MIT 6.828 (六) Lab 6: Network Driver (default final project)
这是最后一个实验,做完这个一个基本的内核就做完了。这章需要自己去看的东西特么的多,所以大部分,我们就看看实现了什么,不会专门一个个细节的看了。
Lab 6: Network Driver (default final project)
Introduction
Lab6 是最后一个实验了,做完这个,一个简单的内核就已经实现了,现在你可以自己做自己的内核。
现在,你有一个文件系统,操作系统没有网络堆栈。在这个实验室里你要编写一个网络接口卡的驱动程序。该卡将基于Intel 82540EM芯片,也被称为E1000上。
Getting Started
先切换个分支。
除了编写驱动程序之外,您还需要创建一个系统调用接口来授予对驱动程序的访问权限。您将实现缺少的网络服务器代码,以在网络堆栈和驱动程序之间传输数据包。您还将通过完成Web服务器将所有内容捆绑在一起。使用新的Web服务器,您将能够从文件系统提供文件。
您必须从头开始编写许多内核设备驱动程序代码。与以前的实验相比,本实验提供的指导要少得多:没有框架文件,没有任何固定的系统调用接口,许多设计决策都由您自己决定。因此,我们建议您在开始任何练习之前,先阅读整个作业记录。许多学生发现本实验比以前的实验困难得多,因此请相应地计划您的时间。
最终你会发现这个主要难点就是看文档写驱动。
根据他的推荐让我们先看看整个任务,直接用谷歌流浪器,翻译整个页面,然后大致看看。
看完之后发现并没有什么卵用,还是不懂,还是慢慢来。
QEMU’s virtual network
我们将使用QEMU的用户模式网络堆栈,因为它不需要运行任何管理权限。QEMU的文档在这里有更多关于user-net的信息。我们已经更新了makefile,以启用QEMU的用户模式网络堆栈和虚拟E1000网卡。
默认情况下,QEMU提供运行在IP 10.0.2.2上的虚拟路由器,并将为JOS分配IP地址10.0.2.15。为了简单起见,我们将这些默认值硬编码到net/ns.h中的网络服务器中。
我们简单看一下这个文件
#include 尽管QEMU的虚拟网络允许JOS进行到Internet的任意连接,但JOS的10.0.2.15地址在QEMU内部运行的虚拟网络外部没有任何意义(即QEMU充当NAT),因此我们无法直接连接到服务器即使在运行QEMU的主机中,也可以在JOS内部运行。为了解决这个问题,我们将QEMU配置为在主机上某个端口上运行服务器,该服务器仅连接到JOS中的某个端口,并在真实主机和虚拟网络之间来回穿梭数据。
您将在端口7(回显)和80(http)上运行JOS服务器。为避免在共享的Athena机器上发生冲突,makefile会根据您的用户ID为这些机器生成转发端口。要查找QEMU将要转发到您的开发主机上的端口,请运行make which-ports。为了方便起见,makefile还提供make nc-7和make nc-80,使您可以直接与在终端中这些端口上运行的服务器进行交互。(这些目标仅连接到正在运行的QEMU实例;您必须单独启动QEMU本身。)
通俗点来讲,就是 这个JOS服务器用的是 7 和80端口,但是你的虚拟机上面可能已经用了,所以帮你转发到另一个端口了。
Packet Inspection
生成文件还配置QEMU的网络堆栈,以将所有传入和传出数据包记录到您的实验室目录中的qemu.pcap。
要获取捕获的数据包的hex/ASCII,请使用tcpdump,如下所示:
tcpdump -XXnr qemu.pcap或者,您可以使用Wireshark以图形方式检查pcap文件。Wireshark还知道如何解码和检查数百种网络协议。如果您使用的是Athena,则必须使用Wireshark的前身ethereal,它位于sipbnet locker。
Debugging the E1000
我们很幸运能够使用仿真硬件。由于E1000在软件中运行,因此仿真的E1000可以以用户可读的格式向我们报告其内部状态以及遇到的任何问题。通常,使用裸机编写驱动程序的开发人员将无法获得这种奢侈。
E1000可以产生很多调试输出,因此您必须启用特定的日志记录通道。您可能会发现有用的一些渠道是:
| Flag | Meaning |
|---|---|
| tx | 日志包发送操作 |
| txerr | 记录传输环错误 |
| rx | 将更改记录到RCTL |
| rxfilter | 传入数据包的日志过滤 |
| rxerr | 日志接收振铃错误 |
| unknown | 日志读取和写入未知寄存器 |
| eeprom | 从EEPROM读取日志 |
| interrupt | 记录中断和更改到中断寄存器。 |
例如,要启用tx和txerr日志记录,请使用make E1000_DEBUG=tx,txerr ...。
注意: E1000_DEBUG标志仅在6.828版本的QEMU中起作用。
您可以进一步使用软件仿真的硬件进行调试。如果您陷入困境并且不了解E1000为什么没有按预期方式做出响应,则可以在hw/net/e1000.c中查看QEMU的E1000实现。
The Network Server
从头开始编写网络堆栈是一项艰巨的工作。相反,我们将使用lwIP,这是一个开源的轻量级TCP/IP协议套件,其中包括一个网络堆栈。您可以在此处找到有关lwIP的更多信息 。就此而言,就我们而言,lwIP是一个黑箱,它实现了BSD套接字接口,并具有一个数据包输入端口和一个数据包输出端口。
网络服务器实际上是四个环境的组合:
- 核心网络服务器环境(包括套接字调用分派器和
lwIP) - 输入环境
- 输出环境
- 计时器环境
下图显示了不同的环境及其关系。该图显示了包括设备驱动程序在内的整个系统,稍后将进行介绍。在本实验中,您将实现以绿色突出显示的部分。
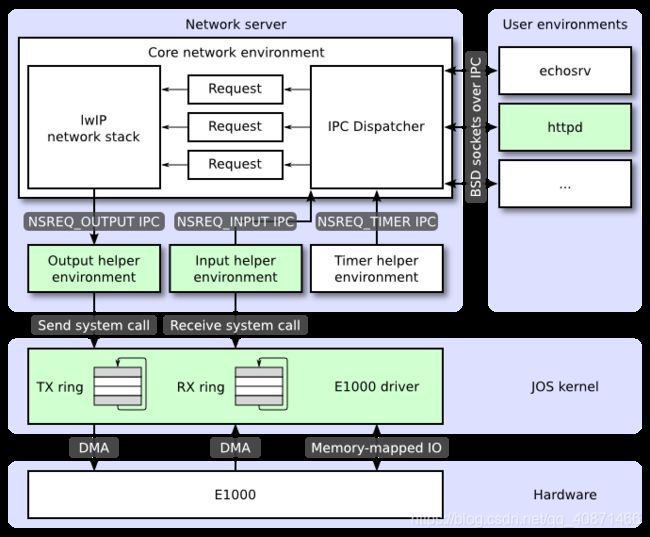
这个地方已经告诉你我们要实现什么了
- 实现
E1000驱动里面的TX用于传输数据,RX用于发送数据。 - 实现
发送环境和输出环境,时钟环境已经帮我们实现好了,我们后面会去看看 http服务器,这些事具体应用服务器了。
The Core Network Server Environment
核心网络服务器环境由套接字调用分派器和lwIP本身组成。套接字调用调度程序的工作方式与文件服务器完全相同。用户环境使用存根(可在lib/nsipc.c中找到)将IPC消息发送到核心网络环境。如果查看 lib/nsipc.c,您会发现我们找到核心网络服务器的方式与找到文件服务器的方式相同:i386_init使用NS_TYPE_NS创建NS环境,因此我们扫描envs,寻找这种特殊的环境类型。对于每个用户环境IPC,网络服务器中的调度程序代表用户调用lwIP提供的相应BSD套接字接口功能。
我们来简单看看这些东西。大部分都是一样的,我们就看看就行。
// Virtual address at which to receive page mappings containing client requests.
#define REQVA 0x0ffff000
union Nsipc nsipcbuf __attribute__((aligned(PGSIZE)));
// Send an IP request to the network server, and wait for a reply.
// The request body should be in nsipcbuf, and parts of the response
// may be written back to nsipcbuf.
// type: request code, passed as the simple integer IPC value.
// Returns 0 if successful, < 0 on failure.
static int
nsipc(unsigned type) //和 文件发送一模一样,自己看看
{
static envid_t nsenv;
if (nsenv == 0)
nsenv = ipc_find_env(ENV_TYPE_NS);
static_assert(sizeof(nsipcbuf) == PGSIZE);
if (debug)
cprintf("[%08x] nsipc %d\n", thisenv->env_id, type);
ipc_send(nsenv, type, &nsipcbuf, PTE_P|PTE_W|PTE_U);
return ipc_recv(NULL, NULL, NULL);
}
/*
struct sockaddr {
u8_t sa_len;
u8_t sa_family;
char sa_data[14];
};
*/
int
nsipc_accept(int s, struct sockaddr *addr, socklen_t *addrlen) //接受函数
{
int r;
nsipcbuf.accept.req_s = s;
nsipcbuf.accept.req_addrlen = *addrlen;
if ((r = nsipc(NSREQ_ACCEPT)) >= 0) {
struct Nsret_accept *ret = &nsipcbuf.acceptRet;
memmove(addr, &ret->ret_addr, ret->ret_addrlen);
*addrlen = ret->ret_addrlen;
}
return r;
}
再看看init.c,多了这么几行,看架势是创建了一个网络服务器。
#if !defined(TEST_NO_NS)
// Start ns.
ENV_CREATE(net_ns, ENV_TYPE_NS);
#endif
不出意外我们在net/serv.c成功找到了umian
void
umain(int argc, char **argv)
{
envid_t ns_envid = sys_getenvid();
binaryname = "ns";
// fork off the timer thread which will send us periodic messages
timer_envid = fork();//创建定时器
if (timer_envid < 0)
panic("error forking");
else if (timer_envid == 0) {
timer(ns_envid, TIMER_INTERVAL);
return;
}
// fork off the input thread which will poll the NIC driver for input
// packets
input_envid = fork();//输入环境
if (input_envid < 0)
panic("error forking");
else if (input_envid == 0) {
input(ns_envid);
return;
}
// fork off the output thread that will send the packets to the NIC
// driver
output_envid = fork();//输出环境
if (output_envid < 0)
panic("error forking");
else if (output_envid == 0) {
output(ns_envid);
return;
}
// lwIP requires a user threading library; start the library and jump
// into a thread to continue initialization.
thread_init();//线程初始化 //做实现开始之前回来好好分析一下
thread_create(0, "main", tmain, 0);//线程创建
thread_yield();//线程调度???
// never coming here!
}
常规用户环境不会nsipc_*直接使用呼叫。相反,它们使用lib/ sockets.c中的函数,该函数提供了基于文件描述符的套接字API。因此,用户环境通过文件描述符引用套接字,就像它们引用磁盘文件一样。多个操作(connect,accept等)特定于插座,但是read,write和 close经过在正常文件描述符设备分派代码lib/fd.c。就像文件服务器为所有打开的文件维护内部唯一ID的方式一样,lwIP还会为所有打开的套接字生成唯一的ID。在文件服务器和网络服务器中,我们都使用存储在其中的信息将struct Fd每个环境的文件描述符映射到这些唯一的ID空间。
我们去看看lib/sockets.c和前面的文件服务调用的接口也是一样的。
即使文件服务器和网络服务器的IPC调度程序看起来似乎相同,也存在关键区别。BSD套接字调用like accept和recv可以无限期阻塞。如果调度程序要让lwIP执行这些阻塞调用之一,则调度程序也将阻塞,并且整个系统一次只能有一个未完成的网络调用。由于这是不可接受的,因此网络服务器使用用户级线程来避免阻塞整个服务器环境。对于每个传入的IPC消息,调度程序都会创建一个线程并在新创建的线程中处理请求。如果线程阻塞,则只有该线程进入睡眠状态,而其他线程继续运行。
除了核心网络环境外,还有三个帮助程序环境。除了接受来自用户应用程序的消息外,核心网络环境的调度程序还接受来自输入和计时器环境的消息。
核心服务器环境,本质上就是一个文件服务器,他负责和高层的数据交换,比如说,http要用socket.c,就调用socket.c里面的一个操作,然后进行转发传到输入/输出环境,他在在E1000来进行硬件操作。
The Output Environment
为用户环境套接字调用提供服务时,lwIP将生成数据包供网卡传输。LwIP将使用NSREQ_OUTPUTIPC消息将每个要发送的数据包发送到输出帮助程序环境,并将该数据包附加在IPC消息的page参数中。输出环境负责接受这些消息,并通过即将创建的系统调用接口将数据包转发到设备驱动程序。
The Input Environment
网卡收到的数据包需要注入lwIP。对于设备驱动程序收到的每个数据包,输入环境(使用您将实现的内核系统调用)将数据包拉出内核空间,然后使用NSREQ_INPUTIPC消息将数据包发送到核心服务器环境。
数据包输入功能与核心网络环境分开,因为JOS使其难以同时接受IPC消息以及轮询或等待来自设备驱动程序的数据包。我们select 在JOS中没有系统调用,该调用允许环境监视多个输入源以标识准备好处理哪些输入。
如果你看看net/input.c和net/output.c你会看到,都需要执行。这主要是因为实现取决于您的系统调用接口。在实现驱动程序和系统调用接口之后,将为两个帮助程序环境编写代码。
The Timer Environment
计时器环境会定期向NSREQ_TIMER核心网络服务器发送消息类型,通知其计时器已过期。lwIP使用此线程的计时器消息来实现各种网络超时。
通过这些我们大致知道这个网络的流程了,实际上核心服务器和文件服务器是一模一样的,让我们再做一次实际上也就是把上次的代码在看一遍。至于输出环境,输入环境和时钟环境,就是让我们实现的东西。
前置代码分析
到这个地方,我们已经知道了基本的结构,但是我们还是对代码没啥了解。所以我们来看看多的代码做了什么。
一如既往,一切的起点,肯定init,前面我们已经看过一点了。
// Lab 6 hardware initialization functions//多了这些东西,看注释事硬件初始化
time_init(); //这个后面第一个实验就会讲是什么,是给内核添加时钟的概念用的
pci_init(); //这个是 PCI初始化,也就是搜索所有 用PCI连接的硬件
#if !defined(TEST_NO_NS)
// Start ns.
ENV_CREATE(net_ns, ENV_TYPE_NS);//这个说过了就是核心环境启动,而且通过这个fork 除了 输入/输出/时钟环境
#endif
我们知道这些之后,我们再去看看net里面的东西.
我靠一进去看里面的lwip目录,我靠那么多东西,看个鬼,告辞。我们还是继续看看serv.c,这个input.c和output.c,是输入输出,后面主要要做的。
一开始我们已经看了一部分,我们直接看看这个线程。
thread_init();
thread_create(0, "main", tmain, 0);
thread_yield();
//lwpic/jos/thread.c
void
thread_init(void) {
threadq_init(&thread_queue);//进去看这个函数
max_tid = 0;
}
//lwpic/jos/threadq.h
static inline void
threadq_init(struct thread_queue *tq)
{
tq->tq_first = 0;
tq->tq_last = 0;
}
struct thread_context;//一个这个表示一个进程
struct thread_queue //一个线程池,或许应该叫线程队列
{
struct thread_context *tq_first;
struct thread_context *tq_last;
};
struct thread_context { //线程结构题 也就是TCB
thread_id_t tc_tid; //线程ID
void *tc_stack_bottom;//线程栈
char tc_name[name_size];//线程名
void (*tc_entry)(uint32_t);//线程指令地址 ,实现过线程这个很好理解
uint32_t tc_arg;//参数
struct jos_jmp_buf tc_jb;//这个可以简单理解为 保存CPU的内容
volatile uint32_t *tc_wait_addr;
volatile char tc_wakeup;
void (*tc_onhalt[THREAD_NUM_ONHALT])(thread_id_t);
int tc_nonhalt;
struct thread_context *tc_queue_link;
};
然后我们运行了线程创建
int
thread_create(thread_id_t *tid, const char *name,
void (*entry)(uint32_t), uint32_t arg) {
struct thread_context *tc = malloc(sizeof(struct thread_context));//分配一个空间
if (!tc)
return -E_NO_MEM;
memset(tc, 0, sizeof(struct thread_context));
thread_set_name(tc, name);//这个不用多说了
tc->tc_tid = alloc_tid();//自己看
tc->tc_stack_bottom = malloc(stack_size);//每个线程应该有独立的栈,但是一个进程的线程内存是共享的,因为共用一个页表。 很明显的能够看出来,TCB没有页表,所以内存都是共享的,所以理论上来说,是可以跨线程访问栈的。
if (!tc->tc_stack_bottom) {
free(tc);
return -E_NO_MEM;
}
void *stacktop = tc->tc_stack_bottom + stack_size;
// Terminate stack unwinding
stacktop = stacktop - 4;
memset(stacktop, 0, 4);
memset(&tc->tc_jb, 0, sizeof(tc->tc_jb));
tc->tc_jb.jb_esp = (uint32_t)stacktop;//初始化栈顶
tc->tc_jb.jb_eip = (uint32_t)&thread_entry;//初始化入口,函数指针
tc->tc_entry = entry;
tc->tc_arg = arg;//参数
threadq_push(&thread_queue, tc);//加入线程队列
if (tid)
*tid = tc->tc_tid;
return 0;
}
然后调用了线程调度
void
thread_yield(void) {
struct thread_context *next_tc = threadq_pop(&thread_queue);//弹出了一个线程
if (!next_tc)
return;
if (cur_tc) {
if (jos_setjmp(&cur_tc->tc_jb) != 0)
return;
threadq_push(&thread_queue, cur_tc);//保存当前线程
}
cur_tc = next_tc;
jos_longjmp(&cur_tc->tc_jb, 1);//将下一个线程对应的thread_context结构的tc_jb字段恢复到CPU继续执行
}
//所以从这个地方就跑去了运行线程main函数了。
static void
tmain(uint32_t arg) {
serve_init(inet_addr(IP),
inet_addr(MASK),
inet_addr(DEFAULT));//初始化了一点东西
serve();//然后就是这个服务了
}
serve()里面主要是和另外两个环境通信。
void
serve(void) {
int32_t reqno;
uint32_t whom;
int i, perm;
void *va;
while (1) {
// ipc_recv will block the entire process, so we flush
// all pending work from other threads. We limit the
// number of yields in case there's a rogue thread.
for (i = 0; thread_wakeups_pending() && i < 32; ++i)
thread_yield();
perm = 0;
va = get_buffer();
reqno = ipc_recv((int32_t *) &whom, (void *) va, &perm);//在这个地方进行通信
if (debug) {
cprintf("ns req %d from %08x\n", reqno, whom);
}
// first take care of requests that do not contain an argument page
if (reqno == NSREQ_TIMER) {//这个就是如果通信来自时钟
process_timer(whom);
put_buffer(va);
continue;
}
// All remaining requests must contain an argument page
if (!(perm & PTE_P)) {
cprintf("Invalid request from %08x: no argument page\n", whom);
continue; // just leave it hanging...
}
// Since some lwIP socket calls will block, create a thread and
// process the rest of the request in the thread.
struct st_args *args = malloc(sizeof(struct st_args));
if (!args)
panic("could not allocate thread args structure");
args->reqno = reqno;
args->whom = whom;
args->req = va;
thread_create(0, "serve_thread", serve_thread, (uint32_t)args);//给他创建一个线程去处理。
thread_yield(); // let the thread created run
}
}
在serve()经历了一大堆,最终处理事件的函数是serve_thread了,可以在里面明确的看出是啥。
static void
serve_thread(uint32_t a) {
struct st_args *args = (struct st_args *)a;
union Nsipc *req = args->req;
int r;
switch (args->reqno) {
case NSREQ_ACCEPT:
{
struct Nsret_accept ret;
ret.ret_addrlen = req->accept.req_addrlen;
r = lwip_accept(req->accept.req_s, &ret.ret_addr,
&ret.ret_addrlen);
memmove(req, &ret, sizeof ret);
break;
}
case NSREQ_BIND:
r = lwip_bind(req->bind.req_s, &req->bind.req_name,
req->bind.req_namelen);
break;
case NSREQ_SHUTDOWN:
r = lwip_shutdown(req->shutdown.req_s, req->shutdown.req_how);
break;
case NSREQ_CLOSE:
r = lwip_close(req->close.req_s);
break;
case NSREQ_CONNECT:
r = lwip_connect(req->connect.req_s, &req->connect.req_name,
req->connect.req_namelen);
break;
case NSREQ_LISTEN:
r = lwip_listen(req->listen.req_s, req->listen.req_backlog);
break;
case NSREQ_RECV:
// Note that we read the request fields before we
// overwrite it with the response data.
r = lwip_recv(req->recv.req_s, req->recvRet.ret_buf,
req->recv.req_len, req->recv.req_flags);
break;
case NSREQ_SEND:
r = lwip_send(req->send.req_s, &req->send.req_buf,
req->send.req_size, req->send.req_flags);
break;
case NSREQ_SOCKET:
r = lwip_socket(req->socket.req_domain, req->socket.req_type,
req->socket.req_protocol);
break;
case NSREQ_INPUT:
jif_input(&nif, (void *)&req->pkt);
r = 0;
break;
default:
cprintf("Invalid request code %d from %08x\n", args->whom, args->req);
r = -E_INVAL;
break;
}
if (r == -1) {
char buf[100];
snprintf(buf, sizeof buf, "ns req type %d", args->reqno);
perror(buf);
}
if (args->reqno != NSREQ_INPUT)
ipc_send(args->whom, r, 0, 0);
put_buffer(args->req);
sys_page_unmap(0, (void*) args->req);
free(args);
}
然后就从其中调用了lwip的一些函数,这个里面有一个socket.c和lib/socket.c有点不一样,也不知道有啥区别,个人觉得是lib/socket.c是系统里面的调用给用户用的这个文件里面的应该是进行底层调用的。具体就不分析了,有兴趣的自己去看看。
其他三个环境后面再看。
Part A: Initialization and transmitting packets
您的内核没有时间概念,因此我们需要添加它。当前,硬件每10毫秒产生一次时钟中断。在每个时钟中断处,我们都可以增加一个变量以指示时间提前了10ms。这是在kern/ time.c中实现的,但尚未完全集成到您的内核中。
不着急做实验,我们先去看看kern/ time.c
#include 看了这个练习1就简单了。练习1就是让我们把他加入内核。我们已经在内核里面初始化了,现在我们需要时钟跳动。那么什么时候时钟增加呢。我们已经实现了时钟中断,所以我们在这个时候调用就行了。另外一个添加一个系统调用获取时钟就行了。
case IRQ_OFFSET + IRQ_TIMER:{
lapic_eoi();
time_tick();//时钟中断 时钟增加
sched_yield();
break;
}
// Return the current time.
static int
sys_time_msec(void)//获取时钟
{
// LAB 6: Your code here.
//panic("sys_time_msec not implemented");
return time_msec();
}
//这个绝对不要完了再syscall()里面添加
case SYS_time_msec:
return sys_time_msec();
我们现在可以实现是时钟环境,我们去看看net/time.c
#include "ns.h"
void
timer(envid_t ns_envid, uint32_t initial_to) {
int r;
uint32_t stop = sys_time_msec() + initial_to;
binaryname = "ns_timer";
while (1) {
while((r = sys_time_msec()) < stop && r >= 0) {//没到到时间
sys_yield();
}
if (r < 0)
panic("sys_time_msec: %e", r);
ipc_send(ns_envid, NSREQ_TIMER, 0, 0);//到了时钟就给核心服务程序发了一个信息
while (1) {
uint32_t to, whom;
to = ipc_recv((int32_t *) &whom, 0, 0);
if (whom != ns_envid) {
cprintf("NS TIMER: timer thread got IPC message from env %x not NS\n", whom);
continue;
}
stop = sys_time_msec() + to;//时钟改变
break;
}
}
}
The Network Interface Card
编写驱动程序需要深入了解硬件和提供给软件的接口。该实验文本将提供有关如何与E1000进行交互的高级概述,但是您在编写驱动程序时需要充分利用Intel的手册。
练习2让我门看看手册。因为是全英文的又不能翻译所以没看。后面告诉我们需要什么我们去看什么。
后面才是真的魔鬼。
PCI Interface
E1000是PCI设备,这意味着它已插入主板上的PCI总线。PCI总线具有地址,数据和中断线,并允许CPU与PCI设备进行通信,并且PCI设备可以读写存储器。在使用PCI设备之前,需要先对其进行发现和初始化。发现是遍历PCI总线以查找连接的设备的过程。初始化是分配I/O和内存空间以及协商设备要使用的IRQ线的过程。
我们在kern/pci.c中为您提供了PCI代码。要在引导过程中执行PCI初始化,PCI代码将遍历PCI总线以查找设备。找到设备后,它将读取其供应商ID和设备ID,并将这两个值用作搜索pci_attach_vendor阵列的键。该数组由以下struct pci_driver条目组成 :
struct pci_driver {
uint32_t key1, key2;
int (*attachfn) (struct pci_func *pcif);
};
如果发现的设备的供应商ID和设备ID与阵列中的条目匹配,则PCI代码将调用该条目的attachfn来执行设备初始化。(设备也可以通过类来标识,这是kern/pci.c中其他驱动程序表的作用。)
Attach函数通过PCI函数进行初始化。尽管E1000仅提供一种功能,但PCI卡可以提供多种功能。这是我们在JOS中表示PCI功能的方式:
struct pci_func {
struct pci_bus *bus;
uint32_t dev;
uint32_t func;
uint32_t dev_id;
uint32_t dev_class;
uint32_t reg_base[6];
uint32_t reg_size[6];
uint8_t irq_line;
};
以上结构反映了开发人员手册第4.1节表4-1中的某些条目。(大家可以去看看)后三个条目 struct pci_func对我们特别有意义,因为它们记录了设备的协商内存,I/O和中断资源。在reg_base与reg_size阵列包含多达六个基地址寄存器或条信息。reg_base存储用于内存映射的I/O区域(或用于I/O端口资源的基本I/O端口)的基本内存地址, reg_size包含来自的相应基本值的字节大小或I/O端口数reg_base,并irq_line包含分配给设备的IRQ线路用于中断。E1000 BAR的具体含义在表4-2的后半部分给出。
调用设备的附加功能时,已找到该设备但尚未启用。这意味着PCI代码尚未确定分配给设备的资源,例如地址空间和IRQ线,因此该struct pci_func结构的最后三个元素尚未填写。attach函数应调用 pci_func_enable,将启用设备,协商这些资源并填写struct pci_func。
看到这个时候应该和我一样云里雾里的,这他妈都在讲些啥啊。
我们简单来说,我们现在需要把设备启动,然后把供应商ID和设备ID对上号,然后需要一个函数启动这个设备。怎么初始化,怎么启动,先不去管他。
我们来分析pci_init怎么执行的。
int
pci_init(void)
{
static struct pci_bus root_bus;//这是个总线结构体就是他提供的。
/*
struct pci_bus {
struct pci_func *parent_bridge;
uint32_t busno;//总线号,因为可能存在多总线
};
struct pci_func {
struct pci_bus *bus; // Primary bus for bridges 主要的总线
uint32_t dev;//这些介绍全在文档里面
uint32_t func;//
uint32_t dev_id;//
uint32_t dev_class;
uint32_t reg_base[6];
uint32_t reg_size[6];
uint8_t irq_line;
};
*/
memset(&root_bus, 0, sizeof(root_bus));
return pci_scan_bus(&root_bus);//然后开始扫描
}
static int
pci_scan_bus(struct pci_bus *bus)
{
int totaldev = 0;
struct pci_func df;
memset(&df, 0, sizeof(df));
df.bus = bus;
for (df.dev = 0; df.dev < 32; df.dev++) {
uint32_t bhlc = pci_conf_read(&df, PCI_BHLC_REG);//在df里面找PCI_BHLC_REG ,具体就不用去关心了
if (PCI_HDRTYPE_TYPE(bhlc) > 1) // Unsupported or no device不支持设备或者没有这个设备
continue;
totaldev++;//设备数+1
struct pci_func f = df;
for (f.func = 0; f.func < (PCI_HDRTYPE_MULTIFN(bhlc) ? 8 : 1);
f.func++) {
struct pci_func af = f;
af.dev_id = pci_conf_read(&f, PCI_ID_REG);//读取ID
if (PCI_VENDOR(af.dev_id) == 0xffff)
continue;
uint32_t intr = pci_conf_read(&af, PCI_INTERRUPT_REG);//读取中断
af.irq_line = PCI_INTERRUPT_LINE(intr);
af.dev_class = pci_conf_read(&af, PCI_CLASS_REG);//读取class
if (pci_show_devs)//打印获取到的设备信息
pci_print_func(&af);
pci_attach(&af);//这个函数我们进去看看
}
}
return totaldev;
}
static int
pci_attach(struct pci_func *f)
{
return
pci_attach_match(PCI_CLASS(f->dev_class),
PCI_SUBCLASS(f->dev_class),
&pci_attach_class[0], f) ||
pci_attach_match(PCI_VENDOR(f->dev_id),
PCI_PRODUCT(f->dev_id),
&pci_attach_vendor[0], f);
}
pci_attach_match(uint32_t key1, uint32_t key2,
struct pci_driver *list, struct pci_func *pcif)
{
uint32_t i;
for (i = 0; list[i].attachfn; i++) {
if (list[i].key1 == key1 && list[i].key2 == key2) {//如果匹配上了
int r = list[i].attachfn(pcif);//这样去运行了
if (r > 0)
return r;
if (r < 0)
cprintf("pci_attach_match: attaching "
"%x.%x (%p): e\n",
key1, key2, list[i].attachfn, r);
}
}
return 0;
}
简单思考了下,pci_init 应该就是扫描了一下总线把总线里面的所有设备,然后初始化了他们,然后返回了总共的设备数量。
在 pci_attach 我们调用了pci_attach_vendor,我们看到这个东西,现在里面啥都没有。所以我们现在要做的就是把我们的网卡驱动添进去初始化。
练习3然我们添加他,并添加初始化函数。
我们运行内核很容易看出来网卡的信息。
同样我们在文档5.1节的表里找到了这个东西
![]()
那么还有个问题,厂商号、设备号有了,怎么初始化????实验的要求是让我写在e1000.h和e1000.c先不管这些,我们先把函数定义好。
先在e1000.h里面定义
#include
//然后修改pci_driver
// pci_attach_vendor matches the vendor ID and device ID of a PCI device. key1
// and key2 should be the vendor ID and device ID respectively
#define PCI_E1000_VENDOR_ID 0x8086
#define PCI_E1000_DEVICE_ID 0x100E
struct pci_driver pci_attach_vendor[] = {
{ PCI_E1000_VENDOR_ID, PCI_E1000_DEVICE_ID, &e1000_init},
{ 0, 0, 0 },
};
在我万般无奈的时候看到了一句练习里面的提示For now, just enable the E1000 device via pci_func_enable. We'll add more initialization throughout the lab.你他妈在逗我,告辞,两行解决。
uint32_t *pci_e1000;
int
e1000_init(struct pci_func *pcif)
{
pci_func_enable(pcif);
return 1;
}
因为会用到其他头文件的的函数,所以先把头文件加入好,最终会用到
#include 出现头文件问题自己去看看少了啥。
软件通过内存映射的I/O(MMIO)与E1000通信。您在JOS中已经看过两次了:CGA控制台和LAPIC都是通过写入和读取“内存”来控制和查询的设备。但是这些读和写操作不会存储到DRAM中。他们直接去这些设备。
pci_func_enable与E1000协商MMIO区域,并将其基数和大小存储在BAR 0(即 reg_base[0]和reg_size[0])中。这是分配给设备的一系列物理内存地址,这意味着您必须做一些事情才能通过虚拟地址访问它。由于MMIO区域分配了很高的物理地址(通常大于3GB),KADDR因此由于JOS的256MB限制,您不能使用它来访问它。因此,您必须创建一个新的内存映射。我们将使用MMIOBASE上方的区域(您 mmio_map_region在实验4中将确保我们不会覆盖LAPIC使用的映射)。由于PCI设备初始化发生在JOS创建用户环境之前,因此您可以在其中创建映射,kern_pgdir并且该映射将始终可用。
练习4 实现mmio_map_region为E1000的BAR 0创建虚拟内存映射,lapic = mmio_map_region(lapicaddr, 4096);仿着这个写一个。然后让我们打印状态,但是状态在哪。后面给了提示
提示:您将需要很多常量,例如寄存器的位置和位掩码的值。尝试将这些内容从开发人员手册中复制出来很容易出错,而错误可能导致痛苦的调试会话。我们建议改用QEMU的e1000_hw.h标头作为指导。我们不建议逐字复制它,因为它定义的内容远远超出您的实际需要,并且可能无法按照您需要的方式进行定义,但这是一个很好的起点。
我们下载那个文件,然后ctrl+f查找statu找到了这个#define E1000_STATUS 0x00008 /* Device Status - RO */,所以添进去就行了。
所以随便添加一点就行了。
uint32_t *pci_e1000;
#define E1000_STATUS 0x00008 /* Device Status - RO 建议写到头文件里面*/
int
e1000_init(struct pci_func *pcif)
{
pci_func_enable(pcif);
pci_e1000 = mmio_map_region(pcif->reg_base[0], pcif->reg_size[0]);
cprintf("the E1000 status register: [%08x]\n", *(pci_e1000+(E1000_STATUS>>2)));
return 1;
}
DMA
您可以想象通过写入和读取E1000的寄存器来发送和接收数据包,但这会很慢,并且需要E1000在内部缓冲数据包数据。相反,E1000使用直接内存访问或DMA直接从内存读取和写入数据包数据,而无需使用CPU。驱动程序负责为发送和接收队列分配内存,设置DMA描述符,并使用这些队列的位置配置E1000,但之后的所有操作都是异步的。为了发送数据包,驱动程序将其复制到发送队列中的下一个DMA描述符中,并通知E1000另一个数据包可用。当有时间发送数据包时,E1000会将数据从描述符中复制出来。同样,当E1000接收到一个数据包时,它会将其复制到接收队列中的下一个DMA描述符中,驱动程序可以在下一次机会读取该描述符。
在高层,接收和发送队列非常相似。两者都由一系列描述符组成。尽管这些描述符的确切结构有所不同,但是每个描述符都包含一些标志和包含数据包数据的缓冲区的物理地址(或者是要发送给卡的数据包数据,或者是OS为卡分配的缓冲区,用于将接收到的数据包写入卡)。
队列被实现为圆形阵列,这意味着当卡或驱动程序到达阵列的末尾时,它会回绕到开头。两者都有一个头指针和一个尾指针队列的内容是这两个指针之间的描述符。硬件始终从头消耗描述符并移动头指针,而驱动程序总是向描述符添加描述符并移动尾指针。传输队列中的描述符表示等待发送的数据包(因此,在稳定状态下,传输队列为空)。对于接收队列,队列中的描述符是卡可以接收数据包的空闲描述符(因此,在稳定状态下,接收队列由所有可用的接收描述符组成)。在不混淆E1000的情况下正确更新尾部寄存器非常棘手;小心!
这个队列是个圈,也就是取个模
指向这些数组的指针以及描述符中的数据包缓冲区的地址都必须是物理地址, 因为硬件无需通过MMU即可直接在物理RAM之间进行DMA操作。
简单来说就是给一块内存用作缓冲区,让硬件能够直接访问DMA
Transmitting Packets
E1000的发送和接收功能基本上彼此独立,因此我们可以一次完成一个工作。我们将首先攻击发送数据包的原因仅仅是因为我们无法在不发送“我在这里!”的情况下测试接收。数据包优先。
首先,您必须按照14.5节中所述的步骤初始化要传输的卡(不必担心这些小节)。传输初始化的第一步是设置传输队列。队列的精确结构在3.4节中描述,描述符的结构在3.3.3节中描述。我们将不会使用E1000的TCP卸载功能,因此您可以专注于“旧版传输描述符格式”。您现在应该阅读这些部分,并熟悉这些结构。
C Structures
您会发现使用C struct来描述E1000的结构很方便。如您所见struct Trapframe,使用C struct 等结构可以 使您精确地在内存中布置数据。C可以在字段之间插入填充,但是E1000的结构布局使得这不成问题。如果确实遇到字段对齐问题,请查看GCC的“打包”属性。
例如,请考虑手册表3-8中给出并在此处复制的旧版传输描述符:
63 48 47 40 39 32 31 24 23 16 15 0 +---------------------------------------------------------------+ | Buffer address | +---------------+-------+-------+-------+-------+---------------+ | Special | CSS | Status| Cmd | CSO | Length | +---------------+-------+-------+-------+-------+---------------+
结构的第一个字节从右上角开始,因此要将其转换为C struct,从右到左,从上到下读取。如果布局正确,您会发现所有字段甚至都非常适合标准大小的类型:
struct tx_desc
{
uint64_t addr;
uint16_t length;
uint8_t cso;
uint8_t cmd;
uint8_t status;
uint8_t css;
uint16_t special;
};
您的驱动程序将必须为传输描述符数组和传输描述符指向的数据包缓冲区保留内存。有多种方法可以执行此操作,从动态分配页面到简单地在全局变量中声明页面都可以。无论您选择什么,请记住E1000直接访问物理内存,这意味着它访问的任何缓冲区必须在物理内存中是连续的。
还有多种处理数据包缓冲区的方法。我们建议最简单的方法是,在驱动程序初始化期间为每个描述符为数据包缓冲区保留空间,并简单地将数据包数据复制到这些预分配的缓冲区中或从其中复制出来。以太网数据包的最大大小为1518字节,这限制了这些缓冲区的大小。更复杂的驱动程序可以动态分配数据包缓冲区(例如,以在网络使用率较低时减少内存开销),甚至可以传递用户空间直接提供的缓冲区(一种称为“零复制”的技术),但是最好还是从简单开始。
练习5执行第14.5节(但不包括其小节)中描述的初始化步骤。使用第13节作为初始化过程所引用的寄存器的参考,并使用3.3.3和3.4节作为发送描述符和发送描述符数组的参考。
请注意对发送描述符数组的对齐要求以及对该数组长度的限制。由于TDLEN必须对齐128字节,每个传输描述符为16字节,因此您的传输描述符数组将需要8个传输描述符的某个倍数。但是,请勿使用超过64个的描述符,否则我们的测试将无法测试传输环溢出。
对于TCTL.COLD,您可以假定为全双工操作。对于TIPG,请参阅第13.4.34节的表13-77中描述的IEEE 802.3标准IPG的默认值(不要使用第14.5节的表中的值)。
。。。对于这个,我真看不懂是啥。
按照14.5节的描述初始化。步骤如下:
- 分配一块内存用作发送描述符队列,起始地址要
16字节对齐。用基地址填充(TDBAL/TDBAH) 寄存器。 - 设置
(TDLEN)寄存器,该寄存器保存发送描述符队列长度,必须128字节对齐。 - 设置
(TDH/TDT)寄存器,这两个寄存器都是发送描述符队列的下标。分别指向头部和尾部。应该初始化为0。 - 初始化
TCTL寄存器。设置TCTL.EN位为1,设置TCTL.PSP位为1。设置TCTL.CT为10h。设置TCTL.COLD为40h。 - 设置
TIPG寄存器。
我们先把这些东西加e1000.h中,在把结构定义出来。
#define E1000_TCTL 0x00400 /* TX Control - RW */
#define E1000_TDBAL 0x03800 /* TX Descriptor Base Address Low - RW */
#define E1000_TDBAH 0x03804 /* TX Descriptor Base Address High - RW */
#define E1000_TDLEN 0x03808 /* TX Descriptor Length - RW */
#define E1000_TDH 0x03810 /* TX Descriptor Head - RW */
#define E1000_TDT 0x03818 /* TX Descripotr Tail - RW */
#define E1000_TIPG 0x00410 /* TX Inter-packet gap -RW */
#define E1000_TCTL_EN 0x00000002 /* enable tx */
#define E1000_TCTL_BCE 0x00000004 /* busy check enable */
#define E1000_TCTL_PSP 0x00000008 /* pad short packets */
#define E1000_TCTL_CT 0x00000ff0 /* collision threshold */
#define E1000_TCTL_COLD 0x003ff000 /* collision distance */
#define E1000_TXD_CMD_RS 0x08000000 /* Report Status */
#define E1000_TXD_STAT_DD 0x00000001 /* Descriptor Done */
#define E1000_TXD_CMD_EOP 0x01000000 /* End of Packet */
#define TX_MAX 64 //发送包的最大数量
#define BUFSIZE 2048
struct tx_desc
{
uint64_t addr;
uint16_t length;
uint8_t cso;
uint8_t cmd;
uint8_t status;
uint8_t css;
uint16_t special;
}__attribute__((packed));
struct tx_desc tx_list[TX_MAX];//描述符
struct packets{
char buffer[BUFSIZE];//16对齐
}__attribute__((packed));
struct packets tx_buf[TX_MAX];//缓冲区
具体实现,我只是看别人的看懂了。。。。
//这个初始化函数是要在前面那个初始化e1000_init里面调用,不然不会运行
void
e1000_transmit_init(){
//初始化
memset(tx_list, 0, sizeof(struct tx_desc)*TX_MAX);
memset(tx_buf, 0, sizeof(struct packets)*TX_MAX);
for(int i=0; i<TX_MAX; i++){
tx_list[i].addr = PADDR(tx_buf[i].buffer);
tx_list[i].cmd = (E1000_TXD_CMD_EOP>>24) | (E1000_TXD_CMD_RS>>24);
tx_list[i].status = E1000_TXD_STAT_DD;
}
//填充E1000_TDBAL/E1000_TDBAH
pci_e1000[E1000_TDBAL>>2] = PADDR(tx_list);
pci_e1000[E1000_TDBAH>>2] = 0;
//设置长度
pci_e1000[E1000_TDLEN>>2] = TX_MAX*sizeof(struct tx_desc);
//初始化头尾
pci_e1000[E1000_TDH>>2] = 0;
pci_e1000[E1000_TDT>>2] = 0;
//设置寄存器的值
pci_e1000[E1000_TCTL>>2] |= (E1000_TCTL_EN | E1000_TCTL_PSP |
(E1000_TCTL_CT & (0x10<<4)) |
(E1000_TCTL_COLD & (0x40<<12)));
pci_e1000[E1000_TIPG>>2] |= (10) | (4<<10) | (6<<20);
}
现在,传输已初始化,您将必须编写代码以传输数据包,并使其通过系统调用可在用户空间访问。要传输数据包,您必须将其添加到传输队列的末尾,这意味着将数据包数据复制到下一个数据包缓冲区,然后更新TDT(传输描述符末尾)寄存器以通知卡中存在另一个数据包。传输队列。(请注意,TDT是传输描述符数组的索引,而不是字节偏移量;文档对此并不十分清楚。)
但是,发送队列只有这么大。如果卡落后于传输数据包并且传输队列已满怎么办?为了检测到这种情况,您需要E1000的一些反馈。不幸的是,您不能只使用TDH(发送描述符头)寄存器。该文档明确指出,从软件读取该寄存器是不可靠的。但是,如果您在发送描述符的命令字段中设置了RS位,则当卡已在该描述符中发送了数据包时,卡将在描述符的状态字段中将DD位置为1。如果已将描述符的DD位置1,则可以安全地回收该描述符并使用它传输另一个数据包。
如果用户呼叫您的传输系统调用,但未设置下一个描述符的DD位,表明传输队列已满怎么办?您必须决定在这种情况下该怎么做。您可以简单地丢弃数据包。网络协议对此具有一定的弹性,但是如果丢弃大量的数据包,则该协议可能无法恢复。您可以改为告诉用户环境必须重试,就像您对所做的一样sys_ipc_try_send。这样做的好处是可以推迟生成数据的环境。
前面已经初始化了发送,现在就是要你实现发送功能。
练习6通过检查下一个描述符是否空闲,将包数据复制到下一个描述符并更新TDT,编写一个函数来发送数据包。确保处理传输队列已满。
int
fit_txd_for_E1000_transmit(void *addr, int length){
int tail = pci_e1000[E1000_TDT>>2];//取队尾
struct tx_desc *tx_next = &tx_list[tail];//获取结构体
if(length > sizeof(struct packets))//长度不能超过最大值
length = sizeof(struct packets);
if((tx_next->status & E1000_TXD_STAT_DD) == E1000_TXD_STAT_DD){//通过这个标志位实现判断
memmove(KADDR(tx_next->addr), addr, length);
tx_next->status &= !E1000_TXD_STAT_DD;
tx_next->length = (uint16_t)length;
pci_e1000[E1000_TDT>>2] = (tail + 1)%TX_MAX;
return 0;
}
return -1;
}
练习7 将他在系统调用里面调用。这个就简单了。
添加一个新的系统调用,自己命名就行。
static int
sys_packet_try_send(void *addr, uint32_t len){
user_mem_assert(curenv, addr, len, PTE_U);
return fit_txd_for_E1000_transmit(addr, len);
}
//添加case 注意这个SYS_packet_try_send 是没有的 要在syscall.h 的头文件里面的enum 添加了。
case (SYS_packet_try_send):
return sys_packet_try_send((void *)a1,a2);
在这个地方添加之后要写到lib/syscall.c里面
int sys_packet_try_send(void *data_va, int len){
return (int) syscall(SYS_packet_try_send, 0 , (uint32_t)data_va, len, 0, 0, 0);
}
//还要在 inc/lib.h里面声明
int sys_packet_try_send(void *data_va, int len);
到这里就有系统调用发送东西了。
Transmitting Packets: Network Server
现在,您已经在设备驱动程序的发送端有了一个系统调用接口,是时候发送数据包了。输出帮助程序环境的目标是循环执行以下操作:接受NSREQ_OUTPUT来自核心网络服务器的IPC消息,并使用上面添加的系统调用将伴随这些IPC消息的数据包发送到网络设备驱动程序。该NSREQ_OUTPUT IPC的由发送low_level_output功能在 net/lwip/jos/jif/jif.c,该胶合的LWIP的堆书的网络系统。每个IPC都将包含一个页面,该页面由union Nsipc其struct jif_pkt pkt字段中包含数据包 (请参见inc / ns.h)。 struct jif_pkt
struct jif_pkt {
int jp_len;
char jp_data [0];
};
jp_len表示数据包的长度。IPC页面上的所有后续字节专用于数据包内容。jp_data在结构的末尾使用零长度数组是一种常见的C技巧,用于表示没有预定长度的缓冲区。由于C不会进行数组边界检查,因此只要您确保该结构后面有足够的未使用内存,就可以将其jp_data用作任何大小的数组。
当设备驱动程序的传输队列中没有更多空间时,请注意设备驱动程序,输出环境和核心网络服务器之间的交互。核心网络服务器使用IPC将数据包发送到输出环境。如果由于发送数据包系统调用而导致输出环境暂停,因为驱动程序没有更多的缓冲区可容纳新数据包,则核心网络服务器将阻止等待输出服务器接受IPC调用。
盗个图

这就是整个的流程了。
最终实现也简单。练习8实现output.c
#include "ns.h"
extern union Nsipc nsipcbuf;
void
output(envid_t ns_envid)
{
binaryname = "ns_output";
// LAB 6: Your code here:
// - read a packet from the network server
// - send the packet to the device driver
envid_t from_env;
int perm;
while(1){
if( ipc_recv(&from_env, &nsipcbuf, &perm) != NSREQ_OUTPUT)
continue;
while(sys_packet_try_send(nsipcbuf.pkt.jp_data, nsipcbuf.pkt.jp_len)<0)
sys_yield();
}
}
Part B: Receiving packets and the web server
我都不想说话了,整个和前面那个基本上一模一样。我直接给代码了
e100..h
#ifndef JOS_KERN_E1000_H
#define JOS_KERN_E1000_H
#include 最终的e1000.c
#include 添加 系统调用的就不贴了都一样。
input.c
#include "ns.h"
extern union Nsipc nsipcbuf;
void
sleep(int msec)//简单的延迟函数
{
unsigned now = sys_time_msec();
unsigned end = now + msec;
if ((int)now < 0 && (int)now > -MAXERROR)
panic("sys_time_msec: %e", (int)now);
while (sys_time_msec() < end)
sys_yield();
}
void
input(envid_t ns_envid)
{
binaryname = "ns_input";
// LAB 6: Your code here:
// - read a packet from the device driver
// - send it to the network server
// Hint: When you IPC a page to the network server, it will be
// reading from it for a while, so don't immediately receive
// another packet in to the same physical page.
char my_buf[2048];
int length;
while(1){
while((length = sys_packet_try_recv(my_buf))<0)
sys_yield();
nsipcbuf.pkt.jp_len=length;
memcpy(nsipcbuf.pkt.jp_data, my_buf, length);
ipc_send(ns_envid, NSREQ_INPUT, &nsipcbuf, PTE_U | PTE_P);
sleep(50);
}
}
到这个地方基本上已经全部结束了。最后让你实现http的部分代码。我也直接给了,因为如果要理解要看全部的http源码。
static int
send_data(struct http_request *req, int fd)
{
// LAB 6: Your code here.
int n;
char buf[BUFFSIZE];
while((n=read(fd,buf,(long)sizeof(buf)))>0){
if(write(req->sock,buf,n)!=n){
die("Failed to send file to client");
}
}
return n;
//panic("send_data not implemented");
}
static int
send_file(struct http_request *req)
{
int r;
off_t file_size = -1;
int fd;
// open the requested url for reading
// if the file does not exist, send a 404 error using send_error
// if the file is a directory, send a 404 error using send_error
// set file_size to the size of the file
// LAB 6: Your code here.
if ((fd = open(req->url, O_RDONLY)) < 0) {
send_error(req, 404);
goto end;
}
struct Stat stat;
fstat(fd, &stat);
if (stat.st_isdir) {
send_error(req, 404);
goto end;
}
//panic("send_file not implemented");
if ((r = send_header(req, 200)) < 0)
goto end;
if ((r = send_size(req, file_size)) < 0)
goto end;
if ((r = send_content_type(req)) < 0)
goto end;
if ((r = send_header_fin(req)) < 0)
goto end;
r = send_data(req, fd);
end:
close(fd);
return r;
}
至此all is over 。