华为云contos7系统部署ES集群--3个主节点
目录
前言:
Elasticsearch
Logstash
Kibana
Beats
一、集群部署
1.ES集群的基本核心概念
二、搭建步骤
1、基础环境配置
2、修改ES配置文件elasticsearch.yml
3. 其它配置文件
4.启动es
5.验证ES集群:
三、安装Kibana
1.获取到安装包
2.配置yum源:
3.修改配置文件kibana.yml:
4.开启端口5601:
5.启动kibana:
四、华为云使用问题总结:
1.怎样登录服务器Linux控制台
2.怎样上传文件:
五、参考文章:
前言:
首先要有一个全面的认识,什么是ELK?
Elastic Stack也就是ELK,ELK是三款软件的集合,分别是Elasticsearch,logstas,Kibana,在发展过程中,有了新的成员Beats加入,所以就形成了Elastic Starck.也是就是说ELK是旧的称呼,Elastic Stack是新的名字。
先通过Beats采集一切的数据如日志文件,网络流量,Win事件日志,服务指标,健康检查等,然后把数据发送给elasticsearch保存起来,也可以发送给logstas处理然后再发送给elasticsearch,最后通过kibana的组件将数据可视化的展示出来。
Elasticsearch
Elasticsearch基于java,是个开源分布式手术引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash
也是基于java,是一个开源的用于收集,分析和存储日志的工具。
Kibana
Kibana基于nodejs,也是开源和免费的工具,Kibana开源为logsash和Elasticsearch提供日志分析友好的web界面,可以汇总,分析和搜索重要的数据日志。
Beats
Bests是elastic公司开源的一款采集系统监控数据的代理agent,是在被监控服务器上以客户端形式运行的数据收集器的统称,可以直接把数据发送给Elasticsearch或者通过Logstash发送给Elasticsearch,然后进行后续的数据分析活动
ELK官网:
直接从官网下载ELK的所有安装包
Free and Open Search: The Creators of Elasticsearch, ELK & Kibana | Elastic
Note: 怎样部署ELK?
ELK需要使用单独的机器部署,为什么? 因为ELK不涉及业务,而且日志量大 会占用业务的资源,所以需要单独部署。
一、集群部署
1.ES集群的基本核心概念
Cluster集群
一个ElasticSearch集群由一个或多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识。
Node节点
一个ElasticSearch实例即一个Node,一台机器可以有多个实例,正常使用下每个实例应该会部署在不同机器上。ElasticSearch的配置文件中可以通过node.master、node.data来设置节点类型。
node.master参数:表示节点是否具有成为主节点的资格
- true代表的是有资格竞选主节点
- false代表的是没有资格竞选主节点
node.data参数:表示节点是否存储数据
二、搭建步骤
本文所用ES版本,elasticsearch-7.8.1-linux-x86_64.tar
1、基础环境配置
添加用户
出于安全的考虑,elasticsearch不允许使用root用户来启动,所以需要创建一个新的用户,并为这个账户赋予相应的权限来启动elasticsearch集群(赋予权限的操作在后面启动ES的环节)。
#useradd es
修改服务打开文件数
(1).vim /etc/security/limits.conf
root soft nofile 65535 (这个不需要修改成262144,无需改动)
root hard nofile 65535 (这个不需要修改成262144,无需改动)
* soft nofile 262144
* hard nofile 262144#下面两句没加,但是看很多文章里加了
* soft memlock unlimited
* hard memlock unlimited
防止进程虚拟内存不足:
(2).vim /etc/sysctl.conf
#文件尾部设置
vm.max_map_count=262144
使上面的设置生效:
sysctl -p
2、修改ES配置文件elasticsearch.yml
集群配置中最重要的两项是node.name与network.host,每个节点都必须不同。其中node.name是节点名称主要是在Elasticsearch自己的日志加以区分每一个节点信息。
#集群名称,三台集群,要配置相同的集群名称!!!
cluster.name: wit
#节点名称
node.name: node-1 #每个节点的名称不能相同
node.master: true
#是否存储数据
node.data: true
network.host: 0.0.0.0
#端⼝
http.port: 9200
#内部节点之间沟通端⼝
transport.tcp.port: 9300
#写⼊候选主节点的设备地址,在开启服务后可以被选为主节点#因为要配置三个主节点,所以这里写了三个,如果只需要一个主节点,则这里只写一个
#这里不要写端口,只写IP,写端口的话,集群搭建不成功。
discovery.seed_hosts: ["es1 IP","es2 IP","es3 IP"]
#初始化⼀个新的集群时需要此配置来选举master,就是说可以被选为主节点的节点列表#这里填写的是节点的名字,不是节点的IP地址
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#数据和存储路径
path.data: /data/esdata (可以自己创建,可以设置在ES解压目录中)
path.logs: /data/eslogs (可以自己创建,可以设置在ES解压目录中)#下面的几个配置还没使用,看情况吧
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
问题:
1. 每个节点都要按照上面的配置?还是说只有主节点这么配置?
都配置的一样 3个节点都作为master,不然master挂了。。集群就没了
后期加机器也只要加slave就行了,节点名称需要不一样
3. 其它配置文件
关于ES与jdk版本关系,请参考文章:支持矩阵 | Elastic
(1).ES自带java,所以不需要在系统中安装java,但是如果系统中已经有了java,那么ES会用哪一个?
在ES解压目录中,/bin/elasticsearch-env文件中,有如下内容:
意思是如果系统中安装了java,那么优先使用系统中安装的java,如果系统中没有安装java,那么使用ES自带的java。
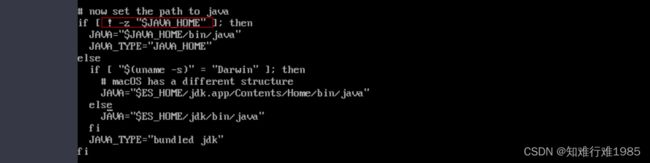
(2).由于Elasticsearch是Java开发的,所以可以通过../elasticsearch/config/jvm.options配置文件来设定JVM的相关设定。如果没有特殊需求按默认即可。 不过其中还是有两项最重要的-Xmx1g 与
-Xms1gJVM的最大最小Heap。如果太小会导致Elasticsearch刚刚启动就立刻停止。太大会拖慢
系统本身。

4.启动es
1、给elasticsearch文件夹分配es权限
chown -R es:es elasticsearch文件路径
2、切换至es用户su - es
3、启动ES
- bin/elasticsearch --前台启动
- bin/elasticsearch -d --后台启动
5.验证ES集群:
shell命令行访问 :
curl localhost:9200/_cluster/health?pretty
命令输出信息:
[es@ecs-dev-0002 bin]$ curl localhost:9200/_cluster/health?pretty
{
"cluster_name" : "wit",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}本地http访问:
curl http://localhost:9200
外部http访问:
开放防火墙端口:
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --reload
systemctl daemon-reload
导入数据到ES:
json数据文件data.json如下:
它的第一行定义了_index,_type,_id等信息;第二行定义了字段的信息(关于ES数据格式问题,比如要有哪些字段,请自行研究)。
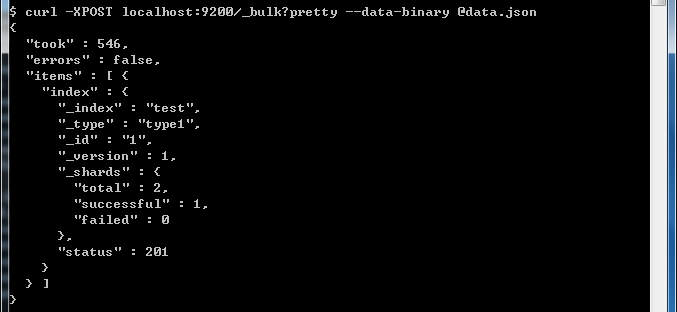
{ "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }curl -H "Content-Type: application/json" -X POST localhost:9200/_bulk --data-binary @data.json
执行结果如下:
三、安装Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,使用Kibana可以查询、查看并与存储在ES索引的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据。
1.获取到安装包
获取kibana-7.8.1-linux-x86_64.tar(自己去官网下载,这里不提供),然后解压
tar xvf kibana-7.8.1-linux-x86_64.tar2.配置yum源(由于不是yum安装,所以这里不需要,仅仅作为以后的参考):
在/etc/yum.repos.d/ 下新建 kibana.repo 配置 yum 源地址:
新建kibana.repo:
cat>>kibana.repo
新建完成之后,在里面加上如下内容:
[kibana-7.x]
name=Kibana repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
3.修改配置文件kibana.yml:
修改config文件夹下的kibana.yml,添加信息:
server.port: 5601
server.host: “0.0.0.0”
server.name: tanklog
elasticsearch.hosts: [“http://127.0.0.0:9200/”]
注意,里面的地址是你自己服务器的IP地址。
4.开启端口5601:
如果防火墙是关闭的,首先打开防火墙,否则没办法开启5601端口:
1.输入命令、开启防火墙:
systemctl start firewalld.service
2.开启防火墙后,添加5601端口:
firewall-cmd --permanent --zone=public --add-port=5601/tcp
出现success,说明端口开启成功。
3.重启防火墙:
firewall-cmd --reload
5.启动kibana:
1.启动kibana之前,先启动ElasticSearch:
进入ES安装包下的bin目录,输入命令:
./elasticsearch -d(后代运行)
2.启动Kibana:
进入kibana安装目录下的bin目录,输入命令:
(1).新建kibana账户(推荐):
#useradd kibana
授权:
chown -R kibana:kibana kibana目录
切换账户:
su - kibana
启动kibana:
nohup ./kibana &
(2).如果在root账户下启动kibana
需要加--allow-root参数。
nohup ./kibana --allow-root & (--allow-root表示允许root用户去启动)
3.关闭防火墙:
kibana成功启动后,关闭防火墙:
systemctl stop firewalld.service
4.访问kibana:
浏览器中输入: http://IP:5601/app/kibana
四、华为云使用问题总结:
1.怎样登录服务器Linux控制台
访问华为云,没有开启ssh等功能的情况下,怎样在管理界面中访问华为云?
点击某个服务器的远程登录按钮
弹出对话框,选择"CloudShell登录"
输入密码,然后就可以进入centos7的控制台了。
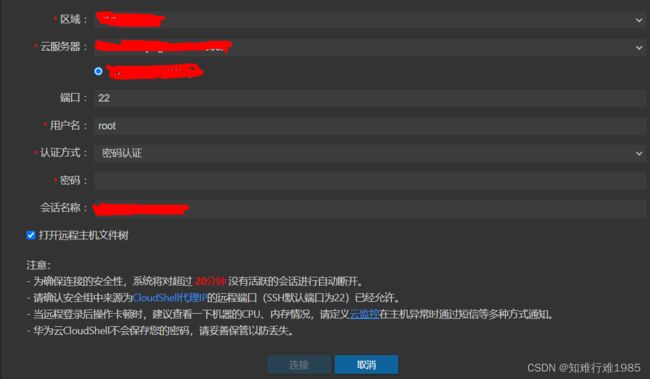
Note:如果服务器的名字与其它服务器重名,则可能进入其它相同名字服务器的控制台,所以要把服务器的名字改成唯一的。
但是在使用过程中出现了问题,什么问题呢?连接超时
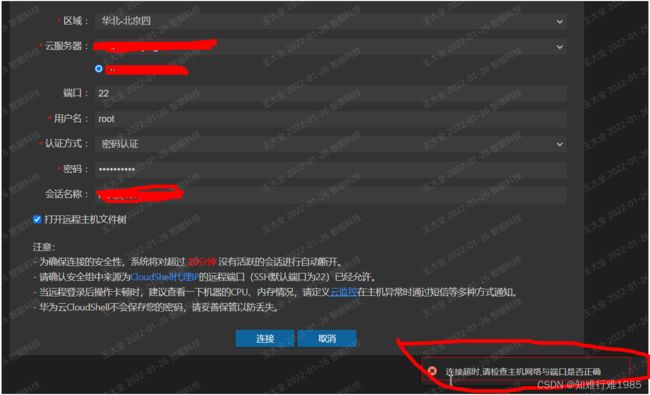
怎样解决?配置安全组,在安全组里加入三个地址,允许它们对云服务器的访问
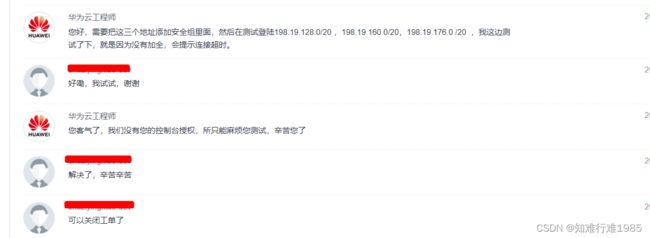
将这三个地址加入安全组,问题解决,可以使用CloudShell的方式登录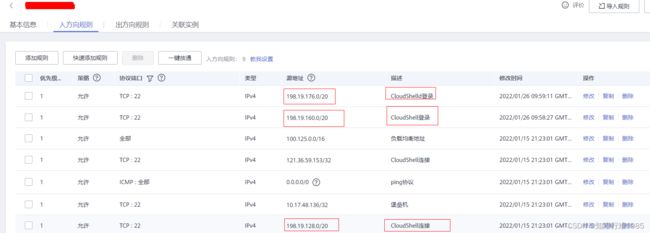
2.怎样上传文件:
在左侧的资源列表,在某个文件夹中右键,然后选择文件上传到这个文件夹。
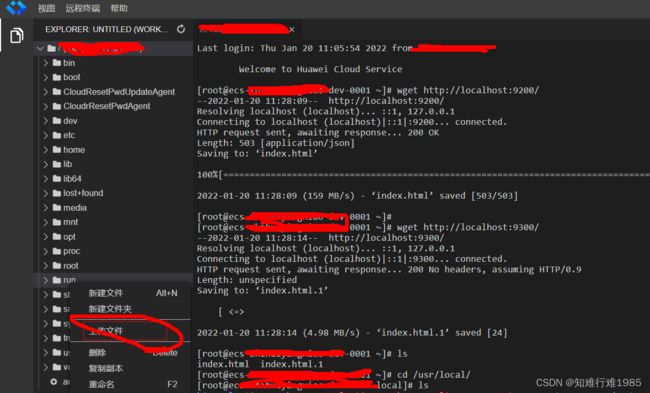
五、参考文章:
这篇参考文章写得还可以
kibana几次崩溃问题引发的探索_墨的博客-CSDN博客_kibana崩溃
ELK笔记(一):Centos7部署elasticsearch-7.8.0集群_pangfaheng的博客-CSDN博客
elasticsearch7 集群搭建(三个master节点)_天涯的博客-CSDN博客_es 多master
ES与java版本关系:支持矩阵 | Elastic