Hbase集群部署
文章目录
- Hbase要集群部署,可正常建表、插入数据和查询数据等
-
- 什么是HBase?
- 一、先下载Hbase安装包
-
- 1.1先改IP
- 1.2去官网下载所需要的版本
- 1.3将HBase的安装包上传到虚拟机后安装
- 二、修改HBase的配置文件
-
- 2.1修改hbase-env.sh文件
- 2.2修改hbase-site.xml文件
- 2.3修改/etc/profile
- 2.5将配置好了的HBase文件拷贝给slave1、slave2
- 三、启动
-
- 3.1启动zookeeper
- 3.2启动hdfs
- 3.3启动hbase
- 3.4查看hbase页面
- 四、HBase操作
-
- 4.1进入 HBase命令行
-
- 4.1.1查看帮助命令
- 4.1.2查看当前数据库有什么表
- 4.2创建表
- 4.3插入数据
- 4.4查看表数据
- 五、总结
Hbase要集群部署,可正常建表、插入数据和查询数据等
什么是HBase?
HBase是一个可以进行随机访问的存取和检索数据的存储平台,存储结构化和半结构化的数据,因此一般的网站可以将网页内容和日志信息都存在 HBase 里。 它不要求数据有预定义的模式,允许动态和灵活的数据模型,也不限制存储数据的类型。HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用 HBASE 技 术可在廉价 PC Server 上搭建起大规模结构化存储集群。
一、先下载Hbase安装包
在下载hbase安装包之前先改IP地址,master、slave1、slave2三个IP地址都要改。
不懂自己电脑IP是多少的可以打开cmd输入Ipconfig命令进行查看。
1.1先改IP
在虚拟机里输入以下命令进入配置文件进行更改IP地址。
vi /etc/sysconfig/network-scripts/ifcfg-ens33

改完IP后需要重启一下网卡
systemctl restart network
重启成功后需要ping一下外网,看是否能用。
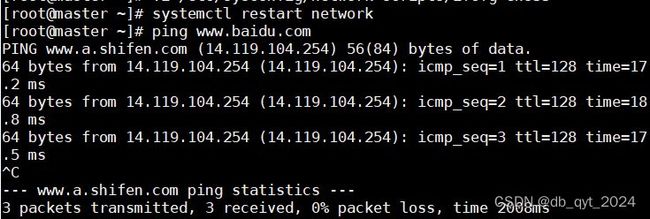
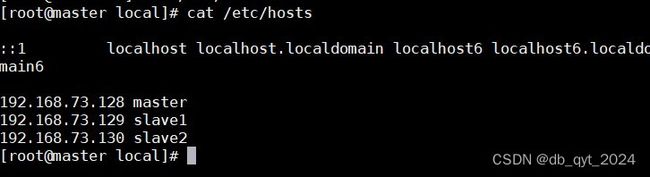
能成功使用后需要查看一下IP映射是否成功。
1.2去官网下载所需要的版本
我下载的版本是hbasehbase-1.4.8-bin.tar.gz
下载网址:
http://archive.apache.org/dist/hbase/?spm=a2c6h.12873639.article-detail.5.3e627a59LuyV5L
1.3将HBase的安装包上传到虚拟机后安装
在此之前先切换到/usr/local路径下
cd /usr/local
在此路径下解压安装包
tar -zxvf hbase-1.4.8-bin.tar.gz
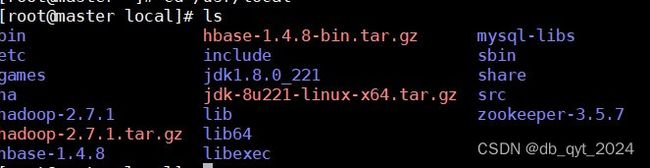
使用ll命令查看当前路径下是否有hbase这个安装包
二、修改HBase的配置文件
切换路径:cd /usr/local/hbase-1.4.8/conf/
2.1修改hbase-env.sh文件
先进入到hbase-env.sh文件里面添加配置
vi hbase-env.sh
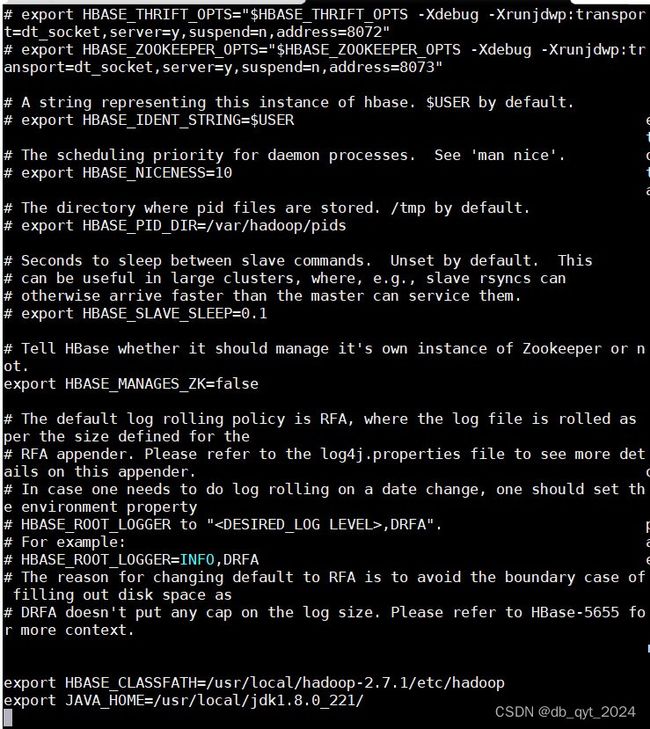
添加的环境配置代码:
export HBASE_CLASSFATH=/usr/local/hadoop-2.7.1/etc/hadoop
export JAVA_HOME=/usr/local/jdk1.8.0_221/
2.2修改hbase-site.xml文件
进入到配置文件
vi hbase-site.xml
添加的环境配置代码:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/HBase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98 后的新变动,之前版本没有.port,默认端口为 60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper-3.5.7/zkData</value>
</property>
</configuration>
2.3修改/etc/profile
进入到配置文件里
vi /etc/profile
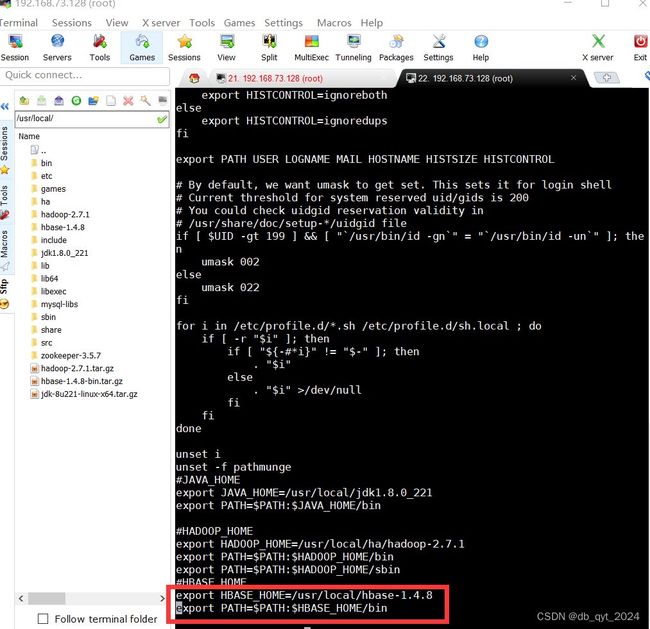
添加的环境配置代码:
export HBASE_HOME=/usr/local/hbase-1.4.8
export PATH=$PATH:/usr/local/hbase-1.4.8/bin
保存退出后需要刷新全局变量,重新可以获取全局变量的信息
ource /etc/profile
2.5将配置好了的HBase文件拷贝给slave1、slave2
需要先切换到/usr/local路径下
scp -r /usr/local/hbase-2.5.4 root@slave1:/usr/local
scp -r /usr/local/hbase-2.5.4 root@slave1:/usr/local
scp -r hbase-1.4.8 root@slave1:/usr/local
scp -r hbase-1.4.8 root@slave2:/usr/local
在slave1中用ll查看有没有配置好的hbase文件,slave2中同理。
三、启动
启动Hadoop前先启动zookeeper集群,最后再启动HBase
3.1启动zookeeper
因为在此之前我已经安装过zookeeper了,所以这里不做操作,需要的自己去百度。
先切换到/usr/local 目录下,随后使用启动zookeeper。
zkServer.sh start
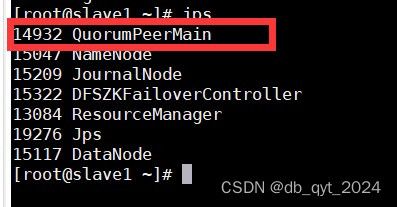
使用jps查看所有集群的进程,看到QuorumPeerMain进程表示启动成功了。
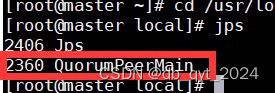
slave1中也是一样
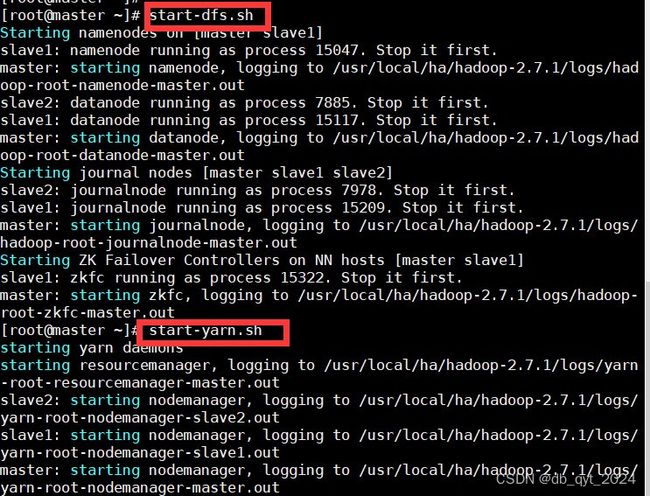
3.2启动hdfs
先启动hds
start-dfs.sh
再启动
start-yarn.sh
嫌麻烦也可以用start-all.sh启动
start-all.sh
停止命令是:
stop-all.sh
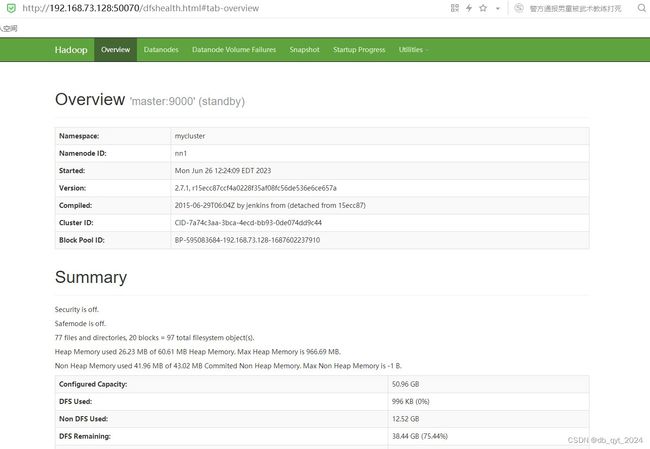
启动hadoop后,进入web端查看是否启动成功。
3.3启动hbase
启动命令
start-hbase.sh
停止命令
stop-hbase.sh
可以用jps查看进程

3.4查看hbase页面
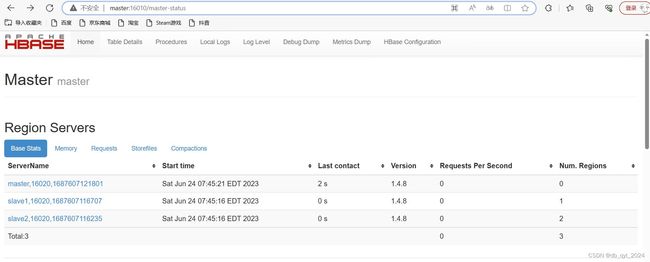
四、HBase操作
4.1进入 HBase命令行
需要切换到/usr/loca路径下,如果已经在此路径下就不需要切换了。
hbase shell
4.1.1查看帮助命令
help
4.1.2查看当前数据库有什么表
list
4.2创建表
create 'student','info'

4.3插入数据
put 'student','1001','info:sex','male'
put 'student','1001','info:age','18'
put 'student','1002','info:name','Janna'
put 'student','1002','info:sex','female'
put 'student','1002','info:age','20'

4.4查看表数据
can 'student'
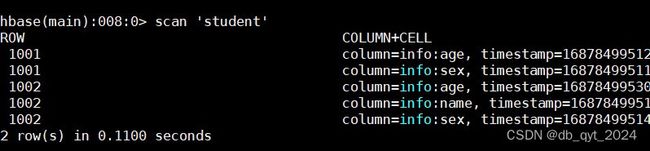
至此Hbase集群搭建完毕。
五、总结
这只是我学习hadoop中的一个小任务,从一开始的看不懂题目到能操作出来,我觉得自己学习收获到了。今后碰到的难题还会更多,学习的脚步不要停止。