目录
一、模型构建器概览
二、模型构建器界面
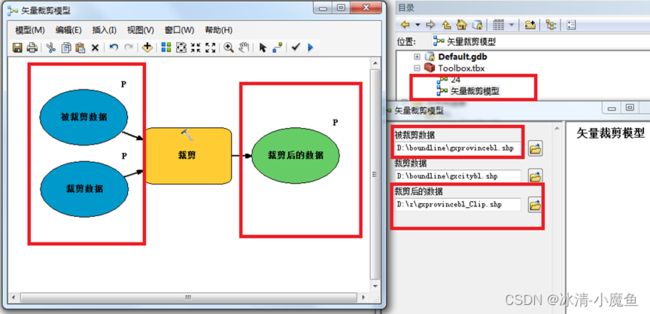
三、为同一个文件夹下的所有影像数据制作一个生成影像金字塔的地理处理模型工具
四、模型各组成部分
五、模型处理控制流
六、复杂地理处理模型嵌套
附件:空间图形对象
一、模型构建器概览
模型构建器molder builder是一款地理信息的图形化编程语言或者建模工具,是esri针对argis地理处理框架提供的一个图形化界面建模工具。模型构建器用于构造地理处理模型,将一系列地理处理工具串联成工作流,无需使用代码块,就可完成一系列的地理处理过程。当然,模型构建器的计算数值模块提供了个性函数定义功能,以代码方式插入,类似于地理数据属性表里的字段计算器。

注:地理处理建模是地理数据处理的一种常用手段之一,大多数地理数据处理流程都是面向工程的,以结果为导向的工作流模式是一整套复杂的流水线,前一个生产步骤往往是后一个生产步骤的先导,工序衔接严密,如:大气辐射校正、正射影像生产、SWAT综合水文模型、生态环境指数计算与评估、区域雷灾模型评估、农业生产适宜性评价等。在地理信息处理软件中,arcgis model builder,envi modeler,erdas model maker等都提供了模型构建器,而像易康、IDRISI、INPHO、DPRID等这样的软件,其软件本身就是一个模型构建器。
arcgis模型构建器可以通过arcmap、arccatlog上方工具栏的模型编辑器图标打开。

二、模型构建器界面
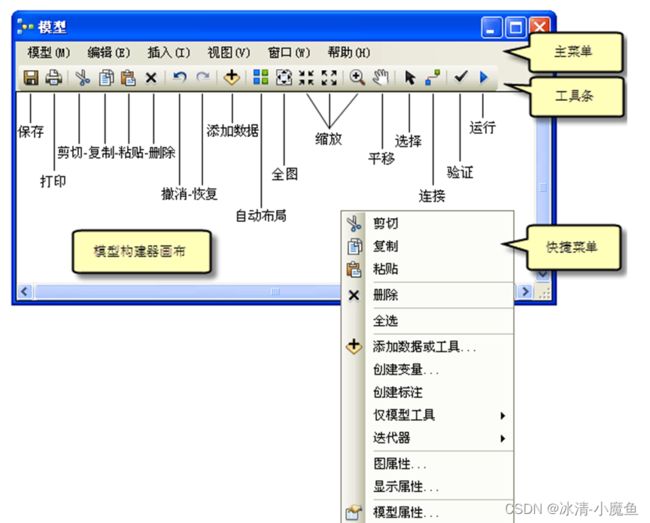
模型编辑器菜单
| 菜单 |
描述 |
| 模型 |
包含运行、验证、查看消息、保存、打印、输入、输出和关闭模型这些选项。还可以使用此菜单删除中间数据和设置模型属性。 |
| 编辑 |
剪切、复制、粘贴、删除和选择模型元素。 |
| 插入 |
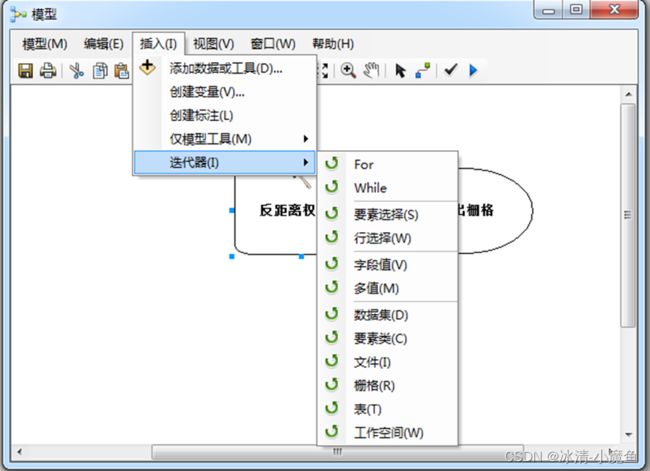
添加数据或工具、创建变量、创建标注及添加“仅模型”工具和迭代器。 |
| 视图 |
包含“自动布局”选项,此选项可将图属性 对话框中指定的设置应用于模型。另外还包含缩放选项。通过“自定义缩放”选项可以自定义缩放百分比。可使用“视图”菜单上的预设缩放级别(25%、50%、75%、100%、200% 和 400%)缩放到实际大小的各个固定百分比。 |
| 窗口 |
包含的总览窗口可显示您在显示窗口中放大某部分模型时整个模型的外观。您在模型窗口的当前位置将在总览 窗口中以矩形标记。 |
| 帮助 |
访问 ArcGIS for Desktop 在线帮助系统和“关于模型构建器”对话框。 |
三、为同一个文件夹下的所有影像数据制作一个生成影像金字塔的地理处理模型工具
思路:
栅格数据存放在D:\x文件夹下,思路:循环迭代文件夹中的每一个影像,调用构建金字塔工具为每一个影像创建金字塔数据,并完善金字塔模型工具。

模型构建器效果如下:
构建金字塔模型
点击arcmap工具栏的模型构建器图标,打开模型构建器界面

在工具箱找到数据管理工具---栅格--栅格属性--构建金字塔工具,将构建金字塔工具拖入模型构建器。(栅格属性工具箱提供了一个批量建立金字塔的工具,也可以使用该工具箱)

在D:\x文件夹下,包含有几个影像数据,需要全部建立金字塔。点击插入菜单项,找到迭代器--栅格工具,点击将栅格迭代工具加入模型构建器。

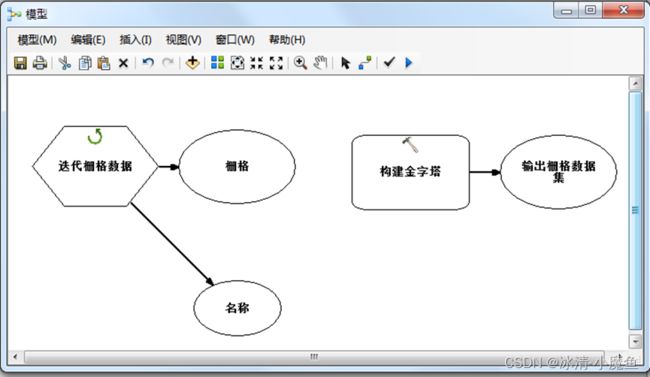
点击模型连接符,将迭代栅格器的输出数据与构建金字塔工具连接起来,在构建金字塔工具集上方选择输入栅格集。

右键点击迭代栅格数据工具,选择打开菜单,在迭代栅格数据界面的工作空间或者栅格目录选择器上进入D:\x文件夹目录。


选择迭代栅格数据界面的确定按钮,模型构造器变成彩色。

点击模型构造器有右上角的黑色√,验证模型是否有效,模型有效后,点击√右侧的运行按钮,创建影像金字塔。创建影像金字塔,保存金字塔模型,金字塔模型在目录的toolbox中可以找到。

设计金字塔模型工具
从工具箱重新打开影像金字塔模型,发现没有输入项。

右击影像金字塔模型,选择编辑,再次在模型编辑器中打开影像金字塔模型。

右键蓝色椭圆数据框x,选择模型参数,蓝色椭圆数据框x右上方出现P字母,表示已选定为模型参数,点击左上角保存按钮保存创建金字塔工具箱。


再次从工具箱打开创建金字塔模型工具箱,已出现输入参数选项按钮。

该对话框输入不够灵活,还留有D:\x字符串,再次编辑创建金字塔模型,选择蓝色椭圆数据框x右键打开菜单,将D:\x删除,点击确定,并再次保存创建金字塔模型。
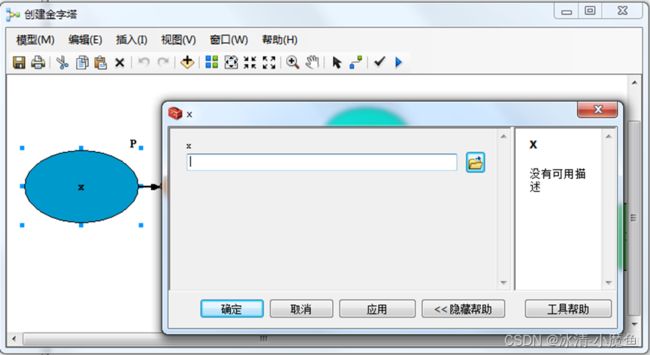
从目录工具箱再次打开创建金字塔模型,D:\x已经去掉。
该创建金字塔模型缺乏描述信息,需要增加一些描述性信息,右键金字塔模型,选择项目描述,进入项目描述界面。
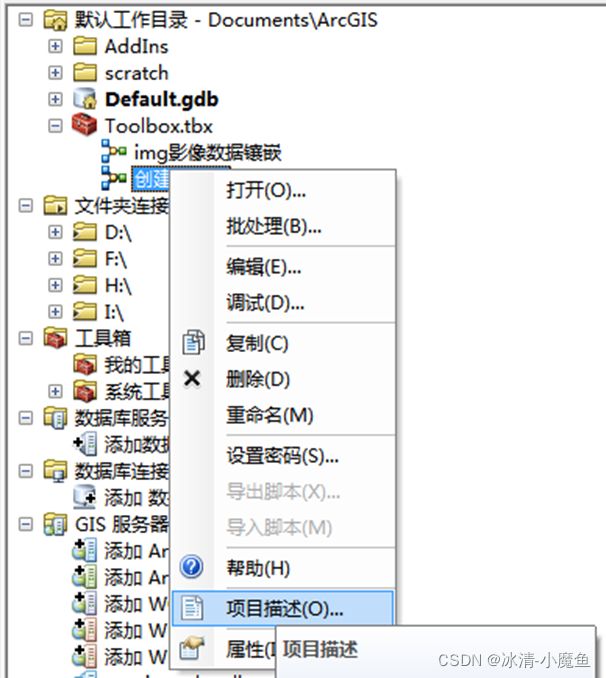
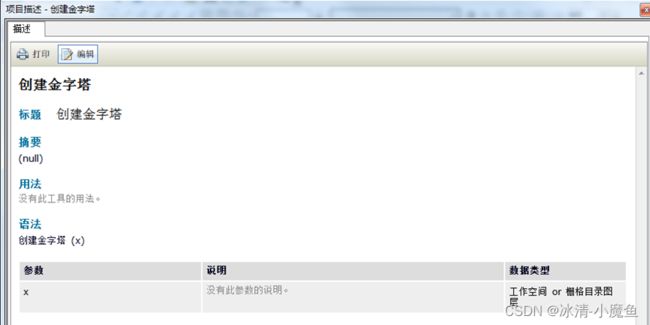
点击编辑界面对相关数据进行描述,保存退出。
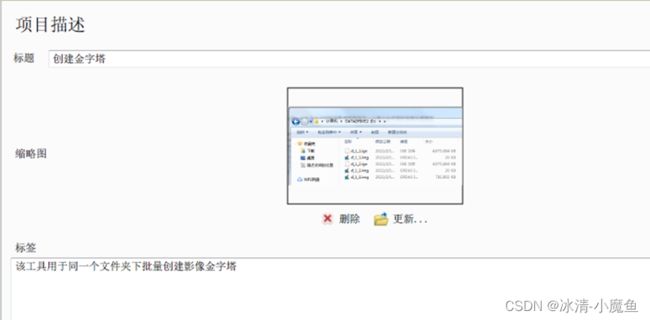
打开创建模型金字塔工具,界面如下:
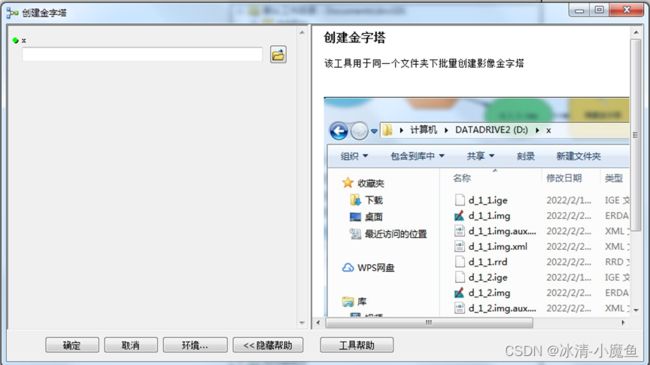
该界面对话框描述X不能表达输入文件夹的含义,进入模型编辑器界面,右击x数据框,重命名为请输入文件夹。


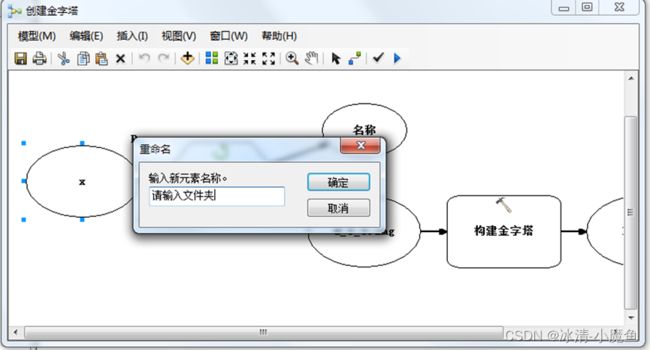
确定,保存退出,再次打开创建金字塔模型。

最后以编辑模式进入创建金字塔模型,选择模型菜单,导出至python脚本。


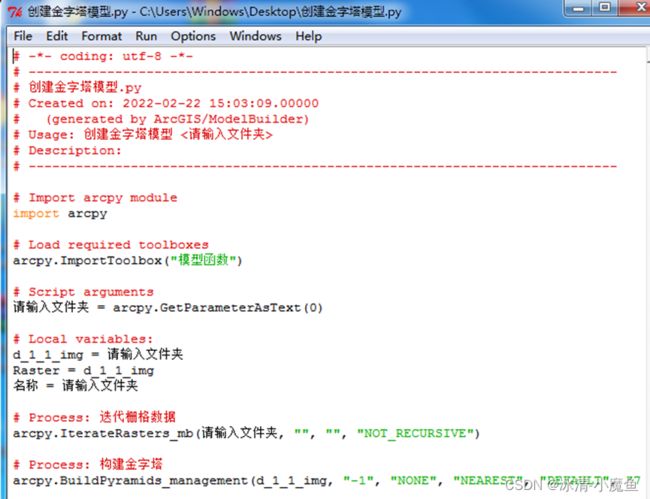
脚本代码如下:
# -*- coding: utf-8 -*-
# ---------------------------------------------------------------------------
# 创建金字塔模型.py
# (generated by ArcGIS/ModelBuilder)
# Usage: 创建金字塔模型 <请输入文件夹>
# Description:
# ---------------------------------------------------------------------------
# Import arcpy module
import arcpy
# Load required toolboxes
arcpy.ImportToolbox("模型函数")
# Script arguments
请输入文件夹 = arcpy.GetParameterAsText(0)
# Local variables:
d_1_1_img = 请输入文件夹
Raster = d_1_1_img
名称 = 请输入文件夹
# Process: 迭代栅格数据
arcpy.IterateRasters_mb(请输入文件夹, "", "", "NOT_RECURSIVE")
# Process: 构建金字塔
arcpy.BuildPyramids_management(d_1_1_img, "-1", "NONE", "NEAREST", "DEFAULT", "75", "OVERWRITE")
也可以将这段代码插入该数据模型的项目描述中去,或者使用一个制作脚本的工具插入的脚本工具中。注:需要将其中的中文去掉,并用相应的变量替换。

python脚本与python脚本工具数据传递:
Str0=arcpy.GetParameterAsText(0)
Str1=arcpy.GetParameterAsText(1)
Str2=arcpy.GetParameterAsText(2)
。。。。。。。。。。。。。。。。。。。
再将Str0、Str1、Str2。。。。传入至相应的arcpy函数中。
四、模型各组成部分
地理处理模型结构由地理处理模型、地理处理模型工具两部分组成。其中,模型构建器用于构建地理处理模型,地理处理模型工具用于向用户提供提供界面的数据输入、输入功能。地理处理模型由一系列的地理处理工具、数据、连接符和工程控制流等元素组成。在模型构造器中,蓝色椭圆表示数据,黄色矩形表示地理处理工具或脚本,黑色连接符表示数据或地理处理工具之间的流向。模型参数是连接地理处理模型与地理处理模型工具的桥梁。


注:地理处理工具、控制流内容较多,其中地理处理工具不能一一列出,控制流是模型地理处理的关键,会单独开辟章节讲述。
模型参数:模型参数是数据在地理处理模型可视化界面前端的体现,当把输入、输出参数指定为模型参数后,即可在模型可视化界面确定输入、输出的数据和变量参数。
模型工具:地理处理或脚本工具是模型地理处理的基本组成部分,用于对地理数据执行多种操作。地理处理或脚本工具被添加到模型中后,便成为了模型工具单元的一部分。模型构造器也提供了地理处理或脚本工具不能完成的处理工具,比如迭代器、收集合并、分支合并、语义表达等处理工具。

模型数据:模型数据是指各类空间数据或者非空间数据类型,它与数据变量有着非常紧密的联系,因空间数据类型复杂多样,这也是使用地理处理模型理解的一个难点。按照模型地理处理流向,数据分为输入数据、中间数据、输出数据和数据变量等。

输入数据:输入数据是从磁盘中输入的空间数据、非空间数据或独立变量数据。
输出数据:输出数据是输出到磁盘或者内存中的数据。
中间数据:中间数据是指前一个工具输出的数据,是下一个工具输入的数据。中间数据既是输入数据,也是输出数据。中间数据包含托管数据、内存数据和数据变量等。
托管数据:托管数据位于模型数据库中,属于模型运行进程中的中间数据。将某一变量设置为托管形式后,无法在模型构建器中更改中间数据的输出路径(参数控件将始终处于不可用状态)。右键椭圆数据框勾选数据托管后,即可将中间数据设置为托管数据。
内存数据:内存数据是模型进程单独为中间数据开辟一段内存空间,用于存放中间数据,以方便后续模型流程调用,类似于在ENVI中将中间数据放入内存管理。内存数据引用方式为in_memory/,关键字为in_memory,内存数据虽然可以加速数据的访问速度,但是空间数据体量大,一般个人电脑的内存配置也不过8G到16G而已,当内存被装入的数据量过大时,反而适得其反。
模型变量: 模型变量是地理处理模型中用于保存数据或或对数据进行引用的数据变量。
地理数据有很多复合的数据类型,模型变量也对应着很多种的数据变量,比如:数值、字符串、文件夹、数据库、矢量要素类、矢量数据集、属性表、字段、SQL表达式、属性记录、像元、栅格类、栅格数据集、栅格表达式、镶嵌数据集、空间参考、几何体、几何拓扑、几何网络、数据服务等。在地理数据中,几乎任何可以看做是地理对象的数据都可以是模型变量。模型变量引用方式为%var%,其中变量名称为var,用百分号 (%) 括起。
模型变量区分为独立变量、迭代变量和系统变量等。
独立变量:在模型构建器中,选择插入菜单的创建变量选项可以创建独立变量。独立变量使用比较多的场景是,在数据输入或输出中,使用双百分号 (%) 将独立变量括起来,用变量值进行替换当前数值,这种变量替换方式称为行内变量替换。

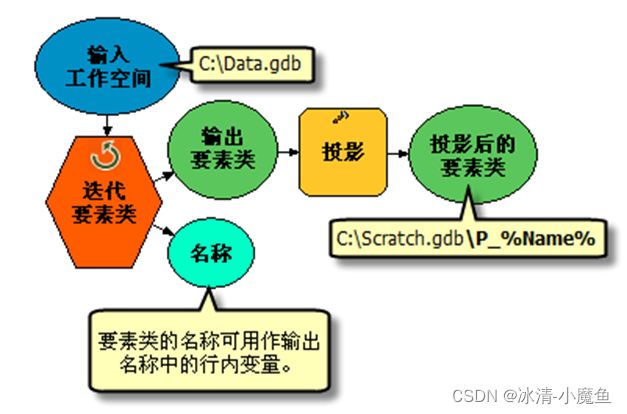
如:工作空间变量Data Workspace的值为 C:\Data.gdb。通过将此变量名称用百分号括起,此工作空间位置将被替换为 Project 工具参数中的行内变量。运行时,将使用实际变量值 C:\Data.gdb 替换 %Data Workspace%。

迭代变量:迭代变量是行内变量的一种特殊表现形式,用于表示可以循环迭代的数据,可以是同一个文件夹下的所有文件,同一个数据库的所有要素类,同一个数据集中的所有数据,同一个属性表中的所有记录等。如:迭代要素类将为要素类的路径和名称各创建一个输出变量。可以使用名称变量中的值构造投影的要素类的路径。工具执行时,%Name% 将被替换为要素类的名称。
系统变量:模型构建器提供了两个在迭代工作流中使用的系统变量。这两个系统变量包含当前迭代次数和当前列表索引:%i% 是指列表变量中的当前列表位置(第一个位置为零),而 %n% 是指当前模型迭代(第一个迭代为零)。
(1)将 %i% 系统变量与行内变量替换结合使用
对于针对输入列表运行进程的模型,每次运行进程时,输出的名称都会与上一次运行进程所得到的输出的名称相同,且上一次输出将会被覆盖。为避免在连续迭代过程中覆盖上一次的输出,可使用 %i% 追加输出的名称,从而为每个输出提供指示其在输入列表中的位置的唯一名称。

- 将 %n% 系统变量与行内变量替换结合使用
%n% 提供当前模型的迭代次数,可在迭代模型中使用。在下例中,使用 For 迭代器对模型迭代四次。缓冲区工具的输出被用作输入反馈到此工具。模型进行迭代,并在每次迭代时创建新的输出。%n% 用于缓冲区工具的输出名称中,以便为每次迭代时的输出提供新名称。

模型连接符: 连接符用于将数据、变量与工具一起连接起来,表示地理处理的执行方向。地理处理模型构造好后,提供可视化界面供用户使用。

下图显示了在模型构建器中模型元素的分类情况:
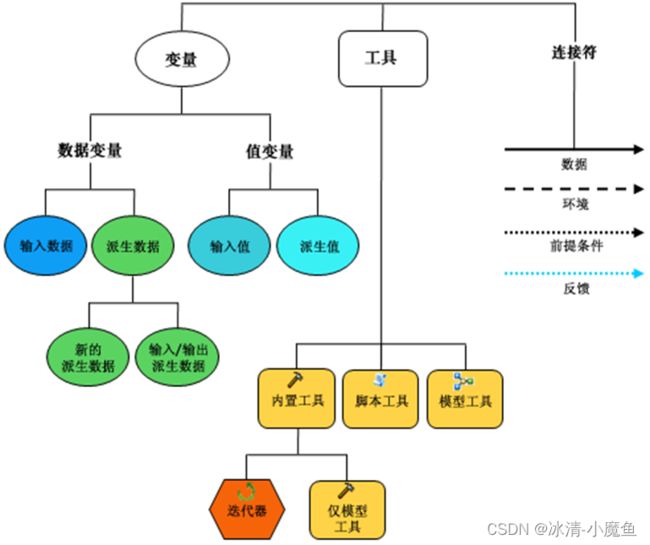
模型各组成部分描述

五、模型处理控制流
地理处理控制流用于控制地理处理流程执行方向,构造一个地理处理模型的关键点,在于如何理清数据处理前后的关系,将地理处理工具、数据和连接符有效地贯穿起来,环环紧扣地完成工作流程,在建立地理处理模型前,思考或画出一个整体的地理处理流程会更加有效地帮助地理处理模型的建立。地理处理控制流包含了顺序执行、循环迭代、分支选择、语义表达等,分支选择还包含了分支合并、收集合并、选择数据等。

顺序流
地理处理始终是以结果为导向的,地理处理控制流从数据输入、数据处理到数据输出从左到右依次顺序执行。

循环迭代流
循环迭代流包含for、while循环,工作空间、文件、数据集、要素、表、栅格数据等多种迭代方式,用于遍历工作空间、文件夹、矢量要素、矢量要素属性表、矢量要素记录、栅格、栅格数据集等。循环迭代器使用范围广,灵活多变,每种迭代器都有一组不同于其他迭代器的参数,但是所有迭代器工具的整体结构都非常相似。

数据迭代输入类型
| 迭代器 |
描述 |
| For 循环 |
按照给定的增量从起始值迭代至终止值。其工作原理与任何脚本/编程语言中 For 循环 的工作原理完全相同,即从头到尾执行固定数量的项目。 |
| While 循环 |
与任何脚本/编程语言中“while”的作用完全相同,当相应输入或一组输入的条件为 true 或 false 时继续执行 While 循环。 |
| 迭代要素选择 |
迭代要素类中的要素。 |
| 迭代行选择 |
迭代表中的所有行。 |
| 迭代字段值 |
迭代字段中的所有值。 |
| 迭代多值 |
迭代值列表。 |
| 迭代数据集 |
迭代工作空间或要素数据集中的所有数据集。 |
| 迭代要素类 |
迭代工作空间或要素数据集中的所有要素类。 |
| 迭代文件 |
迭代文件夹中的文件。 |
| 迭代栅格数据 |
迭代工作空间或栅格数据目录中的所有栅格数据。 |
| 迭代表 |
迭代工作空间中的所有表文件。 |
| 迭代工作空间 |
可迭代文件夹中的所有工作空间。 |
For 迭代器:For 迭代器用来迭代数值。如下图通过对缓冲区距离的值进行迭代,迭代从 500 到 4000 的值,增量值为 500,初次迭代时,值为 500,然后为 1000、1500,依次输出缓冲区处理增量范围。汇总统计数据工具可用来计算所有面的总面积,而获取字段值可用来获取汇总统计数据表中的值。如果总面积值超过 40,则计算值可求得布尔型 true。如果计算值中设置的条件为真,则停止工具被设置为停止模型执行。该模型迭代每个值,在本例中当执行第四次迭代时,所有面的总面积超过 40,使条件为真,停止工具在此时可退出该模型。

栅格迭代器:栅格迭代器对数据库或文件夹的栅格数据进行迭代。如:迭代同一个文件夹下的所有栅格数据,并对数据格式为GRID格式的每一个栅格数据进行重采样,按照原始栅格数据名称变量将重采样的栅格数据输出至指定文件夹。
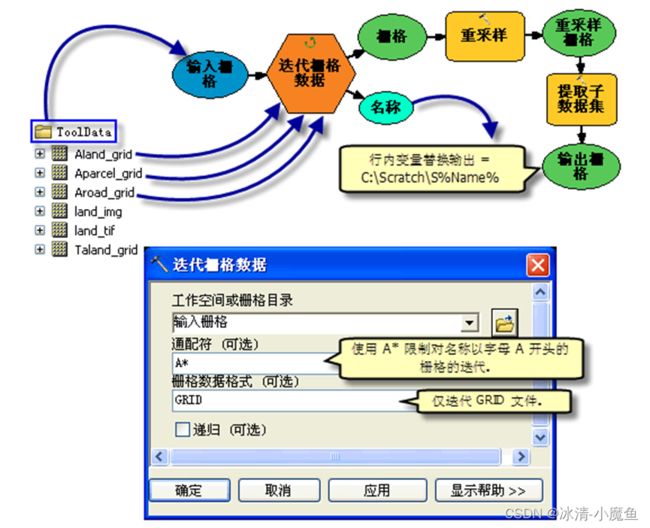
数据集迭代器:数据集迭代器用于对地理数据库的数据进行迭代。如:迭代矢量数据集,并对要素类型为面要素的矢量要素添加字段,计算字段数值后输出到指定要素集中。

选择分支流
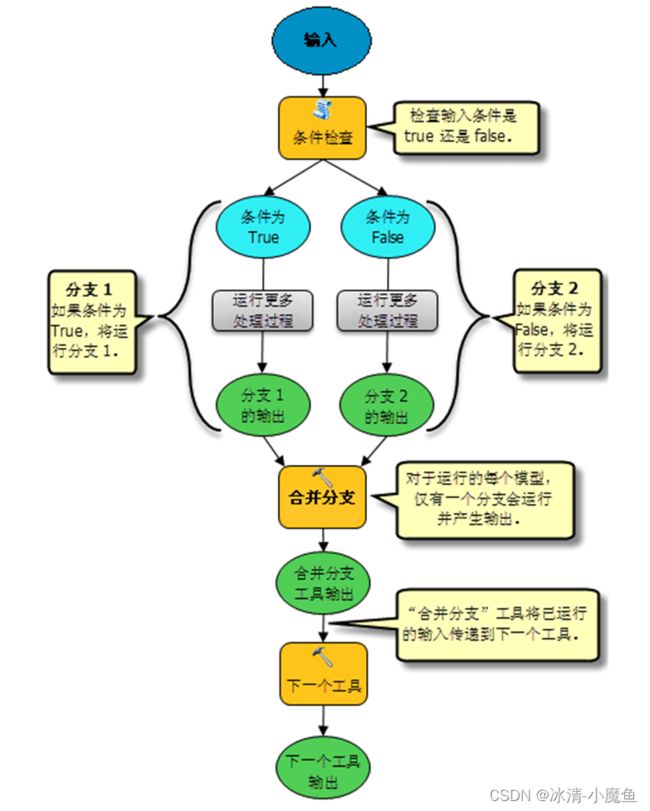
合并分支工具可将两个或多个逻辑分支合并为单个输出。要实现在模型中创建分支,可创建一个执行必要的 if-then-else 逻辑的脚本工具。创建分支后,通常可能需要将两个分支合并到单个进程中。这意味着,如果您要检验输入数据是否符合某项条件(例如:数据是否位于磁盘上,像元大小是否超过 30 米,字段值是否为 1),将会产生两种输出结果:真(如果条件为真)和假(如果条件为假)。如下所示,如果条件为真,可运行某些进程,而如果条件为假,则可运行其他一些不同的进程。无论属于哪种情况,都只会运行其中一个分支,具体运行哪个分支取决于判断条件和输入数据。如果无法判断运行哪个分支,可使用合并分支工具。两个分支的输出均将用作合并分支工具的输入。该工具将检查这两个输入,然后将第一个完成运行的分支输出传递给下一个工具。合并分支工具接受任意数量的输入,并可采用多值参数控制。
分支合并流
分支合并流可以在父数据元素(如文件夹、地理数据库、要素数据集或 coverage)中选择需要的数据,进行合并,是选择分支流的特殊形式。如下将两个 shapefile 复制到地理数据库并将其中一个要素类与其他要素类合并,选择数据工具可用于选择地理数据库中的一个或两个要素类,并将其传递给合并工具。

收集合并流
收集合并流定义了一些空间数据收集的过程,专用于收集迭代器的输出值或将一组多值转换为一个输入,也是选择分支流的特殊形式。收集值的输出可用作合并、追加、镶嵌和像元统计等工具的输入。
如下面将同一个文件夹下的所有栅格数据进行迭代,而后收集所有栅格数据的路径将它们传至镶嵌至新栅格处理工具,完成多个相邻栅格数据的拼接镶嵌。

语义表达流
语义表达通过计算值工具实现,计算值工具提供类似字段计算器一样的界面,通过定义局部函数,插入代码块,完成属性表或者数值的转换。

六、复杂地理处理模型嵌套
部分地理处理过程过于复杂,将复杂的地理处理过程拆分为多个小模型单位,是一件有意义的事情,也有利于对大型地理处理过程分而治之。在arcgis中,模型工具已集成到地理处理框架中,创建的模型可以以嵌套的方式放入大型模型中使用。特别是对于循环迭代工具而言,单个的迭代模型只能在模型中只能使用一次,其他迭代器就不能使用了,此时将单个循环迭代模型作为嵌套的子模型放入大型模型中去,便可使用其他迭代器工具了。
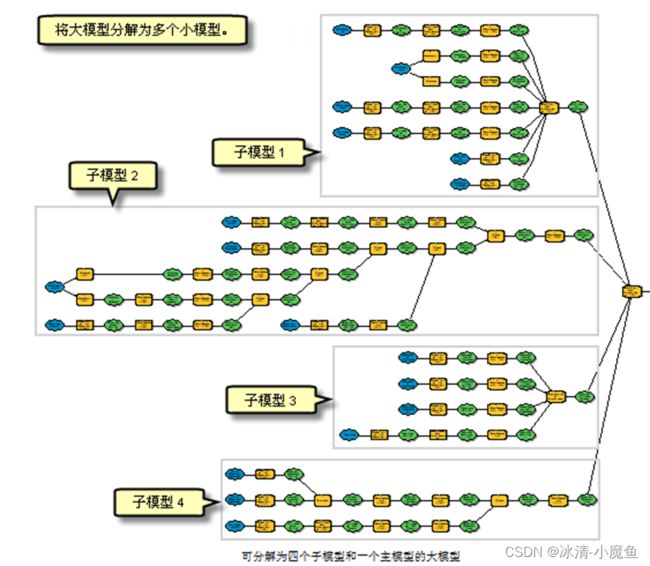
1、创建两个模型:主模型和子模型,其中子模型嵌套在主模型中。向主模型添加 Merge 工具,向子模型添加 Iterate Feature Classes 迭代器和 Collect Values 工具。
2、在子模型中,设置包含要以 Iterate Feature Classes 迭代器的输入形式进行合并的要素类的工作空间。如果仅迭代点要素类,请将 Iterate Feature Classes 的要素类型参数设置为 POINT。

3、将 Iterate Feature Classes 的输出变量 Output Feature Class 连接到 Collect Values 工具,以便迭代和收集工作空间中各点要素类的路径。
4、将输入工作空间变量和 Collect Values 工具的输出变为模型参数。将输入工作空间变量重命名为 Input Dataset 以确保该变量名称是相关名称且易于理解。
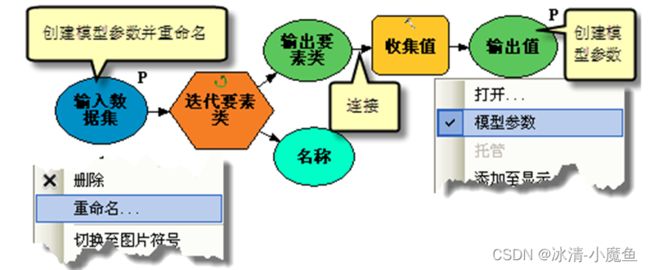
5、保存并关闭子模型,然后将其作为过程添加到主模型。将子模型添加到主模型时,子模型的参数会自动作为主模型中的变量进行添加。

6、将子模型的输出变量设置为 Merge 工具的输入数据集。确保 Merge 工具的输出路径为有效路径。
7、将子模型的输入变量重命名为 Input Dataset,并将 Merge 工具的输出变量重命名为 Merge Output。将 Input Dataset 变量和 Merge Output 变量设置为模型参数。

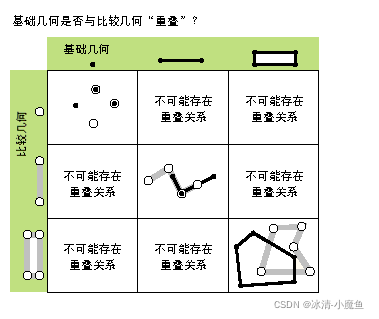
附件:空间图形对象
空间数据需要同时维护属性表数据与图形数据信息,图形数据和属性数据之间通过唯一的ID号进行对象内部关联,涉及到空间数据更新时,一般是同时更新空间对象的属性数据和图形数据。空间图形对象定义了空间图形的空间位置、形状,空间图形包含点、多点、线、面、多面体等多种空间图形对象,空间图形对象是空间拓扑、空间分析、空间几何网络构造的基础,在创建空间几何对象的时候,空间边界、最小边界多边形、包含、相交、接触、相离、合并等空间关系等对象或者方法得以继承,可以直接使用空间图形对象更新图形信息,又因Arcpy调用了arcobject空间对象的方法,也可以使用图形令牌访问图形信息,同时也可以使用游标方式对属性数据和图形数据进行同步更新。如果只需要图形的某些特定属性,利用图形令牌访问几何属性即可,操作比图形对象访问更加简便,例如:SHAPE@XY 会返回一组代表要素质心的 x,y 坐标。
| 令牌 |
说明 |
| SHAPE@ |
要素的 几何对象。 |
| SHAPE@XY |
一组要素的质心 x,y 坐标。 |
| SHAPE@TRUECENTROID |
一组要素的真正质心 x,y 坐标。 |
| SHAPE@X |
要素的双精度 x 坐标。 |
| SHAPE@Y |
要素的双精度 y 坐标。 |
| SHAPE@Z |
要素的双精度 z 坐标。 |
| SHAPE@M |
要素的双精度 m 值。 |
| SHAPE@JSON |
表示几何的 esri JSON 字符串。 |
| SHAPE@WKB |
OGC 几何的熟知二进制 (WKB) 制图表达。该存储类型将几何值表示为不间断的字节流形式。 |
| SHAPE@WKT |
OGC 几何的熟知文本 (WKT) 制图表达。其将几何值表示为文本字符串。 |
| SHAPE@AREA |
要素的双精度面积。 |
| SHAPE@LENGTH |
要素的双精度长度。 |
空间图形对象方法
| 方法 |
说明 |
| boundary () 计算图形边界 |
构造几何边界。
|
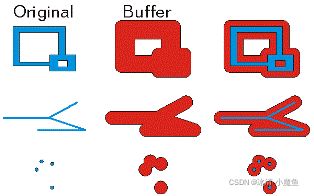
| buffer (distance) 计算指定距离的图形缓冲区 |
计算指定距离的图形缓冲区
|
| clip (envelope) 图形裁剪 |
构造几何体与指定范围的交集。
|
| contains (second_geometry) 判断两个图形之间的包含关系 |
判断两个图形之间的包含关系,本图仅显示 True 关系。
|
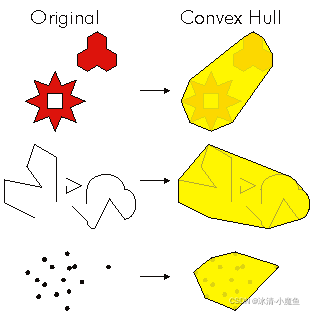
| convexHull () 计算图形凸包 |
构造具有最小边界多边形的凸包。
|
| crosses (second_geometry) 判断两个图形是否相交 |
判断两个图形是否相交,本图仅显示 True 关系。
|
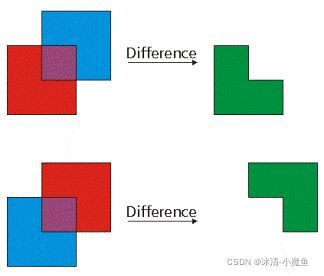
| difference (other) 计算两个图形不同的部分 |
计算两个图形不同的部分。
|
| disjoint (second_geometry) 判断两个图形是否不相交 |
判断两个图形是否不相交,本图仅显示 True 关系。
|
| distanceTo (other) 计算两个图形的距离 |
返回两个几何之间的最小距离。如果两个几何相交,则最小距离为 0。 两个几何必须具有相同的投影。 |
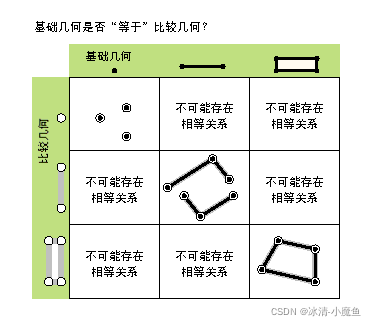
| equals (second_geometry) 判断两个图形是否相同 |
判断两个图形是否相同,本图仅显示 True 关系。
|
| getArea (type) 计算图形面积 |
使用测量类型返回要素的面积。 |
| getLength (measurement_type) 计算图形长度 |
使用测量类型返回要素的长度。 |
| getPart ({index})根据索引获取多部件要素的单个图形 |
根据索引获取多部件要素的单个图形 |
| intersect (other, dimension) 计算两个图形相交部分 |
构造作为两个输入几何交集的几何体。不同的维数可用于创建不同的 shape 类型。 对于同一 shape 类型的两个几何体,其交集为仅包含原始几何重叠区域的几何。
为了更快地获取结果,请在调用 intersect 类之前先测试两个几何体是否不相交。 |
| overlaps (second_geometry)判断两个图形是否重叠 |
判断两个图形是否重叠,本图仅显示 True 关系。
|
| positionAlongLine (value, {use_percentage}) 计算点到线段或者弧段的距离 |
计算点到线段或者弧段的距离。 |
| projectAs (spatial_reference, {transformation_name}) 设置投影参数 |
定义几何投影,并应用相应的地理变换。 要进行投影,几何体需要具有一个空间参考且不具有 UnknownCoordinateSystem。传递到该方法的新空间参考系统参数定义了一个输出坐标系。如果任一空间参考未知,坐标将不会发生更改。ProjectAs 方法并不更改 Z 值和测量值。 |
| symmetricDifference (other) 计算两个图形不相交以外的图形 |
构造一个几何体,该几何体由两个几何的并集减去其交集所形成。 两个输入几何必须为同一 shape 类型。
|
| touches (second_geometry)判断两个图形是否接触 |
判断两个图形是否接触,本图仅显示 True 关系。
|
| union (other) 合并两个图形 |
构造一个几何体,该几何体是输入几何的并集。 要合并的两个几何必须为同一 shape 类型。
|
| within (second_geometry) 判断一个图形是否在另外一个图形内部 |
|










使用几何对象
import arcpy
feature_info = [[[1, 2], [2, 4], [3, 7]],
[[6, 8], [5, 7], [7, 2], [9, 5]]]
features = []
for feature in feature_info:
features.append(
arcpy.Polygon(
arcpy.Array([arcpy.Point(*coords) for coords in feature])))
arcpy.CopyFeatures_management(features, "c:/geometry/polygons.shp")
使用图形令牌
import arcpy
feature_class = "c:/data/Hawaii.shp"cursor = arcpy.da.SearchCursor(feature_class, ["SHAPE@"])
for row in cursor:
print("Number of Hawaiian islands: {0}".format(row[0].partCount))
for island in row[0].getPart():
print("Vertices in island: {0}".format(island.count))
for point in island:
print("X: {0}, Y: {1})".format(point.X, point.Y))
几何数据、属性数据一起插入
import arcpy
row_values = [('Anderson', (1409934.4442000017, 1076766.8192000017)),
('Andrews', (752000.2489000037, 1128929.8114))]
cursor = arcpy.da.InsertCursor("C:/data/texas.gdb/counties",
("NAME", "SHAPE@XY"))
for row in row_values:
cursor.insertRow(row)
del cursor