中国软件杯---基于百度飞桨的单/多镜头行人追踪Baseline,deepsort实现行人追踪
项目简介
本项目基于2021年的“中国软件杯”的《单/多镜头行人追踪模型》赛题做的一个非官方的baseline。该项目使用PaddleDetection快速训练分类模型,然后通过PaddleLite部署到安卓手机上,实现飞桨框架深度学习模型的落地。
- 模型训练:PaddleDetection,
PPYolo的backbone使用MobileNetV3_large和YOLOv3Head - 模型转换:Paddle-Lite
- Android开发环境:Android Studio on Ubuntu 18.04 64-bit
- 移动端设备:安卓9.0以上的手机设备

关于本项目
本项目基于2021年的“中国软件杯针”的《单/多镜头行人追踪模型》赛题做的一个非官方的baseline。对项目还存在的改进空间,以及其它模型在不同移动设备的部署,希望大家多交流观点、介绍经验,共同学习进步,可以互相关注♥。个人主页
项目地址,点我直接跳转看完整内容
1、PaddleDetection快速训练迁移学习模型
PaddleDetection简介
PaddleDetection飞桨目标检测开发套件,旨在帮助开发者更快更好地完成检测模型的组建、训练、优化及部署等全开发流程。PaddleDetection模块化地实现了多种主流目标检测算法,提供了丰富的数据增强策略、网络模块组件(如骨干网络)、损失函数等,并集成了模型压缩和跨平台高性能部署能力。
PPYolo文档


展示部分代码,完整的代码以及环境建议直接到项目运行,防止出现其他错误。项目地址,点我直接跳转看更多详情
2、处理数据集格式
# 创建索引
from pycocotools.coco import COCO
import os
import shutil
from tqdm import tqdm
import skimage.io as io
import matplotlib.pyplot as plt
import cv2
from PIL import Image, ImageDraw
from shutil import move
import xml.etree.ElementTree as ET
from random import shuffle
# import fileinput #操作文件流
"""
处理成VOC格式
"""
# 保存路径
savepath = "VOCData/"
img_dir = savepath + 'images/' #images 存取所有照片
anno_dir = savepath + 'annotations/' #Annotations存取xml文件信息
datasets_list=['train2017', 'val2017']
classes_names = ['person']
# 读取COCO数据集地址 Store annotations and train2014/val2014/... in this folder
dataDir = './'
#写好模板,里面的%s与%d 后面文件输入输出流改变 -------转数据集阶段--------
headstr = """
VOC
%s
My Database
COCO
flickr
NULL
NULL
company
%d
%d
%d
0
"""
objstr = """
"""
tailstr = '''
'''
# if the dir is not exists,make it,else delete it
def mkr(path):
if os.path.exists(path):
shutil.rmtree(path)
os.mkdir(path)
else:
os.mkdir(path)
mkr(img_dir)
mkr(anno_dir)
def id2name(coco): # 生成字典 提取数据中的id,name标签的值 ---------处理数据阶段---------
classes = dict()
for cls in coco.dataset['categories']:
classes[cls['id']] = cls['name']
return classes
def write_xml(anno_path, head, objs, tail): #把提取的数据写入到相应模板的地方
f = open(anno_path, "w")
f.write(head)
for obj in objs:
f.write(objstr % (obj[0], obj[1], obj[2], obj[3], obj[4]))
f.write(tail)
def save_annotations_and_imgs(coco, dataset, filename, objs):
# eg:COCO_train2014_000000196610.jpg-->COCO_train2014_000000196610.xml
anno_path = anno_dir + filename[:-3] + 'xml'
img_path = dataDir + dataset + '/' + filename
dst_imgpath = img_dir + filename
img = cv2.imread(img_path)
if (img.shape[2] == 1):
print(filename + " not a RGB image")
return
shutil.copy(img_path, dst_imgpath)
head = headstr % (filename, img.shape[1], img.shape[0], img.shape[2])
tail = tailstr
write_xml(anno_path, head, objs, tail)
def showimg(coco, dataset, img, classes, cls_id, show=True):
global dataDir
I = Image.open('%s/%s/%s' % (dataDir, dataset, img['file_name']))# 通过id,得到注释的信息
annIds = coco.getAnnIds(imgIds=img['id'], catIds=cls_id, iscrowd=None)
anns = coco.loadAnns(annIds)
# coco.showAnns(anns)
objs = []
for ann in anns:
class_name = classes[ann['category_id']]
if class_name in classes_names:
if 'bbox' in ann:
bbox = ann['bbox']
xmin = int(bbox[0])
ymin = int(bbox[1])
xmax = int(bbox[2] + bbox[0])
ymax = int(bbox[3] + bbox[1])
obj = [class_name, xmin, ymin, xmax, ymax]
objs.append(obj)
return objs
# ----------测试的无用代码---------- 注释不影响
# def del_firstline(file_name):
# for line in fileinput.input(file_name, inplace = 1):
# if fileinput.isfirstline():
# print(line.replace("\n", " "))
# fileinput.close()
# break
# def del_firstline(file_name):
# with open(file_name) as fp_in:
# with open(file_name, 'w') as fp_out:
# fp_out.writelines(line for i, line in enumerate(fp_in) if i != 10)
for dataset in datasets_list:
# ./COCO/annotations/instances_train2014.json
annFile = '{}/annotations/instances_{}.json'.format(dataDir, dataset)
# COCO API for initializing annotated data
coco = COCO(annFile)
'''
COCO 对象创建完毕后会输出如下信息:
loading annotations into memory...
Done (t=0.81s)
creating index...
index created!
至此, json 脚本解析完毕, 并且将图片和对应的标注数据关联起来.
'''
# show all classes in coco
classes = id2name(coco)
print(classes)
# [1, 2, 3, 4, 6, 8]
classes_ids = coco.getCatIds(catNms=classes_names)
print(classes_ids)
for cls in classes_names:
# Get ID number of this class
cls_id = coco.getCatIds(catNms=[cls])
img_ids = coco.getImgIds(catIds=cls_id)
# imgIds=img_ids[0:10]
for imgId in tqdm(img_ids):
img = coco.loadImgs(imgId)[0]
filename = img['file_name']
objs = showimg(coco, dataset, img, classes, classes_ids, show=False)
save_annotations_and_imgs(coco, dataset, filename, objs)
out_img_base = 'images'
out_xml_base = 'Annotations'
img_base = 'VOCData/images/'
xml_base = 'VOCData/annotations/'
if not os.path.exists(out_img_base):
os.mkdir(out_img_base)
if not os.path.exists(out_xml_base):
os.mkdir(out_xml_base)
for img in tqdm(os.listdir(img_base)):
xml = img.replace('.jpg', '.xml')
src_img = os.path.join(img_base, img)
src_xml = os.path.join(xml_base, xml)
dst_img = os.path.join(out_img_base, img)
dst_xml = os.path.join(out_xml_base, xml)
if os.path.exists(src_img) and os.path.exists(src_xml):
move(src_img, dst_img)
move(src_xml, dst_xml)
def extract_xml(infile):
# tree = ET.parse(infile) #源码与我写的效果相同
# root = tree.getroot()
# size = root.find('size')
# classes = []
# for obj in root.iter('object'):
# cls_ = obj.find('name').text
# classes.append(cls_)
# return classes
with open(infile,'r') as f: #解析xml中的name标签
xml_text = f.read()
root = ET.fromstring(xml_text)
classes = []
for obj in root.iter('object'):
cls_ = obj.find('name').text
classes.append(cls_)
return classes
if __name__ == '__main__':
base = 'Annotations/'
Xmls=[]
# Xmls = sorted([v for v in os.listdir(base) if v.endswith('.xml')])
for v in os.listdir(base):
if v.endswith('.xml'):
Xmls.append(str(v))
# iterable -- 可迭代对象。key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
print('-[INFO] total:', len(Xmls))
# print(Xmls)
labels = {'person': 0}
for xml in Xmls:
infile = os.path.join(base, xml)
# print(infile)
cls_ = extract_xml(infile)
for c in cls_:
if not c in labels:
print(infile, c)
raise
labels[c] += 1
for k, v in labels.items():
print('-[Count] {} total:{} per:{}'.format(k, v, v/len(Xmls)))
3、训练代码及调用VisualDL,方便实时观察炼丹情况
3.1 训练代码
#初次炼丹 ,等有一个好的模型了,可以使用断点续训,在下一个代码命令
!python tools/train.py -c configs/ppyolo/ppyolo_voc_Mymobilenet.yml --use_vdl True --eval -o use_gpu=true
#断点续训
!python -u tools/train.py -c configs/ppyolo/ppyolo_voc_Mymobilenet.yml -r output/yolov4_cspdarknet_voc/10000 --use_vdl True --eval #这是指在10000轮的地方接着他的参数训练
3.2 VisualDL使用
查看VisualDL训练过程,需要执行如下步骤:
- 在左边一列工具栏找到 “可视化” 选择添加 “设置logdir” 添加这个路径
work/PaddleDetection-release-2.0-rc/vdl_log_dir/scalar然后点击启动服务–>打开VisualDL 实时观察炼丹一系类指标走向 个人觉得loss与mAP最重要 提分的关键(推荐这个方法 最简单) - 打开终端执行命令
visualdl --logdir ./log --port 8001 - 复制本项目的网址并将
notebooks之后内容全部替换为visualdl,如打开网页https://aistudio.baidu.com/bdvgpu32g/user/90149/613622/visualdl

3.3 mAP简介:

当然炼丹只有这点mAP是不够的,这个模型的推理能力很差,所以后面的推理代码命令 生成的图片很可能会没有框出人来,需要做大量的训练与调节参数,而且也可以使用断点续训来减少你的算力资源消耗。(baseline)

4、推理预测 查看模型训练的效果
!python tools/infer.py -c ppyolo_voc.yml -o weights=output/ppyolo_voc_Mymobilenet/best_model.pdparams --infer_img=../../Test/553.jpg
5、Paddlelite 转化模型生成.np的部署阶段
#部分代码
!python tools/export_model.py -c configs/ppyolo/ppyolo_voc_Mymobilenet.yml -o weights=output/ppyolo_voc_Mymobilenet/best_model.pdparams
# 准备PaddleLite部署模型
!paddle_lite_opt \
--model_file=output/inference_model/ppyolo_voc_Mymobilenet/__model__ \
--param_file=output/inference_model/ppyolo_voc_Mymobilenet/__params__ \
--optimize_out=output/inference_model/ppyolo_voc_Mymobilenet/ppyolo_model \
--optimize_out_type=naive_buffer \
--valid_targets=arm
#下面命令可以打印出ppyolo_voc模型中包含的所有算子,并判断在硬件平台valid_targets下Paddle-Lite是否支持该模型
!paddle_lite_opt --print_model_ops=true --model_dir=output/inference_model/ppyolo_voc_Mymobilenet --valid_targets=arm
上面的opt工具成功后,最终生成.nb的模型文件就可以继续往后部署了

6、部署到64位Linux下的Android Studio开发环境上
准备Android Studio开发环境
安装 Android Studio
参考安装 Android Studio,下载自己PC对应的环境安装,我自己是在Linux自带的火狐浏览器上去Android Studio官网下载的。
本项目介绍在Ubuntu 18.04 64-bit上的Android Studio安装和配置。(详情请进入项目中查看)
完成以上的后,我运行部署成功的截图和一些信息
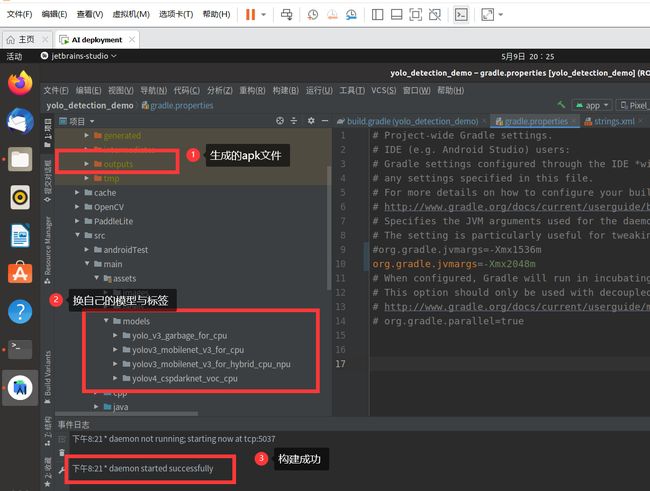
7、部署模型到移动端
手机开发者模式连接
- 将手机通过USB数据线连接到PC上
- 在手机上点击:“设置”——“关于手机”——“版本号”(连续多次点击版本号才能启动开发者模式)
- 回到“设置”界面,可以在“搜索设置项”中查找“开发人员选项”并进入
- 重点:先打开“仅充电模式下允许ADB调试”然后再打开“USB调试”——否则Android Studio识别不到华为手机