设置GPU实现深度学习单卡、多卡 训练
任务背景:在使用YOLOv5的过程中,使用DDP模式时,对其相关操作记录如下
一、查看服务器显卡使用情况
nvidia-smi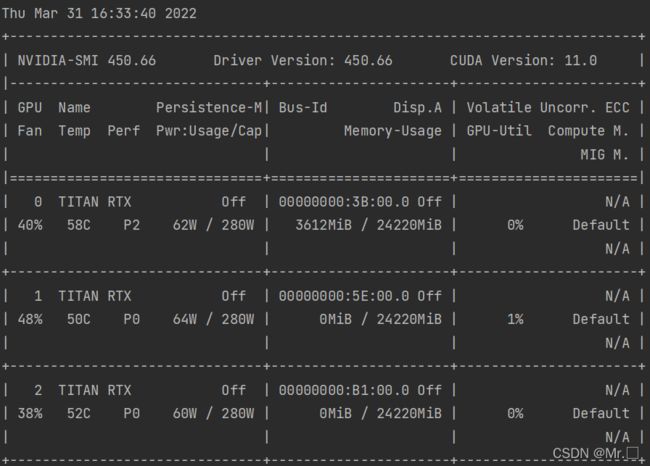
怎么看呢?具体参数含义如下:
- GPU:GPU 编号;
- Name:GPU 型号;
- Persistence-M:持续模式的状态。持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态;
- Fan:风扇转速,从0到100%之间变动;
- Temp:温度,单位是摄氏度;
- Perf:性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能(即 GPU 未工作时为P0,达到最大工作限度时为P12)。
- Pwr:Usage/Cap:能耗;
- Memory Usage:显存使用率;
- Bus-Id:涉及GPU总线的东西
- Disp.A:Display Active,表示GPU的显示是否初始化;
- Volatile GPU-Util:浮动的GPU利用率;
- Uncorr. ECC:Error Correcting Code,错误检查与纠正;
- Compute M:compute mode,计算模式
二、YOLOv5多GPU训练指令
我现在看到我的服务器空闲的GPU的编号有0,1,2,3,4,5,6
# device 设备选择
# parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
python train.py --device 0,1,2,3,4,5,6 --data coco128.yaml --weights yolov5s.pt --img 640 注意事项:
- 可以将 'cuda:0' to '0'
- 检查:batch_size 必须是GPU数量的整数倍(如果使用多块GPU)
三、YOLOv5具体如何实现的
可以查看他实现的函数:
train.py 692行
![]()
torch_utils.py 52行
def select_device(device='', batch_size=0, newline=True):
# 选择计算的设备cpu/gpu
# device = 'cpu' or '0' or '0,1,2,3'
s = '' # string
device = str(device).strip().lower().replace('cuda:', '') # to string, 'cuda:0' to '0'
cpu = device == 'cpu'
if cpu:
os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
elif device: # non-cpu device requested
os.environ['CUDA_VISIBLE_DEVICES'] = device
# set environment variable - must be before assert is_available()
assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', '')), \
f"Invalid CUDA '--device {device}' requested, use '--device cpu' or pass valid CUDA device(s)"
cuda = not cpu and torch.cuda.is_available()
if cuda:
devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
n = len(devices) # device count
if n > 1 and batch_size > 0: # 检查:batch_size 必须是GPU数量的整数倍(如果使用多块GPU)
assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
for i, d in enumerate(devices):
p = torch.cuda.get_device_properties(i)
s += f"CUDA:{d} ({p.name}, {p.total_memory / (1 << 20):.0f}MiB)\n" # bytes to MB
else:
s += 'CPU\n'
if not newline:
s = s.rstrip()
# 打印device选用情况
LOGGER.info(s.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else s) # emoji-safe
return torch.device('cuda:0' if cuda else 'cpu')