SQL——高阶语句3
这里写目录标题
- 一、数据库函数
-
-
-
- 1.数学函数
-
-
- 二.聚合函数
- 三.字符串函数
- 四 日期时间函数
-
-
-
- 4.1 返回时间
- 4.2 查看时间
-
-
- 四.总结
- 五.存储过程概述
-
-
-
- 5.1 MySQL 5.0 版本开始支持存储过程。
- 5.2 为什么要使用存储过程
- 5.3 简介
- 5.4存储的优缺点
-
-
- 存储过程优点:
-
- 5.5存储过程的缺点
- 5.6 格式
-
-
- 六.实验
-
-
-
- 6.1 创建存储过程
- 6.2 查看存储过程
- 6.3修改存储过程
- 6.4删除存储过程
-
-
- 七 总结
-
-
-
- 7.1优点:
- 7.2 存储过程:
- 7.3 操作存储过程时应注意
- 7.4 存储过程的特点
-
-
一、数据库函数
Mysql数据库函数提供了能够实现各种功能的办法 ,使我们在查询记录时能够更高效的输出
mysql是内建了很多函数,常用的包括数学函数、聚合函数、字符串函数和日期时间函数
1.数学函数
数据库内存储的记录,
经常要进行一系列的算术操作,mysql支持很多数学函数
| 数学函数 | 描述 |
|---|---|
| abs(×) | 输出×的绝对值 |
| rand() | 输出o到1的随机数 |
| mod(x,y) | 输出x除以y以后的余数 |
| power(x,y) | 输出x的y次方 |
| round(×) | 输出离x最近的整数 |
| round(x,y) | 保留x的y位小数四舍五入后的值 |
| sqrt(x) | 输出x的平方根 |
| truncate(x,y) | 输出数字x截断为y位小数的值 |
| ceil(×) | 输出大于或等于x的最小整数 |
| floor(x) | 输出小于或等于x的最大整数 |
| greatest(x1,x2…) | 输出集合中最大的值 |
| least(x1,x2…) | 输出集合中最小的值 |
- 返回x的绝对值
abs(x)
select abs(-3);

- ** 返回 0到1的随机数**
rand()
select rand()
- 可搭配运算符
select rand()*100;
select rand()*20;

- 返回x的y次方
power (x,y)
select power(3,3);

- 返回离x最近的整数(四舍五入)
round (x)
select round(1.55);

- 保留x的y位小数位(四舍五入)
round(x,y)
select round(1.8999,2);
- 返回x的平方根
sqrt(x)
select sqrt(4);

- 返回数字x 截断为y位小数的值(保留小数后两位,truncate不会四舍五入)
truncate(x,y)
select truncate(1.896,2);

- 返回大于或等于x的最小整数
ceil(x)
select ceil(5.2);

- 返回小于或等于x的最大整数
floor(x)
select floor(5.2);

- 返回集合中最大的值
greatest(1…2…)
select greatest(1,2,3);

- 返回集合中最小的值
least(1..2..)
select least(1,2,3);

二.聚合函数
特意位库内记录求和或者对表中的数据进行集中概括而设计的即:
库内记录对表中数据进行集中概括而设计的
聚合函数:
| avg | 返回指定的平均值 |
|---|---|
| count() | 返回指定列中非null值的个数 |
| min | 返回指定列的最小值 |
| max | 返回指定列的最大值 |
| sum(x) | 返回指定列的所有值之和 |
- 返回字段的总和
sum()
select sum(score) from info;

- 返回字段的个数
count()
select count(score) from info;

- 返回字段最小值
min()
select min(score) from info;

- 返回字段的最大值
max()
select max(score) from info;

- 返回字段的平均值
avg()
select avg(hobbid) from info;

三.字符串函数
| 字符串函数 | 描述 |
|---|---|
| length(x) | 返回字符串x的长度 |
| trim() | 返回去除指定格式的值 |
| concat(x,y) | 将提供的参数x和y拼接成一个字符串 |
| upper(x) | 将字符串x的所有字符变成大写字母 |
| left(x,y) | 返回字符串x的前y个字符 |
| right(x,y) | 返回字符串x的后y个字符 |
| repeat(x,y) | 将字符串x重复y次 |
| space(x) | 返回x个空格 |
| replace(x,y,z) | 将字符串z替代字符串x中的字符串y |
| strcmp(x,y) | 比较x和y,返回的值可以位-1,0,1 |
| substring(x,y,z) | 获取从字符串x中的第y个位置开始长度为z的字符串 |
- 返回字符串长度,空格也算一个字符
length(…)
select length('abcd');
select length('ab cd');
select length('李四');

- 去掉格式只输出字符串
trim(…)
select trim(' abc');

- 两个字段进行拼接
concat(…)
select concat('abc','def');

- 拼接结合去掉格式
concat(…,trim(…))
select concat('abc',trim(' def'));

- 把字段转换为大写
upper(…)
select upper('abc');

- 把字段转换为小写
lower(…)
select lower('ABC');

- 返回字符串的前n个字母
left(…,n)
select left('abcdefg',3);

- 返回字符串的最后n个字母
right(…,n)
select right('abcdefg',3);
- 把字符串前3个字母和后3个字母拼接起来
concat(left(…,n),right(…,n));
select concat(left('abcdefg',3),right('abcdefg',3));

- 重复字符串n次
repeat(…,n);
select repeat('abc',2);
select repeat('abc',3);

- 返回3个空格,显示无法看出几个空格,这里用length函数显示长度
length(space(3));
select length(space(3));

- 用aa替换hello中的ll
replace(‘hello’,‘ll’,‘aa’)
select replace('hello','ll','aa');
- 比较17和18,小于返回-1,等于返回0,大于返回1只会返回这3个值,比较的第一位数字
strcmp(17,18);
select strcmp(17,18);
select strcmp(17,17);
select strcmp(17,16);

- 返回从字符串中第三个字符开始的4个字符
substring(…,3,4);
select substring('abcdefg',3,4);

四 日期时间函数
| 字符串函数 | 描述 |
|---|---|
| curdate() | 返回当前时间的年月日 |
| curtime() | 返回当前时间的时分秒 |
| now() | 返回当前时间的日期和时间 |
| month(x) | 返回日期x中的月份值 |
| :week(x) | 返回日期x是年度第几个星期 |
| hour(x) | 返回x中的小时值 |
| minute(x) | 返回x中的分钟值 |
| second(x) | 返回x中的秒种值 |
| dayofweek(x) | 返回x是星期几 |
| dayofmonth(x) | 计算日期x是本月的第几天 |
| dayofyear(x) | 计算日期x是本年的第几天 |
| replace(x,y,z) | 将字符串z替代字符串x中的字符串y |
4.1 返回时间
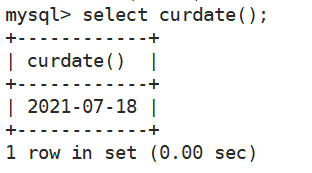
- 返回年月日
select curdate();
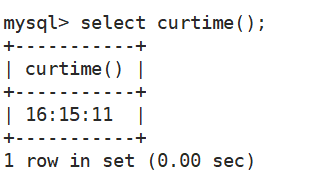
- 返回当前时间(
时分秒)
select curtime();
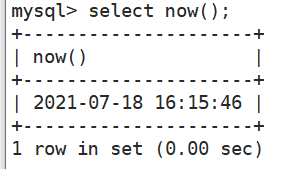
- 返回当前完整时间
select now();
4.2 查看时间
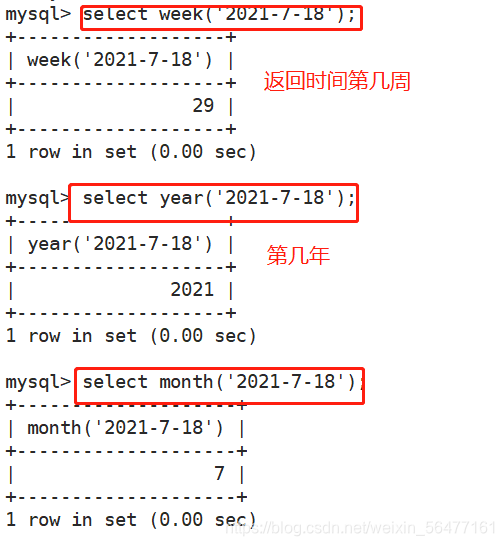
- 查看时间周、年、月
select week('2021-7-18');
select year('2021-7-18');
select month('2021-7-18');
- 查看当前时间的小时
select hour(curtime());
- 查看当前时间分钟
select minute(curtime());
- 查看当前时间的秒
select second(curtime());

- 查看当前是星期几
select dayofweek(curtime());
- 查看当前日期是本年的第几天
select dayofyear(curtime());
四.总结
1.嵌套子查询
子查询使用灵活,可以作为查询条件使用,作为临时表使用,作为列使用。
优点:降低了SQL语句的复杂度,提高了SQL语句的可读性。
2.IN和NOT IN
IN和NOT IN通常在WHERE子句中使用,在IN和NOT IN后接的子句查询中,可以有多个值出现,但必须只能有一列。
3.EXISTS和NOT EXISTS
EXISTS和NOT EXISTS表示存在和不存在的意思。
在语句中会判断EXISTS和NOT EXISTS后接的子句是否存在和是否不存在。
EXISTS和NOT EXISTS的用法一样,唯一区别是意思相反。
4.SOME、ANY、ALL
在SQL查询中SOME、ANY、ALL后必须跟子查询。
在SQL查询中SOME和ANY的作用一样,表示其中任何一项,ALL表示其中所有的项。
5.COMPUTE和COMPUTE BY
使用了COMPUTE进行汇总计算后的查询得到了两个结果集,第一个结果及返回查询语句前面的查询明细,后一个结果集返回汇总的结果,我们也可以在COMPUTE子句中添加多个汇总计算表达式。
COMPUTE子句需要下列信息:
可选BY关键字,它基于每一列计算指定的行聚合。
行聚合函数名称,它包括SUM、AVG、MIN、MAX或COUNT。
要对其执行行聚合函数的列。
在有些场景中我们需要对结果先进行分组,然后进行汇总计算。这种情况下我们可以使用COMPUTE BY进行分组汇总查询。
6.排序函数
语法:排序函数OVER([分组子句]排序子句[DESC/ASC])
①ROW_NUMBER函数不并列不跳空。
②RANK函数存在并列且跳空。
③DENSE_RANK函数存在并列但不跳空。
分组子句:PARTITION BY
排序子句:ORDER BY
五.存储过程概述
有些数据库操作可能会非常复杂,
可能会需要多条sql语句一起去处理完成,
可以使用存储过程
5.1 MySQL 5.0 版本开始支持存储过程。
- 存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
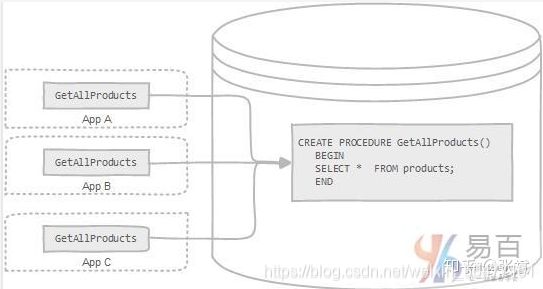
存储过程Procedure是一组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称
并给出参数来执行。
存储过程中可以包含逻辑控制语句和数据操纵语句,它可以接受参数、输出参数、返回单个或多个结果集以及返回值。
由于存储过程在创建时即在数据库服务器上进行了编译并存储在数据库中,所以存储过程运行要比单个的SQL语句
块要快。同时由于在调用时只需用提供存储过程名和必要的参数信息,所以在一定程度上也可以减少网络流量、
简单网络负担。
5.2 为什么要使用存储过程
1、通过把处理封装在容易使用的单元中,简化复杂的操作。
2、 由于不要求反复建立一系列处理步骤,这保证了数据的完整性。如果所有开发人员和应用程序都使用同一存储过程,则所使用的代码都是相同的。这一点的延伸就是防止错误。需要执行的步骤越多,出错的可能性就越大。防止错误保证了数据的一致性。
3、简化对变动的管理。如果表名、列名或业务逻辑有变化,只需要更改存储过程的代码。使用它的人员甚至不需要知道这些变化。这一点的延伸就是安全性。通过存储过程限制对基础数据的访问减少了数据讹误(无意识的或别的原因所导致的数据讹误)的机会。
4、提高性能。因为使用存储过程比使用单独的 SQL语句要快。
5、存在一些只能用在单个请求中的 MySQL元素和特性,存储过程可以使用它们来编写功能更强更灵活的代码(在下一章的例子中可以看到。)
换句话说,使用存储过程有 3个主要的好处,即简单、安全、高性能。显然,它们都很重要。不过,在将 SQL代码转换为存储过程前,也必须知道它的一些缺陷。
1、一般来说,存储过程的编写比基本 SQL语句复杂,编写存储过程需要更高的技能,更丰富的经验。
2、你可能没有创建存储过程的安全访问权限。许多数据库管理员限制存储过程的创建权限,允许用户使用存储过程,但不允许他们创建存储过程。
尽管有这些缺陷,存储过程还是非常有用的,并且应该尽可能地使用。
5.3 简介
是一组为了完成特定功能的sql语句的集合
从5.0版本才开始支持
它可以加快数据库的处理速度,
增强数据库在应用 中的灵活性
- 存储过程是为了完成特定功能的sql集合
- 在使用过程中,是将常用或者复杂的工作预先使用sql语句写好,并用一个指定的名称存储起来。
- 这个过程经编译和优化后存储在数据库服务器中,当需要使用该存储过程时,调用即可
- 在执行时,需要先编译再执行
5.4存储的优缺点
存储过程优点:
- 提高执行效率,执行一次后,会将生成的二进制码驻留缓冲区
- 灵活性高,sql语句加上控制语句的集合
- 在服务器段存储,客户端调用时,降低网络负载
- 可多次重复被调用,可随时更改,不影响客户端调用
- 完成所有库操作,可控制数据库的信息访问权限
5.5存储过程的缺点
- 如果使用大量存储过程,那么使用这些存储过程的每个连接的内存使用量将会大大增加。此外,如果您在存储过程中过度使用大量逻辑操作,则CPU使用率也会增加,因为数据库服务器的设计不当于逻辑运算。
- 存储过程的构造使得开发具有复杂业务逻辑的存储过程变得更加困难。很难调试存储过程。只有少数数据库管理系统允许您调试存储过程。不幸的是,MySQL不提供调试存储过程的功能。
- 开发和维护存储过程并不容易。 开发和维护存储过程通常需要一个不是所有应用程序开发人员拥有的专业技能。这可能会导致应用程序开发和维护阶段的问题。
5.6 格式
格式:
DELIMITER $$
CREATE PROCEDURE xxx()
BEGIN
sql语句;
END $$
DELIMITER
DELIMITER $$ #将语句的结束符号从分号;临时改为两个$$(可以是自定义)
CREATE PROCEDURE xxx() #创建存储过程,过程名为xxx,不带参数
BEGIN #过程体以关键字 BEGIN 开始
sql语句; #过程体语句
END $$ #过程体以关键字 END 结束
DELIMITER ; #将语句的结束符号恢复为分号
六.实验
6.1 创建存储过程
mysql> create database cc;
Query OK, 1 row affected (0.01 sec)
mysql> use cc;
Database changed
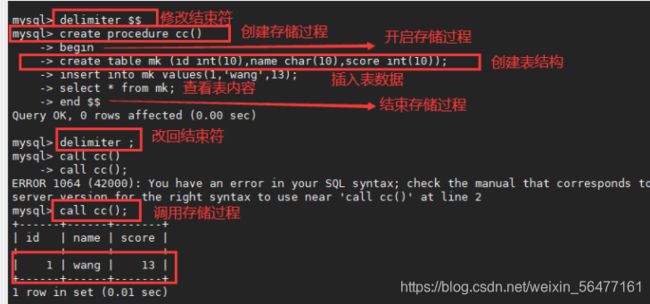
delimiter $$
create procedure cc()
begin
create table mk (id int(10),name char(10),score int(10));
insert into mk values(1,'wang',13);
select * from mk;
end $$
6.2 查看存储过程
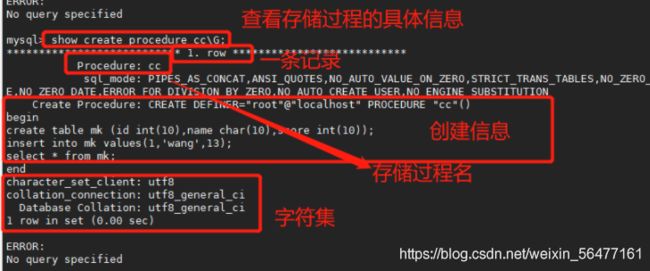
SHOW CREATE PROCEDURE [数据库.]存储过程名; #查看某个存储过程的具体信息
show create procedure cc\G;
6.3修改存储过程
alter procedure <过程名><特征>
show create procedure getrole\G;
alter procedure getrole modifies sql data sql security invoker;
show create procedure getrole\G;

6.4删除存储过程
drop procedure if exists getrole;

七 总结
存储过程:数据库操作复杂,可使用多条sql语句一起完成
为了完成特定功能的sql集合
就是将复杂的工作预先写好,指定存储起来
执行时进行调用
7.1优点:
① 执行效率高
② 灵活
③ 可重复调用
④ 完成所有库操作,可控制数据库信息访问
7.2 存储过程:
输入参数,IN:调用者向过程传入
输出参数:OUT,过程向调用者传出值
7.3 操作存储过程时应注意
-
删除存储过程时只需要指定存储过程名即可,不带括号;
-
创建存储过程时,不管该存储过程有无参数,都需要带括号;
-
在使用SET定义变量时应遵循SET的语法规则
SET @变量名=初始值; -
在定义存储过程参数列表时,应注意参数名与数据库中字段名区别开来,否则将出现无法预期的结果
DECLARE语句被用来把不同项目局域到一个子程序:局部变量DECLARE仅被用在BEGIN … END复合语句里,并且必须在复合语句的开头,在任何其它语句之前。
- 显示数据库中所有存储的存储过程基本信息,包括所属数据库,存储过程名称,创建时间等
show procedure status
- 显示某一个存储过程的详细信息
show create procedure sp_name
7.4 存储过程的特点
1、能完成较复杂的判断和运算
2、可编程行强,灵活
3、SQL编程的代码可重复使用
4、执行的速度相对快一些
5、减少网络之间的数据传输,节省开销