使用python读写txt和json(jsonl)大文件
在深度学习方向,尤其是NLP领域,最重要的就是和海量的文字打交道,不管是读取原始数据还是处理数据亦或是最终写数据,合理的读写文件是极为重要的,这篇博客用以记录一下工作中学习到的对大文件读写的过程。
目录
读写txt文本文件
读写JSON文件
读写JSONL文件
遇到的问题
读写txt文本文件
最简单也是最常见的就是读写txt文本文件
读写txt文件直接调用python内部库的open和write函数就基本可以了,比如中student.txt文件中:
张奇 18 计算机学院 看书,打篮球,看电影
刘欣 19 计算机学院 唱歌,健身
杜航 18 计算机学院 动漫,看书
盛蓉 20 外国语学院 唱歌,看书,美食
余杰 20 土木学院 唱歌,运动,游戏
王某 19 土木学院 羽毛球,游戏
李某 20 外国语学院 动漫,唱歌其中分别为姓名,年龄,学院,兴趣爱好,每类用一个制表符(\t)隔开,兴趣爱好中间用英文逗号分隔开来,然后用open打开txt文件并将内容读取打印
file_txt = "student.txt"
with open(file_txt) as file:
for line in file:
name,age,department,hobby = line.strip().split("\t")
print(name,age,department,hobby)同样,也可以用write函数写到一个新的文件中去,过程中我们可以用几个list先将数据存起来,也可以一边读一边写,但是一行行读一行行写小数据还好,当文件过大时大量的文件io会话费大量的时间,但是使用list全部存储然后写的话又会比较耗内存,各有优劣,看情况使用
使用list:
file_txt = "student.txt"
file_new_txt = "newstudent.txt"
stu = []
with open(file_txt) as file:
for line in file:
name,age,department,hobby = line.strip().split("\t")
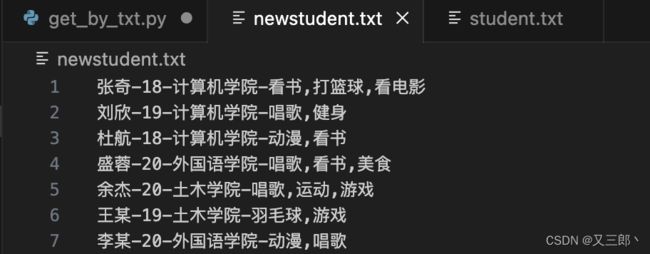
stu.append(name+"-"+age+"-"+department+"-"+hobby)
with open(file_new_txt,"a+") as file:
for student in stu:
file.write(student+"\n")
 边读边写:
边读边写:
file_txt = "student.txt"
file_new_txt = "newstudent.txt"
with open(file_txt) as file:
for line in file:
name,age,department,hobby = line.strip().split("\t")
with open(file_new_txt,"a+") as file_new:
file_new.write(name+"-"+age+"-"+department+"-"+hobby+"\n")
txt文件是最常用的,但是也有其局限性,就是很难对文件中分隔开的内容进行标注,比如,对每一行数据都标明姓名:张奇,年龄:18这样,这时就需要用到json文件格式了
读写JSON文件
python中对json文件的读写需要导入json包,然后调用包内函数就可以完成读写了
import json
file_txt_path = "student.txt"
file_json_path = "student.json"
with open(file_txt_path) as file:
for line in file:
name,age,department,hobby = line.strip().split("\t")
hobby = hobby.split(",")
data = {
"姓名":name,
"年龄":age,
"学院":department,
"爱好":hobby
}
with open(file_json_path,"a+") as file_json:
file_json.write(json.dumps(data,ensure_ascii=False))
file_json.write(","+"\n")
这样就会获得这样一个json文件

但是这样的json文件格式是有问题的,我们需要在前面和后面加个[],并且把最后面那个","去掉
前后加[]倒是比较简单,如何去掉最后一个","倒是比较头疼,我暂时的思路是统计txt文件行数,在最后一行的时候就不写入","了
我们调用wc来统计文件行数:
import json
file_txt_path = "student.txt"
file_json_path = "student.json"
def _wc_count(file_name):
"""通过wc命令统计文件行数"""
import subprocess
out = subprocess.getoutput("wc -l %s" % file_name)
return int(out.split()[0])
count = _wc_count(file_txt_path)
i = 0
with open(file_json_path,"a+") as file:
file.write("["+"\n")
with open(file_txt_path) as file:
for line in file:
name,age,department,hobby = line.strip().split("\t")
hobby = hobby.split(",")
data = {
"姓名":name,
"年龄":age,
"学院":department,
"爱好":hobby
}
with open(file_json_path,"a+") as file_json:
file_json.write(json.dumps(data,ensure_ascii=False))
if(i < count):
file_json.write(","+"\n")
else:
file_json.write("\n")
file_json.write("]")
i +=1
这样写入之后就变成了
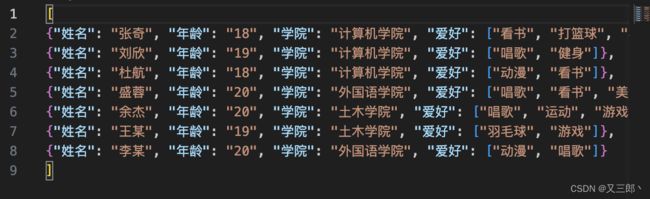
这样,将完成了json文件的写入
json文件的读会比较不太好用,因为它是无法一行行或者说一条条数据的读的,只能一次性将所有内容读到内存中,代码如下:
import json
file_json_path = "student.json"
with open(file_json_path) as file:
result = json.loads(file.read())
#result是一个json对象
for stu in result:
hobby = ",".join(stu["爱好"])
print(stu["姓名"]+"\t"+stu["年龄"]+"\t"+stu["学院"]+"\t"+hobby)

但是上面也提到了,json文件只能一次性将所有内容读到内存中然后进行操作,当文件很大的时候这样说不合理的,尤其是现在的NLP领域,文件都有数十G甚至上百G,显然内存是不足以放下的,那么这样,我们就要用到一个可以逐行读取json对象的文件格式了
读写JSONL文件
jsonl文件的读写和json文件很相似,但是文件格式上有一丝丝的不同
图中将}后面的","去掉就是一个完整的jsonl文件格式
所以,我们写jsonl文件就十分方便了。代码如下
import jsonlines
file_txt_path = "student.txt"
file_jsonl_path = "student.jsonl"
with open(file_txt_path) as file:
for line in file:
name,age,department,hobby = line.strip().split("\t")
hobby = hobby.split(",")
data = {
"姓名":name,
"年龄":age,
"学院":department,
"爱好":hobby
}
with jsonlines.open(file_jsonl_path,mode="a") as file_jsonl:
file_jsonl.write(data)

然后就是jsonl的读了,代码如下:
import jsonlines
file_jsonl_path = "student.jsonl"
with open(file_jsonl_path) as file:
for stu in jsonlines.Reader(file):
hobby = ",".join(stu["爱好"])
print(stu["姓名"]+"\t"+stu["年龄"]+"\t"+stu["学院"]+"\t"+hobby)

这样,就可以实现一条条读取json对象了
遇到的问题
上面这些可以满足大部分对数据的读写了,但是我在工作中遇到了一个问题,就是json对象的删除情况,在json文件中,可以直接调用del来删除字段,但是中jsonl文件中,我无法删除指定字段,只能用复写新文件的方法来实现,翻阅了很久的资料都没有找到相应的方法,希望有大佬能在评论区指导一下