可以分为两种,一种是数据库的时区,一种是 session 时区,也就是客户端连接时的时区
#1. 查看客户端连接时区
select sessiontimezone from dual;
#2. 查看数据库时区
select dbtimezone from dual;
#3. 修改数据库时区
alter database set time_zone='+08:00'
#4. 重启Oracle
Oracle之有修改无新增
begin
update 表名 set filed1 = ?, filed2 = ? ... where 条件;
if sql%notfound then
insert into 表名 (filed1,filed2...) values (?,?...);
end if;
end;
导出dmp
#导出oracle所有的数据
exp 管理员用户名/密码@实例名 file=dmp文件路径 full=y
#导出oracle指定用户下所有的数据
exp 管理员用户名/密码@实例名 file=dmp文件路径 owner=用户名 full=y
#导出oracle指定的表
exp 管理员用户名/密码@实例名 file=dmp文件路径 tables=(用户名.表1,用户名.表2)
#导出oracle按照模糊查询匹配指定的表
exp 管理员用户名/密码@实例名 file=dmp文件路径 tables=用户名.%关键词%
#导出oracle指定用户下所有的表,根据条件导出对应的数据
#注意:
# 1. query参数必须跟tables一起使用
# 2. 查询条件里的<、>、=等都要转义
exp 管理员用户名/密码@实例名 file=dmp文件路径 tables=用户名.% query=\"where rownum \<\= 10\"
#demo
exp system/1@orcl file=/home/oracle/aaa.dmp tables=jxj.% query=\"where rownum \<\= 10\"
Oracle中的特殊表
用户查询
dba_users
--USERNAME 用户名称
--USER_ID 用户ID
--ACCOUNT_STATUS 账户状态
--LOCK_DATE 锁定日期
--EXPIRY_DATE 过期时间
--DEFAULT_TABLESPACE 默认表空间
--TEMPORARY_TABLESPACE 临时表空间
--CREATED 创建时间
select USERNAME, USER_ID, ACCOUNT_STATUS, LOCK_DATE, EXPIRY_DATE, DEFAULT_TABLESPACE, TEMPORARY_TABLESPACE, CREATED from dba_users
表空间文件查询
dba_data_files
--表空间文件查询
--FILE_NAME 表空间文件所在地
--FILE_ID 表空间文件ID
--TABLESPACE_NAME 所属表空间名称
--BYTES 表空间文件字节大小(使用)
--BLOCKS oracle块中文件的大小
--STATUS 文件状态
--AUTOEXTENSIBLE 文件大小是否可扩展
--MAXBYTES 表空间文件最大字节大小
--MAXBLOCKS oracle块中文件的最大大小
--INCREMENT_BY 每次扩展多大
--ONLINE_STATUS 在线状态
select FILE_NAME, FILE_ID, TABLESPACE_NAME, BYTES, BLOCKS, STATUS, AUTOEXTENSIBLE, MAXBYTES, MAXBLOCKS, INCREMENT_BY, ONLINE_STATUS from dba_data_files
查询会话
v$session
查询被锁住的对象
v$locked_object
查询锁对象并解锁
select sess.sid,
sess.serial#,
lo.oracle_username,
lo.os_user_name,
ao.object_name,
lo.locked_mode
from v$locked_object lo,
dba_objects ao,
v$session sess
where ao.object_id = lo.object_id and lo.session_id = sess.sid;
alter system kill session '$sid,$serial#'
查询表
dba_tables
查询视图
dba_views
系统参数
x$ksppi和x$ksppcv
修改Oracle吞吐量,提升全表扫描的性能。
--查询io吞吐量的索引号indx
select ksppinm, indx,KSPPDESC from x$ksppi where ksppinm like '%db_file_optimi%'
--根据索引号indx查询io吞吐量设置的值
select ksppstdvl from x$ksppcv where indx=901
--修改IO吞吐量(修改值:8、16、32、64、128、256),修改的同时查看执行计划,查看SQL查询成本是否不再下降,不再下降则不必再改,表示已到硬件所能支持的极限。
alter session set "_db_file_optimizer_read_count"=16;