Redis系列之常见数据类型应用场景
文章目录
- String
-
- 简单介绍
- 常见命令
- 应用场景
- Hash
-
- 简单介绍
- 常见命令
- 应用场景
- List
-
- 简单介绍
- 常见命令
- 应用场景
- Set
-
- 简单介绍
- 常见命令
- 应用场景
- Sorted Set(Zset)
-
- 简单介绍
- 常见命令
- 应用场景
- Bitmap
-
- 简单介绍
- 常见命令
- 应用场景
- 附录
Redis支持多种数据类型,比如String、hash、list、Set、SortedSet、Streams、Bitmap、Hyperloglog、Geo(物理位置)等等,在 官网也给出了说明,本博客就挑一些比较常有的数据类型说说,本文例子基于Redisson实现
String
简单介绍
在Redis中,所有的数据都是key-value的数据结构存储的,那么在Redis中这个string类型的value值只能存储String类型的数据?其实不然,redis中string类型的value值是可以支持多种类型的,比如String、Number、Float、Bits等等,但是最大还是只能存储512M。Redis中key也是string类型存储的,所以最大也只能存储512M
常见命令
set、get命令就不演示了,下面给出一些常有命令
批量设置多个key
mset tkey1 tvalue tkey2 111
批量获取多个key值
mget tkey1 tkey2
获取长度
strlen tkey
字符串后面追加内容
append tkey tstring
获取指定范围的字符
# 取0~3之间的字符,返回1tst
getrange tkey 0 3
key进行递增(整数)
# 返回1
incr ikey
# 递增指定大小的值,返回124
incrby ikey 124
key进行递增(浮点数)
# 设置初始浮点数值
set fkey 1.2
# 在原来基础上递增2.4,返回3.6
incryfloat fkey 2.4
加上key过期时间
expire tkey 10
分布式锁实现,set if not exists,可以使用setnx单个命令,也可以使用set结合nx命令来实现
# set tkey过期时间10秒,nx:如果键不存在时设置
set tkey aaa ex 10 nx
# setnx命令,相当于set和nx命令一起用
setnx tkey aaa
EX : 设置指定的到期时间(以秒为单位)。
PX : 设置指定的到期时间(以毫秒为单
NX : 仅在键不存在时设置键。
XX : 只有在键已存在时才设置。
String 更多指令请参考官网文档:https://redis.io/commands/?group=string
应用场景
对于Redis String类型的应用场景也比较多,比如很常有的做缓存处理,也可以用于分布式锁、分布式ID
分布式锁的实现主要依赖于命令
setnx
分布式ID主要是利用
incr这个命令
基于Redis实现一个分布式ID生成器
package com.example.redis.common.handlers;
import com.baomidou.mybatisplus.core.incrementer.IdentifierGenerator;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
/**
*
* Redis分布式ID生成器
*
*
*
* 修改记录
* 修改后版本: 修改人: 修改日期: 2023/11/07 14:18 修改内容:
*
*/
@Component
public class RedisIdentifierGenerator implements IdentifierGenerator {
@Resource
private RedisTemplate redisTemplate;
@Override
public Number nextId(Object entity) {
String key = entity.getClass().getName();
return redisTemplate.opsForValue().increment(key);
}
}
Hash
简单介绍
Hash哈希,数据类型也是一种比较常见的数据结构,相对于Redis的string类型而言,其实就是多了一层key(field),所以说只要string类型适用的场景,hash都是支持的
常见命令
hash设置key为hkey,field为a的值
hset hkey a aaaa
获取hkey的field值
hget hkey a
设置多个field值
hmset hkey a 1 b 2 c 3 d 4
获取多个field值
hmget hkey a b c d
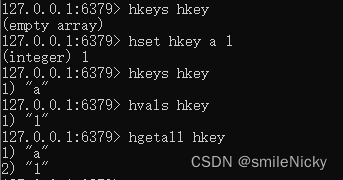
获取key所有的field
hkeys hkey
获取key所有field的值
hvals hkey
获取key所有fileld和值
hgetall hkey
给key某个字段field添加值
hincrby hkey a 10
![]()
对于Hash的更多命令,请参考:https://redis.io/commands/?group=hash
应用场景
对于hash的应用场景,其实只要redis string类型适用的,hash都是适用的,不过hash这种特殊的数据结构,还是适用于一些特殊场景的
- 存储一个对象类的数据,这个对象的多个字段就对应hash的field
- 存储一些统计类的数据,比如访问量、点击量等等
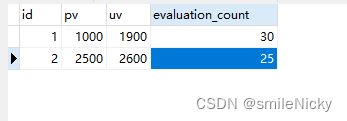
如图,如果要统计博客的pv、uv还有评论数量(evaluation_count),随着博客数量的增加存储到数据库里,后面肯定会查询比较慢,所以可以使用redis进行缓存
使用Redisson来写一个例子:
@Resource
private RedissonClient redissonClient;
@Test
void contextLoads() throws ExecutionException, InterruptedException {
RMap<Object, Object> redissonClientMap = redissonClient.getMap("recordMap");
Map<String,Integer> map = new HashMap<>();
map.put("pv" , 1000);
map.put("uv" , 1500);
map.put("evaluation_count",30)
redissonClientMap.putAll(map);
System.out.println(redissonClientMap.addAndGet("pv", 2));
}
List
简单介绍
redis中的数据类型存储有序的字符串列表,元素是可以重复,列表的最大长度为2^32-1个元素(4294967295),即每个列表超过40亿个元素
常见命令
左右添加元素
# 左边添加元素
lpush queueList a
lpush queueList b c
# 右边添加元素
rpush queueList d e
左右弹出第一条
# 左边弹出一个元素
lpop queueList
# 右边弹出一个元素
rpop queueList
左右弹出一个元素,并且设置超时,直到无数据弹出或者超时
blpop queueList 10
brpop queueList 10
应用场景
-
微信公众号、微博等消息流列表
RDeque<Object> recordList = redissonClient.getDeque("recordList"); recordList.addFirst("1.新闻1"); recordList.addFirst("2.新闻2"); recordList.addFirst("3.新闻3"); IntStream.range(0,3).forEach(a->{ System.out.println(recordList.poll()); }); -
消息队列,使用redis也可以实现消息队列,比如使用
rpush/lpop实现简单队列;blpop或者是brpop来实现阻塞读取队列;补充说明,同时stream、pub/sub(订阅发布模式)、sortedSet等等也是可以实现的不过还是不建议使用Redis来实现消息队列,因为我们已经有成熟的MQ框架,使用redis实现队列有可能有下面的问题:
- 存在内存,可能会有数据丢失,不能重复消费
- 消费后不能回应,没有ack确认机制
Set
简单介绍
Redis中的Set类型是无序集合,最大存储数量为2^32-1,大概有40亿左右,添加、删除元素的时间复杂度都是O(1)
常见命令
添加一个或者多个元素
sadd skey a b c d e f g h
获取所有的元素
smembers skey
获取集合元素的个数
scard skey
随机获取一个元素
srandmember skey
随机弹出一个元素
spop skey
弹出指定的元素
# 如果两个元素都有,返回2
srem skey a g
检查元素是否存在
# 元素存在返回1
sismember skey e
获取前一个集合有,而后面一个集合没有的元素
sdiff skey skey1
获取集合的交集
sinter skey skey1
获取集合的并集
sunion skey skey1
Set的更多命令请参考:https://redis.io/commands/?group=set
应用场景
-
抽奖程序,利用
spop跟standmember随机弹出元素RSet<String> recordSet = redissonClient.getSet("recordSet"); List<String> members = Lists.newArrayList("alice", "tim","tom" , "风清扬", "jack" ); recordSet.addAll(members); RFuture<Set<String>> threeSet = recordSet.removeRandomAsync(3 ); RFuture<Set<String>> twoSet = recordSet.removeRandomAsync(2 ); RFuture<Set<String>> oneSet = recordSet.removeRandomAsync(1 ); System.out.println("三等奖:"+threeSet.get()); System.out.println("二等奖:"+twoSet.get()); System.out.println("一等奖:"+oneSet.get()); -
集合交集(sinter)、并集(sunion)的场景,可以实现共同关注等场景
RSet<Object> tom = redissonClient.getSet("tom"); tom.addAll(Lists.newArrayList("令狐冲","james","风清扬")); RSet<Object> jack = redissonClient.getSet("jack"); jack.addAll(Lists.newArrayList("令狐冲","tim","jack")); System.out.println("共同关注的人:"+tom.readIntersectionAsync("jack").get()); -
sadd 集合存储,实现点赞、签到的业务场景
Sorted Set(Zset)
简单介绍
相对于set来说,sorted set是一种有序的set,排序是根据每个元素的score排序的,score相同时根据key的ASCII码排序

常见命令
批量添加元素
zadd z1 10 a 20 b 30 c 40 d 50 e 60 f 70 g 80 h 90 i
![]()
根据分数从低到高
zrange z1 0 -1 withscore
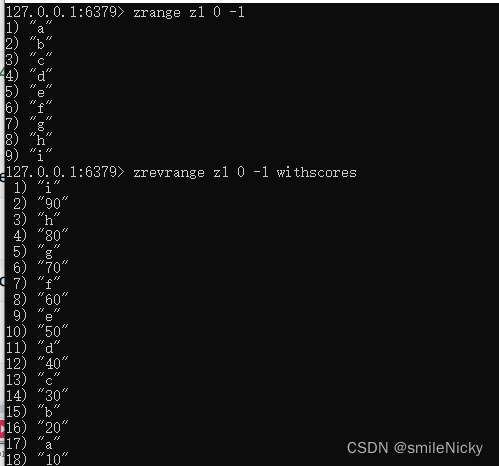
根据分数从高到低
zrevrange z1 0 -1 withscores
根据分数范围取值
zrangebyscore z1 20 30
移除元素
zrem z1 i
获取有序集合个数
zcard z1
给某个元素加分值
zincrby z1 20 a
获取范围内的个数
zcount z1 50 60
返回指定元素的索引值
# 假如d元素排在第4位,索引值就返回3
zrank z1 d
获取元素的分数
zscore z1 h
Sorted Set的更多命令请参考:https://redis.io/commands/?group=sorted_set
应用场景
-
排行榜
RScoredSortedSet<String> school = redissonClient.getScoredSortedSet("school"); school.add(60, "tom"); school.add(60, "jack"); school.add(60, "tim"); school.addScore("tom", 20); school.addScore("jack", 10); school.addScore("tim", 30); RFuture<Collection<ScoredEntry<String>>> collectionRFuture = school.entryRangeReversedAsync(0, -1); Iterator<ScoredEntry<String>> iterator = collectionRFuture.get().iterator(); System.out.println("成绩从高到低排序"); while(iterator.hasNext()) { ScoredEntry<String> next = iterator.next(); String value = next.getValue(); System.out.println(value); } RFuture<Collection<ScoredEntry<String>>> collectionRFuture1 = school.entryRangeReversedAsync(0, 2); Iterator<ScoredEntry<String>> iterator1 = collectionRFuture1.get().iterator(); System.out.println("成绩前三名"); while (iterator1.hasNext()) { System.out.println(iterator1.next().getValue()); }
Bitmap
简单介绍
位图不是实际的数据类型,而是String类型中定义的一种面向位的操作,所以这个位图的最大存储量也是512M。可以容纳最少2^32不同的位,可以在不同的位置设置0或者1
常见命令
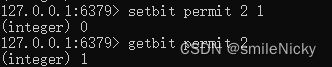
设置位的值
# 将位2设置为1
setbit permit 2 1
获取位的值
getbit permit 2
获取key的为1的个数
# 获取位为1的总数
bitcount permit
获取0或者1的第一位
# 获取key permit 位为1的第一个位置
bitpos permit 1
![]()
获取多个bitmap的位操作,比如& 、|
# 获取bkey和permit这两个的&运算,并且赋值给hbit
bitop AND hbit bkey permit
![]()
应用场景
-
实时的数据统计
比如:人员的考勤打卡记录,例如学生tom每次来上课就将相关的位记录位1
假如当月的第一天、第五天、第十天都来了
setbit tom 1 1
setbit tom 5 1
setbit tom 10 1
如何每月考勤,统计一下这个用户当月来了几天
bitcount tom
也可以应用于统计一个网站一天有多少用户访问,例如用户ID为123、124、125的用户访问了csdn
setbit csdn:2023-11-08 123 1
setbit csdn:2023-11-08 124 1
setbit csdn:2023-11-08 125 1
...
# 统计一下当天的访问次数
bitcount csdn:2023-11-08
- 存储用户权限,比如用1来表示有权限,0表示没权限,使用位图可以节省很大的存储空间
附录
Redis命令查询网站:https://redis.io/commands/