Flink 容错机制CheckPoint 与 反压机制
这里目录
-
- 1.简介
- 2、Flink 搭建
- 3、Flink 运行架构
- 4、程序与数据流(DataFlow)
- 5、Flink 流处理API
- 6、Window 窗口机制
- 7、时间语义与watermark
- 8、状态管理State
- 9、ProcessFunction API(底层API)
- 10、容错机制CheckPoint
-
- 10.1、容错机制
- 10.2、一致性检查点 checkPoint
-
- 10.2.2、Barriers(栅栏)
- 10.3、先决条件
- 10.4、checkpoint barrier 算法
- 10.5、恢复Recovery
- 10.6、启用和配置检查点
- 10.8、保存点Savepoint
- 10.9、连接器 Connector
- 10.10. 状态一致性
-
- 10.10.2 端到端 exactly-once
- 10.10.3、Flink+Kafka 端到端状态一致性的保证
- 13、Flink 反压机制
-
- 13.1、网络监控的意义
- 13.2、1.5版本之前
-
- 13.2.1. TCP流控机制
- 13.2.2.跨TaskManager反压过程
- 6.2.3. TaskManager内反压过程
- 13.2.4. Before1.5缺点
- 13.3、1.5版本以后
1.简介
- Flink 简介 + 运行架构 + 程序与 DataFlow数据流
- 链接: https://blog.csdn.net/weixin_43660536/article/details/120126980.
2、Flink 搭建
- Flink 1.9.3 搭建:
- https://blog.csdn.net/weixin_43660536/article/details/120089661..
3、Flink 运行架构
4、程序与数据流(DataFlow)
- Flink 简介 + 运行架构 + 程序与 DataFlow数据流
- 链接: https://blog.csdn.net/weixin_43660536/article/details/120126980.
5、Flink 流处理API
- Flink 流处理 API 详解
https://blog.csdn.net/weixin_43660536/article/details/120142486.
6、Window 窗口机制
7、时间语义与watermark
- Flink Windows机制 + 时间语义与水位线watermark
- https://blog.csdn.net/weixin_43660536/article/details/120142618.
8、状态管理State
9、ProcessFunction API(底层API)
- Flink state状态 与 ProcessFunction API 详解
- https://blog.csdn.net/weixin_43660536/article/details/120142911.
10、容错机制CheckPoint
10.1、容错机制
-
Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态。
-
保障即使出现故障,经过恢复,程序的状态也会回到以前的状态。
-
Flink通过定期地做checkpoint来实现容错和恢复,容错机制不断地生成数据流的快照。
-
Flink的检查点由分布快照实现,以下的“检查点”和“快照”是同意义的。
-
快照非常轻量级并且可以经常生成快照,而不会对性能产生太大的影响;
-
状态存储在一个可配置的地方(例如主节点或HDFS)。
-
如果出现程序故障(由于机器、网络或软件故障),Flink将停止分布式流数据流。然后系统重新启动 operator,并将其设置为最近一批的检查点。
-
要使得容错机制正常运行,数据流source需要能够将流倒回到指定的之前的点。flink与Kafka的connector可以利用重置kafka topic的偏移量来达到数据重 新读取的目的。
10.2、一致性检查点 checkPoint
-
Flink 故障恢复机制的核心,就是应用状态的一致性检查点
-
有状态流应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);
-
这个时间点,应该是所有任务都恰好处理完一个相同的输 入数据的时候;
-
保存算子的当前状态,当集群出现故障的时候可以进行恢复
-
默认情况下,禁用checkpoint(检查点);
-
Flink可以恢复检查点的数据,数据源也要求可以重复被消费
-
在流式计算中,算子的状态非常宝贵,因为有的状态很难进行重现
-
分布式快照:集群中的算子可以并行的去拍摄快照,不需要等待一起拍摄
10.2.2、Barriers(栅栏)
- 分布式快照的核心元素是stream barriers,轻量级的。
- 这些barriers被注入到数据流中,作为数据流的一部分和其他数据一同流动,barriers不会超过其他数据提前到达(乱序到达)。
- 每个Barrier带有一个ID,该 ID为将处于该Barrier之前的数据归入快照的检查点的ID。
- 不同的快照可以并行同时发生。
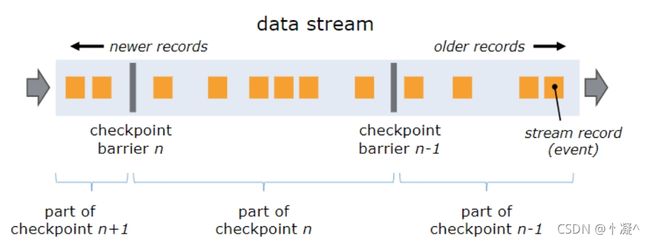
- Barrier是在
source处被插入到数据流中的。 - 快照n的barrier被插入的点(记为Sn),这个点就是在源数据流中快照n能覆盖到的数据的最近位置。
- 如在Kafaka中,这个位置就是上一个数据(record) 在分区(partition)中的偏移量(offset)。
- 这个位置Sn将会交给checkpoint 协调器(它位于Flink的 JobManager中)。
10.3、先决条件
Flink的checkpoint机制一般来说,它需要:
- 持续的数据源。比如消息队列(例如,Apache Kafka,RabbitMQ)或文件系统(例如,HDFS, S3,GFS,NFS,Ceph,…)。
- 状态存储的持久化,通常是分布式文件系统(例如,HDFS,S3,GFS,…)
10.4、checkpoint barrier 算法
- 在分布式一致性算法Chandy-Lamport的基础上实现。
- 有一种特殊的record叫checkpoint barrier(由 JM产生),它带有checkpoint ID来把流进行划分。
- 在CB前面的记录(records)会被包含到checkpoint;

- 以前快照时,数据源禁止发送数据;现在检查点会发送一个栅栏(CB),数据会在栅栏后继续被发出;
- 下游获得其中一个CB时,会暂时处理后续数据,并将这些数据存入缓冲区;完成checkpoint后才开始处理在缓冲区的数据。
- checkpoint完成后,上游会广播CB到所有下游;下游接受到所有上游的CB才会开始快照。

10.5、恢复Recovery
- 在系统失效时,Flink选择最近的已完成的检查点k,系统接下来重部 署整个数据流图,然后给每个Operator在检查点k时的相应状态。
- 数据源则被设置为从数据流的Sk位置开始读取。
- 例如,在Apache Kafka执行恢复时,系统会通知消费者从偏移Sk开始获取数据。
10.6、启用和配置检查点
- 开启checkpoint的方式:调用env.enableCheckpointing(n),其中N是以毫秒为单位的检查点间隔。
- checkpoint的相关参数
// 默认checkpoint功能是disabled的,想要使用的时候须要先启用
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为exactly-once (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间只容许进行一个检查点
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际须要恢复到指定的
Checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCl
eanup.RETAIN_ON_CANCELLATION);
// ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被
cancel后,会保留Checkpoint数据,以便根据实际须要恢复到指定的Checkpoint
// ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被
cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint
// 设置 checkpoint 保存目录
env.setStateBackend(new RocksDBStateBackend("hdfs:///checkpoints-data/");
10.8、保存点Savepoint
-
checkpoint的主要目的是在job意外失败时提供恢复机制。生命周期由Flink管理,即Flink创建,拥有和 发布Checkpoint 。
-
Savepoints由用户创建,拥有和删除。他们一般是有计划的进行手动备份和恢复。
-
例如,在 Flink版本需要更新的时候,或者更改你的流处理逻辑,更改并行性等等。
-
使用
-
保存当前流的状态到指定目录:
-
[root@node01 flink]# flink savepoint jobID target_directory
-
-
重启,恢复数据流;
10.9、连接器 Connector
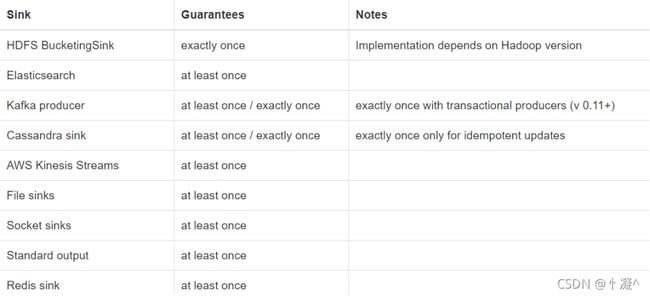
Flink 内置了一些基本数据源(source)和接收器(sink),除了这些之外,除此之外它还提供了其他的连接器 用于与各种第三方系统进行连接。目前支持如下系统的连接:
- Apache Kafka (source/sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache NiFi (source/sink)
- Apache Cassandra (sink)
- Amazon Kinesis Streams (source/sink)
- Twitter Streaming API (source)
在这些连接器中,当启动了Flink的容错机制之后,它分别能够保证不同的语义(at least once 和 exactly once)。如下图: 当连接器是source的时候:

当连接器是sink的时候:
10.10. 状态一致性
流处理器的内部状态需要保证一致性。要注意保证应用程序状态的一致性,并不是保证应用程序的输出结果的一致性。一旦输出结果被持久化,结果的准确性就很难保证了。
- AT-MOST-ONCE
- Atmost-once语义的含义是最多处理一次事件。
- AT-LEAST-ONCE
- 所有 的事件都得到了处理,而且最少处理一次事件。
- EXACTLY-ONCE
- 恰好处理一次是最严格的保证;必须有至少处理一次语义的保证才行,同时还需要数据重放机制。
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在Flink流处理器内部保证的。而 在真实世界中,流处理应用除了流处理器以外还包含了数据源(例如Kafka)和持久化系统。端到端的一致性保证意味着结果的正确性贯穿了整个流处理应用的始终。每一个组件都保证了它自己的一致性。而 整个端到端的一致性级别取决于所有组件中一致性最弱的组件。要注意的是,我们可以通过弱一致性来 实现更强的一致性语义。例如,当任务的操作具有幂等性时,比如流的最大值或者最小值的计算。在这 种场景下,我们可以通过最少处理一次这样的一致性来实现恰好处理一次这样的最高级别的一致性。
10.10.2 端到端 exactly-once
- 内部保证 —— checkpoint
- source 端 —— 可重设数据的读取位置
- sink 端 —— 从故障恢复时,数据不会重复写入外部系统
- 幂等写入
- 事务写入 --预写日志,两阶段提交
10.10.3、Flink+Kafka 端到端状态一致性的保证
-
内部 —— 利用 checkpoint 机制,把状态存盘,发生故障的时候可以恢 复,保证内部的状态一致性
-
source —— kafka consumer 作为 source,可以将偏移量保存下来,如 果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
-
sink —— kafka producer 作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
-
Exactly-once 两阶段提交
- 第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”
- jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
- sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
- sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
- 外部kafka关闭事务,提交的数据可以正常消费了。
13、Flink 反压机制
13.1、网络监控的意义
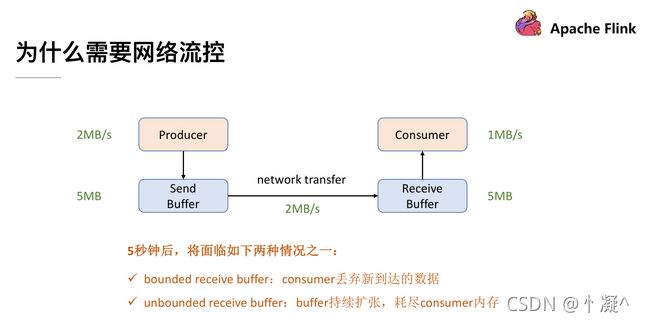
为了解决这个问题,我们就需要网络流控来解决上下游速度差的问题,传统的做法可以在Producer 端实现一个类似 Rate Limiter 这样的静态限流,Producer 的发送速率是 2MB/s,但是经过限流这一层后,往 Send Buffer 去传数据的时候就会降到 1MB/s 了,这样的话 Producer 端的发送速率跟 Consumer 端的处理速率就可以匹配起来了,就不会导致上述问题。但是这个解决方案有两点限制:
- 事先无法预估 Consumer 到底能承受多大的速率
- Consumer 的承受能力通常会动态地波动

针对静态限速的问题我们就演进到了动态反馈(自动反压)的机制,我们需要 Consumer 能够及时的给 Producer 做一个 feedback,即告知 Producer 能够承受的速率是多少。动态反馈分为两种:
- 负反馈:接受速率小于发送速率时发生,告知 Producer 降低发送速率
- 正反馈:发送速率小于接收速率时发生,告知 Producer 可以把发送速率提上来
flink的反压又分为两个阶段,一个是1.5版本之前,一个是1.5版本以后
13.2、1.5版本之前
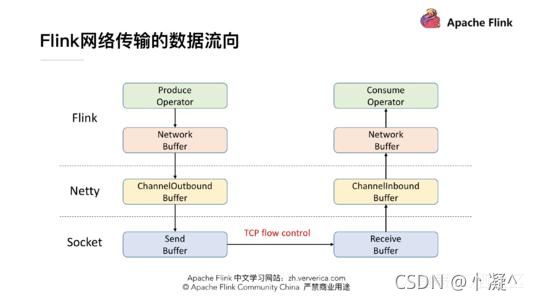
- Flink的反压是通过TCP的反压机制来控制的。
- Flink 在做网络传输的时候基本的数据的流向,发送端在发送网络数据前要经历自己内部的一个流程,会有一个自己的 Network Buffer,在底层用 Netty 去做通信,Netty 这一层又有属于自己的ChannelOutbound Buffer,因为最终是要通过 Socket 做网络请求的发送,所以在 Socket 也有自己的 Send Buffer,同样在接收端也有对应的三级 Buffer。学过计算机网络的时候我们应该了解到,TCP 是自带流量控制的。实际上 Flink (before V1.5)就是通过 TCP 的流控机制来实现feedback 的。
13.2.1. TCP流控机制
- TCP包的格式结构。首先,他有 Sequence number 这样一个机制给每个数据包做一个编号,还有ACK number 这样一个机制来确保 TCP 的数据传输是可靠的,除此之外还有一个很重要的部分就是 Window Size,接收端在回复消息的时候会通过 Window Size 告诉发送端还可以发送多少数据。
- TCP 当中有一个 ZeroWindowProbe 的机制,发送端会定期的发送 1 个字节的探测消息,这时候接收端就会把 window 的大小进行反馈。当接收端的消费恢复了之后,接收到探测消息就可以将window size 反馈给发送端端了从而恢复整个流程。TCP就是通过这样一个滑动窗口的机制实现feedback。
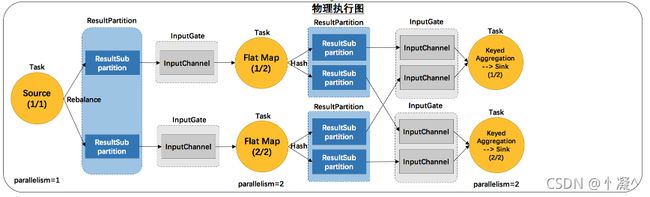
- 上游task向下游task传输数据的时候,有ResultPartition和InputGate两个组件。
- RP用来发送数据,IG用来接收数据
- 反压处理的阶段
- 跨 TaskManager ,反压如何从 InputGate 传播到 ResultPartition
- TaskManager 内,反压如何从 ResultPartition 传播到 InputGate
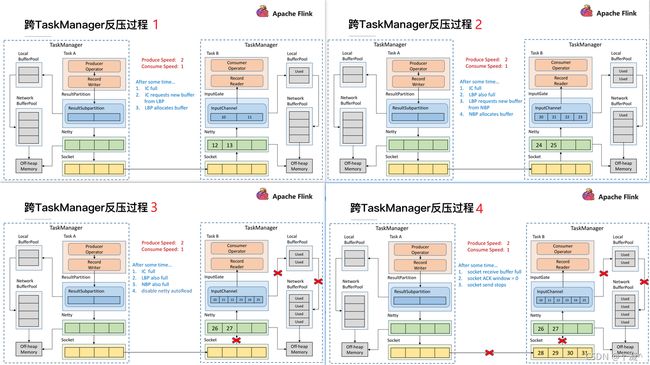
13.2.2.跨TaskManager反压过程
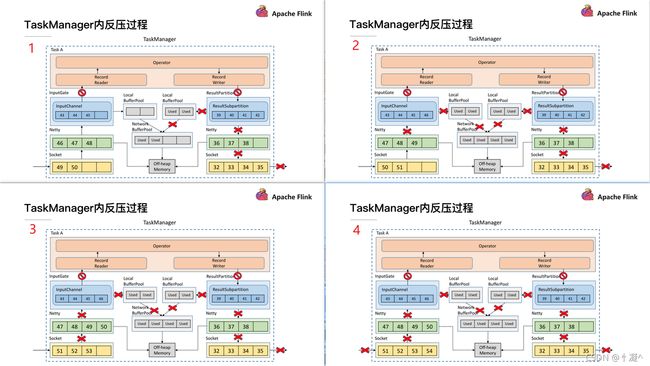
6.2.3. TaskManager内反压过程
13.2.4. Before1.5缺点
- 在一个 TaskManager 中可能要执行多个 Task,如果多个 Task 的数据最终都要传输到下游的同一个 TaskManager 就会复用同一个 Socket 进行传输,这个时候如果单个 Task 产生反压,就会导致复用的 Socket 阻塞,其余的 Task 也无法使用传输,checkpoint barrier 也无法发出导致下游执行checkpoint 的延迟增大。
- 依赖最底层的 TCP 去做流控,会导致反压传播路径太长,导致生效的延迟比较大。
13.3、1.5版本以后
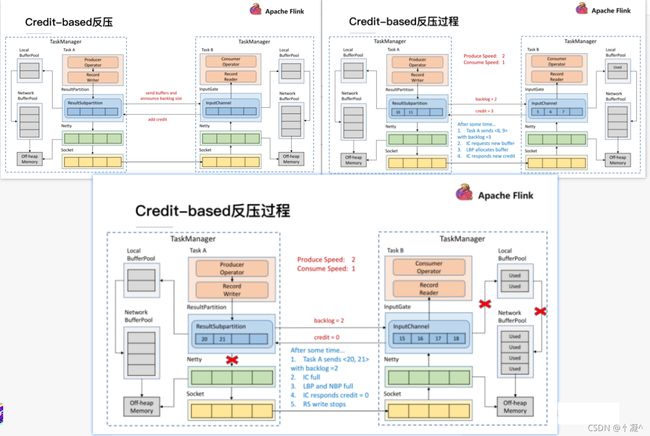
-
ResultSubPartition 直接与Inputchannel 建立联系,询问是否能接受多少数据。
-
在 Flink 层面实现反压机制,就是每一次 ResultSubPartition 向 InputChannel 发送消息的时候都会发送一个 backlog size 告诉下游准备发送多少消息,下游就会去计算有多少的 Buffer 去接收消息,算完之后如果有充足的 Buffer 就会返还给上游一个 Credit 告知他可以发送消息
-
假设我们上下游的速度不匹配,上游发送速率为 2,下游接收速率为 1,可以看到图上在ResultSubPartition 中累积了两条消息,10 和 11, backlog 就为 2,这时就会将发送的数据<8,9> 和 backlog = 2 一同发送给下游。下游收到了之后就会去计算是否有 2 个 Buffer 去接收,可以看到 InputChannel 中已经不足了这时就会从 Local BufferPool 和 Network BufferPool 申请,好在这个时候 Buffer 还是可以申请到的。
-
过了一段时间后由于上游的发送速率要大于下游的接受速率,下游的 TaskManager 的 Buffer 已经到达了申请上限,这时候下游就会向上游返回 Credit = 0,ResultSubPartition 接收到之后就不会向 Netty 去传输数据,上游 TaskManager 的 Buffer 也很快耗尽,达到反压的效果,这样在ResultSubPartition 层就能感知到反压,不用通过 Socket 和 Netty 一层层地向上反馈,降低了反压生效的延迟。同时也不会将 Socket 去阻塞,解决了由于一个 Task 反压导致 TaskManager 和TaskManager 之间的 Socket 阻塞的问题。