Python知识点——文件和数据格式化
目录
文件的打开
文件的打开模式
文件的路径
文件的关闭
文件内容读取
文件的读取
文件的写入
例题
文件的打开
文件的打开模式
| 文件打开模式 | 描述 |
| ‘r’ | 只读模式,默认值,如果文件不存在,返回FileNotFoundError |
| 'w' | 覆盖写模式,文件不存在则创建,存在则完全覆盖 |
| 'x' | 创建写模式,文件不存在则创建,存在则返回FileExistsError |
| ‘a’ | 追加写模式,文件不存在则创建,存在则在文件最后追加内容 |
| ‘b’ | 二进制文件模式 |
| ‘t’ | 文本文件模式,默认值 |
| ‘+’ | 与r/w/a一同使用,在原功能基础上增加同时读写功能 |
文件的路径
<变量名> = open(<文件名>,<打开模式>)
注:与源文件同目录,可省略路径
“D:/PYE/f.txt” “./PYE/f.txt”
”D:\\YE\\f.txt“ "f.txt"
文件打开示例
f = open("f.txt") 文本形式、只读模式、默认值
f = open("f.txt","rt") 文本形式、只读模式、同默认值
f = open("f.txt","w") 文本形式、覆盖写模式
f = open("f.txt","a+") 文本形式、追加写模式+ 读文件
f = open("f.txt","x") 文本形式、创建写模式
f= open("f.txt","b") 二进制形式、只读模式
f = open("f.txt","wb") 二进制形式、覆盖写模式
文件的关闭
<变量名>.close()
#文本形式打开文件
tf = open("f.txt","rt")
print(tf.readline())
tf.close()
#二进制形式打开文件
bf = open("f.txt","rb")print(bf.readline())
bf.close()
文件内容读取
| 操作方法 | 描述 |
| 读入全部内容,如果加入参数size,表示读入前size长度的内容 >>>s = f.read(2) 中国 |
|
| 读入一行内容,如果加入参数size,表示读入改行前size长度的内容 >>>s = f.readline() 中国是一个伟大的国家! |
|
| 读入文件所有行,以每行为元素形成列表如果给出hint,读入文件内对应字节数hint的当前行为止 >>>s = f.readlines() |
文件的读取
方法一:一次性读入
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
txt = fo.read() #对全文txt进行处理
fo.close()
方法二:按数量读入
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
txt = fo.read(2)
while txt != ” “:
#对txt进行处理
txt = fo.read(2)
fo.close()
方法三: 一次读入,按行处理
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
for line in fo.readlines():
print(line)
fo.close()
方法四:分行读入,逐行处理
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
for line in fo:
print(line)
fo.close()
文件的写入
| 操作方法 | 描述 |
| 向文件写入一个字符串或字节流 >>>f.write("中国是一个伟大的国家!") |
|
| 将一个元素全为字符串的列表写入文件 >>>ls = ["中国", "法国", "美国"] >>>f.writelines(ls) 中国法国美国 |
|
| 改变当前文件操作指针的位置,offset开始的偏移量,whence可选,默认为0,含义如下: 0-文件开头; 1- 当前位置; 2- 文件结尾 >>>f.seek(0) #回到文件开头 |
例题:写入一个字符串列表的两种方法
fo = open("output .txt","w+“)
ls = ["中国","法国","美国"]
fo.writelines(ls)
for line in fo:
print(line)fo.close()
#没有任何输出
fo = open("output .txt","w+")
ls = ["中国","法国","美国"]
fo.writelines(ls)
fo.seek(0)
for line in fo:print(line)
fo.close()
#输出中国法国美国
例题
自动轨迹绘制
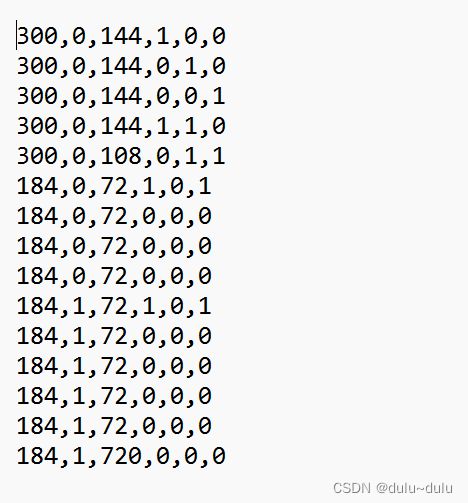
有如下data.txt文件
链接:https://pan.baidu.com/s/1Rt5PD5OPwQpyzJwOoA35Yg
提取码:ghoc
以第一行为例:300 :行进距离 0:转向判断(0:左转,1:右转) 144:转向角度
1,0,0:RGB三个通道颜色
#AutoTraceDraw.py
import turtle as t
t.title('自动轨迹绘制')
t.setup(800, 600, 0, 0)
t.pencolor("red")
t.pensize(5)
#数据读取
datals = []
f = open("data.txt")
for line in f:
line = line.replace("\n","")
datals.append(list(map(eval, line.split(","))))
f.close()
#自动绘制
for i in range(len(datals)):
t.pencolor(datals[i][3],datals[i][4],datals[i][5])
t.fd(datals[i][0])
if datals[i][1]:
t.right(datals[i][2])
else:
t.left(datals[i][2])
能够绘制以下图形,大家可以复制粘贴看看绘制流程:

给出相应星座,输出相应星座日期:
链接:https://pan.baidu.com/s/1Y-cGAmThpFfqpygCs6zd0A
提取码:xtez

import pandas as pd
with open('D:\\SunSign.csv',encoding='UTF-8') as txt:
f=txt.read()
names=[]
datas=[]
for line in f.split("\n"):
line=line.replace("\n","")
datas.append(line.split(","))
names.append(line.split(",")[0])
txt.close()
print("输入星座:")
strList=[]
while(True):
str=input()
if str=='exit':
break
else:
strList.append(str)
for str in strList:
if str in names:
print("{}的生日位于{}-{}之间".format(chr(eval(datas[names.index(str)][3])), datas[names.index(str)][1],datas[names.index(str)][2]))
else:
print("输入星座名称有误!")
输入:

输出:

若输入错误,得到结果为:

构造词云:
使用词云之前要用cmd命令行下载wordcloud

txt文件如下:
链接:https://pan.baidu.com/s/1y6By4u6_3nmy7PBC6POxeQ
提取码:jo9p
代码如下:
#GovRptWordCloudv1.py
import jieba
import wordcloud
f = open("D:\\新时代中国特色社会主义.txt", "r", encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t) #用 jieba 库对文件内容进行中文分词,将分词结果列表赋给变量 ls
txt = " ".join(ls)#将分词结果列表 ls 中的词语用空格连接成一个字符串,并赋给变量 txt
w = wordcloud.WordCloud( font_path = "msyh.ttc",\
width = 1000, height = 700, background_color = "white", \
)
w.generate(txt)#根据文本内容生成词云图像数据。
w.to_file("D:\\grwordcloud.png")#将生成的词云图像数据保存为 "grwordcloud.png" 文件
代码结果如下:
