Databend + lakeFS:将数据版本控制嵌入你的分析工作流
作者:尚卓燃(PsiACE)
澳门科技大学在读硕士,Databend 研发工程师实习生
Apache OpenDAL(Incubating) Committer
PsiACE (Chojan Shang) · GitHub

云计算为以数据为中心的应用提供了廉价、弹性、共享的存储服务,这为现代数据处理工作流提供了显而易见的好处:海量数据、高并发访问、大吞吐量,越来越多的案例开始将旧有的技术栈向数据湖架构进行迁移。
当我们将数据湖置于云端之后,新的问题随之而来:
-
旧有的数据仓库/大数据分析技术可能并不是专为云和对象存储设计的,性能和兼容性可能不太理想,需要投入大量的资源进行维护,如何为数据湖提供真正现代的、低成本、高性能、高质量的分析服务?
-
对数据管理的需求仅一步加强,对分析结果的可复现性、数据源的可共享性提供了更高的要求,如何为数据提供弹性和可管理性,让数据科学家、数据分析师和数据工程师在逻辑一致的视图下紧密协作?
有问题,就会有答案!
Databend 基于云上的对象存储打造了真正跨云且原生的数据仓库。采用 serverless 理念设计,提供分布式、弹性可拓展、运维方便的高性能查询引擎,支持常见的结构化与半结构化数据,能够与现代数据技术栈进行紧密集成。
lakeFS 致力于为共享和协作处理数据提供解决方案。用类似 Git 的操作逻辑赋能对象存储,采用版本化方案为数据提供逻辑一致的视图,为现代化数据工作流嵌入有意义的分支名和提交信息,并且为数据、文档的一体化提供解决方案。
在这篇文章中,我们将会结合二者,提供一个简单清晰的 workshop,帮助你快速搭建现代化的数据工作流。
为什么你需要 Databend
随着数据量的激增,传统的数据仓库面临着巨大的挑战。它们无法有效地存储和处理海量数据,也难以根据工作负载弹性调整计算和存储资源,导致使用成本高昂。此外,数据处理复杂,需要投入大量资源进行 ETL,数据回退和版本控制也非常困难。
Databend 致力于解决这些痛点。它是一款使用 Rust 开发的开源、弹性、负载感知的云数据仓库,能够为超大规模数据集提供经济高效的复杂分析能力。
-
云友好: 无缝集成各种云存储,如 AWS S3、Azure Blob、CloudFlare R2 等。
-
高性能: 使用 Rust 开发,利用 SIMD 和向量化处理实现极速分析。
-
经济弹性: 创新设计,存储和计算独立伸缩,优化成本和性能。
-
简易数据管理: 内置数据预处理能力,无需外部 ETL 工具。
-
数据版本控制: 提供类似 Git 的多版本存储,支持任意时间点的数据查询、克隆和回退。
-
丰富的数据支持: 支持 JSON、CSV、Parquet 等多种数据格式和类型。
-
AI 增强分析: 集成 AI 函数,提供由大模型驱动的数据分析能力。
-
社区驱动: 拥有友好、持续增长的社区,提供易用的云上分析平台。
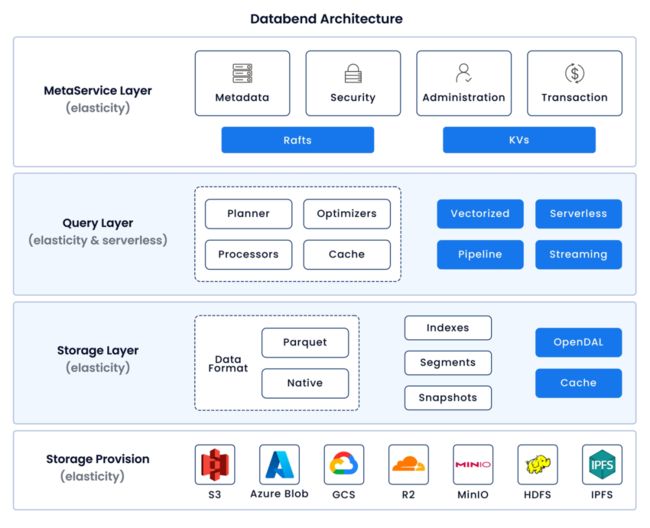
上图为 Databend 架构图,摘自datafuselabs/databend 。
为什么你需要 lakeFS
由于对象存储往往缺乏原子性、回滚等能力,数据的安全性不能很好地得到保证,质量和可恢复性也随之下降。为了保护生产环境的数据,往往不得不采用隔离副本的形式进行预演测试,消耗资源不说,还难以真正进行协同工作。
提到协同,你可能会想到 Git ,但 Git 并不是为数据管理而设计的,除了二进制数据管理不便之外,Git LFS 对单个文件大小的限制也制约了其适用场景。
lakeFS 应运而生,它提供用于数据湖的开源数据版本控制 — branch, commit, merge, revert,就像使用 Git 管理代码一样。由于支持零拷贝开发/测试隔离环境、连续质量验证、错误数据的原子回滚、可重复性等高级特性,你甚至可以轻松在生产数据上验证 ETL 工作流,而不再担心对业务造成损害。

上图为 lakeFS 推荐的数据工作流,摘自 Git for Data - lakeFS 。
Workshop:使用 lakeFS 加持你的分析业务
在这个 workshop 中,我们将会利用 lakeFS 为存储库创建分支,并使用 Databend 对预置数据进行分析和转换。
由于实验环境包含一些依赖,第一次启动可能用时较久。我们更推荐使用 Databend Cloud + lakeFS cloud 的组合,这样你就可以跳过耗时颇多的 环境设置 部分,直接上手体验 数据分析 与转换。
环境设置
本次使用的环境中除了 lakeFS 之外,还将包括作为底层对象存储服务的 MinIO ,以及 Jupyter 、Spark 等常用的数据科学工具。 你可以查看 这个 git 存储库了解更多相关信息。
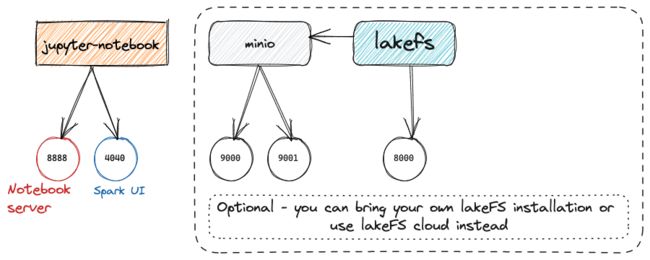
上图为本次实验环境的示意图,摘自 treeverse/lakeFS-samples 。
克隆存储库
git clone https://github.com/treeverse/lakeFS-samples.git
cd lakeFS-samples启动全栈实验环境
docker compose --profile local-lakefs up一旦启动实验环境,你就可以使用默认配置登录 lakeFS 和 MinIO,以在后续的步骤中观察数据的变化。
数据观察
在环境设置过程中,会在 lakeFS 中预先准备一个名为 quickstart 的存储库,在这一步中,我们将会对其进行一些简单的观察。
如果你使用自己部署的 lakeFS + MinIO 环境
- 可能需要先自己手动在 MinIO 中创建对应的 bucket 。

- 再在 LakeFS 中创建对应的存储库,并勾选填充示例数据。
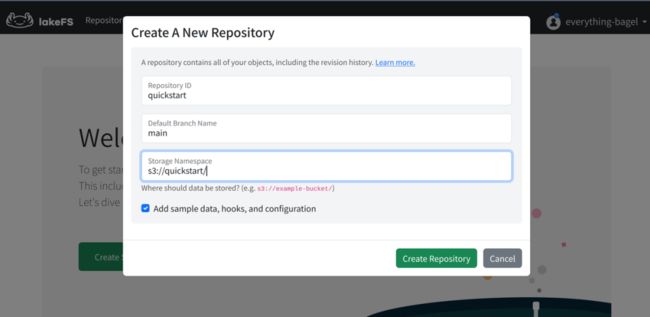
lakeFS
在浏览器打开 lakeFS(http://127.0.0.1:8000),输入 Access Key ID 和 Secret Access Key 就可以登录到 lakeFS 。
接着打开 quickstart 存储库,可以看到已经存在一些默认的数据,并且还包含一个默认教程。
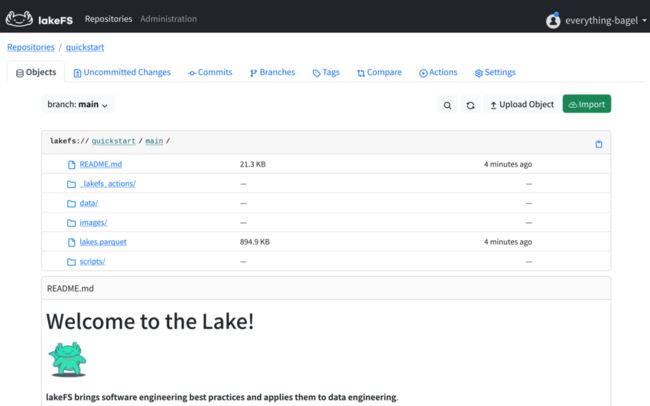
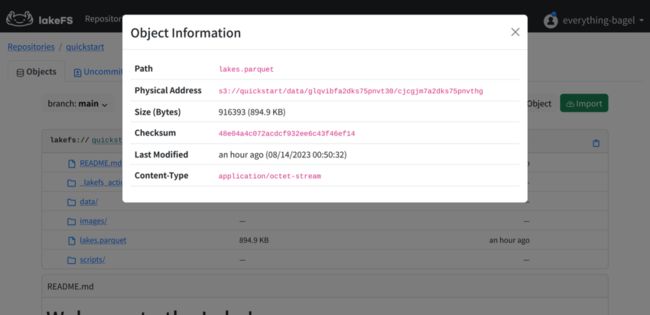
lakeFS 的数据存储库模式几乎与 GitHub 之类的代码存储库对应,几乎没有什么学习成本:其中 lakes.parquet为预先准备好的数据,data 文件夹中的 lakes.source.md 介绍了数据的来源 ; scripts 文件夹包含用于数据校验的脚本,其完整的工作流可以在_lakefs_actions 目录下找到,编写形式类似 GitHub Actions ;README.md 对应下方教程的 Markdown 源文件,而 images 中包含了使用的全部图像。
MinIO
由于在实验环境中,我们使用 MinIO 作为底层存储,所以在 MinIO 中也可以找到一个名为 quickstart 的 bucket 。这是由 lakeFS 创建存储库时的 StorageNamespace 决定的。
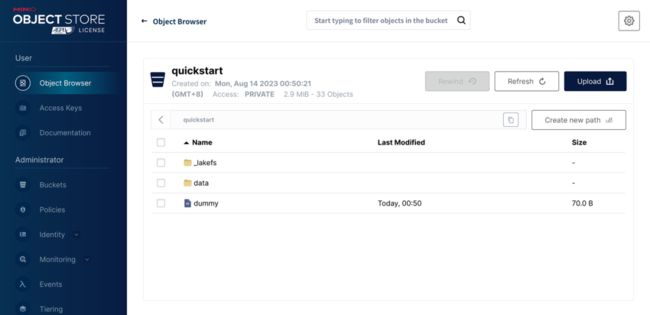
其中,dummy 文件是新建 lakeFS 存储库时就会创建的,用来确保我们有足够的权限写入 bucket 。
而 _lakefs 目录中只包含两个文件,从 S3 等数据源导入数据时创建,用来标识对导入文件原始位置的一些引用。
通过 lakeFS 编写的新对象则会位于 data 目录下。
数据的对应
打开 data 目录,我们可以找到一些文件,但很难与 lakeFS 中的数据对应起来。
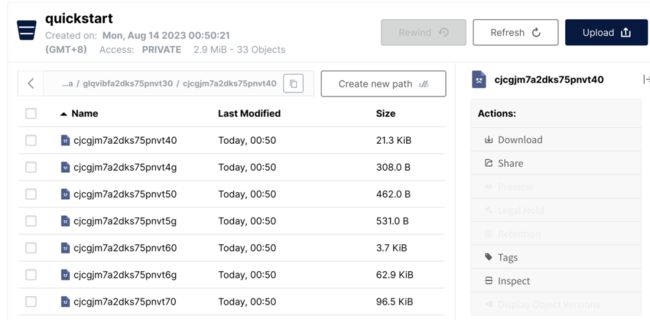
让我们回到 lakeFS ,点击文件右侧的齿轮图标,再选中 Object Info 就可以轻松找出对应关系。
数据分析 与转换
在这一步中,我们将会部署 Databend 服务,通过 Stage 挂载 lakeFS 中的数据并进行分析,并用转换后的结果替换 denmark-lakes 分支中的 lakes.parquet 数据文件。
部署 Databend
Databend 的存储引擎同样支持 Time Travel、原子回滚等高级特性,无需担心操作失误。
这里我们使用单节点 Databend 服务的形式,以 MinIO 作为存储后端。总体上部署过程可以参考 Databend 官方文档 ,需要注意的一些细节如下:
-
由于我们已经在上面的步骤中部署了 MinIO 服务,这里只需要打开
127.0.0.1:9000创建一个名为databend的 Bucket 。 -
接着需要为日志和 Meta 数据准备相关的目录
sudo mkdir /var/log/databend
sudo mkdir /var/lib/databend
sudo chown -R $USER /var/log/databend
sudo chown -R $USER /var/lib/databend- 其次,因为默认的
http_handler_port已经被前面的服务占用掉,所以需要编辑databend-query.toml进行一些修改避免冲突:
http_handler_port = 8088- 另外,我们还需要根据 Docs | Configuring Admin Users 配置管理员用户,由于只是一个 workshop ,这里选择最简单的方式,只是取消
[[query.users]]字段以及 root 用户的注释:
[[query.users]]
name = "root"
auth_type = "no_password"- 由于我们使用 MinIO 作为存储后端,所以需要对
[storage]进行配置。
[storage]
# fs | s3 | azblob | obs | oss
type = "s3"
# To use S3-compatible object storage, uncomment this block and set your values.
[storage.s3]
bucket = "databend"
endpoint_url = "http://127.0.0.1:9000"
access_key_id = "minioadmin"
secret_access_key = "minioadmin"
enable_virtual_host_style = false接下来就可以正常启动 Databend :
./scripts/start.sh我们强烈推荐你使用 BendSQL 作为客户端,由于 http_handler_port 端口变更,需要使用 bendsql -P 8088 连接 Databend 服务。当然,我们也支持像 MySQL Client 和 HTTP API 等多种访问形式。
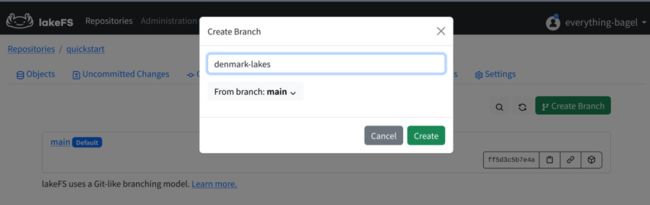
创建分支
lakeFS 的使用方法与 GitHub 类似,打开 Web UI 的 branches 页面 ,点击 Create Branch 按钮,创建一个名为 denmark-lakes 的分支。
创建 Stage
Databend 可以通过 Stage 来挂载位于远端存储服务的数据目录。由于 lakeFS 提供 S3 Gateway API,所以我们可以按照 s3 兼容服务进行配置连接。需要注意的是,此处的 URL 需要按照 s3:// 进行构造,而且 lakeFS 的 ENDPOINT_URL 为 8000 端口。
CREATE STAGE lakefs_stage
URL='s3://quickstart/denmark-lakes/'
CONNECTION = (
REGION = 'auto'
ENDPOINT_URL = 'http://127.0.0.1:8000'
ACCESS_KEY_ID = 'AKIAIOSFOLKFSSAMPLES'
SECRET_ACCESS_KEY = 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY');通过执行下述 SQL 语句,我们可以过滤出目录中 Parquet 格式的数据文件。
LIST @lakefs_stage PATTERN = '.*[.]parquet';
由于 Databend 已经支持 SELECT form Stage 能力,无需导入数据也可以进行基本的查询。
SELECT * FROM @lakefs_stage/lakes.parquet LIMIT 5;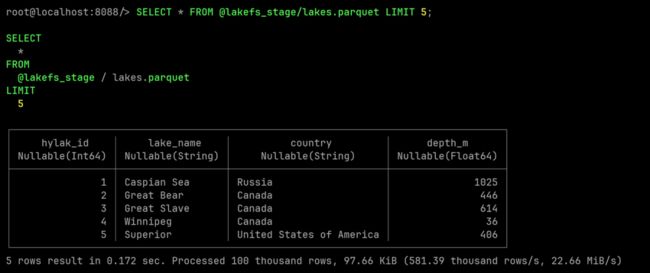
创建表,并进行一些简单的查询
在清洗数据之前,让我们先将数据导入到 Databend 中,进行一些简单的查询。
由于 Databend 内置 Infer Schema(推断数据结构)能力,可以方便地从文件创建表。
CREATE TABLE lakes AS SELECT * FROM @lakefs_stage/lakes.parquet;
接下来,让我们列出湖泊最多的 5 个国家。
SELECT country, COUNT(*)
FROM lakes
GROUP BY country
ORDER BY COUNT(*)
DESC LIMIT 5;
数据清洗
这次数据清洗的目标是构造一个小型的湖泊数据集,只保留丹麦湖泊数据。使用 DELETE FROM 语句可以轻松满足这一目标。
DELETE FROM lakes WHERE Country != 'Denmark';
接下来让我们再次查询湖泊数据,检查是否只剩下丹麦湖泊。
SELECT country, COUNT(*)
FROM lakes
GROUP BY country
ORDER BY COUNT(*)
DESC LIMIT 5;
利用 PRESIGN 将结果写回 lakeFS
在这一步中,我们需要用清洗后的结果替换 denmark-lakes 分支中的 Parquet 文件。
首先我们可以使用 COPY INTO 语法,将数据导出到内置的匿名 Stage。
COPY INTO @~ FROM lakes FILE_FORMAT = (TYPE = PARQUET);接下来,让我们列出 @~ 这个 Stage 下的结果文件。
LIST @~ PATTERN = '.*[.]parquet';
执行 PRESIGN DOWNLOAD 语句,我们可以获取用于下载结果数据文件的 URL:
PRESIGN DOWNLOAD @~/; 
打开新终端,利用 curl 命令即可完成数据文件下载。
curl -O '' 接下来,使用 PRESIGN UPLOAD 语句,我们可以获取预签名的 URL ,用于上传数据文件。这里使用 @lakefs_stage/lakes.parquet; 是希望将 lakes.parquet替换为我们清洗后的丹麦湖泊数据。
PRESIGN UPLOAD @lakefs_stage/lakes.parquet;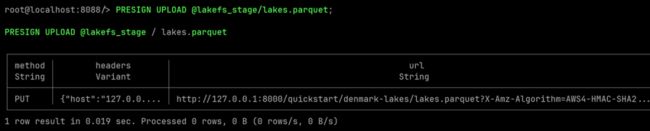
打开终端,利用 curl 命令即可完成上传。
curl -X PUT -T '' 此时文件已经被替换为清洗后的数据,再次列出 Stage 中的 Parquet 文件,可以看到文件大小和最后修改时间已经发生变化。
LIST @lakefs_stage PATTERN = '.*[.]parquet';再次查询数据文件进行验证,确认已经是清洗后的数据。
SELECT country, COUNT(*)
FROM @lakefs_stage/lakes.parquet
GROUP BY country
ORDER BY COUNT(*)
DESC LIMIT 5;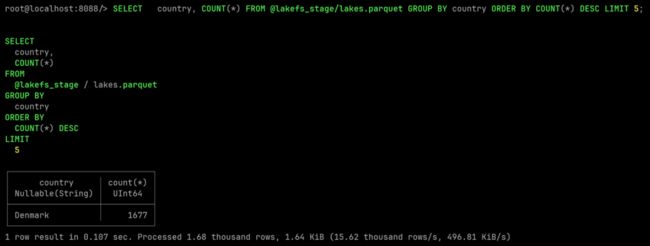
提交变更
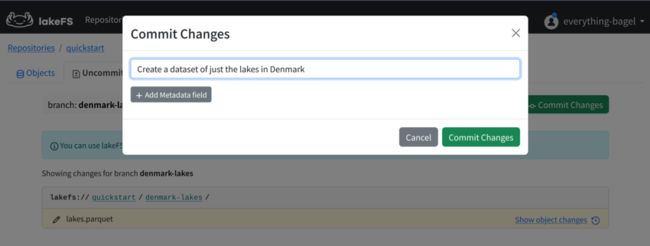
这一步我们会将变更提交至 lakeFS 进行保存。
在 lakeFS 的 Web UI 界面中,打开 Uncommitted Changes 页面,确保选中 denmark-lakes 分支。
点击右上角的 Commit Changes 按键,编写提交信息,并确认提交。
检查主分支中原始数据
denmark-lakes 中的原始数据已经被替换为清洗后的较小数据集,让我们切换回 main 分支,检查原始数据有没有收到影响。
同样地,通过创建 Stage 来挂载数据文件。
CREATE STAGE lakefs_stage_check
URL='s3://quickstart/main/'
CONNECTION = (
REGION = 'auto'
ENDPOINT_URL = 'http://127.0.0.1:8000'
ACCESS_KEY_ID = 'AKIAIOSFOLKFSSAMPLES'
SECRET_ACCESS_KEY = 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY');接着查询湖泊数据,列出湖泊数量最多的 5 个国家。
SELECT country, COUNT(*)
FROM @lakefs_stage_check/lakes.parquet
GROUP BY country
ORDER BY COUNT(*)
DESC LIMIT 5;
main 分支中的一切都保持原样,我们在保证原始数据不受干扰的情况下,得到了一份清洗好的丹麦湖泊数据集。
额外挑战
在这个 workshop 中,我们了解到如何为数据创造隔离的分支,并且在 Databend 中进行了一些简单的查询和清洗工作。
如果你还想挑战更多内容,可以参考 IakeFS 的官方教程,尝试分支合并和数据回滚能力;也可以参考 Databend 官方教程,体验在数据导入阶段进行数据清洗和 Time Travel 等能力。
我们同样欢迎将 Databend 和 IakeFS 引入生产环境,在真实的工作负载中进行验证。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
Databend Cloud:https://databend.cn
Databend 文档:Databend - The Future of Cloud Data Analytics. | Databend
Wechat:Databend
GitHub:GitHub - datafuselabs/databend: Modern alternative to Snowflake. Cost-effective and simple for massive-scale analytics. Cloud: https://databend.com