TCP原理
TCP概述
tcp是一个面向连接、可靠的、基于字节流的传输层协议
参考:https://blog.csdn.net/weixin_41835916/article/details/126042272
- 面向连接
面向连接意味着,就是要建立连接,维护各种状态,以及缓存数据等 - 可靠性
- 数据分割:tcp会将数据报文分割成最适合发送的数据块
- 校验机制:tcp报文头有个校验和
- 确认机制:绝大部分情况,TCP发送都需要对方回复一个确认,只有这样才能知道对方确实收到了。确认机制还会确认有序性,就是告知下一个seq,如果中间缺失,也会告知重发
- 超时重发:首先就是要把发出的报文通过滑动窗口缓存起来,每个段2发出后,都需要配套一个定时器(实现上可以通过优先队列定时器等),如果不能超时不能收到明确的确认,就需要重发。被动重发,就是另一端告知,前面的某个数据段我还没收到
- 幂等:有重发就必然有幂等,通过sequence,把已经确认的通过一个滑动窗口(排序好的)记录下来,如果已经确认过的,不会再处理重发过来的
- 有序性:通过sequence排序,合并处理给到应用层。中间缺失的也会通知对法重发,保证数据不确实
- 流量控制:每一方都有一个固定的缓冲空间,处理不过来,就通知对方慢点发。
校验机制
- 发送方将整个报文段分为多个 16 位的段,然后将所有段进行反码相加,将结果存放在检验和字段中,接收方用相同的方法进行计算,如最终结果为检验字段所有位是全 1 则正确,否则存在错误;
- 如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段;
序列号
TCP 会对每个包都进行编号,序列号的作用是:优化确认机制,应答方告知已确认好的序号,返回ACK 下一个序号
- 保证可靠性(当接收到的数据中少了某个序号的数据时,能马上知道);缺了,应答方会告知,也可以让客户端及时删掉不必要的定时器
- 保证数据的按序到达;后面不漏的也可以排序,使其有序
- 提高效率,可实现多次发送,一次确认;
- 去除重复数据;幂等
确认应答机制(ACK)
发送后应答,才能确保确实发送到了,通过Seq可以优化应答机制
- TCP 通过确认应答机制实现可靠的数据传输。在 TCP 的首部中有一个标志位 —— ACK,此标志位表示确认号是否有效;
- 接收方对于按序到达的数据会进行确认,当标志位 ACK = 1 时,首部的确认字段有效。进行确认时,确认字段值表示这个值之前的数据都已经按序到达了;
- 而发送方如果收到了已发送的数据的确认报文,则继续传输下一部分数据;而如果等待了一定时间还没有收到确认报文就会启动重传机制;
超时重传机制(以及幂等)
当报文发出后在一定的时间内未收到接收方的确认,发送方就会进行重传(通常是在发出报文段后设定一个闹钟定时器,到点了还没有收到应答则进行重传)
当然,未收到确认不一定就是发送的数据包丢了,还可能是确认的 ACK 丢了,实际上通过Sequence的优化,每次ACK并不只是对当前请求的回应,回复的是哪些我已经处理好了,下一个要发送的序列号是啥
有Sequence,很容易幂等
重传时间的确定
报文段发出到收到应答中间有一个报文段的往返时间 RTT,显然超时重传时间 RTO 会略大于这个 RTT;小于肯定与不行的,因为老早就开始重传,浪费也拥堵,太长也不行,太长也不行,尽量快的一致性是必然的选择,一直让中间缺个口子,后面业务都没法进行。重试时间多次后也是递增的形式。
TCP会根据网络情况动态的计算 RTT,即 RTO 是不断变化的。在 Linux 中,超时以 500ms 为单位进行控制,每次判定超时重发的超时时间都是 500ms 的整数倍;
其规律为:如果重发一次仍得不到应答,就等待 2 * 500ms 后再进行重传,如果仍然得不到应答就等待 4 * 500ms 后重传,依次类推,以指数形式递增;
重传次数累计到一定次数后,TCP 认为网络或对端主机出现异常,就会强行关闭连接;
连接管理机制
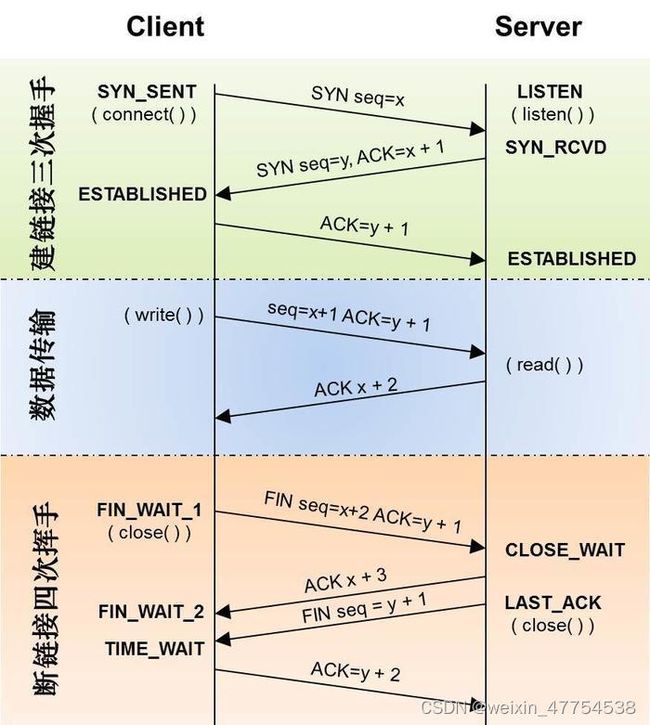
三次握手
一个是方法方做初始化,滑动窗口,确认窗口等等,更重要的是双方要确认Sequence,理论上A–>B发送和确认各一次,B–>A也是发送和确认各一次,B的确认和发送合并成一次了,所以是3次,如果失败了,可以通过超时重发等机制保证可以最终到达。其实也是两阶段握手,只是B给的确认和B发起的初始seq请求两个合并成一次了
为什么两次不行:第二次如果丢了,可以通过重试保证到达,但是B的初始序号无法保证A已经收到。如果真的没收到,就有问题,因为没有初始序号(不是确保收到,其实两次大部分情况都是可以双方的知道对方的初始序号的),如果真的没有确认,那么B发数据过去,A因为没有初始序号就丢弃了,然后B一直重试,死锁了。如果A直接处理呢,就当这个是初始序号??显然有可能后面的先进来,特别是如果这期间,过期的连接的数据包再过来,你把他当成初始序号,那不完蛋了
四次挥手
其实也是两阶段挥手,为啥不能合并成3次,因为A数据发完了,B可能还没有发完,所以最好是先回音,后续自己数据真的发完了,再单独发起FIN请求
为什么 TIME_WAIT 状态还需要等 2MSL 后才能返回到 CLOSED 状态
理论上多少次挥手都没啥作用,因为不管哪一方先关闭,只要关闭重发机制就失效了,关闭的最后一次请求没发送到怎么办,另一方只能一直等,阻塞等待就必须有超时机制
为什么服务端还要有个心跳机制,保活机制
正常情况,客户端如果暂时没有数据,或者没准备好,那么会空着连接,过一会再发。如果真的没有数据,就会发起挥手操作。你没办法判断是暂时没数据传送,还是客户端已经挂掉了。因为暂时没数据,其实就是个阻塞状态,有阻塞,阻塞往往和心跳、超时机制搭配使用。一种是阻塞等待对方回复,那么就是设置超时时间。一种是自己去拉取,其实就是心跳
流量控制
TCP头有16位(实际上可以扩展)是用来告知对方我的缓冲区还剩余多少,知道对方缓冲区满了,就不发送了。
阻塞往往和心跳、超时机制搭配使用,客户端时不时请求一下,看空下来了没,当然心跳由接收端发起也可以,就是自己又有空闲了,就告知对方一下
拥塞控制
流量控制解决的是两方处理能力不一致的问题,那么网络(传输线路)是不是也可能出现状况不好的情况,尽管TCP两方都很空闲,但是网络不好呀,就会出现很多超时,如果此时超时就重发,网络更加扛不住了。极限情况还会触发超时重发机制的重发上限,最后直接就丢包了。
TCP 引入慢启动机制,先发出少量数据,就像探路一样,先摸清当前的网络拥堵状态后,再决定按照多大的速度传送数据
拥塞窗口(cwnd)
发送开始时定义拥塞窗口大小为 1;每次收到一个 ACK 应答,拥塞窗口加 1;而在每次发送数据时,发送窗口取拥塞窗口与发送端接收窗口最小者;
拥塞窗口的维护原则:只要网络没有出现拥塞,拥塞窗口就再增大一些,但只要网络出现拥塞,拥塞窗口就会减少一些
判断出现网络拥塞的依据:没有按时收到应当到达的确认报文(即发生超时重传)
拥塞控制算法1:慢启动
维护一个慢开始门限 ssthresh 状态变量
当 cwnd < ssthresh 时,使用慢开始算法;
当 cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法;
当 cwnd = ssthresh 时,既可使用慢开始算法,也可使用拥塞避免算法;
在启动初期以指数增长方式增长;设置一个慢启动的阈值,当以指数增长达到阈值时就停止指数增长,按照线性增长方式增加;
拥塞控制算法2:拥塞避免
线性增长达到网络拥塞时(重传计数器超时)立即"乘法减小",拥塞窗口置回 1,进行新一轮的“慢启动”,同时新一轮的阈值变为原来的一半;
————————————————
版权声明:本文为CSDN博主「北极星小王子」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_41835916/article/details/126042272