Java Study Notes_Design in 2023(Day15~)
文章目录
- Day15: 集合进阶(异常、集合)
-
- 15.1 认识异常
- 15.2 自定义异常
- 15.3 异常处理
- 15.4 集合概述和分类
-
- 15.4.1 集合名称图
- 15.4.2 集合分类(单列Collection、双列Map集合)
- 15.4.3 Collection单链集合及其实现类
- 15.4.4 Collection单链集合子接口list集合,set集合特点
- 15.5 Collection集合的常用方法
- 15.6 Collection集合遍历方式
-
- 15.6.1 迭代器遍历集合
- 15.6.2 增强for遍历集合
- 15.6.3 forEach遍历集合
- 15.7 Collection集合子接口之List单链集合
-
- 15.7.1 List集合的常用方法
- 15.7.2 ArrayList底层的原理
- 15.7.3 LinkedList底层原理
- 15.7.4 LinkedList集合特点,应用其设计栈、队列结构
- Day16: 集合进阶(Set、Map集合)
-
- 16.1 Set集合特点
-
- 16.1.1 HashSet集合底层原理
- 16.1.2 HashSet去重机制
- 16.1.3 LinkedHashSet集合
- 16.1.4 TreeSet集合
-
- 16.1.4.1 强制排序,不重复,无索引
- 16.1.4.2 存自定义类,要指定排序规则 (否则报错).
-
- 16.1.4.2.1 报错案例演示
- 16.1.4.2.2 指定排序规则——自然排序(Comparable)
- 16.1.4.2.3 指定排序规则——比较器排序(Comparator)
- 16.1.4.2.4 自然排序(Comparable)和比较器排序(Comparator)区别
- 16.2 Collection集合小结
- 16.3 并发修改异常
- 16.4 可变参数
- 16.5 Collections集合工具类
- 16.6 Map集合及其的三种遍历方法
-
- 16.6.1 Map集合
- 16.6.2 Map集合常用方法
- 16.6.3 Map遍历1: 通过键获取对应的值
- 16.6.4 Map遍历2: 通过键值对分别获取键和值
- 16.6.5 Map遍历3: forEach
- 16.6 Map集合统计投票人数案例
- Day19:IO流2
-
- 19.1 字符流
-
- 19.1.1 字符输入流
- 19.1.2 字符输出流
- 19.1.3 字符输出流注意
- 19.2 缓冲流
-
- 19.2.1 字节缓冲流
- 19.2.2 字符缓冲入流
- 19.2.3 字符缓输出流
- 19.2.4 原始流缓冲流性能分析
- 19.3 字节流
-
- 19.3.1 字节输入转换流
- 19.3.2 字节输出转换流
- 19.4 打印流
-
- 19.4.1 打印流应用
- 19.5 数据流
- 19.6 序列化流
- 19.7 IO框架
- Day20:特殊文件、日志技术、多线程
-
- 20.1 Properties属性文件
- 20.2 XML文件
-
- 20.2.1 XML解析1(基于DOM4J解析框架)
- 20.2.2 XML文件写入
- 20.2.3 XML约束
- 20.3 日志技术
-
- 20.3.1 日志框架与日志接口
- 20.3.2 Logback快速入门
- 20.3.3 日志配置文件
- 20.3.4 配置日志级别
- 20.4 多线程
-
- 20.4.1 线程创建方式1
- 10.4.2 线程创建方式2
- 20.4.3 线程创建方式3—匿名内部类(基于方式一、二)
- Day23:单元测试、反射、注解、动态代理
-
- 23.4 动态代理
-
- 23.4.1 动态代理介绍、准备功能
- 23.4.2 生成动态代理对象、invoke方法
Day15: 集合进阶(异常、集合)
15.1 认识异常
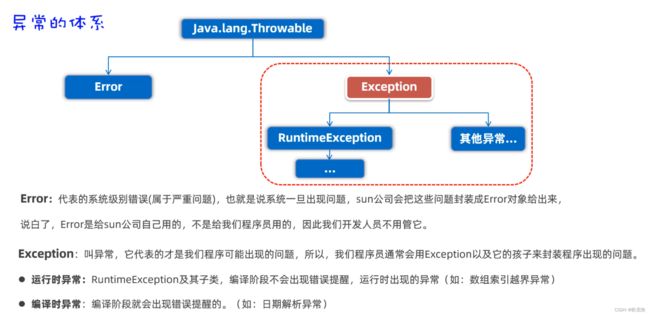
编译时异常的目的:意思就是告诉你,你小子注意了!!,这里小心点容易出错,仔细检查一下
15.2 自定义异常
自定义异常步粟
1.定义一个异常类,见名知意
2.继承RuntimeExceptionlException
3.提供空参和带参构造
package com.sesameseed.d1_exception.demo1;
/*
自定义异常步粟
1.定义一个异常类,见名知意
2.继承RuntimeExceptionlException
3.提供空参和带参构造
*/
public class AgeOutOfBoundException extends Exception{
public AgeOutOfBoundException() {
}
public AgeOutOfBoundException(String message) {
super(message);
}
}
package com.sesameseed.d1_exception.demo1;
/*
自定义异常步骤
1.定义一个异常类,见名知意
2.继承RuntimeExceptionlException
3。提供空参和带参构造
*/
public class AgeOutOfBoundRuntimeException extends Throwable {
public AgeOutOfBoundRuntimeException() {
}
public AgeOutOfBoundRuntimeException(String message) {
super(message);
}
}
到main方法中不能再抛了 :因为会抛向JVM虚拟机,JVM输出异常信息;结束程序
package com.sesameseed.d1_exception.demo1;
public class Demo {
// public static void main(String[] args) throws AgeOutOfBoundRuntimeException { 不能再抛了 :因为会抛向JVM虚拟机,JVM输出异常信息;结束程序
public static void main(String[] args) {
try {
//try的括号中包裹可能出现异常的代码
setAge(180);
// } catch (AgeOutOfBoundRuntimeException e) { //运行时异常
} catch (AgeOutOfBoundException e) { //编译时异常
//我们自己处理异常的代码
System.out.println("你输入的年龄有误");
}
System.out.println("执行了");
}
// //运行时异常
// private static void setAge(int age) throws AgeOutOfBoundRuntimeException {
// if (age < 0 || age > 120){
// System.out.println("你输入的age有误");
// throw new AgeOutOfBoundRuntimeException("你输入的age有误");
// }else {
// System.out.println(age + "正确");
// }
// }
//编译时异常
private static void setAge(int age) throws AgeOutOfBoundException {
if (age < 0 || age > 120){
//1.之前控制台提示错误,不是真正的告诉调用者
//System.out.println("你输入的age有误!")
//2.throw关键字抛出异常对象(用在方法里面)
System.out.println("你输入的age有误");
throw new AgeOutOfBoundException("你输入的age有误");
}else {
System.out.println(age + "正确");
}
}
}
15.3 异常处理
比如有如下的场景:A调用用B,B调用C;C中有异常产生抛给B,B中有异常产生又抛给A;异常到了A这里就不建议再抛出了,因为最终抛出被JVM处理程序就会异常终止,并且给用户看异常信息,用户也看不懂,体验很不好。
此时比较好的做法就是:1.将异常捕获,将比较友好的信息显示给用户看;2.尝试重新执行,看是是否能修复这个问题。
package com.sesameseed.d1_exception.demo2;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
public class Test {
public static void main(String[] args) {
// try {
test();
// } catch (FileNotFoundException e) {
e.printStackTrace(); 页面显示异常方法,没学过,先注释掉
// System.out.println("文件找不到异常:解决方案1");
// }
}
private static void test() { //throws 会抛出,下方代码不会再执行
try {
new SimpleDateFormat("yyyy-MMM-dd HHH-mm-ss").parse("2023年1月19日 11:54:40");
} catch (ParseException e) {
System.out.println("时间格式异常");
// e.printStackTrace();
}
test2();
}
private static void test2() {
try {
FileInputStream file = new FileInputStream("C:\\momo");
} catch (FileNotFoundException e) {
// e.printStackTrace();
System.out.println("文件找不到异常:解决方案1");
}
}
}
15.4 集合概述和分类
15.4.1 集合名称图
注意:vector是线程安全的,默认长度10,扩容2倍。
15.4.2 集合分类(单列Collection、双列Map集合)

15.4.3 Collection单链集合及其实现类
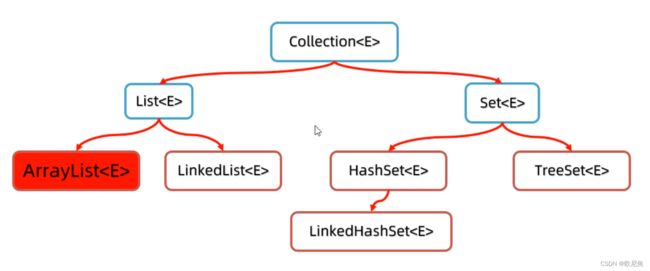
15.4.4 Collection单链集合子接口list集合,set集合特点

//简单确认一下Collection集合的特点
ArrayList<String> list = new ArrayList<>(); //存取顺序一致,可以重复,有索引
list.add("java1");
list.add("java2");
list.add("java1");
list.add("java2");
System.out.println(list); //[java1, java2, java1, java2]
HashSet<String> list = new HashSet<>(); //存取顺序不一致,不重复,无索引
list.add("java1");
list.add("java2");
list.add("java1");
list.add("java2");
list.add("java3");
System.out.println(list); //[java3, java2, java1]
15.5 Collection集合的常用方法
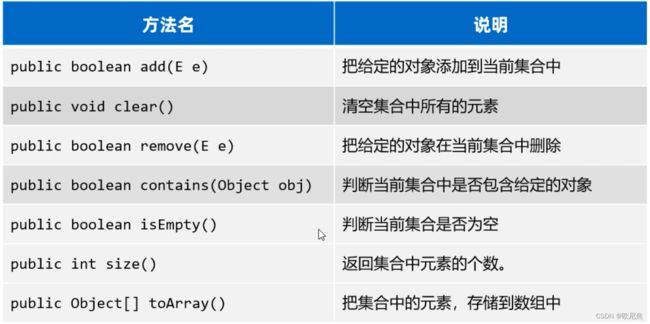
package com.sesameseed.d2_Collection;
import java.util.ArrayList;
import java.util.Collection;
public class Test {
public static void main(String[] args) {
// 创建collection集合对象
Collection<String> c = new ArrayList<>(); //多态的思想
//把给定的对象添加到当前集合中
c.add("张三");
c.add("李四");
c.add("王五");
System.out.println(c);
//清空集合中所有的元素
// c.clear();
// System.out.println(c);
//把给定的对象在当前集合中删除
System.out.println(c.remove("张三")); //true
//判断当前集合中是否包含给定的对象
System.out.println(c.contains("张三")); //false
//返回集合中元素的个数
System.out.println(c.size()); //2
//判断当前集合是否为空
System.out.println(c.isEmpty());//false
//把集合中的元系,存储到数组中
Object[] objects = c.toArray();
//遍历数组
for (int i = 0; i < objects.length; i++) {
System.out.println("遍历出" + objects[i]);
}
}
}
15.6 Collection集合遍历方式
15.6.1 迭代器遍历集合
迭代器代码的原理如下:
- 当调用iterator()方法获取迭代器时,当前指向第一个元素
- hasNext()方法则判断这个位置是否有元素,如果有则返回true,进入循环
- 调用next()方法获取元素,并将当月元素指向下一个位置,
- 等下次循环时,则获取下一个元素,依此内推

package com.sesameseed.d2_Collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
* 送代器相关方法
Iteratoriterator(); 获取送代器象
* boolean hasNext(); 判断当前位置是否有元素可以取出
* E next(),返回当前位置的元素,并将送代器后移一位
* */
public class Test2 {
public static void main(String[] args) {
//准备数据
Collection<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
//送代器遍历集合
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
15.6.2 增强for遍历集合
增强for底层封装了一个送代器(反编译看),能进一步简化遍历的代码
package com.sesameseed.d3_foreach;
import java.util.ArrayList;
import java.util.Collection;
public class Test {
public static void main(String[] args) {
//增强for循环
// 遍历数组和集台
// 增强for底层封装了一个送代器(反编译看),能进一步简化遍历的代码
Collection<String> c = new ArrayList<>(); //多态的思想
//把给定的对象添加到当前集合中
c.add("张三");
c.add("李四");
c.add("王五");
//增强for遍历 ,(反编译看)
for (String s : c) {
//s 依次代表集合中每一个元素
System.out.println(s);
}
}
}
15.6.3 forEach遍历集合

package com.sesameseed.d3_foreach;
import java.util.ArrayList;
import java.util.Collection;
import java.util.function.Consumer;
public class Test2 {
public static void main(String[] args) {
//for - each 循环
//准备数据
Collection<String> c = new ArrayList<>(); //多态的思想
//把给定的对象添加到当前集合中
c.add("张三");
c.add("李四");
c.add("王五");
//for-Each遍历- 匿名内部类(简化代码)
c.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
System.out.println("================");
//forEach遍历 - Lambda(继续简化)
c.forEach(s -> System.out.println(s));
System.out.println("================");
//forEach遍历· -方法引用(继续简化)
c.forEach(System.out::println);
}
}
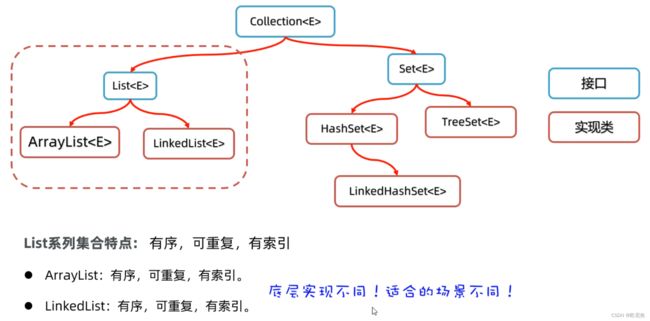
15.7 Collection集合子接口之List单链集合
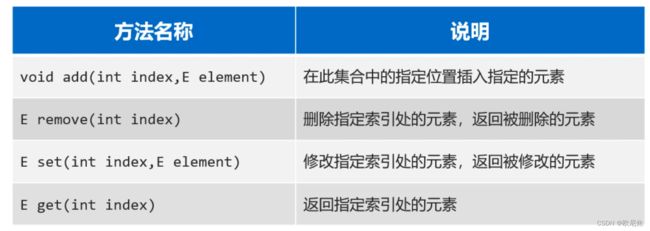
15.7.1 List集合的常用方法
//1.创建一个ArrayList集合对象(有序、有索引、可以重复)
List<String> list = new ArrayList<>();
list.add("蜘蛛精");
list.add("至尊宝");
list.add("至尊宝");
list.add("牛夫人");
System.out.println(list); //[蜘蛛精, 至尊宝, 至尊宝, 牛夫人]
//2.public void add(int index, E element): 在某个索引位置插入元素
list.add(2, "紫霞仙子");
System.out.println(list); //[蜘蛛精, 至尊宝, 紫霞仙子, 至尊宝, 牛夫人]
//3.public E remove(int index): 根据索引删除元素, 返回被删除的元素
System.out.println(list.remove(2)); //紫霞仙子
System.out.println(list);//[蜘蛛精, 至尊宝, 至尊宝, 牛夫人]
//4.public E get(int index): 返回集合中指定位置的元素
System.out.println(list.get(3));
//5.public E set(int index, E e): 修改索引位置处的元素,修改后,会返回原数据
System.out.println(list.set(3,"牛魔王")); //牛夫人
System.out.println(list); //[蜘蛛精, 至尊宝, 至尊宝, 牛魔王]
15.7.2 ArrayList底层的原理
ArrayList集合底层是基于数组结构实现的,也就是说当你往集合容器中存储元素时,底层本质上是往数组中存储元素。
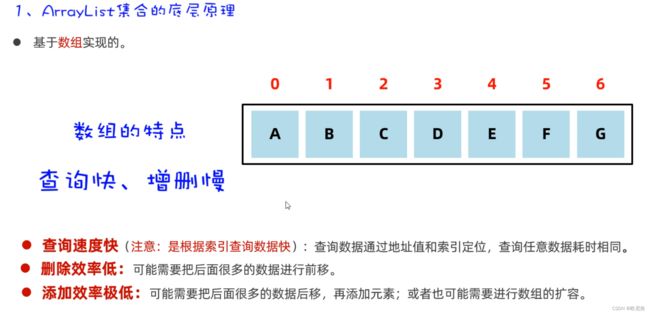
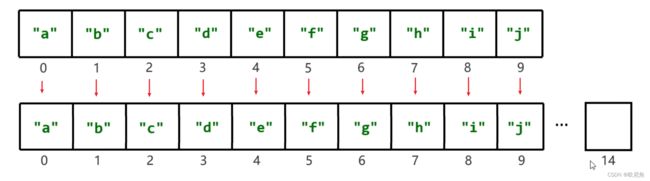
我们知道数组的长度是固定的,但是集合的长度是可变的,原理如下:
数组扩容,并不是在原数组上扩容(原数组是不可以扩容的),底层是创建一个新数组,然后把原数组中的元素全部复制到新数组中去。

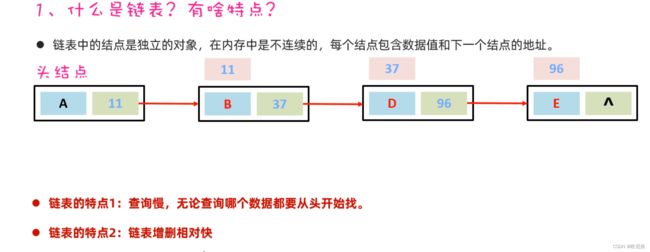
15.7.3 LinkedList底层原理
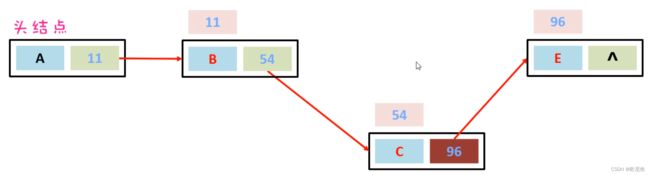
LinkedList底层是链表结构,链表结构是由一个一个的节点组成,一个节点由数据值、下一个元素的地址组成。如下图所示
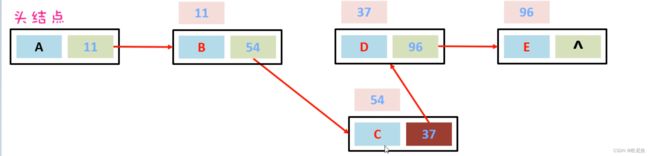
假如,现在要在B节点和D节点中间插入一个元素,只需要把B节点指向D节点的地址断掉,重新指向新的节点地址就可以了。如下图所示:
假如,现在想要把D节点删除,只需要让C节点指向E节点的地址,然后把D节点指向E节点的地址断掉。此时D节点就会变成垃圾,会把垃圾回收器清理掉。
上面的链表是单向链表,它的方向是从头节点指向尾节点的,只能从左往右查找元素,这样查询效率比较慢;还有一种链表叫做双向链表,不光可以从做往右找,还可以从右往左找。如下图所示:
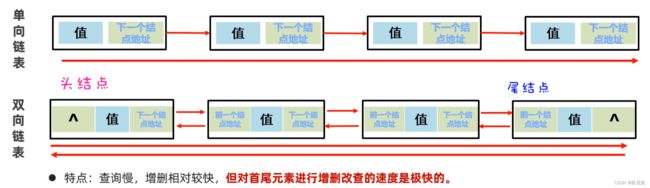
ArrayList针对头尾进行操作方法
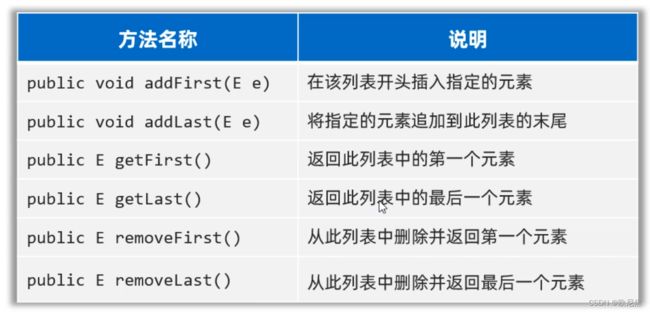
15.7.4 LinkedList集合特点,应用其设计栈、队列结构
LinkedList集合的底层是链表结构实现的,所以可以模拟栈(先进后出)和队列(先进先出)
队列结构:
队列:先进先出、后进后出
//1.创建一个队列:先进先出、后进后出
LinkedList<String> queue = new LinkedList<>();
//入对列
queue.addLast("第1号人");
queue.addLast("第2号人");
queue.addLast("第3号人");
queue.addLast("第4号人");
System.out.println(queue);
//出队列
System.out.println(queue.removeFirst()); //第4号人
System.out.println(queue.removeFirst()); //第3号人
System.out.println(queue.removeFirst()); //第2号人
System.out.println(queue.removeFirst()); //第1号人
栈结构
栈(先进后出)
//1.创建一个栈对象
LinkedList<String> stack = new ArrayList<>();
//压栈(push) 等价于 addFirst()
stack.push("第1颗子弹");
stack.push("第2颗子弹");
stack.push("第3颗子弹");
stack.push("第4颗子弹");
System.out.println(stack); //[第4颗子弹, 第3颗子弹, 第2颗子弹,第1颗子弹]
//弹栈(pop) 等价于 removeFirst()
System.out.println(statck.pop()); //第4颗子弹
System.out.println(statck.pop()); //第3颗子弹
System.out.println(statck.pop()); //第2颗子弹
System.out.println(statck.pop()); //第1颗子弹
//弹栈完了,集合中就没有元素了
System.out.println(list); //[]
Day16: 集合进阶(Set、Map集合)
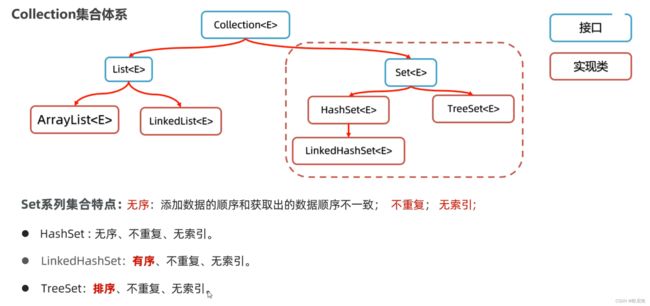
16.1 Set集合特点
16.1.1 案例演示
package com.sesameseed.p1_setpoint;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
public class Demo {
public static void main(String[] args) {
// Set set = new HashSet<>(); //存取无序,不重复,无索引 [33, 22, 11, 44] 哈希值 % 数组长度 得到元素存放位置
// Set set = new LinkedHashSet<>(); //存取有序,不重复,无索引 [22, 11, 33, 44]
Set<Integer> set = new TreeSet<>(); //强制排序,不重复,无索引 [11, 22, 33, 44]
set.add(22);
set.add(11);
set.add(33);
set.add(444);
set.add(44);
set.add(44);
System.out.println(set);
}
}
16.1.1 HashSet集合底层原理
- JDK8以前:哈希表 = 数组+链表
- JDK8以后:哈希表 = 数组+链表+红黑树

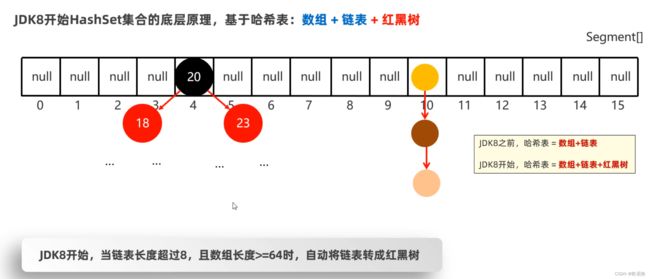
JDK8之后HashSet集合的底层原理: 哈希表+链表+红黑树
链表的特点,查询慢增删快
当链表长度超过8,并且数组长度大于等于64时,会将链表自动转为红黑树
红黑树上数据小于6,切换会链表。
还有就是如果新元素存储进数组时,是直接挂在老元素下(JDK8之前是老元素挂在新元素下)
树结构
二叉树: 没有规律,不用
每一个根节点最多只能有两个子节点(子节点数量称为度)
左子节点
右子节点
树高:树的总层数
左子树
右子树
二叉树查找(搜索)树: 小的存左边,大的存右边,相同则不存
如果数据已经排好序,那么存入二叉树查找树,会形成类似链表结构,查询效率还是低
如果左右子树的树高差比较大,那么导致左右子树不平衡,影响查询效率
平衡二叉树: 有规律且平衡,常用
当插入一个元素,导致左右子树的树高差大于1,那么就会触发旋转
旋转分为左旋和右旋,用来保证左右子树的相对平衡
红黑树: 自平衡的二叉树,有自己保证平衡的规则(红黑规则),性能好,常用
16.1.2 HashSet去重机制
注意:如下方案例演示所示,不重写hashCode和equals方法,比较的是默认的对象的值,而对象是个引用数据类型,比较的是地址的值,两个对象地址值不同,会打印出两个一模一样的数据,由于HashSet无序、不重复、无索引,所以与不重复相矛盾,因此输出有误。所以我们需要重写
hashCode和equals方法,重写完成后会就会比较对象中属性的值,打印出正确的结果。
16.1.2.1去重机制案例演示
package com.sesameseed.p3_repeat;
public class Student {
private String student;
private String age;
public String getStudent() {
return student;
}
public void setStudent(String student) {
this.student = student;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
public Student() {
}
public Student(String student, String age) {
this.student = student;
this.age = age;
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("Student{");
sb.append("student='").append(student).append('\'');
sb.append(", age='").append(age).append('\'');
sb.append('}');
return sb.toString();
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student1 = (Student) o;
if (student != null ? !student.equals(student1.student) : student1.student != null) return false;
return age != null ? age.equals(student1.age) : student1.age == null;
}
@Override
public int hashCode() {
int result = student != null ? student.hashCode() : 0;
result = 31 * result + (age != null ? age.hashCode() : 0);
return result;
}
}
package com.sesameseed.p3_repeat;
import java.util.HashSet;
/*
HashSet去重机制
通过哈希表,依赖存储元素的hashCode和equals方法去重
需求
使用HashSet存储学生对象
属性相同认为是同一个对象则不存
*/
public class Demo {
public static void main(String[] args) {
//创建HashSet
HashSet<Student> set = new HashSet<>();
//存入学生对象 -> 包含属性一样的
set.add(new Student("张三","18"));
set.add(new Student("张三","18"));
set.add(new Student("李四","19"));
set.add(new Student("李明","20"));
//遍历集合打印 -> 没有重写hashCode,equals去重失败! 默认是比较每个对象的地址值
for (Student student : set) {
System.out.println(student);
}
}
}
不重写打印:
Student{student='李四', age='19'}
Student{student='张三', age='18'}
Student{student='张三', age='18'}
Student{student='李明', age='20'}
重写打印
Student{student='张三', age='18'}
Student{student='李四', age='19'}
Student{student='李明', age='20'}
16.1.3 LinkedHashSet集合
LinkedHashSet 特点:存取有序(怎么存怎么取),不重复,无索引。
16.1.3.1 LinkedHashSet集合案例演示
package com.sesameseed.p4_linkedhashsetdemo;
import java.util.LinkedHashSet;
public class Demo1 {
/*
LinkedHashSet 存取有序,不重复,无索引
底层还是基于哈希表(数组,链表,红黑树)实现的
每个元素都额外多了一个双链表机制,来记录它前后元素的位置,从而使得元素有序(有规律)
*/
public static void main(String[] args) {
//特点:怎么存怎么取
LinkedHashSet<Integer> set = new LinkedHashSet<>();
set.add(22);
set.add(11);
set.add(33);
set.add(44);
set.add(44);
set.add(444);
System.out.println(set); //[22, 11, 33, 44, 444]
}
}
16.1.4 TreeSet集合
16.1.4.1 强制排序,不重复,无索引
注意 : TreeSet 强制排序,不重复,无索引
package com.sesameseed.p5_treesetdemo.demo1;
import java.util.TreeSet;
public class Demo {
//TreeSet 强制排序,不重复,无索引
public static void main(String[] args) {
TreeSet<String> set = new TreeSet<>();
set.add("c");
set.add("b");
set.add("a");
set.add("c");
System.out.println(set); //[a, b, c]
}
}
16.1.4.2 存自定义类,要指定排序规则 (否则报错).
注意:TreeSet强制排序,因此在你使用系统自带的类比如“string”,string的底层会封装排序方法,所以可以打印排序出的结果,而当你使用自定义类时,由于自定义类中没有封装排序类型,所以TreeSet不知道如何排序,所以会报错ClassCastExceptio类型转换异常。
16.1.4.2.1 报错案例演示
package com.sesameseed.p5_treesetdemo.demo2;
public class Car {
private String name;
private int price;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
if (price != car.price) return false;
return name != null ? name.equals(car.name) : car.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + price;
return result;
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("Car{");
sb.append("name='").append(name).append('\'');
sb.append(", price=").append(price);
sb.append('}');
return sb.toString();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
public Car() {
}
public Car(String name, int price) {
this.name = name;
this.price = price;
}
}
package com.sesameseed.p5_treesetdemo.demo2;
import java.util.TreeSet;
public class Demo {
/*
* TreeSet 强制排序,不重复,无索引
* 底层基于红黑树实现,强制排序
*
*
* 自定义类排序方式
* 自然排序
* 比较器排序
*
* 需求
使用TreeSet存储汽车对象
按照年龄进行升序排列,如果年龄相同,按照姓名首字母字典排序
* */
public static void main(String[] args) {
//如果存自定义类,要指定排序规则 (否则报错)
TreeSet<Car> set = new TreeSet<>();
set.add(new Car("xiaohong",2000));
set.add(new Car("lihua",100000));
set.add(new Car("ashui",10000));
set.add(new Car("ashui",10000));
for (Car car : set) {
System.out.println(car);
}
}
}

16.1.4.2.2 指定排序规则——自然排序(Comparable)
注意:自然排序,默认升序,需要在实体类中实现Comparable的接口,重写compareTo方法,指定排序规则,如下方第一个代码中重写compareTo方法指定的规则。
案例演示:
package com.sesameseed.p5_treesetdemo.demo2;
public class Car implements Comparable<Car> {
private String name;
private int price;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
if (price != car.price) return false;
return name != null ? name.equals(car.name) : car.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + price;
return result;
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("Car{");
sb.append("name='").append(name).append('\'');
sb.append(", price=").append(price);
sb.append('}');
return sb.toString();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
public Car() {
}
public Car(String name, int price) {
this.name = name;
this.price = price;
}
//自然排序 默认升序
@Override
public int compareTo(Car c) {
/*
* 返回一个整数
* 正数:表示当前存入的是较大值,存右边
* 0:表示重复,不存入
* 负数:表示当前存入的是较小值,存左边
* this代表当前要存入的元素
* c代表容器中的元素
* */
//主要条件: 根据price升序排列
int rs = this.price - c.price;
//次要条件: 根据name进行字典排序
return rs == 0 ? this.name.compareTo(c.name) : rs;
}
}
package com.sesameseed.p5_treesetdemo.demo2;
import java.util.TreeSet;
public class Demo {
/*
* TreeSet 强制排序,不重复,无索引
* 底层基于红黑树实现,强制排序
*
*
* 自定义类排序方式
* 自然排序
* 比较器排序
*
* 需求
使用TreeSet存储汽车对象
按照年龄进行升序排列,如果年龄相同,按照姓名首字母字典排序
* */
public static void main(String[] args) {
//如果存自定义类,要指定排序规则 (否则报错)
TreeSet<Car> set = new TreeSet<>();
set.add(new Car("xiaohong",2000));
set.add(new Car("lihua",100000));
set.add(new Car("ashui",10000));
set.add(new Car("bshui",10000));
for (Car car : set) {
System.out.println(car);
}
}
}
/*
* Car{name='xiaohong', price=2000}
Car{name='ashui', price=10000}
Car{name='bshui', price=10000}
Car{name='lihua', price=100000}
* */
16.1.4.2.3 指定排序规则——比较器排序(Comparator)
注意:比较器排序 (默认升序),c1、c2分别为第一个第二个比较的对象,
案例演示:
package com.sesameseed.p5_treesetdemo.demo3;
import java.util.Comparator;
import java.util.TreeSet;
public class Demo {
/*
* TreeSet 强制排序,不重复,无索引
* 底层基于红黑树实现,强制排序
*
*
* 自定义类排序方式
* 自然排序
* 比较器排序
*
* 需求
使用TreeSet存储汽车对象
按照年龄进行升序排列,如果年龄相同,按照姓名首字母字典排序
* */
public static void main(String[] args) {
//如果存自定义类,要指定排序规则 (否则报错)
//比较器排序 (默认升序)
TreeSet<Car> set = new TreeSet<>(new Comparator<Car>() {
@Override
public int compare(Car c1, Car c2) {
int rs = c1.getPrice() - c2.getPrice();
return rs == 0 ? c1.getName().compareTo(c2.getName()) : rs;
}
});
set.add(new Car("xiaohong", 2000));
set.add(new Car("lihua", 100000));
set.add(new Car("ashui", 10000));
set.add(new Car("bshui", 10000));
for (Car car : set) {
System.out.println(car);
}
}
}
package com.sesameseed.p5_treesetdemo.demo3;
public class Car {
private String name;
private int price;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
if (price != car.price) return false;
return name != null ? name.equals(car.name) : car.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + price;
return result;
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("Car{");
sb.append("name='").append(name).append('\'');
sb.append(", price=").append(price);
sb.append('}');
return sb.toString();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
public Car() {
}
public Car(String name, int price) {
this.name = name;
this.price = price;
}
}
16.1.4.2.4 自然排序(Comparable)和比较器排序(Comparator)区别
注意:Comparator不能用于实体类中,而且我们可以在Comparable不能满足我们的需求时,就不用他了,在我们的main方法中重写Comparator方法,指定排序规则满足我们的需求。
案例演示
package com.sesameseed.p5_treesetdemo.demo4;
import java.util.Comparator;
import java.util.TreeSet;
public class Demo {
/*
需求
Set集合存储四个字符串, "c", "ab", "df", "qwer"
按照长度升序排序, 长度一样则按照首字母排序
*/
public static void main(String[] args) {
TreeSet<String> set = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
//主要条件: 根据长度升序
int rs = s1.length() - s2.length();
//次要条件: 长度一样, 根据字典排序
return rs == 0 ? s1.compareTo(s2) : rs;
}
});
set.add("c");
set.add("ab");
set.add("df");
set.add("qwer");
System.out.println(set);
}
}
16.2 Collection集合小结
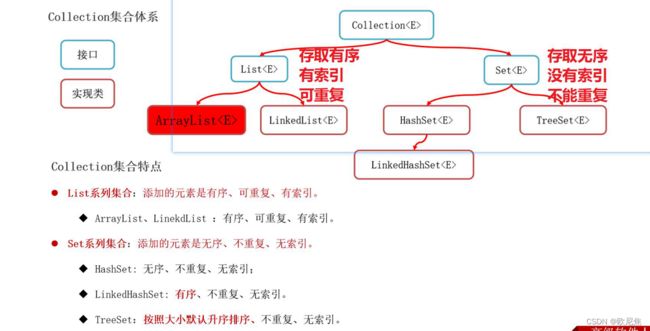
Collection小结
- List - 存取有序,有索引,能重复
- ArrayList
底层由数组实现,查询快,增删漫- LinkedList
底层由链表实现,增删快,查询慢
Set - 存取无序,没有索引,不能重复- HashSet
底层由哈希表实现,依赖存储元素的hashCode和equals方法去重- TreeSet
底层由红黑树实现,默认使用自然排序,如果不满足则使用比较器排序
Collection体系集合应用场景
- 如果希望记住元素顺序,需要存储重复元素,又要频繁根据索引操作元素 -> ArrayList
- 如果希望记住元素顺序,又要频繁操作首尾数据 -> LinkedList
- 如果不在意元素顺序,也没有重复元素要存储,希望CRUD相对都快 -> HashSet
- 如果希望记住元素顺序,也没有重复元素要存储,且希望增删改查相对都快 -> LinkedHashSet
- 如果要对元素进行排序,也没有重复元素要存储,且希望增删改查相对都快 -> TreeSet
16.3 并发修改异常
解释:迭代器是在遍历之前创建的,如果一边迭代一遍操作集合本身,则会造成集合和迭代器不同步,JVM会报异常。
16.3.1 并发修改异常案例
package com.sesameseed.p6_exceptiondemo.demo2;
import java.util.ArrayList;
import java.util.Iterator;
public class Demo {
public static void main(String[] args) {
/*
集合的并发修改异常
需求: 删除ArrayList集合中姓李的名字
总结: 遍历集合的同时删除元素,可能导致索引混乱,底层会报"并发修改异常"
普通for遍历: 当我们要通过索引操作元素时
迭代器遍历: 当我们要在遍历过程中,删除元素时
增强for: 仅仅想遍历时
forEach: 用来简化增强for的
*/
//报错ConcurrentModificationException 并发修改异常
ArrayList<String> list = new ArrayList<>();
list.add("王麻子");
list.add("小李子");
list.add("李爱花");
list.add("张全蛋");
list.add("晓李");
list.add("李玉刚");
System.out.println(list); //ConcurrentModificationException
/* 错误解释:
因为迭代器是在进行遍历操作之前创建的,如果一边迭代一边操作集合本身,
则会造成集合和迭代器不同步,JVM会报异常,如果要删除元素,
则可以使用迭代器的remove()方法而不是集合的remove()方法。
*/
Iterator<String> it = list.iterator();
while (it.hasNext()){
String name = it.next();
if (name.contains("李")){
list.remove(name);
}
}
}
}
16.4 可变参数
注意:
- 可变参数是一种特殊的形参,定义在方法、构造器的形参列表中,格式是数据类型… 参数名称
- 特点: 可以不接收数据,可以接收一个或多个数据,还能接收一个数组
- 好处: 灵活的接收数据,帮调用者省去了封装数据的步骤
- 注意: 可变参数本质是数组,一个形参列表中只能声明一个可变参数,且必须写在最后
16.4.1 可变参数案例一
package com.sesameseed.p7_canchangeparameter.demo1;
import java.util.Arrays;
public class Demo {
/*
可变参数
是一种特殊的形参,定义在方法、构造器的形参列表中,格式是数据类型... 参数名称
特点: 可以不接收数据,可以接收一个或多个数据,还能接收一个数组
好处: 灵活的接收数据,帮调用者省去了封装数据的步骤
注意: 可变参数本质就是一个数组,一个形参列表中只能声明一个可变参数,且必须写在最后
*/
public static void main(String[] args) {
test();
test(10);
test(10, 20, 30);
test(new int[]{1, 2, 3, 4, 5});
}
public static void test(int... nums) {
System.out.println(nums);//[I@776ec8df
/*
[ : 一维数组
I : 数组的数据类型
@ : 分隔符,没有任何意义
776ec8df : 16进制的内存地址
*/
System.out.println(nums.length);
System.out.println(Arrays.toString(nums));
System.out.println("------------------");
/*
*
[I@776ec8df
0
[]
------------------
[I@4eec7777
1
[10]
------------------
[I@3b07d329
3
[10, 20, 30]
------------------
[I@41629346
5
[1, 2, 3, 4, 5]
------------------
* */
}
}
16.4.2 可变参数案例二
package com.sesameseed.p7_canchangeparameter.demo2;
/*
需求
定义方法接收两个整数,返回和
定义方法接收三个整数,返回和
定义方法接收n个整数,返回和
*/
public class Demo {
public static void main(String[] args) {
//JDK5之前,让调用者自己封装一个数组
// int[] arr = {1,2,3,4,5};
// System.out.println(getSum(arr)); //15
//JDK5之后,我们可以使用可变参数来接收用户传递的n个数据
System.out.println(getSum(1, 2, 3, 4, 5)); //15
}
public static int getSum(int a, int b) {
return a + b;
}
public static int getSum(int a, int b, int c) {
return a + b + c;
}
//可变参数在参数列表中只能出现一次
//可变参数必须写在参数列表的最后面
public static int getSum(int... arr) {
int sum = 0;
for (int i = 0; i < arr.length; i++) {
sum += arr[i];
}
return sum;
}
}
16.5 Collections集合工具类
工具类的设计思想
1.空参构造私有 -> 不让外界创建对象
2.方法都是静态的 -> 通过类名直接调用,代码更简洁
Collections集合工具类
public static boolean addAll(单列集合, 可变参数); 批量添加元素
public static void shuffle(List集合); 打乱List集合元素顺序,每次调用都会打乱
public static void sort(List集合); 对List集合进行自然排序
public static void sort(List集合, 比较器); 对List集合进行比较器排序
16.5.1 Collections集合工具类案例
package com.sesameseed.p8_collectionssettings.demo;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collector;
/*
工具类的设计思想
1.空参构造私有 -> 不让外界创建对象
2.方法都是静态的 -> 通过类名直接调用,代码更简洁
Collections集合工具类
public static boolean addAll(单列集合, 可变参数); 批量添加元素
public static void shuffle(List集合); 打乱List集合元素顺序,每次调用都会打乱
public static void sort(List集合); 对List集合进行自然排序
public static void sort(List集合, 比较器); 对List集合进行比较器排序
*/
public class Demo1 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
// public static boolean addAll(单列集合, 可变参数); 批量添加元素
Collections.addAll(list, 1, 2, 3, 4);
System.out.println(list);
// public static void shuffle(List集合); 打乱List集合元素顺序,每次调用都会打乱
Collections.shuffle(list);
System.out.println(list);
List<Student> stus = new ArrayList<>();
stus.add(new Student("zhangsan", 18));
stus.add(new Student("wangwu", 22));
stus.add(new Student("zhaoliu", 21));
stus.add(new Student("lisi", 19));
stus.add(new Student("qianqi", 19));
// public static void sort(List集合); 对List集合进行自然排序
// Collections.sort(stus); //对List集合进行自然排序
// for (Student student : stus) {
// System.out.println(student);
// }
//public static void sort(List集合, 比较器); 对List集合进行比较器排序
Collections.sort(stus, (s1, s2) ->{
int result = s1.getAge() - s2.getAge();
return result == 0 ? s1.getName().compareTo(s2.getName()) : result;
});
for (Student stu : stus) {
System.out.println(stu);
}
}
}
package com.sesameseed.p8_collectionssettings.demo;
public class Student implements Comparable<Student> {
private String name;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("Student{");
sb.append("name='").append(name).append('\'');
sb.append(", age=").append(age);
sb.append('}');
return sb.toString();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Student s) {
int rs = this.age - s.age;
return rs == 0 ? this.name.compareTo(s.getName()) : rs; //compareTo()函数用于判断一个字符串是大于、等于还是小于另一个字符串,按字典顺序比较两个字符串。该比较基于字符串中各个字符的Unicode值,将此String对象表示的字符序列与参数字符串所表示的字符序列进行比较。
}
}
16.6 Map集合及其的三种遍历方法
16.6.1 Map集合
Map集合概述
Map被称为双列集合,一次存一对数据作为一个元素整体
存储数据格式为key=value,key称为键,value称为值,整体称为"键值对"或"键值对对象"(Entry对象)
Map集合的键不能重复,值可以重复,每一个键只能找到自己对应的值
Map集合应用场景
如果需要存储一一对应的数据时,可以考虑使用Map集合
Map集合体系
Map(接口) 由键决定特点
HashMap(实现类) 无序,不重复,无索引
LinkedHashMap(实现类) 有序,不重复,无索引
TreeMap(实现类) 排序,不重复,无索引
16.6.1.1 案例
package com.sesameseed.p9_mapdemo.mapdemo.demo;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.TreeMap;
/*
Map集合概述
Map被称为双列集合,一次存一对数据作为一个元素整体
存储数据格式为key=value,key称为键,value称为值,整体称为"键值对"或"键值对对象"(Entry对象)
Map集合的键不能重复,值可以重复,每一个键只能找到自己对应的值
Map集合应用场景
如果需要存储一一对应的数据时,可以考虑使用Map集合
Map集合体系
Map(接口) 由键决定特点
HashMap(实现类) 无序,不重复,无索引
LinkedHashMap(实现类) 有序,不重复,无索引
TreeMap(实现类) 排序,不重复,无索引
*/
public class Demo1 {
public static void main(String[] args) {
// Map map = new HashMap<>();//HashMap(实现类) 无序,不重复,无索引
Map<Object, Object> map = new LinkedHashMap<>();//HashMap(实现类) 无序,不重复,无索引
map.put("手机", "10000");
map.put("手机", "2000");
map.put("电视", "2000");
map.put("电脑", "2000000");
map.put("洗衣机", "50000");
System.out.println(map); //{手机=2000, 电视=2000, 电脑=2000000, 洗衣机=50000} (key,value)存放。取keyl来排序
Map<Integer, String> map1 = new TreeMap<>();//TreeMap(实现类) 排序,不重复,无索引
map1.put(4, "java");
map1.put(1, "java");
map1.put(2, "java");
map1.put(3, "java");
map1.put(3, "python");
System.out.println(map1); //{1=java, 2=java, 3=python, 4=java} 取key值默认大小排序
}
}
16.6.2 Map集合常用方法
public V put(K key, V value); 添加元素/通过key修改value
public int size(); 返回集合元素个数
public void clear(); 清空集合元素
public boolean isEmpty(); 判断集合是否为空
public V get(Obj obj); 通过key获取对应的value
public V remove(Obj obj); 通过key删除键值对
public boolean containsKey(Obj key); 判断集合是否包含指定的key
public boolean containsValue(Obj value); 判断集合是否包含指定的value
public Set ketSet(); 返回所有键的集合
public Collection values(); 返回所有值的集合
public putAll(); 添加指定集合的全部元素
16.6.2.1 案例
package com.sesameseed.p9_mapdemo.mapdemo.demo;
import java.util.HashMap;
import java.util.Map;
public class Demo2 {
/*
Map集合常用方法
public V put(K key, V value); 添加元素/通过key修改value
public int size(); 返回集合元素个数
public void clear(); 清空集合元素
public boolean isEmpty(); 判断集合是否为空
public V get(Obj obj); 通过key获取对应的value
public V remove(Obj obj); 通过key删除键值对
public boolean containsKey(Obj key); 判断集合是否包含指定的key
public boolean containsValue(Obj value); 判断集合是否包含指定的value
public Set ketSet(); 返回所有键的集合
public Collection values(); 返回所有值的集合
public putAll(); 添加指定集合的全部元素
*/
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
// public V put(K key, V value); 添加元素/通过key修改value
map.put("小龙女","尹志平");
map.put("赵敏","张无忌");
map.put("小燕子","五阿哥");
map.put("孙尚香","刘备");
System.out.println(map); //{小龙女=尹志平, 孙尚香=刘备, 赵敏=张无忌, 小燕子=五阿哥}
//根据key修改value
map.put("小龙女","张无忌");
System.out.println(map); //{小龙女=张无忌, 孙尚香=刘备, 赵敏=张无忌, 小燕子=五阿哥}
//public int size(); 返回集合元素个数
System.out.println(map.size()); //4
//public void clear(); 清空集合元素
// map.clear();
// System.out.println(map); //{}
// System.out.println(map.size()); //0
//public boolean isEmpty(); 判断集合是否为空
System.out.println(map.isEmpty());//f
//public V get(Obj obj); 通过key获取对应的value
System.out.println(map.get("小龙女")); //张无忌
// System.out.println(map.get("刘备")); null,通过值取取不到,map集合需要通过key键取
System.out.println("========================");
//public V remove(Obj obj); 通过key删除键值对
System.out.println(map.remove("小龙女")); //张无忌
System.out.println(map); //{孙尚香=刘备, 赵敏=张无忌, 小燕子=五阿哥}
//public boolean containsKey(Obj key); 判断集合是否包含指定的key
System.out.println(map.containsKey("孙尚香")); //t
//public boolean containsValue(Obj value); 判断集合是否包含指定的value
System.out.println(map.containsValue("刘备")); //t
//public Set ketSet(); 返回所有键的集合(key不能重复,所以返回set集合)
System.out.println(map.keySet()); //[孙尚香, 赵敏, 小燕子]
//public Collection values(); 返回所有值的集合
System.out.println(map.values()); //[刘备, 张无忌, 五阿哥]
Map<Integer, String> map1 = new HashMap<>();//HashMap(实现类) 无序,不重复,无索引
map1.put(1,"java");
map1.put(2,"java");
Map<Integer,String> map2 = new HashMap<>();
map1.put(2,"java");
map1.put(3,"java");
//public void putAll(); 添加指定集合的全部元素
map1.putAll(map2);
System.out.println(map1); //{1=java, 2=java, 3=java}
}
}
16.6.3 Map遍历1: 通过键获取对应的值
package com.sesameseed.p9_mapdemo.ergodicmap;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/*
Map遍历1: 通过键获取对应的值
*/
public class Demo1 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("西游记", "吴承恩");
map.put("三国演义", "罗贯中");
map.put("红楼梦", "曹雪芹");
map.put("水浒传", "施耐庵");
//获取所有键的集合 -> keySet();
Set<String> keys = map.keySet();
System.out.println(keys); //[水浒传, 三国演义, 红楼梦, 西游记]
for (String key : keys) {
// System.out.println(key);
String value = map.get(key);
System.out.println(key+"->"+ value);
/*
水浒传->施耐庵
三国演义->罗贯中
红楼梦->曹雪芹
西游记->吴承恩
* */
}
}
}
16.6.4 Map遍历2: 通过键值对分别获取键和值
package com.sesameseed.p9_mapdemo.ergodicmap;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/*
Map遍历2: 通过键值对分别获取键和值
*/
public class Demo2 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("西游记", "吴承恩");
map.put("三国演义", "罗贯中");
map.put("红楼梦", "曹雪芹");
map.put("水浒传", "施耐庵");
//获取装着"键值对对象"的集合 -> entrySet();
Set<Map.Entry<String, String>> entries = map.entrySet();
System.out.println(entries);
for (Map.Entry<String, String> entry : entries) {
// System.out.println(entry);
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " -> " + value);
/*
* 水浒传 -> 施耐庵
三国演义 -> 罗贯中
红楼梦 -> 曹雪芹
西游记 -> 吴承恩
* */
}
}
}
16.6.5 Map遍历3: forEach
package com.sesameseed.p9_mapdemo.ergodicmap;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
/*
Map遍历3: forEach
*/
public class Demo3 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("西游记", "吴承恩");
map.put("三国演义", "罗贯中");
map.put("红楼梦", "曹雪芹");
map.put("水浒传", "施耐庵");
//匿名内部类
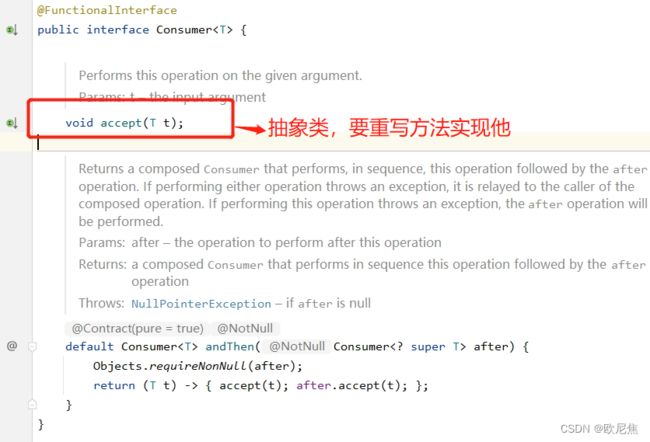
/*BiConsumer源码
@FunctionalInterface //函数式接口,可以用lambda
public interface BiConsumer {
void accept(T t, U u); //抽象方法需要重写
*/
map.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String k, String v) {
System.out.println(k + " -> " + v);
}
});
//Lambda
map.forEach((k, v) -> System.out.println(k + " -> " + v));
}
}
16.6 Map集合统计投票人数案例
package com.sesameseed.p9_mapdemo.maptest;
import javax.swing.text.PlainDocument;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Random;
/*
需求
Map集合统计投票人数
某个班级80个学生,现需要组织户外活动,有四个景点可选(兵马俑,大雁塔,草滩六路,吉祥村)
每个学生只能选择一个景点,请统计最终结果
*/
public class Demo {
public static void main(String[] args) {
//模拟学生随机投票
Random r = new Random();
//创建一个集合用于取出80个人的投票结果
ArrayList<String> places = new ArrayList<>();
//定义一个储存景点信息的数组
String[] selectPlace = {"兵马俑", "大雁塔", "赛格", "吉祥村"};
//80个人开始投票
for (int i = 0; i < 80; i++) {
//循环得到80次景点信息数组下标
int index = r.nextInt(selectPlace.length);
//把得到的数组下标存入到places集合中。由于string是jdk自带的类,他的底层封装了tostring方法,所以可以直接打印出属性
places.add(selectPlace[index]);
}
System.out.println(places);
//遍历投票结果
//创建HashMap集合,key代表景点,value代表次数,用于储存投票结果
HashMap<String, Integer> map = new HashMap<>();
//遍历投票地点结果
for (String place : places) {
// System.out.println(place);
//在集合中判断当前结果是否存在
if (map.containsKey(place)){
//如果存在获取通过键获取取其对应的次数
Integer count = map.get(place);
//次数+1
count++;
//重新存入投票结果集合,这样就能统计相应次数
map.put(place, count);
}else {
//如果不存在,存入当前的景点,次数1代表第一次出现,存在之后执行上边的存在循环
map.put(place, 1);
}
}
System.out.println(map);
}
}
Day19:IO流2
19.1 字符流
- 字符流是专门为读取文本数据而生的
字节流(操作所有类型文件,文件复制)
- 字节输入流 InputStream(抽象类) FileInputStream(实现类)
- 字节输出流 OutputStream(抽象类) FileOutputStream(实现类)
字符流(纯文本文件,读写txt、java文件)
- 字符输入流 Reader(抽象类) FileReader(实现类)
- 字符输出流 Writer(抽象类) FileWriter(实现类)
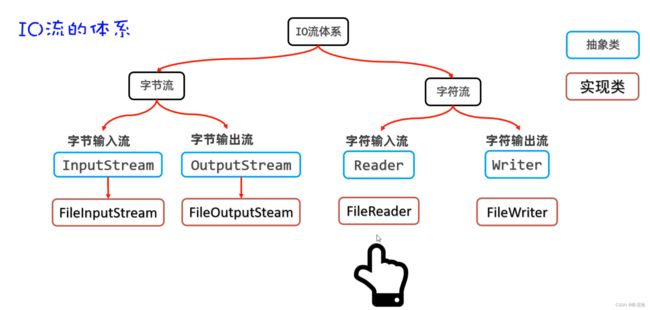
FileReader读取文件的步骤如下:
第一步:创建FileReader对象与要读取的源文件接通
第二步:调用read()方法读取文件中的字符
第三步:调用close()方法关闭流
19.1.1 字符输入流
19.1.1.1 案例一:
字符输入流 Reader(抽象类) FileReader(实现类)
package com.sesameseed.p1_filereader;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class Demo1 {
public static void main(String[] args) throws IOException {
//1.创建字符输入流对象,关联文件
Reader f1 = new FileReader("day19\\1.txt");
//2.读一个
// System.out.println((char) f1.read()); // public int read() throws IOException {
int ch;
while ((ch = f1.read()) != -1){
System.out.print((char)ch);
}
//2.读多个shertl chars = new char!
//3.释放资源
f1.close();
}
}
19.1.1.2 案例二:
try catch 不用结束流,底层会帮我们结束
package com.sesameseed.p1_filereader;
import java.io.FileReader;
import java.io.Reader;
/*
* 注意:try catch 不用结束流,底层会帮我们结束
* */
public class Demo2 {
public static void main(String[] args) {
//FileReader构造方法
//public FileReader(String pathname); 底层帮我们根据pathname封装File对象,更常用
try (
//FileReader读数据
Reader f1 = new FileReader("day19\\1.txt");
) {
int ch;
//一次读一个字符,返回字符对应的字节,读到文件末尾返回-1
while ((ch = f1.read()) != -1){
System.out.print((char) ch);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
19.1.1.3 案例三:
package com.sesameseed.p1_filereader;
import java.io.FileReader;
import java.io.Reader;
public class Demo3 {
public static void main(String[] args) {
//FileReader构造方法
//public FileReader(String pathname); 底层帮我们根据pathname封装File对象,更常用
try (
Reader f1 = new FileReader("day19\\1.txt");
) {
//一次读多个字符,返回本次读取的有效字节个数,读到文件末尾返回-1
int len;
char[] chars = new char[1024];
while ((len = f1.read(chars)) != -1) {
System.out.print(new String(chars, 0, len));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
19.1.2 字符输出流
字符输出流 Writer(抽象类) FileWriter(实现类)
10.1.2.1 案例一
- void write(String str); 写一个字符串
- void write(String str, int off, int len); 写一个字符串的一部分
- 追加写入需要在构造第二个参数传递true
- 换行直接写"\r\n"即可,经过测试\r或者\n也可以,还有newline()方法
package com.sesameseed.p2_filewriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
/*
* FileWriter写数据
void write(int c); 写一个字符
* void write(String str); 写一个字符串
* void write(String str, int off, int len); 写一个字符串的一部分
void write(char[] buffer); 写一个字符数组
void write(char[] buffer, int off, int len); 写一个字符数组的一部分
字符流注意: 换行和追加写入
换行直接写"\r\n"即可
追加写入需要在构造第二个参数传递true
*/
public class Demo1 {
public static void main(String[] args) throws IOException {
//1.创建字符输入流对象,关联文件
Writer w1 = new FileWriter("day19\\2.txt");
//2.写数据
//2.1写一个字符
// w1.write(98);
//2.2写一个字符串
// w1.write("大萨达撒");
//2.3写一个字符串的一部分,需求:写出吴彦祖三个字
String name = "让我打卡吴彦祖";
w1.write(name, 4, 3);
//2.4 写一个字符数组
char[] chars = {'a', 'b', 98};
w1.write(chars);
w1.write("\r");
//2.5 写一个字符数组的一部分
w1.write(chars, 1, 2);
//3.释放资源
w1.close();
}
}
19.1.2.2 案例二
追加写入需要在构造第二个参数传递true Writer w1 = new FileWriter(“day19\2.txt”, true);
package com.sesameseed.p2_filewriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
/*
追加写入需要在构造第二个参数传递true Writer w1 = new FileWriter("day19\\2.txt", true);
*/
public class Demo2 {
public static void main(String[] args) throws IOException {
//1.创建字符输入流对象,关联文件
Writer w1 = new FileWriter("day19\\2.txt", true);
//2.写数据
//2.1写一个字符
// w1.write(98);
//2.2写一个字符串
// w1.write("大萨达撒");
//2.3写一个字符串的一部分,需求:写出吴彦祖三个字
String name = "让我打卡吴彦祖";
w1.write(name, 4, 3);
//2.4 写一个字符数组
char[] chars = {'a', 'b', 98};
w1.write(chars);
w1.write("\r");
//2.5 写一个字符数组的一部分
w1.write(chars, 1, 2);
//3.释放资源
w1.close();
}
}
19.1.3 字符输出流注意
flush() 方法:
- 如果手动刷新(flush),那么会将目前缓冲区中的数据写入文件,如果不手动刷新最后底只调用一次系统资源(close),将所有数据一次性写到文件中即可,这样效率高
package com.sesameseed.p3_flush;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
public class Demo1 {
public static void main(String[] args) throws IOException {
/*
字符流注意: 刷新和关流
写数据时如果每写一个字符,都要调用一次系统资源写到文件,效率就太低了
创建文件字符输出流对象时,底层会准备一个缓冲区,写多个数据会先写到缓冲区中(如果缓冲区满了会自动刷新一次)
如果手动刷新(flush),那么会将目前缓冲区中的数据写入文件,如果不手动刷新
最后底只调用一次系统资源(close),将所有数据一次性写到文件中即可,这样效率就变高了
*刷新和关流方法
public void flush() throws IOException 刷新流
public void close() throws IOException 刷新流并关闭流
* */
Writer w2 = new FileWriter("day19\\3.txt");
//写数据
w2.write("a");
w2.write("b");
w2.write(99);
w2.write("\r");
//刷新流
w2.flush();
w2.write("大大");
w2.write("\n");
w2.write("大多数");
//刷新流
w2.flush();
//释放资源
w2.close(); //关流之前会自动刷新
}
}
19.2 缓冲流
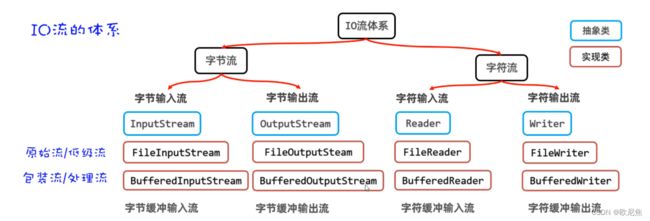
缓冲流的作用**:可以对原始流进行包装,提高原始流读写数据的性能。
- 读数据时:它先用原始字节输入流一次性读取8KB的数据存入缓冲流内部的数组中(ps: 先一次多囤点货),再从8KB的字节数组中读取一个字节或者多个字节(把消耗屯的货)。
- 写数据时: 它是先把数据写到缓冲流内部的8BK的数组中(ps: 先攒一车货),等数组存满了,再通过原始的字节输出流,一次性写到目标文件中去(把囤好的货,一次性运走)。
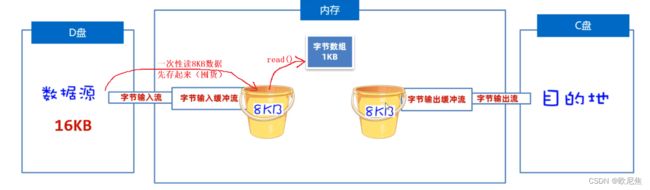
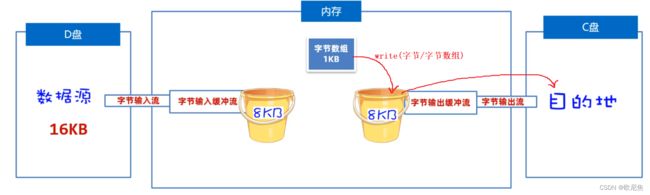
19.2.1 字节缓冲流
19.2.1.1 案例一
public static void main(String[] args) {
/*
需求: 字节缓冲流实现文件复制
*/
try (
//创建字节缓冲输入流,关联数据源(读数据)
BufferedInputStream bis = new BufferedInputStream(
new FileInputStream("C:\\itheima\\1.mp3"));
//创建字节缓冲输出流,关联目的地(写数据)
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("day10\\copy.mp3"));
) {
//边度边写
byte[] bytes = new byte[1024];
int len;
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
}
} catch (Exception e) {
e.printStackTrace();
}
}
19.2.2 字符缓冲入流
- BufferedReader -> 底层提供8K的缓冲区,减少和内存和硬盘的交互,真正干活的还是字符输入流
19.2.2.1 案例一
package com.sesameseed.p4_bufferinoutstream;
import java.io.*;
/*
字符缓冲输入流
BufferedReader -> 底层提供8K的缓冲区,减少和内存和硬盘的交互,真正干活的还是字符输入流
BufferedReader相关方法
public BufferedReader(Reader r);
public String readLine(); 读一行数据,读到文件末尾返回null
* */
public class Demo1 {
//需求 字符缓存流读数据
public static void main(String[] args) throws IOException {
//创建对象,关联文件
BufferedReader br = new BufferedReader(new FileReader("day19\\4.txt"));
//读数据
// System.out.println(br.readLine()); //大萨达撒多撒多
// System.out.println(br.readLine()); //大大的
// System.out.println(br.readLine()); //null
// System.out.println(br.readLine()); //null
// 推出是null的时候结束
String info;
while ((info = br.readLine()) != null) {
System.out.println(info);
}
}
}
19.2.3 字符缓输出流
- BufferedWriter -> 底层提供8K的缓冲区,减少和内存和硬盘的交互,真正干活的还是字符输出流
- BufferedWriter bw2 = new BufferedWriter(new FileWriter(“day19\4a1.txt”)); //将写入流对象写在次,用try catch finally 会导致finally中无法调用关闭流
19.2.3.1 案例一
package com.sesameseed.p4_bufferinoutstream;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class Demo2 {
/*
字符缓冲输出流
BufferedWriter -> 底层提供8K的缓冲区,减少和内存和硬盘的交互,真正干活的还是字符输出流
BufferedWriter相关方法
public BufferedWriter(Writer w);
public String newLine(); 写一个换行
*/
public static void main(String[] args) {
//需求:字符缓冲流写数据
BufferedWriter bw2 = null;
//创建对象,关联文件
try {
// BufferedWriter bw2 = new BufferedWriter(new FileWriter("day19\\4a1.txt")); //将写入流对象写在次,用try catch finally 会导致finally中无法调用关闭流
bw2 = new BufferedWriter(new FileWriter("day19\\4a1.txt")); //将写入流对象写在次,用try catch finally 会导致finally中无法调用关闭流
//写一个字符
bw2.write(97); //a
//换行
bw2.write("\r");
// bw2.newLine();
//写一个字符串
bw2.write("挨打的大所");
//写一个字符串的一部分
bw2.write("搭搭撒撒所多", 1, 3); //搭撒撒
//换行
bw2.newLine();
//写字符数组
char[] chars = {'a', 'b', 'c'};
bw2.write(chars);
} catch (IOException e) {
e.printStackTrace();
}finally {
if (bw2 != null) {
try {
//释放资源
bw2.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
19.2.4 原始流缓冲流性能分析
19.3 字节流
19.3.1 字节输入转换流
- 先获取文件的"原始字节流",按照"指定字符集",封装成"字符输入转换流"进行读取(可继续封装缓冲流),这样就不会乱码了
public InputStreamReader(InputStream is, String charset);
19.3.1.1 案例一
- isr.flush(); //写入流刷新,读流不刷新
- 释放资源,随便释放一个,因为彼此间都有依赖
package com.sesameseed.p5_charactertrans;
import java.io.*;
public class Demo1 {
public static void main(String[] args) throws IOException {
//需求:使用UTF-8读取GBK编码的文件内容
//先获取文件的"原始字节流”
//原始字节流:一个字节一个字节地复制文件
InputStream is= new FileInputStream("day19\\5.txt");
//按照"指定字符集",封装成”字符输入转换流(为了调用他指定编码的方法)”
InputStreamReader isr = new InputStreamReader(is, "gbk");
//可继续封装缓冲流
BufferedReader br = new BufferedReader(isr);
//链式编程,新手不建议这样写,容易晕!
//BufferedReader bis = new BufferedReader(new InputStreamReader(new FileInputStream("day10\\Demo07.txt"),"gbk"));
//读取
String st;
while ((st = br.readLine()) != null){
System.out.println(st); //使用指定字符集GBK写数据
// System.out.println(st);
}
//释放资源,随便释放一个,因为彼此间都有依赖
isr.close();
// isr.flush(); //写入流刷新,读流不刷新
// is.close();
}
}
19.3.2 字节输出转换流
- 先获"字节输出流",按照"指定字符集",封装成"字符输出转换流"进行写出(可继续封装缓冲流),这样就完成了指定字符集写数据
public OutputStreamWriter(OutputStream os, String charset);
19.3.2.1 案例一
- 先获取"字节输出流",按照"指定字符集",封装成"字符输出转换流"进行写出(可继续封装缓冲流),这样就完成了指定字符集写数据
public OutputStreamWriter(OutputStream os, String charset);
package com.sesameseed.p5_charactertrans;
import java.io.*;
public class Demo2 {
public static void main(String[] args) throws IOException {
//需求: 使用指定字符集,控制写出去的字符
//先获”字节输出流"
OutputStream os = new FileOutputStream("day19\\5.txt");
//按照"指定字符集",封装成”字符输出转换流"
OutputStreamWriter osw = new OutputStreamWriter(os, "GBK");
//可继续封装缓冲流
BufferedWriter bw = new BufferedWriter(osw);
//写数据
bw.write("在Demo07.txt文件中");
bw.newLine();
bw.write("使用指定字符集GBK写数据");
bw.flush(); //这时候如果你调用了 close()方法关闭了读写流,那么这部分数据就会丢失,所以应该在关闭读写流之前先flush(),先清空数据。
//释放资源
bw.close();
}
}
19.4 打印流
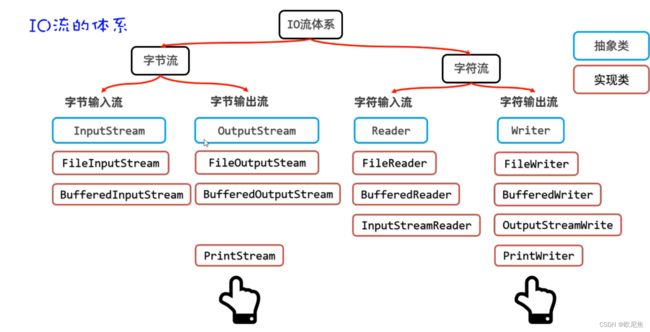
PrintStream字节打印流 和 PrintWriter字符打印流
19.4.1 案例一:PrintStream字节打印流
两者打印数据的功能是一样的,核心优势是性能高 (底层封的是高效流(如序列流,数据流))
- PrintStream继承字节输出流,因此支持写字节的相关方法
- PrintWriter继承字符输出流,因此支持写字符的相关方法
package com.sesameseed.p6_printdemo;
import java.io.IOException;
import java.io.PrintStream;
/*
打印流
可以实现更方便、更高效地写数据,分为PrintStream和PrintWriter
两者打印数据的功能是一样的,核心优势是性能高 (底层封的是高效流(如序列流,数据流))
PrintStream继承字节输出流,因此支持写字节的相关方法
PrintWriter继承字符输出流,因此支持写字符的相关方法
PrintStream字节打印流
* public PrintStream(OutputStream/File/String); 创建对象并关联字节输出流/文件对象/文件路径
public PrintStream(String pathname, Charset charset);
public PrintStream(OutputStream out, Boolean autoFlush);
public PrintStream(OutputStream out, Boolean autoFlush, Charset charset);
* public void println(内容); 写任意类型数据
public void write(内容); 写字节数据
*/
public class Demo1 {
public static void main(String[] args) throws IOException {
PrintStream p1 = new PrintStream("day19\\6.txt");
//public void println(内容);写任意类型数据
p1.println(10);
p1.println(3.14);
p1.println((char)97);
p1.println('c');
p1.println(true);
p1.close();
}
}
19.4.1 案例二:PrintWriter字符打印流
package com.demo11_IO流_打印流;
import java.io.FileNotFoundException;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.nio.charset.Charset;
/*
PrintWriter字符打印流
* public PrintWriter(OutputStream/Writer/File/String); 创建对象并关联字节输出流/字符输出流/文件对象/文件路径
public PrintWriter(String pathname, Charset charset);
public PrintWriter(OutputStream out/Writer, Boolean autoFlush);
public PrintWriter(OutputStream out, Boolean autoFlush, String encoding);
* public void println(内容); 写任意类型数据
public void write(内容); 写字符数据
*/
public class Demo02 {
public static void main(String[] args) throws FileNotFoundException {
try (
//public PrintWriter(OutputStream/Writer/File/String); 创建对象并关联字节输出流/字符输出流/文件对象/文件路径
//PrintWriter pw = new PrintWriter("day10\\Demo09.txt");
//注意1: 将参数封装为原始流,才能通过构造,开启追加写入
//PrintWriter pw = new PrintWriter(new FileWriter("day10\\Demo09.txt",true));
//注意2: 指定字符集,需要使用Charset的静态方式forName
PrintWriter pw = new PrintWriter("day10\\Demo09.txt", Charset.forName("gbk"));
) {
//public void println(内容); 写任意类型数据
pw.println(10);
pw.println(3.14);
pw.println('A');
pw.println("黑马程序员"); //默认ut8还可以指定字符集
pw.println(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
19.4.1 打印流应用
输入语句重定向
System.setOut(new PrintStream("day19\\6a1.txt"));
package com.sesameseed.p6_printdemo;
import java.io.FileNotFoundException;
import java.io.PrintStream;
public class Demo3 {
/*
打印流的应用
输出语句的重定向(指定打印数据的目的地)
之前我们代码中的输出语句,打印目的地是控制台,但是项目上线后肯定就看不到了
我们可以使用打印流,指定打印目的地,实现输出语句的重定向
*/
public static void main(String[] args) throws FileNotFoundException {
//打印在控制台
System.out.println("床前明月光");
System.out.println("疑是地上霜");
/*
跟进out源码,本质上是一个打印流,输出目的地默认是控制台
public static final PrintStream out = null;
可以通过System类的静态方法setOut,指定打印数据的目的地
public static void setOut(PrintStream out)
*/
//输入语句重定向
System.setOut(new PrintStream("day19\\6a1.txt"));
//打印在指定路径的文件中
System.out.println("举头望明月");
System.out.println("低头思故乡");
}
}
19.5 数据流
DataInputStream和DataOutputStream.
- DataOutputStream继承字节输出流,因此支持写字节的相关方法
- DataInputStream继承字节输入流,因此支持读字节的相关方法
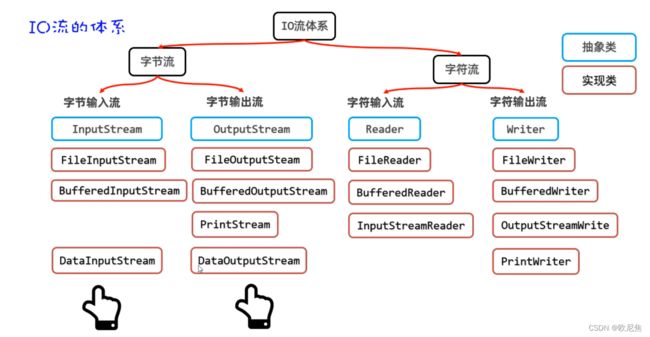
19.5.1 案例一:
DataOutputStream字节数据输出流,写数据
package com.sesameseed.p7_datainoutstream;
import java.io.DataOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/*
数据流
可以实现将数据和其类型一并读写
分为DataOutputStream和DataInputStream
DataOutputStream继承字节输出流,因此支持写字节的相关方法
DataInputStream继承字节输入流,因此支持读字节的相关方法
DataOutputStream字节数据输出流
public DataOutputStream(OutputStream is); 创建对象,通过封装的字节输出流关联文件
public final void writeInt(int data);
public final void writeDouble(int data);
public final void writeBoolean(int data);
public final void writeUTF(String data);
public void write(字节数据);
注意: 写出的数据直观是看不懂的,我们需要用字节数据输入流读
*/
public class Demo1 {
public static void main(String[] args) throws IOException {
//public·DataOutputStream(InputStream is); 创建对象,通过封装的字节输出关联文件
DataOutputStream dos = new DataOutputStream(new FileOutputStream("day19\\7.txt"));
dos.writeInt(97);
dos.writeDouble(3.14);
dos.writeBoolean(false);
dos.writeUTF("首发打发顺丰");
//释放资源
dos.close();
}
}
DataInputStream字节数据输入流,读数据
package com.sesameseed.p7_datainoutstream;
import java.io.DataInputStream;
import java.io.FileInputStream;
import java.io.IOException;
/*
DataInputStream字节数据输入流
public DataInputStream(InputStream is); 创建对象,通过封装的字节输入流关联文件
public final void readInt(int data);
public final void readDouble(int data);
public final void readBoolean(int data);
public final void readUTF(String data);
public void write(字节数据);
*/
public class Demo2 {
public static void main(String[] args) throws IOException {
//创建数据输入流对象
DataInputStream dis = new DataInputStream(new FileInputStream("day19\\7.txt"));
//读数据,按照写的顺序读
System.out.println(dis.readInt());
System.out.println(dis.readDouble());
System.out.println(dis.readBoolean());
System.out.println(dis.readUTF());
}
}
19.6 序列化流
- 序列化:意思就是把对象写到文件或者网络中去。(简单记:写对象)
- 反序列化:意思就是把对象从文件或者网络中读取出来。(简单记:读对象)
19.6.1 案例演示
package com.sesameseed.p8_serialize.baseserializable;
import java.io.Serializable;
public class User implements Serializable { //标记性接口
private String name;
private int age;
//transient修饰的password不参与序列化
private transient String passwd;
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("User{");
sb.append("name='").append(name).append('\'');
sb.append(", age=").append(age);
sb.append(", passwd='").append(passwd).append('\'');
sb.append('}');
return sb.toString();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getPasswd() {
return passwd;
}
public void setPasswd(String passwd) {
this.passwd = passwd;
}
public User(String name, int age, String passwd) {
this.name = name;
this.age = age;
this.passwd = passwd;
}
public User() {
}
}
ObjectOutputStream流,它也是一个包装流,不能单独使用,需要结合原始的字节输出流使用。
package com.sesameseed.p8_serialize.baseserializable;
import java.io.*;
import java.util.ArrayList;
public class Demo1 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//创建用户对象
User u1 = new User("张飞", 18, "123");
User u2 = new User("李四", 18, "123sdcard");
User u3 = new User("王五", 18, "555");
//创建集合存储对象
ArrayList<User> users = new ArrayList<>();
users.add(u1);
users.add(u2);
users.add(u3);
//序列化
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("day19\\8.txt"));
oos.writeObject(users);
oos.close();
//反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("day19\\8.txt"));
System.out.println(ois.readObject());
ois.close();
}
}
19.7 IO框架
Day20:特殊文件、日志技术、多线程
20.1 Properties属性文件
- 属性文件后缀以
.properties结尾- 属性文件里面的每一行都是一个键值对,键和值中间用=隔开。比如:
admin=123456#表示这样是注释信息,是用来解释这一行配置是什么意思。- 每一行末尾不要习惯性加分号,以及空格等字符;不然会把分号,空格会当做值的一部分。
- 键不能重复,值可以重复
Properties
本质是一个Map集合,但是我们不会当集合使用
Properties是用来代表属性文件的,通过它提供的方法,可以对文件内容进行读写

Properties读取属性文件中的键值对案例:
package com.sesameseed.p1_propertieswriteload;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
import java.util.Set;
/*
属性文件.properties特点
1.存储的数据都只能是键值对
2.键不能重复
3.文件后缀一般是.properties
Properties
本质是一个Map集合,但是我们不会当集合使用
Properties是用来代表属性文件的,通过它提供的方法,可以对文件内容进行读写
Properties相关方法
构造方法
* public Properties(); 创建Properties集合(属性文件)对象
加载方法(读)
public void load(InputStream is); 读取文件中的键值对数据
* public void load(Reader reader); 读取文件中的键值对数据
* public String getProperty(String key); 根据键获取值 (类似get方法)
* public Set stringPropertyNames(); 获取所有键的集合 (类似keySet方法)
存储方法(写)
public Object setProperty(String key, String value);
public void store(OutputStream os, String comments);
public void store(Writer w, String comments);
*/
public class Demo1 {
public static void main(String[] args) throws IOException {
//publicProperties();创建Properties集合(属性文件)对象
Properties p = new Properties();
//public:void.load(Reader:reader);· 读取文件中的键值对数据
p.load(new FileReader("day20\\users.properties"));
System.out.println(p);
System.out.println("-------------------");
//publicString getProperty(string key);根据键获取值(类get方法)
System.out.println(p.getProperty("zhangsan")); //18
System.out.println(p.getProperty("zhangliu")); //null 无此键 map集合返回null
System.out.println("-------------------");
//public SetstringPropertyNames(); 获取所有键的集合(类似keySet方法)
Set<String> keys = p.stringPropertyNames();
for (String key : keys) {
System.out.println(key);
}
}
}
使用Properties往属性文件中写键值对:

package com.sesameseed.p1_propertieswriteload;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Properties;
/*
构造方法
* public Properties(); 创建Properties集合对象
存储方法(写)
* public Object setProperty(String key, String value);
public void store(OutputStream os, String comments);
* public void store(Writer w, String comments);
注释中文乱码的解决
File - Settings - Editor - File Encodings
Properties Files(*.properties)选择 - UTF-8 - 后面勾选!
*/
public class Demo2 {
public static void main(String[] args) throws IOException {
//public Properties(); 创建Properties集合对象
Properties p = new Properties();
//public Object setProperty(String key, String value);
p.setProperty("zhangsan", "xian");
p.setProperty("lisi", "shanghan");
p.setProperty("wangwu", "beijing");
//public void store(Writer w, String comments);
p.store(new FileWriter("day20\\info.properties"), "我是注释");
}
}
20.2 XML文件
XML是可扩展的标记语言,由标签组成 的,标签是自定义的。本质是一种数据格式,可以用来表示复杂的数据关系。
- XML中的
<标签名>称为一个标签或者一个元素,一般是成对出现的。- XML中的标签名可以自己定义(可扩展),但是必须要正确的嵌套
- XML中只能有一个根标签。
- XML标准中可以有属性
- XML必须第一行有一个文档声明,格式是固定的
- XML文件必须是以.xml为后缀结尾
<users>
<user id="1">
<name>张无忌name>
<gender>男gender>
<address>光明顶address>
user>
<user id="2">
<name>赵敏name>
<gender>女gender>
<address>西安address>
user>
<data>
< > & ' "
<> && "" '']]>
data>
users>
20.2.1 XML解析1(基于DOM4J解析框架)
DOM4J解析XML文件的思想是:文档对象模型(意思是把整个XML文档、每一个标签、每一个属性都等都当做对象来看待)。Dowument对象表示真个XML文档、Element对象表示标签(元素)、Attribute对象表示属性、标签中的内容就是文本
DOM4J提供的相关方法
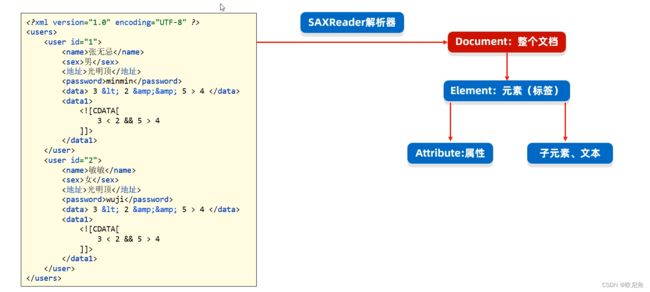

案例演示,解析XML并存入对象中:
对象分类
- Document: 整个xml文档对象
- Element: 标签对象
- Attribute: 属性对象
- Text标签体: 文本对象
package com.sesameseed.p2_dom4j;
public class User {
private String id;
private String name;
private String gender;
private String address;
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("User{");
sb.append("id='").append(id).append('\'');
sb.append(", name='").append(name).append('\'');
sb.append(", gender='").append(gender).append('\'');
sb.append(", address='").append(address).append('\'');
sb.append('}');
return sb.toString();
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public User(String id, String name, String gender, String address) {
this.id = id;
this.name = name;
this.gender = gender;
this.address = address;
}
public User() {
}
}
package com.sesameseed.p2_dom4j;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import javax.xml.transform.Source;
import java.util.ArrayList;
import java.util.List;
/*
DOM解析思想?
DOM (document Object Model)文档对象模型
将文档的各个组成部分看做是对应的对象
首先会将xml文件全部加载到内存,在内存中形成一个树状结构,在获取对应的值
对象分类
Document: 整个xml文档对象
Element: 标签对象
Attribute: 属性对象
Text标签体: 文本对象
重点记忆
DOM解析思想就是一层一层的进入,一层一层的解析
常见的解析工具
DOM4J: 开源组织提供的一套xml解析的API-dom4j (全称Dom for Java)
下载官网: https://dom4j.github.io
DOM4J准备工作
将jar包拖入lib文件夹下
对着jar包右键Add As Library...
查看API获取Document文档对象
*/
public class Demo1 {
public static void main(String[] args) throws Exception {
//创建集合,用来存储user对象
ArrayList<User> list = new ArrayList<>();
//获取解析器对象
SAXReader reader = new SAXReader();
//获取文档对象
Document document = reader.read("day20\\users.xml");
//获取根标签对象
Element rootElement = document.getRootElement();
//System.out.println(rootElement.getName());
//获取所有user字标签的集合
List<Element> userList = rootElement.elements("user");
//遍历集合获取每一个user标签对象
for (Element element : userList) {
//获取id属性对象,通过对象获取id值
String id = element.attribute("id").getValue();
//获取name标签对象,通过对象获取name值
String name = element.element("name").getText();
//获取gender标签对象,通过对象获取gender值
String gender = element.element("gender").getText();
//获取address标签对象,通过对象获取address值
String address = element.element("address").getText();
//封装成User对象,分别存入集合
User user = new User(id, name, gender, address);
list.add(user);
}
//打印集合展示内容
for (User users : list) {
System.out.println(users);
}
}
}
20.2.2 XML文件写入
使用StringBuilder按照标签的格式拼接,再使用BufferedWriter写到XML文件中。
package com.sesameseed.p3_xmlappend;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class Demo1 {
/*
如何从程序中写数据到mxl中?
不建议用DOM4J将,数据写入到xml文件中
推荐在java代码中,将数据拼接成xml格式,用IO流写出去
案例需求
将如下数据写入到book.mxl中
删库跑路
李明
89.5
* */
public static void main(String[] args) throws IOException {
//创建sb对象
StringBuilder sb = new StringBuilder();
//拼接数(细心)
sb.append("\r\n");
sb.append("\r\n" );
sb.append("\t删库跑路 \r\n");
sb.append("\t李明 \r\n");
sb.append("\t89.5 \r\n");
sb.append("");
//字符输出流写数( 一个字符申)
BufferedWriter bw = new BufferedWriter(new FileWriter("day20\\books.xml"));
bw.write(sb.toString());
bw.flush();
bw.close();
System.out.println("success");
}
}
20.2.3 XML约束
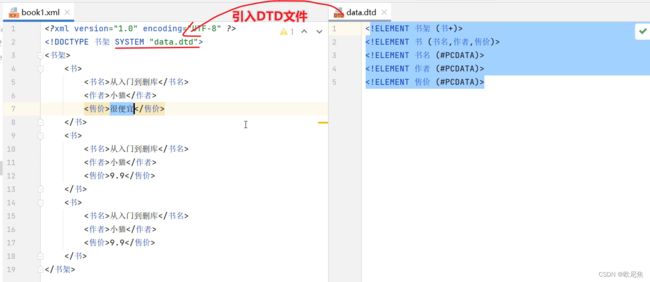
- DTD约束案例
如下图所示book.xml中引入了DTD约束文件,book.xml文件中的标签就受到DTD文件的约束
- 表示根标签是<书架>,并且书架中有子标签<书>
- 表示书是一个标签,且书中有子标签<书名>、<作者>、<售价>
- 表示<书名>是一个标签,且<书名>里面是普通文本
- 表示<作者>是一个标签,且<作者>里面是普通文本
- 表示<售价>是一个标签,且<售价>里面是普通文本
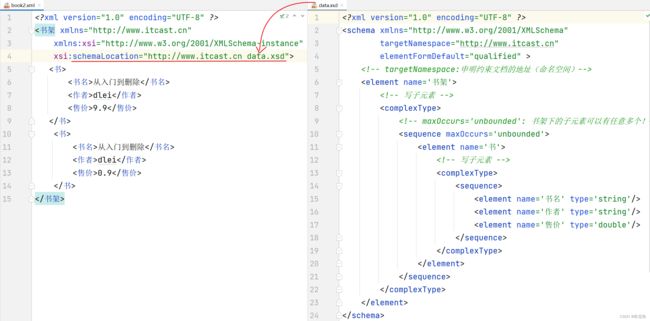
- Schame约束案例
20.3 日志技术
日志:通常就是一个文件,记录程序运行过程中产生的各种数据。
日志技术有如下好处
- 日志可以将系统执行的信息,方便的记录到指定位置,可以是控制台、可以是文件、可以是数据库中。
- 日志可以随时以开关的形式控制启停,无需侵入到源代码中去修改。
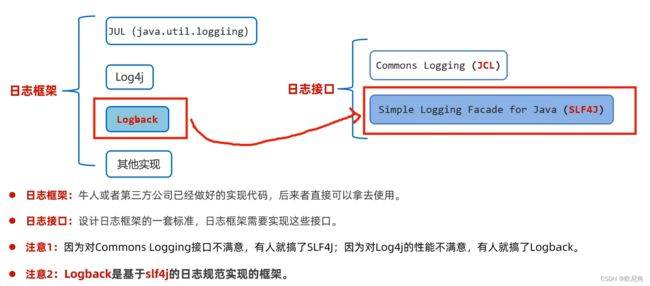
20.3.1 日志框架与日志接口
20.3.2 Logback快速入门
package com.sesameseed.p4_logdemo;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/*
日志的体系结构
规范接口
Jakarta Commons Logging(commons-logging) (JCL)
Simple Logging Facade for Java (SLF4J)
实现框架
Log4j
JUL(java.util.logging)
Logback
Logback
Logback是基于slf4j日志规范实现的框架,性能比Log4j好 (同一个作者)
官方网站 https://logback.qos.ch/index.html
技术模块
logback-core: 核心模块,另外两个模块的基础,必须有
logback-classic: 完整实现了SLF4J的模块,必须有
logback-access: 与Tomcat和Jetty等Servlet容器集成,提供HTTP访日日志功能,后面具体使用
*/
/*
logback快速入门
将jar包拖入lib文件夹下,对着jar包右键Add As Library...
src下导入配置文件logback.xml
查看API获取日志对象LOGGER
private static final Logger LOGGER = LoggerFactory.getLogger("类名");
记录日志
LOGGER.info(String info);
LOGGER.debug(String info);
LOGGER.error(String info);
*/
public class Demo1 {
//getLogger 方法的参数传当前类名的字符串形式
private static final Logger LOGGER = LoggerFactory.getLogger("Demo1");
public static void main(String[] args) {
try {
LOGGER.info("Division Begin");
division(5, 0);
LOGGER.info("Division Run Success");
} catch (Exception e) {
// e.printStackTrace();
LOGGER.error("division do not run success , code has a bug");
}
}
public static void division(int a, int b) {
LOGGER.debug("parameter A:" + a);
LOGGER.debug("parameter B:" + b);
int c = a / b; //这是存在一个ArithmeticException运算异常(运行时异常),不需要立刻处理,运行后出现,如果没处理会抛给调用者
LOGGER.info("result is" + c);
}
}
20.3.3 日志配置文件
- 如下图所示,控制日志往文件中输出,还是往控制台输出
- 如下图所示,控制打开和关闭日志
- *如下图所示,控制日志的输出的格式
日志格式是由一些特殊的符号组成,可以根据需要删减不想看到的部分。比如不想看到线程名那就不要[%thread]。但是不建议更改这些格式,因为这些都是日志的基本信息。



20.3.4 配置日志级别
在哪里配置日志级别呢?如下图所示


20.4 多线程
线程其实是程序中的一条执行路径。
20.4.1 线程创建方式1
线程类Thread
创建线程并执行线程的步骤如下:
1.定义一个子类继承Thread类,并重写run方法
2.创建Thread的子类对象
3.调用start方法启动线程(启动线程后,会自动执行run方法中的代码)
package com.sesameseed.p5_thread.multithreaddemo1;
//1.定义MyThread类继承Thread美,重写run方法封装这条线程要做的事情
public class MyThread extends Thread{
@Override
public void run() {
for (int i = 1; i <= 20; i++) {
System.out.println("子线程执行了" + i);
}
}
}
package com.sesameseed.p5_thread.multithreaddemo1;
public class Demo1 {
/*
什么是线程
线程(Thread)是一个程序内部的一条执行流程
程序中如果只有一条执行流程,那么该程序称为单线程程序
什么是多线程?
多线程是指从软硬件上,实现多条执行流程的技术(多条线程由CPU负责调度执行)
多线程的应用场景?
12306
百度网盘上传下载
消息通信边发边收
淘宝京东等
如何在程序中创建出多条线程?
Java是通过java.lang.Thread类的对象来代表线程的
根据查阅API,掌握多线程的实现方式一
1.定义MyThread类继承Thread类,重写run方法封装这条线程要做的事情
2.测试类中,创建MyThread类的对象
3.调用继承来的start方法启动线程
实现方式一优缺点
优点是编码简单,调用方法方便
缺点是已经继承Thread类,就不能继承其他类,扩展性低
*/
/*
* 多线程的实现方式1根据查阅API,掌握多线程的实现方式一
1.定义MyThread类继承Thread类,重写run 方法封装这条线程要做的事2.测试类中,创建MyThread美的对象
3。调用继承来的start 方法启动线程
实现方式一优缺点
优点是编码简单,调用方法方便缺点是已经继Thread类,就不能继承其他美,扩展性低
*
* */
public static void main(String[] args) {
//2.测试类中,创建MyThread美的对象
MyThread mt = new MyThread();
//3.调用继承来的start方法启动线程
mt.start();
//模拟主线程任务
for (int i = 1; i <= 20; i++) {
System.out.println("主线程执行了" + i);
//结果是随机的,所以多运行几遍查看
}
}
}
10.4.2 线程创建方式2
通过Runnable接口的实现类,、重写runnable的run方法
具体步骤如下:
1.先写一个Runnable接口的实现类,重写run方法(这里面就是线程要执行的代码)
2.再创建一个Runnable实现类的对象
3.创建一个Thread对象,把Runnable实现类的对象传递给Thread
4.调用Thread对象的start()方法启动线程(启动后会自动执行Runnable里面的run方法)
package com.sesameseed.p5_thread.multithreaddemo2;
/*
* 根据查阅API,掌握多线程的实现方式二
1.定义MyRunnable类实现Runnable接口,重写run方法封装这条线程要做的事情
2.测试类中,创建MyRunnable类的对象,作为参数传递给Thread对象
3.调用Thread对象的start方法启动线程
* */
public class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 1; i <= 20; i++) {
System.out.println("子线程3执行了" + i);
}
}
}
package com.sesameseed.p5_thread.multithreaddemo2;
public class Demo1 {
/*
根据查阅API,掌握多线程的实现方式二
1.定义MyRunnable类实现Runnable接口,重写run方法封装这条线程要做的事情
2.测试类中,创建MyRunnable类的对象,作为参数传递给Thread对象
3.调用Thread对象的start方法启动线程
实现方式二优缺点
优点是扩展性强
缺点是编码复杂,因为没有直接继承Thread类,Thread类的方法不能直接调用
*/
public static void main(String[] args) {
//普通方式开启线程
MyRunnable target = new MyRunnable();
Thread t = new Thread(target);
t.start();
//匿名内部类开启线程
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 20 ; i++) {
System.out.println("子线程1执行" + i);
}
}
}).start();
//Lambda
new Thread(() -> {
for (int i = 1; i <= 20 ; i++) {
System.out.println("子线程1执行" + i);
}
}).start();
for (int i = 1; i <= 20 ; i++) {
System.out.println("main线程执行" + i);
}
}
}
20.4.3 线程创建方式3—匿名内部类(基于方式一、二)
注意:这种写法不是新知识将前面第二种方式用匿名内部类改写一下
package com.sesameseed.p5_thread.Anonymousnuthreaddemo3;
public class Demo {
public static void main(String[] args) {
// 1、直接创建Runnable接口的匿名内部类形式(任务对象)
Runnable targe = new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
System.out.println("子线程1输出:" + i);
}
}
};
new Thread(targe).start();
// 简化形式1:
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
System.out.println("子线程2输出:" + i);
}
}
}).start();
// 简化形式2:
new Thread(() -> {
for (int i = 1; i <= 5; i++) {
System.out.println("子线程3输出:" + i);
}
}).start();
for (int i = 1; i <= 5 ; i++) {
System.out.println("主线程main输出:" + i);
}
}
}
Day23:单元测试、反射、注解、动态代理
23.4 动态代理
23.4.1 动态代理介绍、准备功能
介绍:在艺人演出收费过程中,艺人不但要唱歌、跳舞演出,在每次唱歌的过程中还要准备话筒、收钱再唱歌;在跳舞的时候也要准备场地、收钱再唱歌,完成收费,每次唱歌跳舞前准备太繁琐,就可以找经纪公司,作为自己的代理人,如果有人请艺人唱歌就直接找代理人,艺人只管演出就可以。
准备功能:
唱歌、跳舞接口:package com.sesameseed.d4_proxy.demo1; public interface Star { String sing(String name); void dance(); }
实现接口的艺人类:package com.sesameseed.d4_proxy.demo1; public class BigStar implements Star { private String name; public BigStar(String name) { this.name = name; } @Override public String sing(String name) { System.out.println(this.name + "正在唱" + name); return "谢谢"; } @Override public void dance() { System.out.println(this.name + "正在跳舞"); } }
23.4.2 生成动态代理对象、invoke方法
通过Proxy类的newInstance(…)方法可以为实现了同一接口的类生成代理对象。 调用方法时需要传递三个参数,该方法的参数解释可以查阅API文档,如下。
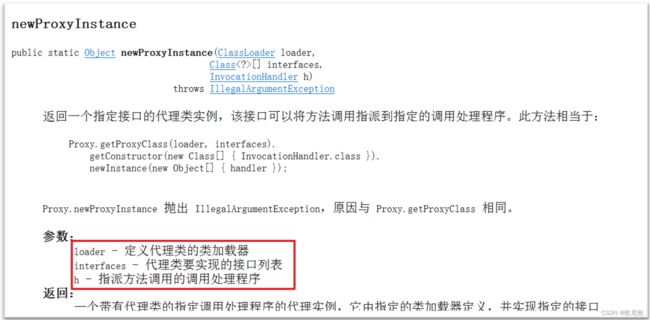
23.4.2.1 newProxyInstance方法源码详解
注意:方法返回值object,所以要强转

| 参数名 | 解释 |
|---|---|
| classLoader | 类加载器。可以通过getClass().getClassLoader()获取 |
| intefaces | 绑定的接口,将代理对象绑定到哪些接口下面,可多个 |
| invocationHandle | 绑定代理对象的实现逻辑,传入一个实现了InvocationHandler接口的类 |
23.4.2.2 代理工具类实现
| 方法名 | 解释 |
|---|---|
| invoke(… …) | 代理对象要做的事情,在这里写代码 |
public class ProxyUtil {
public static Star createProxy(BigStar bigStar){
/* newProxyInstance(ClassLoader loader,
Class[] interfaces,
InvocationHandler h)
参数1:用于指定一个类加载器
参数2:指定生成的代理长什么样子,也就是有哪些方法
参数3:用来指定生成的代理对象要干什么事情
*/
// Star starProxy = ProxyUtil.createProxy(s);
// starProxy.sing("好日子") starProxy.dance()
Star starProxy = (Star) Proxy.newProxyInstance(ProxyUtil.class.getClassLoader(),
new Class[]{Star.class}, new InvocationHandler() {
@Override // 回调方法
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 代理对象要做的事情,会在这里写代码
if(method.getName().equals("sing")){
System.out.println("准备话筒,收钱20万");
}else if(method.getName().equals("dance")){
System.out.println("准备场地,收钱1000万");
}
return method.invoke(bigStar, args);
}
});
return starProxy;
}
}
23.4.2.3 测试方法
package com.sesameseed.d4_proxy.demo1;
public class Test {
public static void main(String[] args) {
BigStar s = new BigStar("艺人");
Star starProxy = ProxyUtil.createProxy(s);
String rs = starProxy.sing("好日子");
System.out.println(rs);
starProxy.dance();
}
}