flink sql 如何upsert 到一张hologres表中
Flink Table 的三种 Sink 模式
作为计算引擎 Flink 应用的计算结果总要以某种方式输出,比如调试阶段的打印到控制台或者生产阶段的写到数据库。而对于本来就需要在 Flink 内存保存中间及最终计算结果的应用来说,比如进行聚合统计的应用,输出结果便是将内存中的结果同步到外部。就 Flink Table/SQL API 而言,这里的同步会有三种模式,分别是 Append、Upsert 和 Retract。实际上这些输出计算结果的模式并不限于某个计算框架,比如 Storm、Spark 或者 Flink DataStream 都可以应用这些模式,不过 Flink Table/SQL 已有完整的概念和内置实现,更方便讨论。
基础原理
相信接触过 Streaming SQL 的同学都有了解或者听过流表二象性,简单来说流和表是同一事实的不同表现,是可以相互转换的。流和表的表述在业界不尽相同,笔者比较喜欢的一种是: 流体现事实在时间维度上的变化,而表则体现事实在某个时间点的视图。如果将流比作水管中流动的水,那么表将是杯子里静止的水。
将流转换为表的方法对于大多数读者都不陌生,只需将聚合统计函数应用到流上,流很自然就变为表(值得注意的是,Flink 的 Dynamic Table 和表的定义有细微不同,这将在下文讲述)。比如对于一个计算 PV 的简单流计算作业,将用户浏览日志数据流安 url 分类统计,变成 (url, views) 这样的一个表。然而对于如何将表转换成流,读者则未必有这么清晰的概念。
假设一个典型的实时流计算应用的工作流程可以被简化为下图:
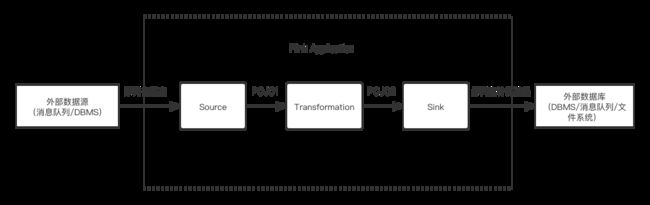
其中很关键的一点是 Transformation 是否聚合类型的计算。若否,则输出结果依然是流,可以很自然地使用原本流处理的 Sink(与外部系统的连接器);若是,则流会转换为表,那么输出的结果将是表,而一个表的输出通常是批处理的概念,不能直接简单地用流处理的 Sink 来表达。
这时有个很朴素的想法是,我们能不能避免批处理那种全量的输出,每次只输出表的 diff,也就是 changelog。这也是表转化为流的方法: 持续观察表的变化,并将每个变化记录成日志输出。因此,流和表的转换可以以下图表示:

其中表的变化具体可以分为 INSERT、UPDATE 和 DELETE 三类,而 Flink 根据这些变化类型分别总结了三种结果的输出模式。
| 模式 | INSERT | UPDATE | DELETE |
|---|---|---|---|
| Append | 支持 | 不支持 | 不支持 |
| Upsert | 支持 | 支持 | 支持 |
| Retract | 支持 | 支持 | 支持 |
通常来说 Append 是最容易实现但功能最弱的,Retract 是最难实现而功能最强的。下文分别谈谈三种模式的特点和应用场景。
Append 输出模式
Append 是最为简单的输出模式,只支持追加结果记录的操作。因为结果一旦输出以后便不会再有变更,Append 输出模式的最大特性是不可变性(immutability),而不可变性最令人向往的优势便是安全,比如线程安全或者 Event Sourcing 的可恢复性,不过同时也会给业务操作带来限制。通常来说,Append 模式会用于写入不方便做撤回或者删除操作的存储系统的场景,比如 Kafka 等 MQ 或者打印到控制台。
在实时聚合统计中,聚合统计的结果输出是由 Trigger 决定的,而 Append-Only 则意味着对于每个窗口实例(Pane,窗格)Trigger 只能触发一次,则就导致无法在迟到数据到达时再刷新结果。通常来说,我们可以给 Watermark 设置一个较大的延迟容忍阈值来避免这种刷新(再有迟到数据则丢弃),但代价是却会引入较大的延迟。
不过对于不涉及聚合的 Table 来说,Append 输出模式是非常好用的,因为这类 Table 只是将数据流的记录按时间顺序排在一起,每条记录间的计算都是独立的。值得注意的是,从 DataFlow Model 的角度来看未做聚合操作的流不应当称为表,但是在 Flink 的概念里所有的流都可以称为 Dynamic Table。笔者认为这个设计也有一定的道理,原因是从流中截取一段出来依然可以满足表的定义,即”某个时间点的视图”,而且我们可以争辩说不聚合也是一种聚合函数。
Upsert 输出模式
Upsert 是 Append 模式的升级版,支持 Append-Only 的操作和在有主键的前提下的 UPDATE 和 DELETE 操作。Upsert 模式依赖业务主键来实现输出结果的更新和删除,因此非常适合 KV 数据库,比如
HBase、JDBC 的 TableSink 都使用了这种方式。
在底层,Upsert 模式下的结果更新会被翻译为 (Boolean, ROW) 的二元组。其中第一个元素表示操作类型,true 对应 UPSERT 操作(不存在该元素则 INSERT,存在则 UPDATE),false 对应 DELETE 操作,第二个元素则是操作对应的记录。如果结果表本身是 Append-Only 的,第一个元素会全部为 true,而且也无需提供业务主键。
Upsert 模式是目前来说比较实用的模式,因为大部分业务都会提供原子或复合类型的主键,而在支持 KV 的存储系统也非常多,但要注意的是不要变更主键,具体原因会在下一节谈到。
Retract 输出模式
Retract 是三种输出模式中功能最强大但实现也最复杂的一种,它要求目标存储系统可以追踪每个条记录,而且这些记录至少在一定时间内都是可以撤回的,因此通常来说它会自带系统主键,不必依赖于业务主键。然而由于大数据存储系统很少有可以精确到一条记录的更新操作,因此目前来说至少在 Flink 原生的 TableSink 中还没有能在生产环境中满足这个要求的。
不同于 Upsert 模式更新时会将整条记录重新输出,Retract 模式会将更新分成两条表示增减量的消息,一条是 (false, OldRow) 的撤回(Retract)操作,一条是 (true, NewRow) 的积累(Accumulate)操作。这样的好处是,在主键出现变化的情况下,Upsert 输出模式无法撤回旧主键的记录,导致数据不准确,而 Retract 模式则不存在这个问题。
举个例子,假设我们将电商订单按照承运快递公司进行分类计数,有如下的结果表。
| 公司 | 订单数 |
|---|---|
| 中通 | 2 |
| 圆通 | 1 |
| 顺丰 | 3 |
那么如果原本一单为中通的快递,后续更新为用顺丰发货,对于 Upsert 模式会产生 (true, (顺丰, 4)) 这样一条 changelog,但中通的订单数没有被修正。相比之下,Retract 模式产出 (false, (中通, 1)) 和 (true, (顺丰, 1)) 两条数据,则可以正确地更新数据。
总结
Flink Table Sink 的三种模式本质上是如何监控结果表并产生 changelog,这可以应用于所有需要将表转为流的场景,包括同一个 Flink 应用的不同表间的联动。三种模式中 Append 模式只支持表的 INSERT,最为简单;Upsert 模式依赖业务主键提供 INSERT、UPDATE 和 DELETE 全部三类变更,比较实用;Retract 模式同样支持三类变更且不要求业务主键,但会将 UPDATE 翻译为旧数据的撤回和新数据的累加,实现上比较复杂。
flink sql 如何upsert 到一张hologres表中
要使用Flink SQL将数据upsert到Hologres表中,您需要执行以下步骤:
1.首先,使用Hologres JDBC驱动程序在Flink SQL客户端中注册Hologres数据源。
2.在Flink SQL中创建一个包含所有要upsert的字段的临时表,例如:
CREATE TEMPORARY TABLE tmp_table (
id INT,
name VARCHAR,
age INT
);
3.使用Flink SQL的UPSERT语法将临时表中的数据插入到Hologres表中。UPSERT语法基于唯一约束来决定是插入新行还是更新现有行。以下是一个示例UPSERT语句:
UPSERT INTO hologres_table
SELECT *
FROM tmp_table
ON CONFLICT (id) DO UPDATE SET
name = EXCLUDED.name,
age = EXCLUDED.age;
在此示例中,我们将临时表中的所有数据upsert到Hologres表中,并使用“id”字段作为唯一约束条件。如果Hologres表中已存在具有相同“id”值的行,则使用临时表中的数据更新该行的“name”和“age”字段。否则,将临时表中的数据插入新行。
4.执行UPSERT语句并将其发送到Hologres表中,您需要使用Flink SQL的Table API和Hologres JDBC连接器。以下是一个示例Java代码片段,说明如何使用Table API将UPSERT语句发送到Hologres表中:
// 创建一个Hologres JDBC连接器
HologresJdbcConnector jdbcConnector = new HologresJdbcConnector(url, username, password);
// 创建Flink TableEnvironment
TableEnvironment tEnv = TableEnvironment.create(env);
// 将Hologres数据源注册到TableEnvironment中
tEnv.registerJdbcTable("hologres_table", jdbcConnector);
// 创建临时表
tEnv.executeSql("CREATE TEMPORARY TABLE tmp_table (id INT, name VARCHAR, age INT)");
// 在临时表中插入数据
tEnv.executeSql("INSERT INTO tmp_table VALUES (1, 'Alice', 25), (2, 'Bob', 30)");
// UPSERT数据到Hologres表中
tEnv.executeSql("UPSERT INTO hologres_table SELECT * FROM tmp_table ON CONFLICT (id) DO UPDATE SET name = EXCLUDED.name, age = EXCLUDED.age");
请注意,您需要替换示例代码中的“url”,“username”和“password”参数为您的Hologres连接信息。