pandas + sqlalchemy mysql
Quick Tip: SQLAlchemy for MySQL and Pandas
Before we get into the SQLAlchemy aspects, let’s take a second to look at how to connect to a SQL database with the mysql-python connector (or at least take a look at how I do it).
First, let’s setup our import statements. For this, we will import MySQLdb, pandas and pandas.io.sql in order to read SQL data directly into a pandas dataframe.
| 1 2 3 |
import pandas as pd import MySQLdb import pandas.io.sql as psql |
Next, let’s create a database connection, create a query, execute that query and close that database.
| 1 2 3 4 5 6 7 8 9 10 |
# setup the database connection. There's no need to setup cursors with pandas psql. db=MySQLdb.connect(host=HOST, user=USER, passwd=PW, db=DBNAME)
# create the query query = "select * from TABLENAME"
# execute the query and assign it to a pandas dataframe df = psql.read_sql(query, con=db) # close the database connection db.close() |
This is a fairly standard approach to reading data into a pandas dataframe from mysql using mysql-python. This approach is what I had been using before when I was getting 4.5+ seconds as discussed above. Note – there were multiple database calls and some analysis included in that 4.5+ seconds. A basic database call like the above ran in approximately 0.45 seconds in my code that I was trying to improve performance on and establishing the database connection was the majority of that time.
To improve performance – especially if you will have multiple calls to multiple tables, you can use SQLAlchemy with pandas. You’ll need to pip install sqlalchemy if you don’t have it installed already. Now, let’s setup our imports:
| 1 2 |
import pandas as pd import sqlalchemy as sql |
Now you can setup your connection string to your database for SQLAlchemy, you’d put everything together like the following:
| 1 |
connect_string = 'mysql://USER:PW@DBHOST/DB' |
where USER is your username, PW is your password, DBHOST is the database host and DB is the database you want to connect to.
To setup the persistent connection, you do the following:
| 1 |
sql_engine = sql.create_engine(connect_string) |
Now, you have a connection to your database and you’re ready to go. No need to worry about cursors or opening/closing database connections. SQLAlchemy keeps the connection management aspects in for you.
Now all you need to do is focus on your SQL queries and loading the results into a pandas dataframe.
| 1 2 |
query =query = "select * from TABLENAME" df = pd.read_sql_query(query, sql_engine) |
That’s all it takes. AND…it’s faster. In the example above, my database setup / connection / query / closing times dropped from 0.45 seconds to 0.15 seconds. Times will vary based on what data you are querying and where the database is of course but in this case, all things were the same except for mysql-python being replaced with SQLAlchemy and using the new(ish) read_sql_query function in pandas.
Using this approach, the 4.5+ seconds it took to grab data, analyze the data and return the data was reduced to about 1.5 seconds. Impressive gains for just switching out the connection/management method.
Python之使用Pandas库实现MySQL数据库的读写
ORM技术
对象关系映射技术,即ORM(Object-Relational Mapping)技术,指的是把关系数据库的表结构映射到对象上,通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。
在Python中,最有名的ORM框架是SQLAlchemy。Java中典型的ORM中间件有:Hibernate,ibatis,speedframework。
SQLAlchemy
SQLAlchemy是Python编程语言下的一款开源软件。提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行。
可以使用pip命令安装SQLAlchemy模块:
pip install sqlalchemySQLAlchemy模块提供了create_engine()函数用来初始化数据库连接,SQLAlchemy用一个字符串表示连接信息:
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'
Pandas读写MySQL数据库
我们需要以下三个库来实现Pandas读写MySQL数据库:
- pandas
- sqlalchemy
- pymysql
其中,pandas模块提供了read_sql_query()函数实现了对数据库的查询,to_sql()函数实现了对数据库的写入,并不需要实现新建MySQL数据表。sqlalchemy模块实现了与不同数据库的连接,而pymysql模块则使得Python能够操作MySQL数据库。
我们将使用MySQL数据库中的mydb数据库以及employee表,内容如下:
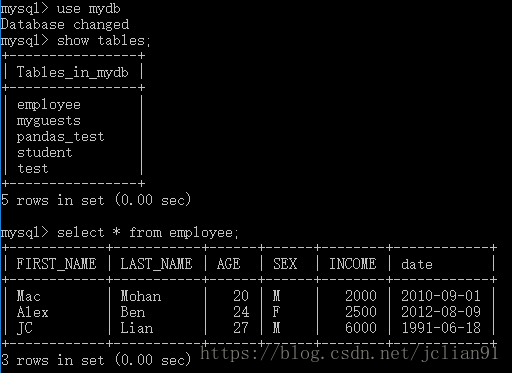
下面将介绍一个简单的例子来展示如何在pandas中实现对MySQL数据库的读写:
# -*- coding: utf-8 -*-
# 导入必要模块
import pandas as pd
from sqlalchemy import create_engine
# 初始化数据库连接,使用pymysql模块
# MySQL的用户:root, 密码:147369, 端口:3306,数据库:mydb
engine = create_engine('mysql+pymysql://root:147369@localhost:3306/mydb')
# 查询语句,选出employee表中的所有数据
sql = '''
select * from employee;
'''
# read_sql_query的两个参数: sql语句, 数据库连接
df = pd.read_sql_query(sql, engine)
# 输出employee表的查询结果
print(df)
# 新建pandas中的DataFrame, 只有id,num两列
df = pd.DataFrame({'id':[1,2,3,4],'num':[12,34,56,89]})
# 将新建的DataFrame储存为MySQL中的数据表,不储存index列
df.to_sql('mydf', engine, index= False)
print('Read from and write to Mysql table successfully!')程序的运行结果如下:

在MySQL中查看mydf表格:
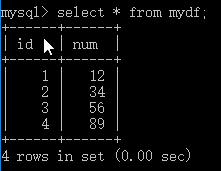
这说明我们确实将pandas中新建的DataFrame写入到了MySQL中!
将CSV文件写入到MySQL中
以上的例子实现了使用Pandas库实现MySQL数据库的读写,我们将再介绍一个实例:将CSV文件写入到MySQL中,示例的mpg.CSV文件前10行如下:
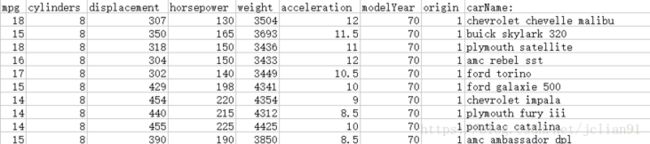
示例的Python代码如下:
# -*- coding: utf-8 -*-
# 导入必要模块
import pandas as pd
from sqlalchemy import create_engine
# 初始化数据库连接,使用pymysql模块
engine = create_engine('mysql+pymysql://root:147369@localhost:3306/mydb')
# 读取本地CSV文件
df = pd.read_csv("E://mpg.csv", sep=',')
# 将新建的DataFrame储存为MySQL中的数据表,不储存index列
df.to_sql('mpg', engine, index= False)
print("Write to MySQL successfully!")在MySQL中查看mpg表格:

仅仅5句Python代码就实现了将CSV文件写入到MySQL中,这无疑是简单、方便、迅速、高效的!
Python中从SQL型数据库读写dataframe型数据
Python的pandas包对表格化的数据处理能力很强,而SQL数据库的数据就是以表格的形式储存,因此经常将sql数据库里的数据直接读取为dataframe,分析操作以后再将dataframe存到sql数据库中。而pandas中的read_sql和to_sql函数就可以很方便得从sql数据库中读写数据。
read_sql
参见pandas.read_sql的文档,read_sql主要有如下几个参数:
- sql:SQL命令字符串
- con:连接sql数据库的engine,一般可以用SQLalchemy或者pymysql之类的包建立
- index_col: 选择某一列作为index
- coerce_float:非常有用,将数字形式的字符串直接以float型读入
- parse_dates:将某一列日期型字符串转换为datetime型数据,与pd.to_datetime函数功能类似。可以直接提供需要转换的列名以默认的日期形式转换,也可以用字典的格式提供列名和转换的日期格式,比如{column_name: format string}(format string:"%Y:%m:%H:%M:%S")。
- columns:要选取的列。一般没啥用,因为在sql命令里面一般就指定要选择的列了
- chunksize:如果提供了一个整数值,那么就会返回一个generator,每次输出的行数就是提供的值的大小。
- params:其他的一些执行参数,没用过不太清楚。。。
以链接常见的mysql数据库为例:
import pandas as pd
import pymysql
import sqlalchemy
from sqlalchemy import create_engine
# 1. 用sqlalchemy构建数据库链接engine
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(DB_USER, DB_PASS, DB_HOST, DB_PORT, DATABASE) #1
engine = create_engine(connect_info)
# sql 命令
sql_cmd = "SELECT * FROM table"
df = pd.read_sql(sql=sql_cmd, con=engine)
# 2. 用DBAPI构建数据库链接engine
con = pymysql.connect(host=localhost, user=username, password=password, database=dbname, charset='utf8', use_unicode=True)
df = pd.read_sql(sql_cmd, con)解释一下 #1: 这个是sqlalchemy中链接数据库的URL格式:dialect[+driver]://user:password@host/dbname[?key=value..]。dialect代表书库局类型,比如mysql, oracle, postgresql。driver代表DBAPI的名字,比如psycopg2,pymysql等。具体说明可以参考这里。此外由于数据里面有中文的时候就需要将charset设为utf8。
to_sql
参见pandas.to_sql函数,主要有以下几个参数:
- name: 输出的表名
- con: 与read_sql中相同
- if_exits: 三个模式:fail,若表存在,则不输出;replace:若表存在,覆盖原来表里的数据;append:若表存在,将数据写到原表的后面。默认为fail
- index:是否将df的index单独写到一列中
- index_label:指定列作为df的index输出,此时index为True
- chunksize: 同read_sql
- dtype: 指定列的输出到数据库中的数据类型。字典形式储存:{column_name: sql_dtype}。常见的数据类型有sqlalchemy.types.INTEGER(), sqlalchemy.types.NVARCHAR(),sqlalchemy.Datetime()等,具体数据类型可以参考这里
还是以写到mysql数据库为例:
df.to_sql(name='table',
con=con,
if_exists='append',
index=False,
dtype={'col1':sqlalchemy.types.INTEGER(),
'col2':sqlalchemy.types.NVARCHAR(length=255),
'col_time':sqlalchemy.DateTime(),
'col_bool':sqlalchemy.types.Boolean
})注:如果不提供dtype,to_sql会自动根据df列的dtype选择默认的数据类型输出,比如字符型会以sqlalchemy.types.TEXT类型输出,相比NVARCHAR,TEXT类型的数据所占的空间更大,所以一般会指定输出为NVARCHAR;而如果df的列的类型为np.int64时,将会导致无法识别并转换成INTEGER型,需要事先转换成int类型(用map,apply函数可以方便的转换)。
参考:
https://pythondata.com/quick-tip-sqlalchemy-for-mysql-and-pandas/
https://segmentfault.com/a/1190000014210743
http://docs.sqlalchemy.org/en/latest/core/type_basics.html#sql-standard-and-multiple-vendor-types
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_sql.html
http://docs.sqlalchemy.org/en/latest/core/engines.html
http://docs.sqlalchemy.org/en/latest/core/type_basics.html#sql-standard-and-multiple-vendor-types
http://stackoverflow.com/questions/30631325/writing-to-mysql-database-with-pandas-using-sqlalchemy-to-sql
http://stackoverflow.com/questions/5687718/how-can-i-insert-data-into-a-mysql-database
http://stackoverflow.com/questions/32235696/pandas-to-sql-gives-unicode-decode-error
http://stackoverflow.com/questions/34383000/pandas-to-sql-all-columns-as-nvarchar