Python常用数据分析操作
目录
- Numpy基础
-
- 1.多维数组对象:ndarray
-
- 1.1 生成多维数组对象
- 1.2 ndarry的数据类型
- 1.3 Numpy数组计算
- 1.4 数组索引与切片
- 1.5 布尔索引
- 1.6 神奇检索
- 1.7 数组转置与换轴
- 2. 通用函数:向量化计算
- 3. 使用数组进行面向数组编程
-
- 3.1 将条件逻辑作为数组操作
- 3.2 数学和统计方法
- 3.3 排序
- 3.4 其他集合逻辑
- 4. 线性代数
- 5. 示例:随机漫步
- pandas入门
-
- 1.pandas数据结构
-
- 1.1 series
- 1.2 DataFrame
- 1.3 索引对象
- 2. 基本功能
-
- 2.1 重建索引
- 2.2 删除条目
- 2.3 索引、选择、过滤
- 2.4 算术和整数对齐
- 2.5 函数应用和映射
- 2.6 排序和排名
- 3. 描述性统计
-
- 3.1 相关性和协方差
- 3.2 其他方法
- 数据载入、存储、文件格式
-
- 1.文本格式数据读写
-
- 1.1 分块读入文本文件
- 1.2 将数据写入文本
- 1.3 使用分隔格式
- 2.其他格式
-
- 2.1 读取Excel文件
- 数据清洗与准备
-
- 1. 缺失值
-
- 1.1 过滤缺失值
- 1.2 缺失值填补
- 2. 数据转换
-
- 2.1 删除重复值
- 2.2 使用函数或映射进行数据转换
- 2.3 替代值
- 2.4 重命名轴索引
- 2.5 离散化和分组
Numpy基础
1.多维数组对象:ndarray
1.1 生成多维数组对象
array函数
该函数的参数为任意的序列型对象,比如Python内建的列表对象
import numpy as np
ls1 = range(1,10,1)
array1 = np.array(ls1)
ls2 = [[1,2,3,4],[5,6,7,8]]
array2 = np.array(ls2)
在生成多维数组后,可以使用array.shape查看维数,array.dtype查看数据类型。
也可以使用内建函数range的数组版:
array = np.arange(0,10,2)
此外还有其他生成特殊数组的方法:
array3 = np.zeros(10)
array4 = np.ones(3,6) #创建3行6列的1数组
array5 = np.empty(2,3,2)
更多的数组生成函数可以参考书P91的表4-1
1.2 ndarry的数据类型
数据类型(dtype)也是一种对象,可以在创建数组的时候进行声明:
array6 = np.array([1,2,3], dtype = np.float64)
array7 = np.array([1,2,3], dtype = np.int32)
此外还可以利用astype方法转换数组数据类型:
array6.astype(np.int32)
array6.dtype
也可以用astype方法将全部是数字的字符串转换为数字。
甚至直接用另一个数组的dtype属性作为astype方法的参数
1.3 Numpy数组计算
利用Numpy创建的数组具有一个重要的特性:可以进行向量化操作,而无须进行循环
array2 * array2 #会把array2中的每个元素分别相乘
1 / array2 #会用1除以array2中的每个元素
1.4 数组索引与切片
对于一维数组,Numpy的索引和切片方法与Python的List类型相似。但是与Python的内建列表不同,数组的切片是原数组的视图,即任何对于视图的的修改都会反映到原数组上,看个例子就知道是什么意思了:
In [4]: arr[5:8]
Out[4]: array([5, 6, 7])
In [5]: arr_slice = arr[5:8]
In [6]: arr_slice[1] = 10
In [7]: arr
Out[7]: array([ 0, 1, 2, 3, 4, 5, 10, 7, 8, 9])
可以看到对于切片的改变也会改变原数组。
这反映了在Numpy中很少去做赋值数组这种操作,因为Numpy本身设计的目的是处理大数组的,所以如果总是在复制数据会占用很多内存。
如果非得复制数据切片的话,需用方法copy():
arr_slice = arr[5:8].copy()
在多维数据中,情况会稍显复杂:
我们先创建一个3*3*1的数组看看:
In [9]: arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])
In [10]: arr2d
Out[10]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [11]: arr2d[2]
Out[11]: array([7, 8, 9])
In [12]: arr2d[2][2]
Out[12]: 9
In [13]: arr2d[2,2]
Out[13]: 9
即如果只用一个索引,会返回一整行。要返回某个具体元素的话,得用递归。
再来创建一个2*2*3的数组看看:
In [14]: arr3d = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
In [15]: arr3d
Out[15]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
In [16]: arr3d[0]
Out[16]:
array([[1, 2, 3],
[4, 5, 6]])
In [17]: arr3d[1]
Out[17]:
array([[ 7, 8, 9],
[10, 11, 12]])
In [18]: arr3d[0][0]
Out[18]: array([1, 2, 3])
所谓2*2*3数组,意思是每个元素都是3维数组,矩阵为2*2的。
注意以上所有子集选择返回的都是视图。
多维数组切片也与一维数组不太一样,与索引类似,进行切片时,首先对行切片,然后才是对列切片:
In [19]: arr2d[:2]
Out[19]:
array([[1, 2, 3],
[4, 5, 6]])
In [20]: arr2d[:2,1:]
Out[20]:
array([[2, 3],
[5, 6]])
此外还可以把索引和切片结合:
In [22]: arr2d[0, :1]
Out[22]: array([1])
这样就是选择了第一行(通过索引),然后选择了第一行的前一列(通过切片)
切片[:]表示选择所有的数组,通过结合这个操作就可以单纯返回列的切片:
In [23]: arr2d[:, :1]
Out[23]:
array([[1],
[4],
[7]])
我把下面这张图称为:随心所欲想怎么切怎么切
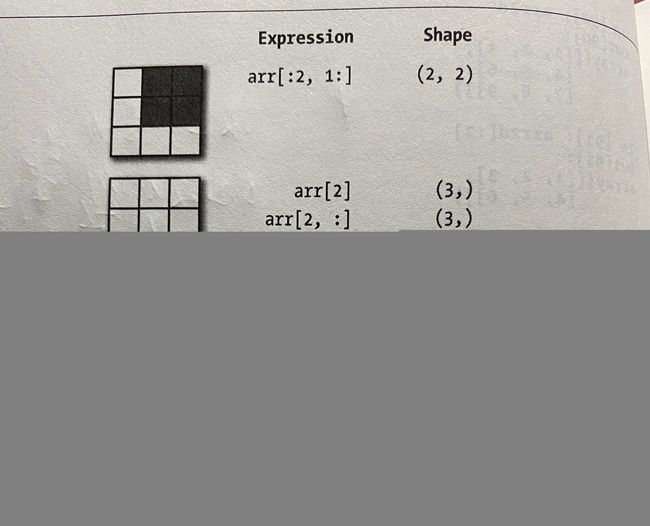
1.5 布尔索引
布尔索引值就是用一些条件判断式来对多维数组进行索引。
比如我们有一个姓名数组,另一个多维数组存储的是相应的不同人的数据(利用numpy.random中的randn函数随机生成正态分布数据):
In [25]: names = np.array(['bob','joe','will','bob','will','joe','joe'])
In [26]: data = np.random.randn(7,4)
In [27]: names
Out[27]: array(['bob', 'joe', 'will', 'bob', 'will', 'joe', 'joe'], dtype=')
In [28]: data
Out[28]:
array([[ 0.33570344, -0.35161261, -1.46194168, -0.09575411],
[ 1.12495352, 1.01942178, -0.57483366, -0.76607756],
[ 0.40598446, -0.26207084, 1.21948522, -0.65978086],
[ 0.1566132 , -0.19558611, 3.31560437, 0.65168252],
[ 0.70533795, -0.02594408, -0.7427101 , 0.99027039],
[ 0.18283008, -0.71197155, 0.8294305 , 0.98896259],
[ 1.69864451, 0.08284518, 0.64629488, -0.6459553 ]])
现在我们只想查看Bob的数据,该怎么索引呢?:
In [30]: data[names == 'bob']
Out[30]:
array([[ 0.33570344, -0.35161261, -1.46194168, -0.09575411],
[ 0.1566132 , -0.19558611, 3.31560437, 0.65168252]])
我们还可以只看Bob的前两项数据:
In [31]: data[names == 'bob', :2]
Out[31]:
array([[ 0.33570344, -0.35161261],
[ 0.1566132 , -0.19558611]])
可以看除了Bob以外的所有人的数据,可以使用!=或者~符号
data[names != 'bob']
data[~(names == 'bob')]
可以选择bob和joe的数据:
In [35]: data[(names == 'bob') |( names == 'joe')]
注意在numpy检索中,python关键字and和or失效,只能使用&,|
除了检索之外,还可以直接把检索出来的结果赋值。
此外,利用布尔值索引选择数据时,总是会生成数据的拷贝,返回的数组不会发生变化。
1.6 神奇检索
之前我们试过了在多维数组方括号[]中加入数字(索引),加入:进行切片,或者加入表达式进行布尔值检索,我们还可以继续加入数组,产生神奇的检索效果:返回符合特定顺序的子集:
array[[3,2,1]] ##按顺序返回第4行、第3行、第2行数据
按照之前的习惯,如果再加入一个数组会怎样?
array[[3,2,1],[1,2,3]]
这时会依次返回元素(3,1),(2,2,),(1,3)
但是如果是想按3,2,1的顺序返回行,再在返回数据中按1,2,3的顺序返回列怎么办?这时候应该使用一次递归:
array[[3,2,1]][:,[1,2,3]]
注意神奇索引与布尔值索引类似,都会返回数据的拷贝。
1.7 数组转置与换轴
数组转置,直接用其特殊的T属性就可以了:
array.T
数组转置后会返回底层数据的视图,不需要进行数据复制。
或者可以使用transpose方法:
arrary.transpose()
而对于高维数据,transpose方法可以接受包含轴编号的元组,用于置换轴:
In [36]: arr = np.arange(16).reshape((2,2,4))
In [37]: arr
Out[37]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
In [38]: arr.transpose((1,0,2))
Out[38]:
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
上述操作中,把原来的1轴和0轴进行了交换
2. 通用函数:向量化计算
常用的通用函数如下:
np.sqrt(arr) #对每个元素求平方根
np.exp(arr) #对每个元素求指数幂
np.add(arr1,arr2) #将两个数组求和,返回一个数组作为结果
np.maximum(arr1,arr2) #求两个数组同一位置上的最大值,返回一个数组作为结果
value1, value2 = np.modf(arr) #返回浮点值数组的小数部分和整数部分
更多的一元和二元通用函数可以见书P108的表4-3和表4-4
3. 使用数组进行面向数组编程
假设我们想要对网格数据进行计算,例如计算 x 2 + y 2 \sqrt{x^2+y^2} x2+y2:
points = np.arange(-5, 5, 0.01)
xs, ys = np.meshgrid(points, points)
这里用到了np.meshgrid(xarray, yarray)函数,这个函数接收两个一维数组作为参数,并且返回两个数组,返回的第一个数组是以xarray为行,一共ydimension行;第二个数组以yarray的转置为列,一共xdimension列。
z = np.sqrt(xs ** 2 + ys ** 2)
3.1 将条件逻辑作为数组操作
numpy.where函数是python内建的x if condition else y的向量化版本:
np.where(cond, xarr, yarr)
这条语句会使得当cond中的元素为真时,返回xarr中的对应元素值,当cond中的元素为假时,返回yarr中的对应元素值。
除此之外np.where的第二个和第三个参数还可以是标量,比如我们要把一个随机生成的数据矩阵中的正值替换为2,负值替换为-2;或者只把正值替换为2,负值不动:
arr = np.random.randn(4,4)
np.where(arr > 0, 2, -2)
np.where(arr > 0, 2, arr)
3.2 数学和统计方法
可以用np.mean(arr)计算数组所有数值的平均数,也可以调用方法arr.mean()计算,还可以在方法中加上可选参数axis,来计算数组在某个方向上的统计值:arr.mean(0),arr.mean(1)
当然除了平均数可以这么用之外,求和sum,求标准差std都可以这么用
还有函数cumsum,是从第一个元素开始累积求和。
我们还可以把数学统计方法和布尔值表达式结合,比如我们要计算某个数组中所有正数的和:
(arr > 0).sum()
3.3 排序
和python一样,在numpy中也是使用sort方法进行排序:
arr = np.random.randn(6)
arr.sort()
而在多维数组中,还可以向sort()方法传递参数,判断是按照哪个轴进行排序
arr = np.random.randn(2,3)
arr.sort(1)
3.4 其他集合逻辑
numpy中还有一些专门针对一维ndarray的操作,例如np.unique,会返回数组中的唯一值:
In [2]: names = np.array([3,3,2,2,1,4,5,])
In [3]: np.unique(names)
Out[3]: array([1, 2, 3, 4, 5])
还有其他很多集合操作,详见书P115的表4-6
4. 线性代数
来看看numpy中的线性代数运算:
x = np.random.randn(2,3)
y = np.random.randn(3,3)
z = np.dot(x,y)
np.dot(x,y)表示对x,y做点乘,也可以写成x.dot(y)
注意如果是x * y,做的是向量化运算(即每个元素相乘)
如果要做其他的线性代数运算,需要利用np.linalg函数集:
np.linalg.det(x) ## 计算矩阵的行列式
np.linalg.diag(x) ## 将方阵的对角元素作为一维数组返回
np.linalg.trace(x) ## 计算矩阵的迹
np.linalg.inv(x) ## 计算矩阵的逆矩阵
5. 示例:随机漫步
import random
import matplotlib.pyplot as plt
position = 0
walk = [position]
steps = 1000
for i in range(steps):
step = 1 if random.randint(0,1) else -1
position += step
walk.append(position)
plt.plot(walk[:100])
plt.show()

这个是纯python风格的代码,如果想要进行大量计算,还是用numpy比较好:
import numpy as np
nsteps = 1000
draws = np.random.randint(0, 2, size = nsteps)
steps = np.where(draws > 0, 1, -1)
walk = steps.cumsum()
plt.plot(walk)
plt.show()
这里的np.where函数就比较有灵性,省掉了if判断语句,而且对于累计求和直接用cumsum函数代替
利用numpy我们可以同时模拟多次随机漫步:
import numpy as np
nsteps = 1000
nwalks = 5000
draws = np.random.randint(0, 2, size = (nwalks, nsteps))
steps = np.where(draws > 0, 1, -1)
walk = steps.cumsum(1)
pandas入门
1.pandas数据结构
1.1 series
series类型与数组有些相似,每个数据都对应着一个索引值。
In [1]: import pandas as pd
In [2]: obj = pd.Series([4, 7, -5, 3])
In [3]: obj
Out[3]:
0 4
1 7
2 -5
3 3
dtype: int64
对于Series对象,可以用value和index属性获得对象的值和索引。
除此之外,我们还可以自己定义索引值,并通过索引值直接访问对象。
In [4]: obj = pd.Series([4, 7, -5, 3], index = ['a', 'b', 'c', 'd'])
In [5]: obj.index
Out[5]: Index(['a', 'b', 'c', 'd'], dtype='object')
In [7]: obj['a']
Out[7]: 4
可以使用Numpy风格的操作,比如利用布尔值数组进行过滤,或者进行向量化计算:
In [8]: obj[obj > 0]
Out[8]:
a 4
b 7
d 3
dtype: int64
In [9]: obj * 2
Out[9]:
a 8
b 14
c -10
d 6
dtype: int64
In [10]: import numpy as np
In [11]: np.exp(obj)
Out[11]:
a 54.598150
b 1096.633158
c 0.006738
d 20.085537
dtype: float64
我们可以把Series看作是一种字典。因此如果已经在Python内置数据结构中生成了一个字典,可以利用该字典生成Series。
我们还可以设定好index数组的内容,并传入该字典中,使得字典的输出内容以我们输入的index为序。
In [12]: sdata = {'Ohio': 35000, 'Texas': 710000}
In [13]: obj2 = pd.Series(sdata)
In [14]: obj2
Out[14]:
Ohio 35000
Texas 710000
dtype: int64
In [15]: states = ['California', 'Ohio', 'Texas']
In [16]: obj3 = pd.Series(sdata, index = states)
In [17]: obj3
Out[17]:
California NaN
Ohio 35000.0
Texas 710000.0
dtype: float64
此外我们还可以检验Series中是否存在缺失值,检验方法有两种:
- 利用
pandas中的isnull和notnull函数; - 利用
Series的isnull和notnull方法。
对Series之间的运算跟数据库的join操作有些类似,类似于full join。
Series自身和索引还有一个重要的属性:name,可以将这个属性理解为Series自己的名称:
In [18]: obj3.name = 'population'
In [21]: obj3.index.name = 'state'
In [22]: obj3
Out[22]:
state
California NaN
Ohio 35000.0
Texas 710000.0
Name: population, dtype: float64
1.2 DataFrame
dataframe数据类型有点像R里的数据框,它是已排序的列集合,可以被视作是一个共享共同索引的Series的字典。
创建dataframe的方法有很多,最常用的是利用包含等长列表或numpy数组的字典来形成dataframe,然后可以通过指定参数columns来按照指定顺序排列,并且用index把列的顺序传给dataframe,如果index中有某一列不包含在字典中,结果中会出现缺失值。
data = {
'state': ['a', 'b', 'c', 'd'],
'year': [1,2,3,4],
'pop': [1.5,1.7,1.8,2.0]
}
frame = pd.DataFrame(data, columns = ['year', 'state', 'pop'],/
index = ['one', 'two', 'three', 'four'])
输出的dataframe是这样的:

另外一种创建dataframe的方法是利用包含字典的嵌套字典:
pop = {
'Nevada': {2001 : 2.4, 2002 : 2.9},
'Ohio': {2000 : 1.5, 2001 : 1.7, 2002 : 3.6}
}
frame2 = pd.DataFrame(pop)
用这个方法创建dataframe时,列是字典的键,索引是内部字典的键。输出结果为:

在dataframe中,我们可以直接检索出某一列,检索方法有两种:
- 像字典一样检索
frame['year'] - 利用属性检索
frame.year
可以直接对列的值进行修改,但是注意修改时长度必须要匹配,否则会报错。
frame['pop'] = 16.5
frame['pop'] = np.arange(4.)
此外还可以将一组Series的值赋给dataframe,且可以指定index值,未指定的index会填充缺失值。如果被赋值的列不存在时会创建新列。注意只有用检索方法才能创建新列,属性方法不能创建新列。
val = pd.Series([-1.2,-1.5,-1.7], index = ['two', 'four', 'five'])
frame.pop = val
和series类似,dataframe也有name属性,比如我们可以分别给索引和列指定name:
frame2.index.name = 'year'
frame2.columns.name = 'state'
而dataframe的values属性会将包含在dataframe中的数据以二维ndarray的形式返回。
从dataframe中选取的列是数据框的视图,不是数据框的拷贝,对选取列的修改会直接影响dataframe,如果需要复制则需要使用copy方法。
可以使用类似Numpy的方法对dataframe进行矩阵操作,如转置,此时会把列和索引进行调换。
frame2.T
1.3 索引对象
在pandas中,索引也是作为一个对象存在的,可以将其看作是不可修改的数组,甚至可以对它进行切片。
obj = pd.Series(range(3), index = ['a', 'b', 'c'])
index = obj.index
index[1:]
在pandas中创建索引对象的方法是用Index函数:
labels = pd.Index(np.arange(3))
obj2 = pd.Series(range(3), index = labels)
有个需要注意的小点是,在pandas中,索引名可以重复。
2. 基本功能
2.1 重建索引
reindex方法可以将已经编制好的Series按照新的索引进行排列,当索引值之前不存在时,将会引入缺失值。
import pandas as pd
obj = pd.Series([4, 7, -2, 3], index = ['d', 'b', 'a', 'c'])
obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e'])
reindex方法中还有一个method方法,它允许我们再重建索引时按照合适的方法对数据进行插补,如:使用ffill方法,将值前项填充
obj = pd.Series([4,5,6,1], index = [1, 4, 5, 7])
obj2 = obj.reindex(range(8), method = 'ffill')
除了Series,reindex还可以对DataFrame使用:
比如我们先创建一个DataFrame
frame = pd.DataFrame(np.arange(9).reshape((3,3)),
index = ['a', 'c', 'd'],
columns = ['O', 'T', 'C'])
然后可以分别改变DataFrame的行索引和列索引,如果只有一个参数时,默认重建行索引。
frame2 = frame.reindex(['a', 'b', 'c', 'd'])
frame.reindex(colunmns = ['T', 'U', 'C'])
一种更为便捷的索引方式是使用loc方法:
frame.loc[['a','b','c','d'], ['T','U','C']]
2.2 删除条目
使用drop方法可以删除某个轴向的一整条数据,它会返回一个新对象,如果加上inplace参数,则会清除被删除的数据。
例如在Series中
obj = pd.Series([4,5,6,1], index = [1, 4, 5, 7])
obj2 = obj.reindex(range(8), method = 'ffill')
obj2.drop(1, inplace = True)
在DataFrame中同理,只不过优先删除行向上的数据,列向上的数据需要通过指定参数axis = 'columns'来完成。
2.3 索引、选择、过滤
在Series中进行索引与在Numpy数组中进行索引操作相似,只是Series可以同时使用数字(行号)和索引值进行索引,此外也可以用表达式进行索引。还有一个需要注意的问题是Series进行索引时是包含最后一项值的。
在DataFrame中,情况有所不同,
In [23]: data = pd.DataFrame(np.arange(16).reshape((4,4)),
...: index = ['O','C','U','N'],
...: columns = ['one','two','three','four'])
In [24]: data
Out[24]:
one two three four
O 0 1 2 3
C 4 5 6 7
U 8 9 10 11
N 12 13 14 15
In [25]: data['two']
Out[25]:
O 1
C 5
U 9
N 13
Name: two, dtype: int64
In [26]: data[['four','one']]
Out[26]:
four one
O 3 0
C 7 4
U 11 8
N 15 12
In [30]: data[:2]
Out[30]:
one two three four
O 0 1 2 3
C 4 5 6 7
In [33]: data[data['three'] > 5]
Out[33]:
one two three four
C 4 5 6 7
U 8 9 10 11
N 12 13 14 15
In [35]: data > 5
Out[35]:
one two three four
O False False False False
C False False True True
U True True True True
N True True True True
In [36]: data[data > 5] = 0
In [37]: data
Out[37]:
one two three four
O 0 1 2 3
C 4 5 0 0
U 0 0 0 0
N 0 0 0 0
这里有点Numpy中数组操作的感觉。
再介绍两种索引方法:loc, iloc,其中loc可以使用轴标签进行索引,iloc可以使用整数标签进行索引。
data.loc['C', ['two', 'three']]
data.iloc[[1,2], [3,0,1]]
甚至可以用这两种索引符号进行切片索引
data.loc[:'U', 'two']
data.iloc[:, :3][data.three > 5]
2.4 算术和整数对齐
在pandas中,可以对不同索引的对象进行算术运算,如果存在索引值对不相同的情形,将会把两个对象取并集,即类似于数据库中out join
对于dataframe来说,如果行或列上存在不匹配,都会执行数据对齐操作(即分别取并集)。
取并集的结果就是会出现缺失值标记NaN,影响后续计算,比如我们希望缺失值可以被视作0看待,进行后面的计算,此时就行不通了。
那么接下来考虑一下如何对默认设置的缺失值进行填充。方法就是在某个dataframe上使用以下方法,并指定参数fill_value
| 方法 | 描述 |
|---|---|
| add | + |
| sub | - |
| div | / |
| floordiv | // |
| mul | * |
| pow | ** |
例如我们可以用
df1.add(df2, fill_value = 0)
就是把df2中的缺失值标记为0
那如果是对dataframe和series之间进行运算会有什么结果?看一个例子:
frame = pd.DataFrame(np.arange(12.).reshape((4,3)),
columns = list("bde"),
index = ['U', 'O', 'T', 'I'])
series = frame.iloc[0]
print(frame - series)
运算结果如下,dataframe的列会与series的索引进行匹配:
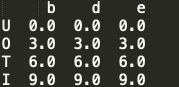
可以看到frame中的每一行都减去了series,这就是所谓广播机制。
注意两点:
- dataframe与series必须要匹配上,对于没有匹配上的会设置成
NaN - 默认情况是对行进行广播,如果想要对列进行广播,必须要使用算术方法,并且要指定参数
series2 = frame.iloc[:,1]
frame.sub(series2, axis = 'index')
2.5 函数应用和映射
- 一般numpy中的函数对pandas对象也有效
- 可以将函数应用到某一行或一列的一维数组上,使用datafrmae中的
apply方法,默认是对列进行处理。如果需要对行进行处理,可以指定参数axis = 'columns'
def f(x):
return x.max() - x.min()
frame.apply(f)
除了这么用之外,还可以返回一个series
def f2(x):
return pd.Series([x.min(), x.max()], index = ['min', 'max'])
frame.apply(f2)
- 如果需要按元素使用函数,那么可以对dataframe用
applymap方法,而对于series,我们可以用map方法。
2.6 排序和排名
- 使用
sort_index方法可以对series或dataframe按照索引值进行排序,在dataframe中默认对index进行排序,如果需要对columns进行排序,需要额外指定参数frame.sort_index(axis = 1) - 一般默认按照升序排序,如果需要按照降序排序,需要额外指定参数
frame.sort_index(ascending = False) - 如果需要对series的值进行排序,使用
sort_values方法,默认会把缺失值放在尾部。 - 在对dataframe的值进行排序时,需要指定要排序的列,并且排序有先后顺序,
frame.sort_values(by = ['a', 'b'])
- 排名可以返回给定series中每个数据的相对大小,使用内置的
rank()方法实现,同时如果有相同值,会默认进行平均化 - 如果不希望进行平均化处理,加入参数
rank(method = 'first'),相同数字出现在前面的序号较低 - 默认从低到高进行排名,越大的值排名越高,也可以通过制定参数
ascending = False进行调整 - 也可以对dataframe进行排名,但需要指定是行还是列:
frame.rank(axis = 'columns')
3. 描述性统计
- pandas中可以对dataframe按照行或者列进行聚合计算,并且计算中缺失值是被默认忽略的,例如
frame.sum(),可以返回每一列的总和,frame.sum(axis = 'columns')可以返回每一行的和 - 可以直接求列的最大值或最小值,
frame.idxmax()或frame.idxmin() - 可以求累加和
frame.cumsum(),但是这里不会替代原本的缺失值 - 使用函数
frame.descirbe()可以自动返回每一列的很多有关统计量的值。 - 更多的操作方法见书籍P159的表5-8
3.1 相关性和协方差
- 计算两列之间的相关系数:
frame['O'].corr(frame['I]) - 计算两列之间的协方差:
frame['O'].cov(frame['I']) - 计算协方差矩阵:
frame.cov() - 计算相关系数矩阵:
frame.corr() - 采用
corrwith方法,可以计算一个dataframe中的每一列与传入的某个series的相关系数frame.corrwith(frame['I'])
3.2 其他方法
- 返回一组数据的不重复集合:
series.unique(),返回结果是数组。 - 对series的值进行计数:
series.value_counts(),也可以使用value_counts()函数,将值作为参数 - 计算某个数字是否属于series,并且返回对应的项:
mask = series.isin(['b','c'], series[mask]
数据载入、存储、文件格式
1.文本格式数据读写
利用pandas中的解析函数可以读入大部分格式的数据。例如利用read_csv读入CSV格式数据,其中以逗号作为默认分隔符,利用read_table读入以制表符为默认分隔符的文件,read_excel从excel的xls或xlsx中读取表格数据。
讨论几种情况:
- 用
read_table读入以逗号为分隔符的文件,需要修改参数sep,pd.read_table("filename", sep = ',')。如果分隔符是不同数量的空格,则需要使用正则表达式作为分隔符,pd.read_table("filename", sep = "\s+") - 如果原始文件不包含标题行,需要指定参数
header,`pd.read_csv(“filename”, header = None) - 如果原始文件不包含标题行,还可以通过参数
names自己指定,pd.read_csv("filename", names = [ ...] - 若文件中有一列为索引列,又缺少标题行,则需要先指定标题,然后确定索引列
names = ['a','b',message], pd.read_csv("filename", names = names, index_col = 'message') - 此外还可以指定两列为索引列,形成分层索引
1.1 分块读入文本文件
一种常见的情况是需要处理的文件是大文件,此时只需要读入文件中的一个小片段,或者按照片段遍历整个文件。
通常为了屏幕上能把一个观测的数据完整展现出来,设置pd.options.display.max_rows = 10。
想要读取部分文件,指定参数nrows =。
在分块读入数据时,通过指定参数chunksize,确定每一块的行数,此时会返回TextParser对象,能够根据chunksize遍历文件。
chunker = pd.read_csv("filename", chunksize = 1000)
tot = pd.Series([])
for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value = 0)
tot = tot.sort_values(ascending = False)
1.2 将数据写入文本
现在看看如何导出数据。
对于dataframe数据,用to_csv方法即可导出:data.to_csv("filename")
这种输出方式的分隔符默认为逗号,可以控制用其他的分隔符进行代替,此外如果有缺失值,在文本中是默认用空格表示的,可以替换成其他标注方式。
import sys
data.to_csv(sys.stdout, sep = "|", na_rep = "NULL")
## sys.stdout的意思是直接观察控制台中打印的文本效果
也可以指定不输出行、列标签信息,或者只输出某些列
data.to_csv(sys.stdout, index = False, header = False)
data.to_csv(sys.stdout, index = False, columns = ['a', 'b', 'c'])
1.3 使用分隔格式
一般来说观测都是按行记录的,如果碰到按列记录的情况该怎么处理?例如
| a | b |
|---|---|
| 1 | 2 |
| 1 | 3 |
如果一个文件中只有单字符分隔符,可以使用Python内建的csv版块
with open("examples/ex7.csv") as f:
lines = list(csv.reader(f))
然后提取出标题行和数据行
header, values = lines[0], lines[1:]
然后就可以生成一个包含观测的字典了:
data_dict = {h : v for h, v in zip(header, zip(*values))}
其中zip(*values)表示对values的解压
>>> a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,可理解为解压,为zip的逆过程,可用于矩阵的转置
[(1, 2, 3), (4, 5, 6)]
2.其他格式
2.1 读取Excel文件
frame = pd.read_excel("filenmae", "sheet1")
如果需要将数据写入excel,则需要先生成一个ExcelWriter,然后利用对象的to_excel方法写入数据。
writer = pd.ExcelWriter("filename")
frame.to_excel(writer, "sheet1")
或者直接写成
frame.to_excel("filename")
数据清洗与准备
1. 缺失值
1.1 过滤缺失值
在pandas中,为了返回一个series中所有的非空数据及其索引,可以使用dropna方法。
data = pd.Series([1, NA, 3.5, NA, 7])
data.dropna()
但是在dataframe中就相对比较麻烦,因为对于dataframe,默认删除含有缺失值的所有行。如果只想删掉全部数据都是NA的行,需要添加参数how,如果需要删除全部数据都是NA的列,需要添加参数axis
data.dropna(how = "all")
data.dropna(how = 'all', axis = 1)
我们还可以再个性化一点,例如设置如果缺失值大于等于2,就删除该条观测,通过指定thresh参数:
data.dropna(thresh = 2)
1.2 缺失值填补
通过调用fillna()方法补全缺失值,可以指定一个常数来填补缺失值,再个性化一点,可以对不同的列指定不同的填补常数(参数为字典),当然最常用的方法是利用均值进行填补
df.fillna(0)
df.fillna({1 : 0.5, 2 : 0})
data = pd.Series([1., NA, 3.5, NA, 7])
data.fillna(data.mean())
通过fillna方法,返回一个新的对象,如果想要对原始数据进行修改,可以添加inplace = True参数。
2. 数据转换
2.1 删除重复值
在dataframe中,可以用duplicated方法返回一个布尔型series,可以说明dataframe中每一行之间是否存在重复。而用drop_duplicates可以删掉重复的观测。
当然也可以不检测所有的列是否存在重复,可以单独指定某个列,这样只会保留该列中的不重复观测frame.drop_duplicates(['k1'])
判断和删除重复值时,默认保留第一个观测的值,如果要保留最后的值,可以传入参数keep = 'last'。
2.2 使用函数或映射进行数据转换
series的map方法接收一个函数或一个包含映射关系的字典型对象,从而可以进行键值对匹配。
例如dataframe中储存量一些肉和它们的重量,现在要增加一列:每种肉的类型,因此需要新建一列data['animal']
data['animal'] = data['food'].map(meat_to_animal)
2.3 替代值
data.replace({-999 : np.nan, -1000 : 0})
这样就可以把series中的-999替换成缺失值,-1000替换成0.
2.4 重命名轴索引
假设我们想把dataframe的index都变成大写字母,有以下两种方法:
- 使用map方法
- 使用rename方法
data = pd.DataFrame(np.arange(12).reshape(3,4),
index = ['Ohio', 'Colorado', 'Newyork'],
columns = ['one', 'two', 'three', 'four']
transform = lambda x : x[:4].upper()
# 使用map方法
data.index = data.index.map(transform)
# 使用rename方法
data.rename(index = str.upper)
此外还可以通过rename方法单独对某个index或columns进行重命名,只需在参数里传入一个字典就可以了:
data.rename(index = {'Ohio' : 'INDIANA'},
columns = {'three' : 'peekaboo'})
如果想要对原数据集进行修改,参数中传入inplace = True。
2.5 离散化和分组
假如有一组关于年龄的数据ages,需要把这组数据按照年龄段进行划分,则需要用到cut函数,第一个参数是原始数据,第二个参数是需要分组的节点。
bins = [18, 25, 35, 60, 100]
cats = pd.cut(ages, bins)
这个函数返回的对象,是原始数组ages中每个数据对应的组,可以通过cats.codes查看每个数据的组别,通过cats.categories查看一共有几个组,pd.value_counts(cats)查看每一组中元素的个数。