【备战秋招系列-3】Java高频知识点——排序、设计模式、JavaSE、JVM
排序算法 9
P1:分类
排序算法可以分为内部排序和外部排序,在内存中进行的排序称为内部排序,当要排序的数据量很大时无法全部拷贝到内存,这时需要使用外存进行排序,这种排序称为外部排序。
内部排序包括比较排序和非比较排序,比较排序包括插入排序、选择排序、交换排序和归并排序,非比较排序包括计数排序、基数排序和桶排序。
其中插入排序又包括直接插入排序和希尔排序,选择排序包括直接选择排序和堆排序,交换排序包括冒泡排序和快速排序。
P2:直接插入排序
直接插入排序属于插入排序,是一种稳定的排序,平均/最差时间复杂度均为 O(n²),当元素基本有序时最好时间复杂度为 O(n),空间复杂度为 O(1)。
基本原理:每一趟将一个待排序记录按其关键字的大小插入到已排好序的一组记录的适当位置上,直到所有待排序记录全部插入为止。
适用场景:待排序记录较少或基本有序的情况。
public void insertionSort(int[] nums) {
for (int i = 1; i < nums.length; i++) {
int insertNum = nums[i];
int insertIndex;
for (insertIndex = i - 1; insertIndex >= 0 && nums[insertIndex] > insertNum; insertIndex--) {
nums[insertIndex + 1] = nums[insertIndex];
}
nums[insertIndex + 1] = insertNum;
}
}
优化:直接插入没有利用到要插入的序列已有序的特点,插入第 i 个元素时可以通过二分查找找到插入位置 insertIndex,再把 i~insertIndex 之间的所有元素后移一位,把第 i 个元素放在插入位置上。
public void binaryInsertionSort(int[] nums) {
for (int i = 1; i < nums.length; i++) {
int insertNum = nums[i];
int insertIndex = -1;
int start = 0;
int end = i - 1;
while (start <= end) {
int mid = start + (end - start) / 2;
if (insertNum > nums[mid])
start = mid + 1;
else if (insertNum < nums[mid])
end = mid - 1;
else {
insertIndex = mid + 1;
break;
}
}
if (insertIndex == -1)
insertIndex = start;
if (i - insertIndex >= 0)
System.arraycopy(nums, insertIndex, nums, insertIndex + 1, i - insertIndex);
nums[insertIndex] = insertNum;
}
}
P3:希尔排序
希尔排序属于插入排序,又称缩小增量排序,是对直接插入排序的一种改进,并且是一种不稳定的排序,平均时间复杂度为O(n1.3),最差时间复杂度为 O(n²),最好时间复杂度为 O(n),空间复杂度为 O(1)。
基本原理:把记录按下标的一定增量分组,对每组进行直接插入排序,每次排序后减小增量,当增量减至 1 时排序完毕。
适用场景:中等规模的数据量,对规模很大的数据量不是最佳选择。
public void shellSort(int[] nums) {
for (int d = nums.length / 2; d > 0 ; d /= 2) {
for (int i = d; i < nums.length; i++) {
int insertNum = nums[i];
int insertIndex;
for (insertIndex = i - d; insertIndex >= 0 && nums[insertIndex] > insertNum; insertIndex -= d) {
nums[insertIndex + d] = nums[insertIndex];
}
nums[insertIndex + d] = insertNum;
}
}
}
P4:直接选择排序
直接选择排序属于选择排序,是一种不稳定的排序,任何情况下时间复杂度都是 O(n²),空间复杂度为 O(1)。
基本原理:每次在未排序序列中找到最小元素,和未排序序列的第一个元素交换位置,再在剩余未排序序列中重复该操作直到所有元素排序完毕。
适用场景:数据量较小的情况,比直接插入排序稍快。
public void selectSort(int[] nums) {
int minIndex;
for (int index = 0; index < nums.length - 1; index++){
minIndex = index;
for (int i = index + 1;i < nums.length; i++){
if(nums[i] < nums[minIndex])
minIndex = i;
}
if (index != minIndex){
swap(nums, index, minIndex);
}
}
}
P5:堆排序
堆排序属于选择排序,是对直接选择排序的改进,并且是一种不稳定的排序,任何情况时间复杂度都为 O(nlogn),空间复杂度为 O(1)。
基本原理:将待排序记录看作完全二叉树,可以建立大根堆或小根堆,大根堆中每个节点的值都不小于它的子节点值,小根堆中每个节点的值都不大于它的子节点值。
以大根堆为例,在建堆时首先将最后一个节点作为当前节点,如果当前节点存在父节点且值大于父节点,就将当前节点和父节点交换。在移除时首先暂存根节点的值,然后用最后一个节点代替根节点并作为当前节点,如果当前节点存在子节点且值小于子节点,就将其与值较大的子节点进行交换,调整完堆后返回暂存的值。
适用场景:数据量较大的情况。
public void add(int[] nums, int i, int num){
nums[i] = num;
int curIndex = i;
while (curIndex > 0) {
int parentIndex = (curIndex - 1) / 2;
if (nums[parentIndex] < nums[curIndex])
swap(nums, parentIndex, curIndex);
else break;
curIndex = parentIndex;
}
}
public int remove(int[] nums, int size){
int result = nums[0];
nums[0] = nums[size - 1];
int curIndex = 0;
while (true) {
int leftIndex = curIndex * 2 + 1;
int rightIndex = curIndex * 2 + 2;
if (leftIndex >= size) break;
int maxIndex = leftIndex;
if (rightIndex < size && nums[maxIndex] < nums[rightIndex])
maxIndex = rightIndex;
if (nums[curIndex] < nums[maxIndex])
swap(nums, curIndex, maxIndex);
else break;
curIndex = maxIndex;
}
return result;
}
P6:冒泡排序
冒泡排序属于交换排序,是一种稳定的排序,平均/最坏时间复杂度均为 O(n²),当元素基本有序时最好时间复杂度为O(n),空间复杂度为 O(1)。
基本原理:是比较相邻的元素,如果第一个比第二个大就进行交换,对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对,每一轮排序后末尾元素都是有序的,针对 n 个元素重复以上步骤 n -1 次排序完毕。
public void bubbleSort(int[] nums) {
for (int i = 0; i < nums.length - 1; i++) {
for (int index = 0; index < nums.length - 1 - i; index++) {
if (nums[index] > nums[index + 1])
swap(nums, index, index + 1)
}
}
}
优化:当序列已经有序时仍会进行不必要的比较,可以设置一个标志记录是否有元素交换,如果没有直接结束比较。
public void betterBubbleSort(int[] nums) {
boolean swap;
for (int i = 0; i < nums.length - 1; i++) {
swap = true;
for (int index = 0; index < nums.length - 1 - i; index++) {
if (nums[index] > nums[index + 1]) {
swap(nums, index ,index + 1);
swap = false;
}
}
if (swap) break;
}
}
P7:快速排序
快速排序属于交换排序,是对冒泡排序的一种改进,并且是一种不稳定的排序,平均/最好时间复杂度均为 O(nlogn),当元素基本有序时最坏时间复杂度为O(n²),空间复杂度为 O(logn)。
基本原理:首先选择一个基准元素,通过一趟排序将要排序的数据分割成独立的两部分,一部分全部小于等于基准元素,一部分全部大于等于基准元素,再按此方法递归对这两部分数据进行快速排序。
快速排序的一次划分从两头交替搜索,直到 low 和 high 指针重合,因此一趟时间复杂度是 O(n),而整个算法的时间复杂度与划分趟数有关。最好情况是每次划分选择的中间数恰好将当前序列等分,经过 log(n) 趟划分便可得到长度为 1 的子表,这样算法的时间复杂度为O(nlogn)。最坏情况是每次所选中间数是当前序列中的最大或最小元素,这使每次划分所得子表其中一个为空表,另一个子表的长度为原表的长度 - 1。这样长度为 n 的数据表的需要经过 n 趟划分,整个排序算法的时间复杂度为O(n²)。
适用场景:数据量较大且元素基本无序的情况。
public void quickSort(int[] nums, int start, int end) {
if (start < end) {
int pivotIndex = getPivotIndex(nums, start, end);
quickSort(nums, start, pivotIndex - 1);
quickSort(nums, pivotIndex + 1, end);
}
}
public int getPivotIndex(int[] nums, int start, int end) {
int pivot = nums[start];
int low = start;
int high = end;
while (low < high) {
while (low <= high && nums[low] <= pivot)
low++;
while (low <= high && nums[high] > pivot)
high--;
if (low < high)
swap(nums, low, high);
}
swap(nums, start, high);
return high;
}
优化:当规模足够小时,例如 end - start < 10 时,采用直接插入排序。
P8:归并排序
归并排序基于归并操作,是一种稳定的排序算法,任何情况时间复杂度都为 O(nlogn),空间复杂度为 O(n)。
基本原理:应用分治法将待排序序列分成两部分,然后对两部分分别递归排序,最后进行合并,使用一个辅助空间并设定两个指针分别指向两个有序序列的起始元素,将指针对应的较小元素添加到辅助空间,重复该步骤到某一序列到达末尾,然后将另一序列剩余元素合并到辅助空间末尾。
适用场景:数据量大且对稳定性有要求的情况。
int[] help;
public void mergeSort(int[] arr) {
int[] help = new int[arr.length];
sort(arr, 0, arr.length - 1);
}
public void sort(int[] arr, int start, int end) {
if (start == end) return;
int mid = start + (end - start) / 2;
sort(arr, start, mid);
sort(arr, mid + 1, end);
merge(arr, start, mid, end);
}
public void merge(int[] arr, int start, int mid, int end) {
if (end + 1 - start >= 0) System.arraycopy(arr, start, help, start, end + 1 - start);
int p = start;
int q = mid + 1;
int index = start;
while (p <= mid && q <= end) {
if (help[p] < help[q])
arr[index++] = help[p++];
else
arr[index++] = help[q++];
}
while (p <= mid) arr[index++] = help[p++];
while (q <= end) arr[index++] = help[q++];
}
P9:排序算法的选择原则
当数据量规模较小时,考虑直接插入排序或直接选择排序,当元素分布有序时直接插入排序将大大减少比较次数和移动记录的次数,如果不要求稳定性,可以使用直接选择排序,效率略高于直接插入排序。
当数据量规模中等时,选择希尔排序。
当数据量规模较大时考虑堆排序、快速排序和归并排序。如果对稳定性有要求可以采用归并排序,如果元素分布随机可以采用快速排序,如果元素分布接近正序或逆序可以采用堆排序。
一般不使用冒泡排序。
设计模式 12
P1:原则
开闭原则:面向对象设计中最基础的设计原则,指一个软件实体(类、模块、方法等)应该对扩展开放,对修改关闭。它强调用抽象构建框架,用实现扩展细节,提高代码的可复用性和可维护性。例如在版本更新时尽量不修改源代码,但可以增加新功能。
单一职责原则:一个类、接口或方法只负责一个职责,提高代码可读性和可维护性,降低代码复杂度以及变更引起的风险。
依赖倒置原则:程序应该依赖于抽象类或接口,而不是具体的实现类。可以降低代码的耦合度,提高系统的稳定性。
接口隔离原则:将不同功能定义在不同接口中实现接口隔离,避免了类依赖它不需要的接口,减少了接口之间依赖的冗余性和复杂性。
里氏替换原则:对开闭原则的补充,规定了任何父类可以出现的地方子类都一定可以出现,可以约束继承泛滥,加强程序健壮性。
迪米特原则:也叫最少知道原则,每个模块对其他模块都要尽可能少地了解和依赖,降低代码耦合度。
合成/聚合原则:尽量使用组合(has-a)/聚合(contains-a)而不是继承(is-a)达到软件复用的目的,避免滥用继承带来的方法污染和方法爆炸,方法污染指父类的行为通过继承传递给子类,但子类并不具备执行此行为的能力;方法爆炸指继承树不断扩大,底层类拥有的方法过于繁杂,导致很容易选择错误。
P2:分类
创建型模式:提供了一种在创建对象的同时隐藏创建逻辑的方式,而不是使用 new 运算符直接实例化对象,使程序在判断需要创建哪些对象时更加灵活。包括工厂模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式:通过类和接口之间的继承和引用实现创建复杂结构的对象。包括适配器模式、桥接模式、过滤器模式、组合模式、装饰器模式、外观模式、享元模式、代理模式。
行为型模式:通过类之间不同的通信方式实现不同的行为。包括责任链模式、命名模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、模板模式、访问者模式。
###P3:简单工厂模式
工厂模式属于创建型模式,分为简单工厂模式,工厂方法模式和抽象工厂模式。
简单工厂模式指由一个工厂对象来创建实例,客户端不需要关注创建的逻辑,只需要提供传入工厂对象的参数。适用于工厂类负责创建对象较少的情况,缺点是如果要增加新产品,就需要修改工厂类的判断逻辑,违背开闭原则,且产品多的话会使工厂类比较复杂。
应用举例
Calendar 抽象类的 getInstance 方法,该方法调用了 createCalendar 方法,根据不同的地区参数创建不同的日历对象。
Spring 中的 BeanFactory 使用简单工厂模式,根据传入一个唯一的标识来获得 Bean 对象。
举例
一个工厂和一种抽象产品。例如一个麦当劳店可以生产汉堡。
public class MacDonaldFactory {
public Hamburger eatHamburger(String name) {
if ("beef".equals(name))
return new BeefHamburger();
else if ("pig".equals(name))
return new PigHamburger();
return null;
}
}
interface Hamburger {
void eat();
}
class BeefHamburger implements Hamburger {
@Override
public void eat() {
System.out.println("吃牛肉汉堡");
}
}
class PigHamburger implements Hamburger {
@Override
public void eat() {
System.out.println("吃猪肉汉堡");
}
}
P4:工厂方法模式
工厂方法模式指定义一个创建对象的接口,让接口的实现类来决定创建哪一种对象,让类的实例化推迟到子类中进行。客户端只需关心对应的工厂而无需关心创建细节,主要解决了产品扩展的问题,在简单工厂模式中如果产品种类变多,工厂的职责会越来越多,不便于维护。
应用举例
Collection 接口这个抽象工厂中定义了一个抽象的 iterator 工厂方法,返回一个 Iterator 类的抽象产品。该方法通过 ArrayList 、HashMap 等具体工厂实现,返回 Itr、KeyIterator 等具体产品。
Spring 的 FactoryBean 接口的 getObject 方法也是一个工厂方法。
举例
多个工厂和一种抽象产品。例如一个麦当劳店可以生产汉堡,一个肯德基店也可以生产汉堡。
public interface HamburgerFactory {
Hamburger build();
}
class MCFactory implements HamburgerFactory {
@Override
public Hamburger build() {
return new MCHamburger();
}
}
class KFCFactory implements HamburgerFactory {
@Override
public Hamburger build() {
return new KFCHamburger();
}
}
interface Hamburger {
void eat();
}
class MCHamburger implements Hamburger {
@Override
public void eat() {
System.out.println("吃麦当劳汉堡");
}
}
class KFCHamburger implements Hamburger {
@Override
public void eat() {
System.out.println("吃肯德基汉堡");
}
}
P5:抽象工厂模式
抽象工厂模式指提供一个创建一系列相关或相互依赖对象的接口,无需指定它们的具体类。客户端不依赖于产品类实例如何被创建和实现的细节,主要用于系统的产品有多于一个的产品族,而系统只消费其中某一个产品族产品的情况。抽象工厂模式的缺点是不方便扩展产品族,并且增加了系统的抽象性和理解难度。
应用举例
java.sql.Connection 接口就是一个抽象工厂,其中包括很多抽象产品如 Statement、Blob、Savepoint 等。
举例
多个工厂和多种抽象产品。例如一个麦当劳店和一个肯德基店都可以生产汉堡和可乐。
public interface FoodFactory {
Hamburger buildHamburger();
Drink buildDrink();
}
class MCFactory implements FoodFactory {
@Override
public Hamburger buildHamburger() {
return new MCHamburger();
}
@Override
public Drink buildDrink() {
return new MCDrink();
}
}
class KFCFactory implements FoodFactory {
@Override
public Hamburger buildHamburger() {
return new KFCHamburger();
}
@Override
public Drink buildDrink() {
return new KFCDrink();
}
}
interface Hamburger {
void eat();
}
class MCHamburger implements Hamburger {
@Override
public void eat() {
System.out.println("吃麦当劳汉堡");
}
}
class KFCHamburger implements Hamburger {
@Override
public void eat() {
System.out.println("吃肯德基汉堡");
}
}
interface Drink {
void drink();
}
class MCDrink implements Drink {
@Override
public void drink() {
System.out.println("喝麦当劳饮料");
}
}
class KFCDrink implements Drink {
@Override
public void drink() {
System.out.println("喝肯德基饮料");
}
}
P6:单例模式
单例模式属于创建型模式,指一个单例类在任何情况下都只存在一个实例,构造方法必须是私有的、由自己创建一个静态实例对象存储该实例,并对外提供一个静态公有方法获取实例。优点是内存中只有一个实例,减少了开销,尤其是频繁创建和销毁实例的情况下,并且可以避免对资源的多重占用。缺点是没有抽象层,难以扩展,与单一职责原则冲突。
应用举例
Spring 的 ApplicationContext 创建的 Bean 实例都是单例对象,还有 ServletContext、数据库连接池等也都是单例模式。
饿汉式:在类加载时就初始化创建单例对象,线程安全,但不管是否使用都创建对象可能会浪费内存。
public class HungrySingleton {
private HungrySingleton(){}
private static HungrySingleton instance = new HungrySingleton();
public static HungrySingleton getInstance() {
return instance;
}
}
懒汉式:在外部调用时才会加载,线程不安全,可以加锁保证线程安全但效率低。
public class LazySingleton {
private LazySingleton(){}
private static LazySingleton instance;
public static LazySingleton getInstance() {
if(instance == null) {
instance = new LazySingleton();
}
return instance;
}
}
双重检查锁:使用 volatile 以及多重检查来减小锁范围,提升效率。
public class DoubleCheckSingleton {
private DoubleCheckSingleton(){}
private volatile static DoubleCheckSingleton instance;
public static DoubleCheckSingleton getInstance() {
if(instance == null) {
synchronized (DoubleCheckSingleton.class) {
if (instance == null) {
instance = new DoubleCheckSingleton();
}
}
}
return instance;
}
}
静态内部类:同时解决饿汉式的内存浪费问题和懒汉式的线程安全问题。
public class StaticSingleton {
private StaticSingleton(){}
public static StaticSingleton getInstance() {
return StaticClass.instance;
}
private static class StaticClass {
private static final StaticSingleton instance = new StaticSingleton();
}
}
枚举:Effective Java 作者提倡的方式,不仅能避免线程安全问题,还能防止反序列化重新创建新的对象,绝对防止多次实例化,也能防止反射破解单例的问题。
public enum EnumSingleton {
INSTANCE;
}
P7:代理模式
代理模式属于结构型模式,为其他对象提供一种代理以控制对这个对象的访问。优点是可以增强目标对象的功能,降低代码耦合度,扩展性好。缺点是在客户端和目标对象之间增加代理对象会导致请求处理速度变慢,增加系统复杂度。
应用举例
Spring 利用动态代理实现 AOP,如果 Bean 实现了接口就使用 JDK 代理,否则使用 CGLib 代理。
静态代理:代理对象持有被代理对象的引用,调用代理对象方法时也会调用被代理对象的方法,但是会在被代理对象方法的前后增加其他逻辑。需要手动完成,在程序运行前就已经存在代理类的字节码文件,代理类和被代理类的关系在运行前就已经确定了。 缺点是一个代理类只能为一个目标服务,如果要服务多种类型会增加工作量。
public interface Company {
void findWorker();
}
public class Hr implements Company {
@Override
public void findWorker() {
System.out.println("需要找招聘一个员工");
}
}
public class Proxy implements Company {
private Hr hr;
public Proxy(){
this.hr = new Hr();
}
@Override
public void findWorker() {
hr.findWorker();
System.out.println("找到了员工");
}
}
动态代理:动态代理在程序运行时通过反射创建具体的代理类,代理类和被代理类的关系在运行前是不确定的。动态代理的适用性更强,主要分为 JDK 动态代理和 CGLib 动态代理。
- JDK 动态代理:通过 Proxy 类的 newInstance 方法获取一个动态代理对象,需要传入三个参数,被代理对象的类加载器、被代理对象实现的接口,以及一个 InvocationHandler 调用处理器来指明具体的逻辑,相比静态代理的优势是接口中声明的所有方法都被转移到 InvocationHandler 的 invoke 方法集中处理。
public static void main(String[] args) { Hr hr = new Hr(); Company proxyHr = (Company) Proxy.newProxyInstance(hr.getClass().getClassLoader(), hr.getClass().getInterfaces(), (proxy, method, args1) -> { System.out.println("接收代理请求"); Object obj = method.invoke(hr, args1); System.out.println("找到了员工,完成请求"); return obj; }); proxyHr.findWorker(); } ``` - CGLib 动态代理:JDK 动态代理要求实现被代理对象的接口,而 CGLib 要求继承被代理对象,如果一个类是 final 类则不能使用 CGLib 代理。两种代理都在运行期生成字节码,JDK 动态代理直接写字节码,而 CGLib 动态代理使用 ASM 框架写字节码,ASM 的目的是生成、转换和分析以字节数组表示的已编译 Java 类。 JDK 动态代理调用代理方法通过反射机制实现,而 GCLib 动态代理通过 FastClass 机制直接调用方法,它为代理类和被代理类各生成一个类,该类为代理类和被代理类的方法分配一个 int 参数,调用方法时可以直接定位,因此调用效率更高。
P8:装饰器模式
装饰器模式属于结构型模式,在不改变原有对象的基础上将功能附加到对象,相比继承可以更加灵活地扩展原有对象的功能。这种模式创建了一个装饰类用来包装原有的类,并在保持类方法签名完整性的前提下提供了额外的功能。装饰器模式适合的场景:在不想增加很多子类的前提下扩展一个类的功能。
应用举例
java.io 包中,InputStream 字节输入流通过装饰器 BufferedInputStream 增强为缓冲字节输入流。
和代理模式的区别:装饰器模式的关注点在于给对象动态添加方法,而动态代理更注重对象的访问控制。动态代理通常会在代理类中创建被代理对象的实例,而装饰器模式会将装饰者作为构造方法的参数。
P9:适配器模式
适配器模式属于结构型模式,它作为两个不兼容接口之间的桥梁,结合了两个独立接口的功能,将一个类的接口转换成另外一个接口,这种模式涉及到一个单一的类,该类负责加入独立或不兼容的接口功能。优点是使得原本由于接口不兼容而不能一起工作的类可以一起工作。 缺点是过多使用适配器会让系统非常混乱,不易整体把握。
应用举例
- java.io 包中,InputStream 字节输入流通过适配器 InputStreamReader 转换为 Reader 字符输入流。
- Spring MVC 中的 HandlerAdapter,由于 handler 有很多种形式,包括 Controller、HttpRequestHandler、Servlet 等,但调用方式又是确定的,因此需要适配器来进行处理,根据适配规则调用 handle 方法。
- Arrays.asList 方法,将数组转换为对应的集合(注意不能使用修改集合的方法,因为返回的 ArrayList 是 Arrays 的一个内部类)。
和装饰器模式的区别:适配器模式没有层级关系,适配器和被适配者没有必然连续,满足 has-a 的关系,主要用于解决不兼容的问题,注重兼容和转换,是一种后置考虑。装饰器模式具有层级关系,装饰器与被装饰者实现同一个接口,满足 is-a 的关系,注重覆盖和扩展,是一种前置考虑。
和代理模式的区别:适配器模式主要改变所考虑对象的接口,而代理模式不能改变所代理类的接口。
P10:策略模式
策略模式属于行为型模式,定义了一系列算法并把它们封装起来,让它们之间可以互相替换。策略模式的应用场景主要包括:① 在一个系统里面有许多类,它们之间的区别仅在于它们的行为,使用策略模式可以动态地让一个对象在许多行为中选择一种行为。 ② 一个系统需要动态地在几种算法中选择一种。策略模式主要解决在有多种算法相似的情况下,使用 if/else 所带来的复杂和难以维护。策略模式的优点是算法可以自由切换,可以避免使用多重条件判断并且扩展性良好,缺点是策略类会增多并且所有策略类都需要对外暴露。
应用举例
- 比较器 Comparator:在集合框架中,经常需要通过构造方法传入一个比较器 Comparator 进行比较排序。Comparator 就是一个抽象策略,一个类通过实现该接口并重写 compare 方法成为具体策略类。
- ThreadPoolExecutor 中的四种拒绝策略:在创建线程池时,需要传入拒绝策略,当创建新线程使当前运行的线程数超过maximumPoolSize 时会使用相应的拒绝策略进行处理。
P11:模板模式
模板模式属于行为型模式,指定义一个算法的骨架,并允许子类为一个或多个步骤提供实现。模板模式使子类可以在不改变算法结构的情况下重新定义算法的某些步骤,适用于抽取子类的重复代码到一个公共父类中。优点是可以封装固定不变的部分,扩展可变的部分。缺点是每一个不同实现都需要一个子类维护,会增加类的数量。为防止恶意操作,一般模板方法都以 final 修饰。
应用举例
每一个 Servlet 都必须实现 Servlet 接口,GenericServlet 是实现了该接口的通用抽象类,而 HttpServlet 继承了 GenericServlet,提供了处理 HTTP 协议的通用实现,所以一般定义 Servlet 只需要继承 HttpServlet 即可。
HttpServlet 定义了一套处理 HTTP 请求的模板,service 方法为模板方法,定义了处理HTTP请求的基本流程,doXXX 等方法为基本方法,根据请求方法的类型做相应的处理,子类可重写这些方法。
P12:观察者模式
观察者模式属于行为型模式,也叫发布订阅模式,定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。主要解决一个对象状态改变给其他对象通知的问题,缺点是如果一个被观察者对象有很多的直接和间接观察者的话,通知很耗时, 并且如果存在循环依赖的话可能导致系统崩溃,另外观察者无法知道目标对象具体是怎么发生变化的。
应用举例
ServletContextListener 能够监听 ServletContext 对象的生命周期,实际上就是监听 Web 应用。在 ServletContextListener 中定义了处理对应事件的两个方法,当 Servlet 容器启动 Web 应用时调用 contextInitialized 方法,终止 Web 应用时调用 contextDestroyed 方法。
Java 基础 22
P1:基本概念
优点
① 具有平台无关性,摆脱了硬件平台的束缚,实现了"一次编写,到处运行"。
② 提供了一种相对安全的内存管理和访问机制,避免了大部分内存泄漏和指针越界问题。
③ 实现了热点代码检测和运行时编译及优化,使得程序随运行时间增长可以获得更高的性能。
④ 有一套完善的应用程序接口,还支持很多第三方类库。
Java 平台无关性原理
主要通过 JVM 和语言规范实现。
- 编译器生成一个体系结构中立的目标文件格式,这是一种编译后的代码,只要有 Java 运行时系统,这些编译后的代码就可以在很多处理器上运行。Java 编译器通过生成与特定计算机体系结构无关的字节码指令来实现这一特性,字节码文件不仅可以很容易地在任何机器上解释执行,还可以动态地转换成本地机器代码,转换是由 JVM 实现的,JVM 是平台相关的,屏蔽了不同操作系统的差异。
- Java 中基本数据类型的大小以及有关运算的行为都有明确的说明,例如 int 类型永远为 32 位整数,而在 C/C++ 中可能是 16 位整数、32 位整数,也可能是编译器开发商指定的其他任何大小。在 Java 中数值类型有固定的字节数,二进制数据以固定的格式进行存储和传输,字符串则采用标准的 Unicode 格式存储。
JDK 和 JRE 的区别
JDK:Java Development Kit,Java 开发工具包。它提供了编译、运行 Java 程序所需的各种工具和资源,包括 Java 编译器、JRE 以及常用的基础类库等,是 JAVA 的核心。
JRE:Java Runtime Environment,Java 运行时环境,是运行基于 Java 语言编写的程序所不可缺少的运行环境,包括 JVM、核心类库、核心配置工具等。
P2:数据类型
基本数据类型

JVM 并没有针对 boolean 数据类型进行赋值的专用字节码指令,boolean f = false 就是使用 ICONST_0,即常数 0 来进行赋值。单个boolean 变量用 int 代替,而 boolean 数组会编码成 byte 数组。
每个基本数据类型都对应一个自己的包装类,除了 int 和 char 对应 Integer 和 Character 之外,其余基本数据类型的包装类都是首字母大写即可。自动装箱指的是将基本数据类型包装为一个包装类对象,例如向一个泛型为 Integer 类型的集合添加 int 类型的元素。自动拆箱指的是将一个包装类对象转换为一个基本数据类型,例如将一个包装类对象赋值给一个基本数据类型的变量。要比较两个包装类的数值需要使用 equals 方法,而不能使用 == 比较运算符。
所有的 POJO 类属性必须使用包装数据类型,RPC 方法的返回值和参数必须使用包装数据类型,所有局部变量推荐使用基本数据类型。
引用数据类型
引用数据类型分为引用变量本身和引用指向的对象,引用变量称为 refvar,引用指向的实际对象称为 refobj。
refvar 是基本的数据类型,它的默认值是 null,存储 refobj 的首地址,可以直接使用双等号 == 进行等值判断。作为一个引用变量,不管它指向包装类、集合类、字符串还是自定义类,均占 4B 空间。无论 refobj 是多么小的对象,最小的占用空间是 12B(用于存储基本信息,称为对象头),但由于存储空间分配必须是 8B 的倍数,所以初始分配空间至少是 16B。
一个 refvar 至多存储一个 refobj 的首地址,一个 refobj 可以被多个 refvar 存储下它的首地址,即一个堆内对象可以被多个 refvar 引用指向。如果 refobj 没有被任何 refvar 指向,那么迟早会被垃圾回收。
P3:String
String 是 final 修饰的不可变只读字符串类,存储数据的 value 字符数组也是 final 修饰的不可变数组。String 对象是不可变对象,对它的任何修改实际上都是创建一个新对象,再把引用指向该对象。String 对象赋值操作后,会在常量池中进行缓冲,如果下次申请创建对象时,缓存中已经存在就直接返回相应引用给创建者。
直接使用 + 进行字符串拼接,如果是字面量会自动拼接为一个新的常量,但如果在循环体内拼接效率就很低。要提升拼接效率可以使用 StringBuilder 或 StringBuffer 可变字符串,可以直接在原对象上进行修改,区别是 StringBuffer 使用了 synchronized 保证线程安全性,但一般字符串拼接都是单线程操作,所以使用 StringBuilder 较多。常量和常量的拼接,结果也在常量池中,且不存在两个相同的常量。只要参与拼接的字符串里有变量,结果就在堆中。
如果是通过字符串常量赋值的形式,例如 String s = “s”,字符串常量内容存于常量池,变量存于栈中并直接引用常量池中的字符串。如果是通过new 的形式,例如 String s = new String(“s”),会先在堆中创建实例对象,然后再去常量池寻找需要的字符串常量,如果找到了则直接使用,没找到则开辟新的空间并存储内容,最后栈中变量引用堆中对象,对象再引用常量池中的字符串。
P4:值调用和引用调用
按值调用指的是方法接收的是调用者提供的值,而按引用调用指的是方法接收的是调用者提供的变量地址。Java 总是采用按值调用,也就是说方法得到的是所有参数值的一个副本,当传递对象时实际上方法接收的是这个对象引用的副本。方法不能修改基本数据类型的参数,可以改变对象参数的状态,但不能让对象参数引用一个新的对象。
举例来说,如果传递了一个 int 类型的值 ,改变该值不会影响实参,因为改变的是该值的一个副本。如果传递了一个 int[] 类型的数组,改变数组的内容会影响实参,而如果改变这个参数的引用,并不会让实参引用新的数组对象。
P5:面向对象
概念
面向过程让计算机有步骤地顺序做一件事,是一种过程化思维,在使用面向过程语言开发大型项目时,软件复用和维护存在很大问题,模块之间耦合严重。面向对象相对于面向过程而言更适合解决规模较大的问题,可以拆解问题复杂度,对现实事物进行抽象并映射为开发对象,更接近人的思维。
例如开门这个动作,面向过程是"open(Door door)",是一种动宾结构,“door"是被作为操作对象的参数传入方法的,方法内定义开门的具体步骤实现。而使用面向对象的方式,首先会定义一个类"Door”,然后抽象出门的属性(如尺寸、颜色)和行为(如 open 和 close),属于主谓结构。面向过程的代码结构松散,强调如何流程化地解决问题。面向对象的代码强调高内聚、低耦合,先抽象模型,定义共性行为,再解决实际问题。
封装
封装是一种对象功能内聚的表现形式,在抽象基础上决定信息是否公开,以及公开等级,核心问题是以什么样的方式暴漏哪些信息。封装的主要任务是对属性、数据、部分内部敏感行为实现隐藏,对熟悉的访问和修改必须通过公共接口来实现,某些敏感方法或外部不需要感知的复杂逻辑一般也会进行封装。封装使对象之间的关系变得简单,降低了代码耦合度,有利维护。
设计模式原则的迪米特原则就是对封装的具体要求,即 A 模块使用 B 模块的某个接口行为,对 B 模块中除此行为之外的其他信息知道的应该尽可能少。之所以不直接对 public 的属性进行读取和修改,而是使用对应的 getter/setter 方法,是因为假设想在修改属性时进行权限控制、日志记录等操作,在直接访问属性的情况下是无法做到的。如果将公开的属性和行为修改为 private 则依赖模块都会报错,因此在不知道使用哪种访问控制权限时应当优先使用 private。
继承
可以通过继承来扩展一个类,子类可以继承父类的部分属性和行为,使模块具有复用性。继承是一种"is-a"的关系,可以使用里氏替换原则判断是否满足"is-a"关系,即任何父类出现的地方子类都可以出现。如果父类引用直接使用子类引用来代替,可以正确编译并执行,输出结果符合子类场景的预期,那么说明两个类符合里氏替换原则,可以使用继承关系。
多态
多态是以封装和继承为基础,根据运行时的实际对象类型,同一个方法产生不同的运行结果,使同一个行为具有不同的表现形式。多态是指在编译层面无法确定最终调用的方法体,以重写为基础来实现面向对象特性,在运行期由 JVM 进行动态绑定,调用合适的重写方法体来执行。由于重载是编译期确定方法调用,属于静态绑定,本质上重载的结果是完全不同的方法,因此一般多态专指重写。
-
重载
重载是指方法名称相同,但是参数类型或参数个数不相同,是水平方向上行为的不同实现。对于编译器来说,方法名称和参数列表组成了一个唯一键,称为方法签名,JVM 通过这个唯一键决定调用哪种重载的方法。
JVM 在重载方法中,选择合适的目标方法的顺序:① 精确匹配。② 如果是基本数据类型,自动转换成更大表示范围的基本类型。③ 通过自动拆箱与装箱。④ 通过子类向上转型继承路线依次匹配。⑤ 通过可变参数匹配。
不管继承关系如何复杂,重载在编译时可以根据规则知道调用哪种目标方法,因此重载属于静态绑定。 -
重写
重写是指子类实现接口或者继承父类时,保持方法签名完全相同,实现不同的方法体,是垂直方向上行为的不同实现。
元空间有一个方法表保存着每个可以实例化类的方法信息,JVM 可以通过方法表快速激活实例方法。如果某个类重写了父类的某个方法,则方法表中的方法指向引用会指向子类的实现处。需要注意父类引用执行子类方法时无法调用子类存在而父类不存在的方法。
重写的子类方法访问权限不能变小,返回类型和抛出的异常类型不能变大,且必须加 @Override 注解。
P6:访问权限控制符

P7:Object 类
Object 的类是所有类的父类,Object 类的方法:
- equals:用于检测一个对象是否等于另一个对象,默认使用 == 比较两个对象的引用,可以重写 equals 方法自定义比较规则。equals 方法需要满足以下规范:自反性、对称性、传递性、一致性并对于任何非空引用 x,x.equals(null) 返回 false。
- hashCode:散列码是由对象导出的一个整型值,是没有规律的,每个对象都有一个默认的散列码,值由对象的存储地址得出。字符串可能有相同的散列码,因为字符串的散列码是由内容导出的。为了在集合中正确使用对象,一般需要同时重写 equals 和 hashCode 方法,要求是 equals 相同是 hashCode 必须相同,但 hashCode 相同时 equals 未必相同,因此 hashCode 是两个对象相同的必要不充分条件。
- toString:打印对象时默认会调用它的 toString 方法,如果没有重写该方法默认打印的是表示对象值的一个字符串,一般需要重写该方法。打印数组时可以使用 Arrays.toString() 方法。
- clone:clone 方法声明为 protected,类只能通过该方法克隆它自己的对象,如果希望其他类也能调用该方法必须定义该方法为 public。如果一个对象的类没有实现 Cloneable 接口,该对象调用 clone 方法会抛出一个 CloneNotSupport 异常。默认的 clone 方法是浅拷贝,一般重写 clone 方法需要实现 Cloneable 接口并指定访问修饰符为 public。
- 浅拷贝:只复制当前对象的基本数据类型以及相应的引用变量,但没有复制引用变量指向的实际对象。对克隆对象的修改可能会影响原对象,是不安全的。
- 深拷贝:会完全拷贝基本数据类型和引用数据类型,深拷贝是安全的。
- finalize:要确定一个对象死亡至少要经过两次标记,如果对象在进行可达性分析后发现没有与 GC Roots 连接的引用链,会被第一次标记,随后进行一次筛选,筛选条件是此对象是否有必要执行 finalize 方法。假如对象没有重写 finalize 方法或者该方法已经被虚拟机调用过,这两种情况视为没有必要执行。如果判断为有必要执行,对象就会被放置在一个叫做 F-Queue 的队列中,由一条虚拟机自动建立的低调度优先级的 Finalizer 线程去执行其 finalize 方法。虚拟机会触发该方法但不保证它会运行结束,这是为了防止某个对象的 finalize 方法执行缓慢或发生死循环。只要对象在 finalize 方法中重新与引用链上的任何一个对象建立关联就会在第二次标记时被移出即将回收集合。由于运行代价高昂,不确定性大,无法保证各个对象的调用顺序,在 JDK 9 已经被标记为过时方法,因此它并不适合释放资源,释放资源可以使用 try-finally 代码块。
- getClass:返回包含对象信息的类对象。
- wait / notify / notifyAll:阻塞或唤醒持有该对象锁的线程。
P8:内部类
使用内部类主要有两个原因:内部类可以对同一个包中的其他类隐藏。内部类方法可以访问定义这个内部类的作用域中的数据,包括原本私有的数据。内部类是一个编译器现象,与虚拟机无关。编译器会把内部类转换成常规的类文件,用美元符号 $ 分隔外部类名与内部类名,其中匿名内部类使用数字进行编号,虚拟机对此一无所知。
静态内部类:由 static 修饰,属于外部类本身,只加载一次。静态内部类的好处是作用域仅在包内,可以通过 外部类.内部类 直接访问,并且静态内部类可以访问外部类中所有静态属性和方法。例如 HashMap 中的 Node 节点,ReentrantLock 中继承自 AQS 的 Sync 类,ArrayList 中的 SubList 都是静态内部类。内部类中还可以定义内部类,例如 ThreadLoacl 静态内部类 ThreadLoaclMap 中还定义了一个内部类 Entry。
成员内部类:属于外部类的每个对象,随对象一起加载。不可以定义静态成员和方法,可以访问外部类的所有内容。
局部内部类:定义在方法或者表达式内部。不能声明访问修饰符,只能定义实例成员变量和实例方法,作用范围仅在声明这个局部类的代码块中。
匿名内部类:没有名字的局部内部类,可以简化代码,匿名内部类会立即创建一个匿名内部类的对象返回,对象类型相当于当前 new 的类的子类类型。匿名内部类一般用于实现事件监听器和其他回调。
class OuterClass{
static class StaticInnerClass {}
class NormalInnerClass {}
public void test() {
class LocalClass {}
// 静态内部类创建对象
new OuterClass.StaticInnerClass();
// 成员内部类创建对象
new OuterClass().new NormalInnerClass();
// 局部内部类创建对象
new LocalClass();
// 匿名内部类创建对象
Runnable runnable = () -> {};
}
}
P9:接口和抽象类
定义类的过程就是抽象和封装的过程,而接口和抽象类则是对实体类进行更高层次的抽象,仅定义公共行为和特征。
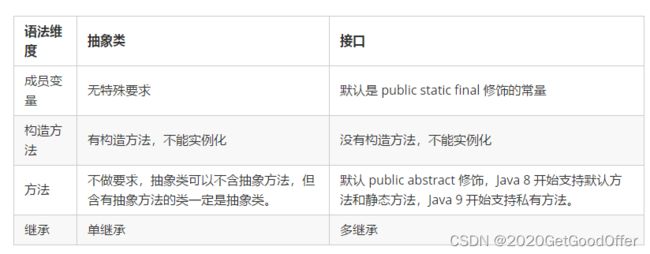
抽象类在被继承时体现的是 is-a 关系,接口在被实现时体现的是 can-do 关系。与接口相比,抽象类通常是对同类事物相对具体的抽象,通常包含抽象方法、实体方法、属性变量。is-a 关系需要符合里氏替换原则,can-do 关系要符合接口隔离原则,实现类要有能力去实现并执行接口定义的行为。例如 Plane 和 Bird 都具有 fly 方法,应该把 fly 定义为一个接口,而不是作为某个抽象类的方法,再利用 is-a 关系去继承抽象类,因为除了 fly 这个行为外,Plane 和 Bird 之间很难找到其他共同特征。
抽象类是模板式设计,包含一组具体的特征,例如某品牌特定型号的汽车,底盘、控制电路、刹车系统等是抽象出来的共同特征,但根据不同级别的配置,内饰,显示屏,座椅材质可以存在不同版本的实现。
接口是契约式设计,是开放的,就像一份合同,定义了方法名、参数、返回值甚至抛出的异常类型,谁都可以实现它,但必须要遵守这个接口的约定。例如所有车辆都必须实现刹车这个强制行为规范。
接口是顶级的类,虽然关键词是 interface,但编译之后的字节码扩展名还是 .class,抽象类在接口下面的第二层,对各个接口进行了组合,然后实现部分接口。当纠结定义接口和抽象类时,推荐定义为接口,遵循接口隔离原则,按某个维度划分成多个接口,然后再利用抽象类去实现这些接口,这样做有利于后续的扩展和重构。
P10:static 关键字
static 关键字主要有两个作用:(1)为某特定数据类型或对象分配单一的存储空间,而与创建对象的个数无关。(2)让某个属性或方法与类而不是对象关联在一起,可以在不创建对象的情况下通过类名来访问。
作用范围
static 修饰的变量称为静态变量,也叫类变量,可以直接通过类名访问,静态变量存储在 JVM 的方法区中。
static 修饰的方法称为静态方法,也叫类方法,可以直接通过类名访问,静态方法只能访问静态变量或静态方法,不能访问实例成员变量和实例方法,也不能使用 this 和 super 关键字,通常用于定义工具类方法。
static 修饰的代码块称为静态代码块,只能定义在类下,在类加载时执行且只会执行一次,通常用于初始化属性和环境配置等。
static 修饰的类称为静态内部类,可以访问外部类的静态变量和方法。
static 也可以用来导入包下的静态变量。
类初始化的顺序
(1)父类静态代码块和静态变量
(2)子类静态代码块和静态变量
(3)父类普通代码块和普通变量
(4)父类构造方法
(5)子类普通代码块和普通变量
(6)子类构造方法
其中代码块和变量的初始化顺序按照类中声明的顺序执行。
P11:序列化和反序列化
Java 对象在 JVM 运行时被创建,当 JVM 退出时存活对象都会销毁,如果需要将对象及其状态持久化,就需要通过序列化来实现,将内存中的对象保存在二进制流中,在需要时再将二进制流反序列化为对象。对象序列化保存的是对象的状态,因此类中的静态变量不会被序列化,因为静态变量是类属性。除了静态变量外,transient 修饰的变量也不会被序列化。transient 的作用就是把这字段的生命周期仅限于内存中而不会写到磁盘里持久化,被 transient 修饰的变量会被设为对应数据类型的默认初始值。
序列化的常用常见是 RPC 框架的数据传输,常见的序列化有三种:
- Java 原生序列化
实现 Serializabale 标记接口,Java 序列化保留了对象类的元数据(如类、成员变量、继承类信息等),以及对象数据等,兼容性最好,但不支持跨语言,性能一般。序列化和反序列化必须保持序列化 ID 的一致,一般使用 private static final long serialVersionUID 定义序列化 ID,如果不设置编译器会根据类的内部实现自动生成该值。如果是兼容升级不应该修改序列化 ID,如果是不兼容升级则需要修改。使用 Java 原生序列化不会调用类的无参构造方法,而是调用本地方法将成员变量赋值为对应类型的初始值,基于性能一般不推荐使用。 - Hessian 序列化
Hessian 序列化是一种支持动态类型、跨语言、基于对象传输的网络协议。Java 对象序列化的二进制流可以被其它语言反序列化。Hessian 协议的特性:① 自描述序列化类型,不依赖外部描述文件或接口定义,用一个字节表示常用基础类型,极大缩短二进制流。② 语言无关,支持脚本语言。③ 协议简单,比 Java 原生序列化高效。Hessian 会把复杂对象所有属性存储在一个 Map 中进行序列化,当父类和子类存在同名成员变量时会先序列化子类,再序列化父类,因此子类值会被父类覆盖。 - JSON 序列化
JSON 是一种轻量级的数据格式,JSON 序列化就是将数据对象转换为 JSON 字符串,在序列化过程中抛弃了类型信息,所以反序列化时只有提供类型信息才能准确进行。相比前两种方式可读性更好,方便调试。
序列化通常会使用网络传输对象,而对象中往往有敏感数据,容易遭受攻击,Jackson 和 fastjson 等都出现过反序列化漏洞,因此有些对象的敏感属性不需要进行序列化传输时应该加上 transient 关键字。如果一定要传递敏感属性可以使用对称与非对称加密方式独立传输,再使用某个方法把属性还原到对象中。
P12:反射
在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法,对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为Java的反射机制。优点是运行时动态获取类的全部信息,缺点是破坏了类的封装性,泛型的约束性。反射是框架的核心灵魂,动态代理设计模式采用了反射机制,还有 Spring、Hibernate 等框架也大量使用到了反射机制。
在程序运行期间,Java 运行时系统始终为所有对象维护一个运行时类型标识,这个信息会跟踪每个对象所属的类,虚拟机利用运行时类型信息选择要执行的正确方法,保存这些信息的类名为 Class。
获取 Class 实例的方法有三种:① 直接通过 类名.class 。②通过对象的 getClass()方法。③通过 Class.forName(类的全限定名)。Class 类中的 getFields、getMethods 和 getConstructors 方法分别返回这个类支持的公共字段、方法和构造方法的数组,其中包括父类的公共成员。Class 类中的 getDeclaredFields、getDeclaredMethods 和 getDeclaredConstructors方法分别返回这个类声明的全部字段、方法和构造方法的数组,其中包括私有成员、包成员和受保护成员,但不包括父类的成员。
Field、Method、Constructor 分别用于描述类的字段、方法和构造方法。这三个类都有一个 getName 方法返回字段、方法或构造方法的名称。Field 类有一个 getType 方法用来返回描述字段类型的一个对象,这个对象的类型也是 Class。Method 和 Constructor 类有报告参数类型的方法,Method 类还有一个报告返回类型的方法。这三个类都有一个 getModifiers 方法,它返回一个整数,用不同的 0/1 位描述所使用的修饰符。
P13:注解
注解是一种标记,可以使类或接口附加额外的信息,是帮助编译器和 JVM 完成一些特定功能的,例如常用注解 @Override 标识一个方法是重写方法。
元注解就是自定义注解的注解,包括:
- @Target:用来约束注解作用的位置,值是枚举类 ElementType 的枚举实例,包括 METHOD 方法、VARIABLE 变量、TYPE 类/接口、PARAMETER 方法参数、CONSTRUCTORS 构造方法和 LOACL_VARIABLE 局部变量等。
- @Rentention:用来约束注解的生命周期,值是 RetentionPolicy 枚举类实例,包括:SOURCE 源码、CLASS 字节码和 RUNTIME 运行时。
- @Documented:表明这个注解应该被 javadoc 工具记录。
- @Inherited:表面某个被标注的类型是被继承的。
P14:异常
所有的异常都是 Throwable 的子类,分为 Error 和 Exception。Error 描述了 Java 运行时系统的内部错误和资源耗尽错误,例如 StackOverFlowException 和 OutOfMemoryException,这种异常程序无法处理。Exception 又分为受检异常和非受检异常,受检异常是需要在代码中显式处理的异常,否则会编译出错,非受检异常是运行时异常,继承自 RuntimeException。
受检异常又可以分为:① 无能为力型,程序无法处理,例如字段超长导致的 SQLException。一般处理的方法是完整保存异常现场,供开发人员解决。② 力所能及型,如发生未授权异常 UnAuthorizedException,程序可跳转至权限申请页面。常见的受检异常还有FileNotFoundException、ClassNotFoundException、IOException等。
非受检异常又可以分为:① 可预测的异常,例如 IndexOutOfBoundsException、NullPointerException 等,这类异常应该提前做好处理。② 需捕捉异常,例如进行 RPC 调用时产生的远程服务超时异常,这类异常是客户端必须显式处理的。③ 可透出异常,主要指框架或系统产生的且会自行处理的异常,而程序无需关心,例如 Spring 中抛出的 NoSuchRequestHandingMethodException,Spring 会自动完成异常处理,默认将抛出的异常自动映射到合适的状态码。
以坐飞机为例,机场地震属于不可抗力,对应了 Error。飞机延误属于受检异常,应对这种异常无能为力,堵车也属于受检异常,应对这种异常可以提前除非或改签。没有带身份证属于可预测的异常,汽车突然抛锚属于需捕捉异常,虽然难以预料但必须处理,检票机器故障属于可透出异常,由机场处理而无需我们关心。
异常处理
抛出异常:遇到异常不进行具体处理,而是将异常抛出给调用者,由调用者根据情况处理。抛出异常有2种形式,一种是 throws 关键字声明抛出的异常,作用在方法上,一种是使用throw 语句直接抛出异常,作用在方法内。
捕获异常:使用 try/catch 进行异常的捕获,try 中发生的异常会被 catch 代码块捕获,根据情况进行处理,如果有 finally 代码块无论是否发生异常都会执行,一般用于释放资源,Java 7 开始可以将资源定义在 try 代码块中自动释放资源。
P15:泛型
泛型的本质是参数化类型,解决不确定具体对象类型的问题。泛型在定义处只具备执行 Object 方法的能力。泛型的好处:① 类型安全,放置的是说明取出来就是什么,不存在 ClassCastException 异常。② 提升可读性,从编码阶段就显式地知道泛型集合、泛型方法等处理的对象类型是什么。③ 代码重用,泛型合并了同类型的处理代码。
类型擦除
虚拟机没有泛型类型对象,所有对象都属于普通类。无论何时定义一个泛型类型,都会自动提供一个相应的原始类型,原始类型的名字就是去掉类型参数后的泛型类型名。类型变量会被擦除,如果没有限定类型就会替换为 Object,如果有限定类型就会替换为第一个限定类型,例如
泛型主要用于编译阶段,在编译后生成的 Java 字节代码文件中不包含泛型中的类型信息。
泛型规范

泛型限定
对泛型上限的限定使用,它表示该通配符所代表的类型是 T 类的子类型或 T 接口的子接口。
对泛型下限的限定使用,它表示该通配符所代表的类型是 T 类的父类型或 T 接口的父接口。
P16:Java 8 新特性
lambda 表达式:lambda 表达式允许把函数作为一个方法的参数传递到方法中,主要用来简化匿名内部类的代码。
函数式接口:使用 @FunctionalInterface 注解标识,有且仅有一个抽象方法,可以被隐式转换为 lambda 表达式。
方法引用:可以直接引用已有类或对象的方法或构造方法,进一步简化 lambda 表达式。方法引用有四种形式:引用构造方法、引用类的静态方法、引用特定类的任意对象方法、引用某个对象的方法。
接口中的方法:接口中可以定义 default 修饰的默认方法,降低了接口升级的复杂性,还可以定义静态方法。
注解:Java 8 引入了重复注解机制,相同的注解在同一个地方可以声明多次。注解的作用范围也进行了扩展,可以作用于局部变量、泛型、方法异常等。
类型推测:加强了类型推测机制,可以使代码更加简洁,例如在定义泛型集合时可以省略对象中的泛型参数。
Optional 类:用来处理空指针异常,提高代码可读性。
Stream 类:把函数式编程风格引入 Java 语言,提供了很多功能,可以使代码更加简洁。方法包括 forEach 遍历、count 统计个数、filter 按条件过滤、limit 取前 n 个元素、skip 跳过前 n 个元素、map 映射加工、concat 合并stream流等。
日期:增强了日期和时间的 API,新的 java.time 包主要包含了处理日期、时间、日期/时间、时区、时刻和时钟等操作。
JavaScript:Java 8 提供了一个新的 JavaScript 引擎,它允许在 JVM上运行特定的 JavaScript 应用。
P17:Java IO
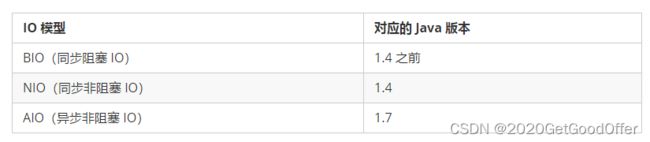
同步和异步是通信机制,阻塞和非阻塞是调用状态。
同步 IO 是用户线程发起 I/O 请求后需要等待或者轮询内核 I/O 操作完成后才能继续执行。
异步 IO 是用户线程发起 I/O 请求后仍可以继续执行,当内核 I/O 操作完成后会通知用户线程,或者调用用户线程注册的回调函数。
阻塞 IO 是指 I/O 操作需要彻底完成后才能返回用户空间 。
非阻塞 IO 是指 I/O 操作被调用后立即返回一个状态值,无需等 I/O 操作彻底完成。
BIO
同步阻塞式 IO,服务器实现模式为一个连接请求对应一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。可以通过线程池机制改善,这种 IO 称为伪异步 IO。
主要分为字符流和字节流,字符流包括字符输入流 Reader 和字符输出流 Writer,字节流包括字节输入流 InputStream 和 字节输出流 OutputStream,字节流和字符流都有对应的缓冲流和过滤流,也可以将字节流包装为字符流。
适用场景:连接数目少、服务器资源多、开发难度低。
NIO
同步非阻塞 IO,服务器实现模式为多个连接请求对应一个线程,客户端发送的连接请求都会注册到一个多路复用器 Selector 上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理,有数据才会开启线程处理,性能比较好。
同步是指线程还是要不断接收客户端连接并处理数据,非阻塞是指如果一个管道没有数据,不需要等待,可以轮询下一个管道。
有三个核心组件:
Selector
选择器或多路复用器,主要作用是轮询检查多个 Channel 的状态,判断 Channel 注册的事件是否发生,即判断 Channel 是否处于可读或可写状态。在使用之前需要将 Channel 注册到 Selector 上,注册之后会得到一个 SelectionKey,通过 SelectionKey 可以获取 Channel 和 Selector 的相关信息。
Channel
双向通道,替换了 IO 中的 Stream,不能直接访问数据,要通过 Buffer 来读写数据,也可以和其他 Channel 交互。
FileChannel 处理文件、DatagramChannel 处理 UDP 数据、SocketChannel 处理 TCP 数据,用作客户端、ServerSocketChannel 处理 TCP 数据,用作服务器端。
Buffer
缓冲区,本质是一块可读写数据的内存,这块内存被包装成 NIO 的 Buffer 对象,用来简化数据的读写。Buffer 的三个重要属性:position 表示下一次读写数据的位置,limit 表示本次读写的极限位置,capacity 表示最大容量。
- flip() 将写转为读,底层实现原理是把 position 置 0,并把 limit 设为当前的 position 值。
- 通过 clear() 将读转为写模式(用于读完全部数据的情况,把 position 置 0,limit 设为 capacity)。
- 通过 compact() 将读转为写模式(用于没有读完全部数据,存在未读数据的情况,让 position 指向未读数据的下一个)。
- 通道的方向和 Buffer 的方向是相反的,读取数据相当于向 Buffer 写入,写出数据相当于从 Buffer 读取。
使用步骤:向 Buffer 写入数据,调用 flip 方法将 Buffer 从写模式切换为读模式,从 Buffer 中读取数据,调用 clear 或 compact 方法来清空 Buffer。
适应场景:连接数目多、连接时间短、开发难度高。
AIO
异步非阻塞 IO,服务器实现模式为一个有效请求对应一个线程,客户端的 I/O 请求都是由操作系统先完成 IO 操作后再通知服务器应用来启动线程直接使用数据。
异步是指服务端线程接收到客户端管道后就交给底层处理IO通信,自己可以做其他事情,非阻塞是指客户端有数据才会处理,处理好再通知服务器。
AsynchronousServerSocketChannel 异步服务器端通道,通过静态方法 open() 获取实例,通过 accept 方法获取客户端连接通道。
AsynchronousSocketChannel 异步客户端通道,通过静态方法 open() 获取实例,过 connect 方法连接服务器通道。
AsynchronousChannelGroup 异步通道分组管理器,它可以实现资源共享。创建时需要传入一个ExecutorService,也就是绑定一个线程池,该线程池负责两个任务:处理 IO 事件和触发 CompletionHandler 回调接口。
实现方式:
通过 Future 的 get 方法进行阻塞式调用。
通过实现 CompletionHandler 接口,重写请求成功的回调方法 completed() 和 请求失败回调方法 failed()。
适用场景:连接数目多、连接时间长、开发难度高。
P18:List
List 集合是线性数据结构的主要实现,集合元素通常存在明确的前驱和后继元素以及首尾元素。List 集合的遍历结果是稳定的,最常用的是 ArrayList 和 LinkedList。
ArrayList
ArrayList 是容量可以改变的非线程安全集合,内部使用数组进行存储,集合扩容时会创建更大的数组空间,把原有数组复制到新数组中。ArrayList 支持对元素的快速随机访问,但是插入与删除时速度通常很慢。ArrayList 实现了 RandomAcess 标记接口,如果一个类实现了该接口,那么表示这个类使用索引遍历比迭代器更快。
三个重要的成员变量:
- elementData:ArrayList 的数据域,被 transient 修饰,表示在类的序列化时被忽视,集合序列化时会调用 writeObject 写入流中,在网络客户端反序列化的 readObject 中会重新赋值到新对象的 elementData 中。之所以这样做的原因是 elementData 容量通常会大于实际存储元素的数量,所以只需发送真正有实际值的数组元素即可。
- size:表示当前实际大小,elementData 的大小是大于等于 size 的。
- modCount:继承自 AbstractList,记录了结构性变化的次数,所有涉及结构变化的方法都会增加该值。expectedModCount 是在迭代器初始化时记录的 modCount 值,每次访问新元素时都会检查 modCount 和 expectedModCount 是否相等,如果不相等就会抛出异常。这种机制叫做 fail-fast,所有集合类都有这种机制。
可以使用线程安全的 CopyOnWriteArrayList 代替 ArrayList,它实现了读写分离。如果是写操作则复制一个新的集合,在新集合内添加或删除元素,待修改完成之后再将原集合的引用指向新集合。这样做的好处是可以高并发地进行读写操作而不需要加锁,因为当前集合不会添加任何元素。使用时注意尽量设置容量初始值,避免多次扩容,并且可以使用批量添加或删除,比如只增加一个元素却复制整个集合。CopyOnWriteArrayList 适合读多写少的场景,单个添加时效率极低。CopyOnWriteArrayList 是 fail-safe 的,并发包的集合都是这种机制,fail-safe 是在安全的副本上进行遍历,集合修改与副本的遍历没有任何关系,但缺点就是无法读取到最新的数据。这也是 CAP 理论中 C 和 A 的矛盾,即一致性与可用性的矛盾。
LinkedList
LinkedList 本质是双向链表,与 ArrayList 相比插入和删除速度更快,但是随机访问元素则很慢。除了继承自 AbstractList 外,它还实现了 Deque 接口,这个接口同时具有队列和栈的性质。成员变量被 transient 修饰,序列化原理和 ArrayList 类似。
LinkedList 包含三个重要的成员:size、first 和 last。size 是双向链表中节点的个数。first 和 last 分别指向首尾节点的引用。
LinkedList 的优点在于可以将零散的内存单元通过附加引用的方式关联起来,形成按链路顺序查找的线性结构,内存利用率较高。
Vector 和 Stack
Vector 的实现和 ArrayList 基本一致,底层使用的也是数组,它和 ArrayList 的区别主要在于:① Vector 的所有公有方法都使用了 synchronized 修饰保证线程安全性。② 增长策略不同,Vector 多了一个成员变量 capacityIncrement 用于标明扩容的增量。
Stack 是 Vector 的子类,实现和 Vector基本一致,与之相比多提供了一些方法表达栈的含义。
P19:Set
Set 是不允许出现重复元素的集合类型,常用的是 HashSet、TreeSet 和 LinkedHashSet。
HashSet 的是通过 HashMap 实现的,HashMap 的 Key 值即 HashSet 存储的元素,所有 Key 都使用相同的 Value ,一个 static final 修饰的变量名为 PRESENT 的 Object 类型的对象。使用 Key 保证集合元素的唯一性,但它不保证集合元素的有序性。由于 HashSet 的底层是 HashMap 实现的,HashMap 是线程不安全的,因此 HashSet 也是线程不安全的。
HashSet 判断元素是否相同时,对于基本类型的包装类,直接按值进行比较。对于引用数据类型,会先比较 hashCode 返回值是否相同,如果不同则代表不是同一个对象,如果相同则继续比较 equals 方法返回值是否相同,都相同说明是同一个对象。
TreeSet 的是使用 TreeMap 实现的,底层为树结构,在添加新元素到集合中时,按照某种比较规则将其插入合适的位置,保证插入后的集合仍然是有序的。LinkedHashSet 继承自 HashSet,内部使用链表维护了元素插入的顺序。
P20:红黑树
AVL 树是一种平衡二叉查找树,增加和删除节点后通过树形旋转重新达到平衡。右旋是以某个节点为中心,将它沉入当前右子节点的位置,而让当前的左子节点作为新树的根节点,也称为顺时针旋转。同理左旋是以某个节点为中心,将它沉入当前左子节点的位置,而让当前的右子节点作为新树的根节点,也称为逆时针旋转。
红黑树是 1972 年发明的,当时称为对称二叉 B 树,1978 年正式命名为红黑树,它的主要特征是在每个节点上增加一个属性来表示节点的颜色,可以是红色也可以是黑色。红黑树和 AVL 树类似,都是在进行插入和删除元素时,通过特定的旋转来保持自身平衡的,从而获得较高的查找性能。与 AVL 树相比,红黑树不追求所有递归子树的高度差不超过 1,而是保证从根节点到叶尾的最长路径不超过最短路径的 2 倍,所以它的最差时间复杂度也是 O(logn)。红黑树通过重新着色和左右旋转,更加高效地完成了插入和删除之后的自平衡调整。
红黑树在本质上还是二叉查找树,它额外引入了 5 个约束条件:① 节点只能是红色或黑色。② 根节点必须是黑色。③ 所有 NIL 节点都是黑色的。④ 一条路径上不能出现相邻的两个红色节点。⑤ 在任何递归子树中,根节点到叶子节点的所有路径上包含相同数目的黑色节点。这五个约束条件保证了红黑树的新增、删除、查找的最坏时间复杂度均为 O(logn)。如果一个树的左子节点或右子节点不存在,则均认定为黑色。红黑树的任何旋转在 3 次之内均可完成。
红黑树的平衡性不如 AVL 树,它维持的只是一种大致的平衡,并不严格保证左右子树的高度差不超过 1。这导致节点数相同的情况下,红黑树的高度可能更高,也就是说平均查找次数会高于相同情况的 AVL 树。在插入时,红黑树和 AVL 树都能在至多两次旋转内恢复平衡,在删除时由于红黑树只追求大致平衡,因此红黑树至多三次旋转可以恢复平衡,而 AVL 树最多需要 O(logn) 次。AVL 树在插入和删除时,将向上回溯确定是否需要旋转,这个回溯的时间成本最差为 O(logn),而红黑树每次向上回溯的步长为 2,回溯成本低。因此面对频繁地插入与删除红黑树更加合适。
P21:TreeMap
基于红黑树实现的 TreeMap 提供了平均和最差时间复杂度均为 O(logn) 的增删改查操作,该集合最大的特点就是 Key 的有序性。TreeMap 继承了 SortedMap 和 NavigableMap,SortedMap 表示 Key 是有序不可重复的,支持获取头尾 Key-Value 元素,或者根据 Key 指定范围获取子集合等。插入的 Key 必须实现 Comparable 接口或提供额外的 Comparator 比较器,所以 Key 不允许为 null。NavigableMap 继承了 SortedMap,根据指定的搜索条件返回最匹配的 Key-Value 元素。
不同于 HashMap 的是 TreeMap 并非一定要重写 hashCode 和 equals 方法来达到 Key 去重的目的。HashMap 是依靠 hashCode 和 equals 来去重的,而 TreeMap 依靠 Comparable 或 Comparator 来实现去重。 TreeMap 对 Key 进行排序时,如果比较器不为空就会优先使用比较器的 compare 方法,如果比较器为空就会使用 Key 实现的自然排序 Comparable 接口的 compareTo 方法,如果两者都不满足就会抛出异常。
TreeMap 通过 put 和 deleteEntry 实现红黑树增加和删除节点的操作。插入新节点的规则有三个:① 需要调整的新节点总是红色的。② 如果插入新节点的父节点是黑色的,不需要调整。③ 如果插入新节点的父节点是红色的,由于红黑树中不能出现相邻的红色,则进入循环判断,通过重新着色或左右旋转来调整。TreeMap 的插入操作就是按照 Key 的对比往下遍历,大于比较节点值的向右查找,小于的向左查找,先按照二叉查找树的特性操作,无需关心节点颜色与树的平衡,后续会重新着色和旋转,保持红黑树的特性。
TreeMap 是线程不安全的集合,在多线程操作时需要添加互斥机制,或者把对象放在 Collections.synchronizedMap() 中实现同步。在 JDK 7 之后的 HashMap、TreeSet、ConcurrentHashMap 也都是使用红黑树的方式管理节点。如果只是对单个元素进行排序,使用 TreeSet 即可。TreeSet 的底层就是 TreeMap,Value 共享一个静态的 Object 对象。
P22:HashMap
JDK 8 之前
底层实现是数组 + 链表,主要成员变量包括:存储数据的 table 数组、键值对数量 size、加载因子 loadFactor。
table 数组用于记录 HashMap 的所有数据,它的每一个下标都对应一条链表,所有哈希冲突的数据都会被存放到同一条链表中,Entry 是链表的节点元素,包含四个成员变量:键 key、值 value、指向下一个节点的指针 next 和元素的散列值 hash。
在 HashMap 中数据都是以键值对的形式存在的,键对应的 hash 值将会作为其在数组里的下标,如果两个元素 key 的 hash 值一样,就会发送哈希冲突,被放到同一个下标中的链表上,为了使 HashMap 的查询效率尽可能高,应该使键的 hash 值尽可能分散。
HashMap 默认初始化容量为 16,扩容容量必须是 2 的幂次方、最大容量为 1<< 30 、默认加载因子为 0.75。
1.put 方法:添加元素
① 如果 key 为 null 值,直接存入 table[0]。② 如果 key 不为 null 值,先计算 key 对应的散列值。③ 调用 indexFor 方法根据 key 的散列值和数组的长度计算元素存放的下标 i。④ 遍历 table[i] 对应的链表,如果 key 已经存在,就更新其 value 值然后返回旧的 value 值。⑤ 如果 key 不存在,就将 modCount 的值加 1,使用 addEntry 方法增加一个节点,并返回 null 值。
2.hash 方法:计算元素 key 对应的散列值
① 处理 String 类型的数据时,直接调用对应方法来获取最终的hash值。② 处理其他类型数据时,提供一个相对于 HashMap 实例唯一不变的随机值 hashSeed 作为计算的初始量。③ 执行异或和无符号右移操作使 hash 值更加离散,减小哈希冲突的概率。
3.indexFor 方法:计算元素下标
直接将 hash 值和数组长度 - 1 进行与操作并返回,保证计算后的结果不会超过 table 数组的长度范围。
4.resize 方法:根据 newCapacity 来确定新的扩容阈值 threshold
① 如果当前容量已经达到了最大容量,就将阈值设置为 Integer 的最大值,之后扩容就不会再触发。② 创建一个新的容量为 newCapacity 的 Entry 数组,并调用 transfer 方法将旧数组的元素转移到新数组.③ 将阈值设为 newCapacity x loadFactor 和 最大容量 + 1 的较小值。
5.transfer:转移旧数组到新数组
① 遍历旧数组的所有元素,调用 rehash 方法判断是否需要哈希重构,如果需要就重新计算元素 key 的散列值。② 调用 indexFor 方法根据 key 的散列值和数组的长度计算元素存放的下标 i,利用头插法将旧数组的元素转移到新的数组。
6.get 方法:根据 key 获取元素的 value 值
① 如果 key 为 null 值,调用 getForNullKey 方法,如果 size 为 0 表示链表为空,返回 null 值。如果 size 不为 0,说明存在链表,遍历 table[0] 的链表,如果找到了 key 为 null 的节点则返回其 value 值,否则返回 null 值。
② 调用 getEntry 方法,如果 size 为 0 表示链表为空,返回 null 值。如果 size 不为 0,首先计算 key 的散列值,然后遍历该链表的所有节点,如果节点的 key 值和 hash 值都和要查找的元素相同则返回其 Entry 节点。
③ 如果找到了对应的 Entry 节点,调用 getValue 方法获取其 value 值并返回,否则返回 null 值。
JDK 8 开始
使用的是数组 + 链表/红黑树的形式,table 数组的元素数据类型换成了 Entry 的静态实现类 Node。
1.put 方法:添加元素
① 调用 putVal 方法添加元素。
② 如果 table 为空或没有元素时就进行扩容,否则计算元素下标位置,如果不存在就新创建一个节点存入。
③ 如果首节点和待插入元素的 hash值和 key 值都一样,直接更新 value 值。
④ 如果首节点是 TreeNode 类型,调用 putTreeVal 方法增加一个树节点,每一次都比较插入节点和当前节点的大小,待插入节点小就往左子树查找,否则往右子树查找,找到空位后执行两个方法:balanceInsert 方法,把节点插入红黑树并对红黑树进行调整使之平衡; moveRootToFront 方法,由于调整平衡后根节点可能变化,table 里记录的节点不再是根节点,需要重置根节点。
⑤ 如果是链表节点,就遍历链表,根据 hash 值和 key 值判断是否重复,决定更新值还是新增节点。如果遍历到了链表末尾,添加链表元素,如果达到了建树阈值,还需要调用 treeifyBin 方法把链表重构为红黑树。
⑥ 存放元素后,将 modCount 值加 1,如果 节点数 + 1 大于扩容阈值,还需要进行扩容。
2.get 方法:根据 key 获取元素的 value 值
① 调用 getNode 方法获取 Node 节点,如果不是 null 值就返回 Node 节点的 value 值,否则返回 null。
② 如果数组不为空,先比较第一个节点和要查找元素的 hash 值和 key 值,如果都相同则直接返回。
③ 如果第二个节点是 TreeNode 节点则调用 getTreeNode 方法进行查找,否则遍历链表根据 hash 值和 key 值进行查找,如果没有找到就返回 null。
3.hash 方法:计算元素 key 对应的散列值
Java 8 的计算过程简单了许多,如果 key 非空就将 key 的 hashCode() 返回值的高低16位进行异或操作,这主要是为了让尽可能多的位参与运算,让结果中的 0 和 1 分布得更加均匀,从而降低哈希冲突的概率。
4.resize 方法:扩容数组
重新规划长度和阈值,如果长度发生了变化,部分数据节点也要重新排列。
重新规划长度
① 如果 size 超出扩容阈值,把 table 容量增加为之前的2倍。
② 如果新的 table 容量小于默认的初始化容量16,那么将 table 容量重置为16。
③ 如果新的 table 容量大于等于最大容量,那么将阈值设为 Integer 的最大值,并且 return 终止扩容,由于 size 不可能超过该值因此之后不会再发生扩容。
重新排列数据节点
① 如果节点为 null 值则不进行处理。
② 如果节点不为 null 值且没有next节点,那么重新计算其散列值然后存入新的 table 数组中。
③ 如果节点为 TreeNode 节点,那么调用 split 方法进行处理,该方法用于对红黑树调整,如果太小会退化回链表。
④ 如果节点是链表节点,需要将链表拆分为 hashCode() 返回值超出旧容量的链表和未超出容量的链表。对于hash & oldCap == 0 的部分不需要做处理,反之需要放到新的下标位置上,新下标 = 旧下标 + 旧容量。
线程安全
Java 7 的 HashMap 存在死循环和数据丢失问题。
并发赋值被覆盖:在 createEntry 方法中,新添加的元素直接放在头部,使得新添加的元素在下次提取时可以更快被访问到,但是如果两个线程如果同时执行到此处,就会导致其中一个线程的赋值被覆盖,这是数据丢失的原因之一。
已遍历区间新增元素丢失:当某个线程在 transfer 方法迁移时,其他线程新增的元素可能落在已经遍历过的哈希槽上。在遍历完成后,table 数组引用指向了 newTable,这时新增元素就会丢失,被垃圾收集器回收。
新表被覆盖:如果扩容完成,执行了 table = newTable,则后续的元素就可以在新表上进行插入操作。但是如果多线程同时扩容,每个线程又都会 new 一个数组对象,这是线程内的局部数组对象,线程之间不可见。迁移完成后,resize 线程会赋值给 table,从而覆盖其他线程的操作,因此在新表中进行插入操作的对象都会被丢弃。
扩容时 resize 方法调用的 transfer 方法中使用头插法迁移元素,虽然 newTable 是局部变量,但是原先 table 中的 Entry 链表是共享的,产生问题的根源是 Entry 的 next 指针被并发修改,这可能导致数据丢失、两个对象互链或者对象自己互链,形成环路的原因是两个线程都执行完第一个节点的遍历操作后,到第二个节点时产生互链。
JDK 8 的 HashMap 在 resize 方法中完成扩容,并且改用了尾插法,不会产生死循环的问题,但是在多线程的情况下还是可能会导致数据覆盖的问题,因此依旧线程不安全。可以使用 ConcurrentHashMap 代替或者 Collections.synchronizedMap 包装成同步集合。
JVM 15
P1:运行时数据区
程序计数器
程序计数器是一块较小的内存空间,可以看作当前线程所执行字节码的行号指示器。字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,它是程序控制流的指示器,分支、循环、跳转、线程恢复等功能都需要依赖计数器完成。程序计数器是线程私有的,各条线程之间互不影响。
如果线程正在执行的是一个 Java 方法,计数器记录的是正在执行的虚拟机字节码指令的地址。如果正在执行的是本地(Native)方法,计数器值则应为空(Undefined)。
此区域是唯一在虚拟机规范中没有规定任何内存溢出情况的区域。
Java 虚拟机栈
Java 虚拟机栈是线程私有的,用来描述 Java 方法的内存模型。每当有新的线程创建时就会给它分配一个栈空间,当线程结束后栈空间就被回收,因此栈与线程拥有相同的生命周期。栈中的元素用于支持虚拟机进行方法调用,每个方法在执行的时候都会创建一个栈帧用来存储这个方法的局部变量表、操作栈、动态链接和方法出口等信息。每个方法从开始调用到执行完成的过程,就是栈帧从入栈到出栈的过程。在活动线程中,只有位于栈顶的帧才是有效的,称为当前栈帧。
该区域有两类异常情况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常。如果 JVM 栈容量可以动态扩展,当栈扩展时无法申请到足够的内存会抛出 OutOfMemoryError 异常(HotSpot 不可以动态扩展,不存在此问题)。
本地方法栈
本地方法栈与虚拟机栈的作用相似,不同的是虚拟机栈为虚拟机执行 Java 方法(字节码)服务,而本地方法栈是为虚拟机栈用到的本地(Native)方法服务。调用本地方法时虚拟机栈保持不变,动态链接并直接调用指定的本地方法。
虚拟机规范对本地方法栈中方法所用语言、使用方式与数据结构无强制规定,具体的虚拟机可根据需要自由实现,例如 HotSpot 直接将虚拟机栈和本地方法栈合二为一。
与虚拟机栈一样,本地方法栈也会在栈深度异常和栈扩展失败时分别抛出 StackOverflowError 和 OutOfMemoryError 异常。
Java 堆
堆是虚拟机所管理的内存中最大的一块,是被所有线程共享的,在虚拟机启动时创建。堆用来存放对象实例,Java 里几乎所有的对象实例都在这里分配内存。堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的。但对于大对象(例如数组),多数虚拟机实现出于简单、存储高效的考虑会要求连续的内存空间。
堆既可以被实现成固定大小的,也可以是可扩展的,可以通过 -Xms 和 -Xmx 设置堆的最小和最大容量,当前主流的 JVM 都是按照可扩展来实现的。如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,虚拟机将抛出 OutOfMemoryError 异常。
方法区
方法区和 Java 堆一样是各个线程共享的内存区域,它用于存储被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
JDK 8 之前使用永久代来实现方法区,这种设计导致了容易发生内存溢出,因为永久代有 -XX:MaxPermSize的上限,即使不设置也有默认大小。JDK 7 时把原本放在永久代的字符串常量池、静态变量等移出,到了 JDK8 时永久代被完全废弃,改用在本地内存中实现的元空间代替,把 JDK 7 中永久代剩余内容(主要是类型信息)全部移到元空间。
虚拟机规范对方法区的约束很宽松,除了和堆一样不需要连续内存和可以选择固定大小/可扩展外,还可以不实现垃圾回收。垃圾回收在该区域出现较少,主要目标针对常量池和类型卸载。如果方法区无法满足新的内存分配需求,将抛出 OutOfMemoryError 异常。
运行时常量池
运行时常量池是方法区的一部分,Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表,用于存放编译器生成的各种字面量与符号引用,这部分内容将在类加载后存放到运行时常量池。一般来说,除了保存 Class 文件中描述的符号引用外,还会把符号引用翻译出来的直接引用也存储在运行时常量池中。
运行时常量池相对于 Class 文件常量池的一个重要特征是具备动态性,Java 并不要求常量一定只有编译期才能产生,也就是说并非预置入 Class 文件常量池的内容才能进入方法区运行时常量池,运行期间也可以将新的常量放入池中,例如 String 类的 intern 方法。
由于运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 异常。
直接内存
直接内存不是运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但这部分内存被频繁使用,而且可能导致内存溢出。
JDK 1.4 中新加入了 NIO 模型,引入了一种基于通道与缓冲区的 IO 方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆里的 DirectByteBuffer 对象作为这块内存的引用进行操作,能在一些场景中显著提高性能,避免了在 Java 堆和 Native堆中来回复制数据。
直接内存的分配不会受到 Java 堆大小的限制,但还是会受到本机总内存大小以及处理器寻址空间的限制,一般配置虚拟机参数时会根据实际内存设置 -Xmx 等参数信息,但经常忽略掉直接内存,使各个内存区域总和大于物理内存限制,导致动态扩展时出现 OOM 异常。
P2:对象创建的过程
字节码角度
- NEW:如果找不到 Class 对象则进行类加载。加载成功后在堆中分配内存,从 Object 到本类路径上的所有属性值都要分配内存。分配完毕后进行零值设置。这个指令完成后,将指向实例对象的引用变量压入虚拟机栈顶。
- DUP:在栈顶复制该引用变量,这时栈顶有两个指向堆内实例的引用变量。如果 init 方法有参数还需要把参数压入操作栈中。两个引用变量的目的不同,栈底的引用用于赋值或保存到局部变量表,栈顶的引用作为句柄调用相关方法。
- INVOKESPECIAL:通过栈顶的引用变量调用 init 方法。
执行角度
当 JVM 遇到一条字节码 new 指令时,首先将检查该指令的参数能否在常量池中定位到一个类的符号引用,并检查这个引用代表的类是否已被加载、解析和初始化,如果没有就必须先执行类加载。
在类加载检查通过后虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定,分配空间的任务实际上等于把一块确定大小的内存块从 Java 堆中划分出来。假设 Java 堆内存是规整的,被使用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界指示器,分配内存就是把该指针向空闲方向挪动一段与对象大小相等的距离,这种方式叫"指针碰撞"。
如果 Java 堆中的内存不是规整的,那么虚拟机就必须维护一个列表记录哪些内存块可用,在分配时从列表中找到一块足够大的空间划分给对象实例并更新列表上的记录,这种方式叫做"空闲列表"。
选择哪种分配方式由堆是否规整决定,堆是否规整又由所用垃圾回收器是否带有空间压缩整理能力决定。因此使用 Serial、ParNew 等带压缩整理的收集器时,系统采用指针碰撞;当使用 CMS 这种基于清除算法的垃圾收集器时,采用空间列表。
对象创建十分频繁,即使修改一个指针的位置在并发情况下也不是线程安全的,可能出现正给对象 A 分配内存,指针还没来得及修改,对象 B 又同时使用了指针来分配内存的情况。解决该问题有两个方法:① 采用 CAS 加失败重试保证更新操作的原子性。② 把内存分配的动作按照线程划分在不同空间进行,即每个线程在 Java 堆中预先分配一小块内存,叫做本地线程分配缓冲 TLAB,哪个线程要分配内存就在对应的 TLAB 分配,只有 TLAB 用完了才需要同步。
内存分配完成后虚拟机必须将成员变量设定为零值,保证对象的实例字段可以不赋初始值就直接使用。
初始化为零值后,设置对象头,包括哈希码、GC 信息、锁信息、对象所属类的类元信息等。
最后执行 init 方法,初始化成员变量,执行实例化代码块,调用类的构造方法,并把堆内对象的首地址赋值给引用变量。
P3:对象的内存布局
在 HotSpot 虚拟机中,对象在堆内存中的存储布局可分为三个部分。
对象头
对象头占用 12B,存储内容包括对象标记和类元信息。对象标记存储对象本身的运行时数据,如哈希码、GC 标记、锁信息、线程关联信息等,这部分数据在 64 位 JVM 上占用 8B,称为"Mark Word"。为了存储更多的状态信息,对象标记的存储格式是不固定的,与具体 JVM 实现有关。
类元信息存储的是对象指向它的类元数据的首地址,占用 4B。JVM 通过该指针来确定对象是哪个类的实例。并非所有虚拟机实现都必须在对象数据上保留类型指针,查找对象的元数据不一定要经过对象本身。此外如果对象是一个 Java 数组,在对象头还必须有一块用于记录数组长度的数据。
实例数据
实例数据是对象真正存储的有效信息,即本类对象的实例成员变量和所有可见的父类成员变量。存储顺序会受到虚拟机分配策略参数和字段在源码中定义顺序的影响。相同宽度的字段总是被分配到一起存放,在满足该前提条件的情况下父类中定义的变量会出现在子类之前。
对齐填充
这部分不是必然存在的,仅起占位符的作用。由于 HotSpot 虚拟机的自动内存管理系统要求对象的起始地址必须是 8 字节的整数倍,而对象头已经被设为正好是 8 字节的整数倍,因此如果对象实例数据部分没有对齐,就需要对齐填充来补全。
P4:对象的访问定位
Java 程序会通过栈上的 reference 数据来操作堆上的具体对象,而具体对象访问方式是由虚拟机决定的,主流的访问方式主要有使用句柄和直接指针两种。
使用句柄
如果使用句柄访问,Java 堆中将可能会划分出一块内存作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自具体的地址信息。
优点是 reference 中存储的是稳定句柄地址,在对象被移动(处于垃圾收集过程中)时只会改变句柄中的实例数据指针,而 reference 本身不需要被修改。
直接指针
如果使用直接指针访问的话,Java 堆中对象的内存布局就必须考虑如何放置访问类型数据的相关信息,reference中存储的直接就是对象地址,如果只是访问对象本身的话就不需要多一次间接访问的开销。
优点就是速度更快,节省了一次指针定位的时间开销,HotSpot 主要使用的就是直接指针来进行对象访问。
P5:内存溢出异常
Java 堆溢出
Java 堆用于存储对象实例,我们只要不断创建对象,并且保证GC Roots到对象有可达路径来避免垃圾回收机制清除这些对象,那么随着对象数量的增加,总容量触及最大堆容量的限制后就会产生OOM异常。例如在 while 死循环中一直 new 创建实例。
Java 堆内存的 OOM 是实际应用中最常见的 OOM 情况,常规的处理方法是先通过内存映像分析工具对 Dump 出来的堆转储快照进行分析,确认内存中导致 OOM 的对象是否是必要的,即分清楚到底是出现了内存泄漏还是内存溢出。
如果是内存泄漏,可进一步通过工具查看泄漏对象到 GC Roots 的引用链,找到泄露对象是通过怎样的引用路径、与哪些GC Roots相关联才导致垃圾收集器无法回收它们,一般可以准确定位到对象创建的位置进而找出产生内存泄漏代码的具体位置。
如果不是内存泄漏,即内存中的对象确实都是必须存活的那就应当检查 JVM 的堆参数设置,与机器的内存相比是否还有向上调整的空间。再从代码上检查是否存在某些对象生命周期过长、持有状态时间过长、存储结构设计不合理等情况,尽量减少程序运行期的内存消耗。
虚拟机栈和本地方法栈溢出
由于HotSpot虚拟机不区分虚拟机和本地方法栈,因此设置本地方法栈大小的参数没有意义,栈容量只能由 -Xss 参数来设定,存在两种异常:
-
StackOverflowError:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常。例如一个递归方法不断调用自己。
该异常有明确错误堆栈可供分析,容易定位到问题所在。 -
OutOfMemoryError:如果 JVM 栈容量可以动态扩展,当栈扩展时无法申请到足够的内存会抛出OutOfMemoryError异常。HotSpot 虚拟机不支持虚拟机栈的扩展,所以除非在创建线程申请内存时就因无法获得足够内存而出现OOM异常,否则在线程运行时是不会因为扩展而导致内存溢出的,只会因为栈容量无法容纳新的栈帧而导致StackOverflowError异常。
运行时常量池溢出
String 类的 intern 方法是一个本地方法,作用是如果字符串常量池中已经包含一个等于此 String 对象的字符串,则返回代表池中这个字符串的 String 对象的引用,否则将此 String 对象包含的字符串添加到常量池并返回此 String 对象的引用。
在 JDK 6 及之前常量池都分配在永久代,因此可以通过 -XX:PermSize 和 -XX:MaxPermSize 限制永久代大小,间接限制常量池。在 while 死循环中不断调用 intern 方法导致运行时常量池溢出。
在 JDK 7 及之后不会出现该问题,因为存放在永久代的字符串常量池已经被移至 Java 堆中。
方法区溢出
方法区的主要职责是存放类型信息,如类名、访问修饰符、常量池、字段描述、方法描述等。只要不断在运行时产生大量的类去填满方法区,就会导致溢出。例如使用 JDK 反射或 CGLib 直接操作字节码在运行时生成大量的类。当前的很多主流框架如 Spring、Hibernate 等对类增强时都会使用 CGLib 这类字节码技术,增强的类越多就需要越大的方法区保证动态生成的新类型可以载入内存,也就更容易导致方法区溢出。
JDK 8 之后永久代完全被废弃,取而代之的是元空间,HotSpot 提供了一些参数作为元空间的防御措施:
-XX:MaxMetaspaceSize:设置元空间的最大值,默认 -1,表示不限制即只受限于本地内存大小。
-XX:MetaspaceSize:指定元空间的初始大小,以字节为单位,达到该值就会触发垃圾收集进行类型卸载,同时收集器会对该值进行调整:如果释放了大量空间就适当降低该值,如果释放了很少的空间就适当提高该值。
-XX:MinMetaspaceFreeRatio:作用是在垃圾收集之后控制最小的元空间剩余容量百分比,可减少因为元空间不足导致的垃圾收集的频率。类似的还有-XX:MinMetaspaceFreeRatio,用于控制最大的元空间剩余容量百分比。
本机直接内存溢出
直接内存的容量大小可通过 -XX:MaxDirectMemorySize 指定,如果不指定则默认与 Java 堆的最大值一致。
由直接内存导致的内存溢出,一个明显的特征是在 Heap Dump 文件中不会看见明显的异常,如果发现内存溢出后产生的 Dump 文件很小,而程序中又直接或间接使用了直接内存(典型的间接使用就是 NIO),那么就可以考虑检查直接内存方面的原因。
P6:判断对象是否是垃圾
在堆中存放着所有对象实例,垃圾收集器在对堆进行回收前,首先要判断对象是否还存活着。
引用计数算法
在对象中添加一个引用计数器,如果有一个地方引用它计数器就加1,引用失效时计数器就减1,如果计数器为0则该对象就是不再被使用的。该算法原理简单,效率也高,但是在 Java中很少使用,因为它存在对象之间互相循环引用的问题,导致计数器无法清零。
可达性分析算法
当前主流语言的内存管理子系统都是使用可达性分析算法来判断对象是否存活的。这个算法的基本思路就是通过一系列称为 GC Roots 的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为引用链,如果某个对象到 GC Roots之间没有任何引用链相连,则此对象是不可能再被使用的。
可作为GC Roots的对象包括虚拟机栈中引用的对象、方法区中类静态属性引用的对象、方法区中常量引用的对象、本地方法栈中引用的对象等。
P7:引用类型
无论通过引用计数还是可达性分析判断对象是否存活,都和引用离不开关系。在 JDK1.2 之前引用的定义是:如果 reference 类型数据存储的数值代表另外一块内存的起始地址,那么就称该 reference 数据是代表某块内存、某个对象的引用。在 JDK 1.2之后 Java 对引用的概念进行了扩充,按强度分为四种:
强引用:最常见的引用,例如 Object obj = new Object 这样的变量声明和定义就会产生对该对象的强引用。只要对象有强引用指向,并且 GC Roots 可达,那么进行内存回收时即使濒临内存耗尽也不会回收该对象。
软引用:弱于强引用,描述非必需对象。在系统将要发生内存溢出异常前,会把软引用关联的对象加入回收范围以获得更多的内存空间。主要用来缓存服务器中间计算结果及不需要实时保存的用户行为等。
弱引用:弱于软引用,描述非必需对象。被弱引用关联的对象只能生存到下一次 YGC 之前,当垃圾收集器开始工作时无论当前内存是否足够都会回收只被弱引用关联的对象。由于 YGC 具有不确定性,因此弱引用何时被回收也有不确定性。
虚引用:是最弱的引用关系,定义完成后就无法通过该引用获取指向的对象。一个对象是否有虚引用存在,完全不会对其生存时间造成影响。该引用的唯一目的就是为了能在这个对象被垃圾收集器回收时收到一个系统通知。虚引用必须与引用队列联合使用,当垃圾回收时如果出现虚引用,就会在回收对象内存之前把这个虚引用加入关联的引用队列。
P8:GC 算法
标记-清除算法
- 原理:分为标记和清除两个阶段,首先从每个 GC Roots 出发依次标记有引用关系的对象,最后将没有被标记的对象清除。
- 特点:① 执行效率不稳定,如果堆中包含大量对象且其中大部分是需要被回收的,这时必须进行大量标记和清除,导致效率随对象数量增长而降低。② 内存空间碎片化问题,会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行中需要分配较大对象时容易触发 Full GC。
标记-复制算法
- 原理:为了解决内存碎片问题,将可用内存按容量划分为大小相等的两块,每次只使用其中一块。当这一块的空间用完了,就将还存活着的对象复制到另一块,然后再把已使用过的内存空间一次清理掉。主要用于进行新生代的垃圾回收。
- 特点:① 实现简单、运行高效,解决了内存碎片问题。② 代价是将可用内存缩小为原来的一半,浪费了过多空间。
- HotSpot 的新生代划分
把新生代划分为一块较大的 Eden 空间和两块较小的 Survivor 空间,每次分配内存只使用 Eden 和其中一块 Survivor。发生垃圾收集时将 Eden 和 Survivor 中仍然存活的对象一次性复制到另一块 Survivor 上,然后直接清理掉 Eden 和已用过的那块 Survivor 空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,即每次新生代中可用空间为整个新生代的90%。
标记-整理算法
- 原理:标记-复制算法在对象存活率较高时要进行较多的复制操作,效率将会降低。并且如果不想浪费空间,就需要有额外空间进行分配担保,应对被使用内存中所有对象都100%存活的极端情况,所以老年代一般不使用此算法。老年代使用标记-整理算法,标记过程与标记-清除算法一样,只是后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存。
- 特点:标记-清除与标记-整理的差异在于前者是一种非移动式回收算法而后者是移动式的。是否移动回收后的存活对象优缺点并存:① 如果移动存活对象,尤其是在老年代这种每次回收都有大量对象存活的区域,是一种极为负重的操作,而且这种移动必须全程暂停用户线程。② 如果不移动对象就会导致空间碎片问题,只能依赖更复杂的内存分配器和访问器来解决。所以是否移动对象都存在弊端,移动则内存回收更复杂,不移动则内存分配更复杂。
P9:垃圾收集器
经典垃圾收集器:指 JDK 11之前的垃圾收集器。
Serial
最基础、历史最悠久的收集器,该收集器是一个使用复制算法的单线程工作收集器,单线程的意义不仅是说明它只会使用一个处理器或一条收集线程去完成垃圾收集工作,更重要的是强调它进行垃圾收集时必须暂停其他所有工作线程直到收集结束。
Serial 是虚拟机运行在客户端模式下的默认新生代收集器,优点是简单高效,对于内存受限的环境它是所有收集器中最小的;对于单核处理器或处理器核心较少的环境来说,Serial 收集器由于没有线程交互开销,因此可获得最高的单线程收集效率。
ParNew
实质上是 Serial 的多线程版本,除了使用多线程进行垃圾收集外其余行为完全一致。
ParNew 是虚拟机运行在服务端模式下的默认新生代收集器,一个重要原因是除了 Serial 外只有它能与 CMS 配合。自从 JDK 9 开始,ParNew 加 CMS 收集器的组合就不再是官方推荐的服务端模式下的收集器解决方案了,官方希望他能被 G1 完全取代。
Parallel Scavenge
新生代收集器,基于标记-复制算法,是可以并行的多线程收集器,与 ParNew 类似。
特点是它的关注点与其他收集器不同,CMS 等收集器的关注点是尽可能缩短收集时用户线程的停顿时间,而 Parallel Scavenge 的目标是达到一个可控制的吞吐量,吞吐量就是处理器用于运行用户代码的时间与处理器消耗总时间的比值。自适应调节策略也是它区别于 ParNew 的一个重要特性。
Serial Old
Serial 的老年代版本,同样是一个单线程收集器,使用标记-整理算法。
Serial Old 是虚拟机在客户端模式下的默认老年代收集器,用于服务端有两种用途:一种是 JDK 5 及之前与 Parallel Scavenge 搭配使用,另一种是作为CMS 发生失败时的预案。
Parellel Old
Parallel Scavenge 的老年代版本,支持多线程收集,基于标记-整理算法实现。这个收集器直到 JDK 6 才开始提供,在注重吞吐量优先的场景可以有效考虑Parallel Scavenge 加 Parallel Old 组合。
CMS
以获取最短回收停顿时间为目标的收集器,如果希望系统停顿时间尽可能短以给用户带来更好的体验就可以使用 CMS。
基于标记-清除算法,过程相对复杂,分为四个步骤:初始标记、并发标记、重新标记、并发清除。
其中初始标记和重新标记仍然需要 STW(Stop The World,表示系统停顿),初始标记仅是标记 GC Roots 能直接关联到的对象,速度很快。并发标记就是从 GC Roots 的直接关联对象开始遍历整个对象图的过程,耗时较长但不需要停顿用户线程,可以与垃圾收集线程并发运行。重新标记则是为了修正并发标记期间因用户程序运作而导致标记产生变动的那一部分对象的标记记录,该阶段停顿时间比初始标记稍长,但远比并发标记短。最后是并发清除,清理标记阶段判断的已死亡对象,由于不需要移动存活对象,因此该阶段也可以与用户线程并发。
由于整个过程中耗时最长的并发标记和并发清除阶段中,垃圾收集器都可以和用户线程一起工作,所以从总体上说 CMS 的内存回收过程是与用户线程并发执行的。
CMS 是 HotSpot 追求低停顿的第一次成功尝试,但还存在三个明显缺点:① 对处理器资源敏感,在并发阶段虽然不会导致用户线程暂停,但会降低总吞吐量。② 无法处理浮动垃圾,有可能出现并发失败而导致另一次 Full GC。③ 基于标记-清除算法,会产生大量空间碎片,给大对象分配带来麻烦。
G1
开创了收集器面向局部收集的设计思路和基于Region的内存布局,是一款主要面向服务端的收集器,最初设计目标是替换CMS。
G1 之前的收集器,垃圾收集的目标要么是整个新生代,要么是整个老年代或整个堆。而 G1 可以面向堆内存任何部分来组成回收集进行回收,衡量标准不再是它属于哪个分代,而是哪块内存中存放的垃圾数量最多,回收受益最大。
不再坚持固定大小及数量的分代区域划分,而是把 Java 堆划分为多个大小相等的独立区域(Region),每一个 Region 都可以根据需要扮演新生代的 Eden 空间、Survivor 空间或老年代空间。收集器能够对扮演不同角色的 Region 采用不同的策略处理,这样无论是新创建的对象还是已经存活了一段时间、熬过多次收集的旧对象都能获取很好的收集效果。
跟踪各个 Region 里垃圾堆积的价值大小,价值即回收所获得的空间大小以及回收所需时间的经验值,在后台维护一个优先级列表,每次根据用户设定允许的收集停顿时间优先处理回收价值收益最大的 Region。这种方式保证了 G1 在有限时间内获取尽可能高的收集效率。
G1的运作过程:
- 初始标记:标记 GC Roots 能直接关联到的对象,让下一阶段用户线程并发运行时能正确地在可用 Region 中分配新对象。该阶段需要 STW 但耗时很短,是借用进行 Minor GC 时同步完成的。
- 并发标记:从 GC Roots 开始对堆中对象进行可达性分析,递归扫描整个堆的对象图,找出需要回收的对象。该阶段耗时长,但可与用户线程并发执行,当对扫描完成后还要重新处理 SATB 记录的在并发时有引用变动的对象。
- 最终标记:对用户线程做一个短暂暂停,用于处理并发阶段结束后仍遗留下来的少量 SATB 记录。
- 筛选回收:对各个 Region 的回收价值和成本排序,根据用户期望的停顿时间制定回收计划,可自由选择任意多个 Region 构成回收集然后把决定回收的那部分存活对象复制到空的 Region 中,再清理掉整个旧 Region 的全部空间。该操作必须暂停用户线程,由多条收集器线程并行完成。
可以由用户指定期望停顿时间是 G1 的一个强大功能,但该值不能设得太低,一般设置为100~300毫秒比较合适。G1不存在内存空间碎片的问题,但为了垃圾收集产生的内存占用和程序运行时的额外执行负载都高于 CMS。
低延迟垃圾收集器:指 Shenandoah 和 ZGC,这两个收集器几乎整个工作过程都是并发的,只有初始标记、最终标记这些阶段有短暂停顿,停顿时间基本上固定。
Shenandoah
相比 G1 内存布局同样基于 Region,默认回收策略也是优先处理回收价值最大的 Region。但在管理堆内存方面与 G1 有不同:① 支持并发整理,G1 的回收阶段不能与用户线程并发。② 默认不使用分代收集,不会有专门的新生代 Region 或老年代 Region。③ 摒弃了在 G1 中耗费大量内存和计算资源维护的记忆集,改用名为连接矩阵的全局数据结构记录跨 Region 的引用关系。
ZGC
JDK 11中新加入的具有实验性质的低延迟垃圾收集器,和 Shenandoah 的目标相似,都希望在尽可能对吞吐量影响不大的前提下实现把停顿时间限制在 10ms 以内的低延迟。
基于 Region 内存布局,不设分代,使用了读屏障、染色指针和内存多重映射等技术实现可并发的标记-整理,以低延迟为首要目标。 ZGC 的 Region 具有动态性,是动态创建和销毁的,并且区容量大小也是动态变化的。
P10:内存分配与回收策略
以 Seial + Serial Old 客户端默认收集器组合为例:
对象优先在 Eden 区分配
大多数情况下对象在新生代 Eden 区分配,当 Eden 区没有足够空间进行分配时将发起一次 Minor GC。
可通过 -XX:Xms 和 -XX:Xmx 设置堆大小, -Xmn 设置新生代的大小, -XX:SurvivorRatio 设置新生代中 Eden 和 Survivor 的比例。
大对象直接进入老年代
大对象指需要大量连续内存空间的对象,典型的是很长的字符串或元素数量庞大的数组。大对象容易导致内存明明还有不少空间就提前触发垃圾收集以获得足够的连续空间,复制对象时大对象就意味着高额内存复制开销。
HotSpot 提供了 -XX:PretenureSizeThreshold 参数,大于该值的对象直接在老年代分配,避免在 Eden 和 Survivor 之间来回复制产生大量内存复制操作。
长期存活对象进入老年代
虚拟机给每一个对象定义了一个对象年龄计数器,存储在对象头。对象通常在 Eden 诞生,如果经历过第一次 MinorGC 仍然存活并且能被 Survivor 容纳,该对象就会被移动到 Survivor 中并将年龄设置为 1。对象在 Survivor 中每熬过一次 MinorGC 年龄就加 1 ,当增加到一定程度(默认15)就会被晋升到老年代。对象晋升老年代的年龄阈值可通过 -XX:MaxTenuringThreshold 设置。
动态对象年龄判定
为了适应不同程序的内存状况,虚拟机并不永远要求对象年龄达到阈值才能晋升老年代,如果在 Survivor 中相同年龄所有对象大小的总和大于 Survivor 的一半,年龄不小于该年龄的对象就可以直接进入老年代,无需等到 -XX:MaxTenuringThreshold 参数设置的年龄。
空间分配担保
发生 MinorGC 前,虚拟机必须先检查老年代最大可用连续空间是否大于新生代所有对象总空间,如果这个条件成立,那这一次 MinorGC可以确定是安全的。
如果不成立,虚拟机会先查看 -XX:HandlePromotionFailure 参数的值是否允许担保失败,如果允许会继续检查老年代最大可用连续空间是否大于历次晋升老年代对象的平均大小,如果满足将冒险尝试一次 MinorGC,如果不满足或不允许担保失败就会改成一次 FullGC。
之所以说冒险是因为新生代使用复制算法,为了内存利用率只使用其中一个 Survivor 作为备份,因此当出现大量对象在 MinorGC 后仍然存活的情况时需要老年代进行分配担保,把 Survivor 无法容纳的对象直接送入老年代。
P11:故障处理工具
jps:虚拟机进程状况工具
jps 即 JVM Process Status,参考了 UNIX 命令的命名格式,功能和 ps 命令类似:可以列出正在运行的虚拟机进程,并显示虚拟机执行主类名称以及这些进程的本地虚拟机唯一 ID(LVMID)。LVMID 与操作系统的进程 ID(PID)是一致的,使用 Windows 的任务管理器或 UNIX 的 ps 命令也可以查询到虚拟机进程的 LVMID,但如果同时启动了多个虚拟机进程,无法根据进程名称定位就必须依赖 jps 命令。
jps 还可以通过 RMI 协议查询开启了 RMI 服务的远程虚拟机进程状态,参数 hostid 为 RMI 注册表中注册的主机名。
jstat:虚拟机统计信息监视工具
jstat 即 JVM Statistic Monitoring Tool,是用于监视虚拟机各种运行状态信息的命令行工具。它可以显示本地或者远程虚拟机进程中的类加载、内存、垃圾收集、即时编译器等运行时数据,在没有 GUI 界面的服务器上是运行期定位虚拟机性能问题的常用工具。
一些参数的含义:S0 和 S1 表示两个 Survivor 区,E 表示新生代,O 表示老年代,YGC 表示 Young GC 次数,YGCT 表示Young GC 耗时,FGC 表示 Full GC 次数,FGCT 表示 Full GC 耗时,GCT 表示所有 GC 总耗时。
jinfo:Java 配置信息工具
jinfo 表示 Configuration Info for Java,作用是实时查看和调整虚拟机各项参数,使用 jps 的 -v 参数可以查看虚拟机启动时显式指定的参数列表,但如果想知道未被显式指定的参数的系统默认值就只能使用 jinfo 的 -flag 选项进行查询。jinfo 还可以把虚拟机进程的 System.getProperties() 的内容打印出来。
jmap:Java 内存映像工具
jmap 表示 Memory Map for Java,jamp 命令用于生成堆转储快照,还可以查询 finalize 执行队列、Java 堆和方法区的详细信息,如空间使用率,当前使用的是哪种收集器等。和 jinfo 命令一样,有部分功能在 Windows 平台下受限,除了生成堆转储快照的 -dump 选项和用于查看每个类实例的 -histo 选项外,其余选项都只能在 Linux 使用。
jhat:虚拟机堆转储快照分析工具
jhat 表示 JVM Heap Analysis Tool,JDK 提供 jhat 命令与 jmap 搭配使用来分析 jamp 生成的堆转储快照。jhat 内置了一个微型的 HTTP/Web 服务器,生成堆转储快照的分析结果后可以在浏览器中查看。
jstack:Java 堆栈跟踪工具
jstack 表示 Stack Trace for Java,jstack 命令用于生成虚拟机当前时刻的线程快照。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的目的通常是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间挂起等。线程出现停顿时通过 jstack 查看各个线程的调用堆栈,就可以获知没有响应的现场到底在后台做什么或等待什么资源。
除了上述的基础故障处理工具,还有一些可视化故障处理工具,例如 JHSDB 基于服务性代理的调试工具、JConsole Java 监视与管理控制台、VisualVM 多合一故障处理工具、Java Mission Control 可持续在线监控工具。
P12:Java 程序运行的过程
通过 Javac 编译器将 .java 代码转为 JVM 可以加载的 .class 字节码文件。
Javac 编译器是由 Java 语言编写的程序,从 Javac 代码的总体结构看,编译过程可以分为: ① 词法解析,通过空格分割处单词、操作符、控制符等信息,将其形成 token 信息流,传递给语法解析器。② 语法解析,把词法解析得到的 token 信息流按照 Java 语法规则组装成一颗语法树。④ 语义分析,检查关键字的使用是否合理、类型是否匹配、作用域是否正确等。④ 字节码生成,将前面各个步骤的信息转换为字节码。
字节码必须通过类加载过程加载到 JVM 环境后才可以执行,执行有三种模式,解释执行、JIT 编译执行、JIT 编译与解释器混合执行(主流 JVM 默认执行的方式)。混合模式的优势在于解释器在启动时先解释执行,省去编译时间。
通过即时编译器 JIT 把字节码文件编译成本地机器码。
Java 程序最初都是通过解释器进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁,就会把这些代码认定为"热点代码",热点代码的检测主要有基于采样和基于计数器两种方式,为了提高热点代码的执行效率,在运行时虚拟机会把这些代码编译成本地机器码,并尽可能对代码优化,在运行时完成这个任务的后端编译器被称为即时编译器。
还可以通过静态的提前编译器 AOT 直接把程序编译成与目标机器指令集相关的二进制代码。
P13:类加载机制和初始化时机
在 Class 文件中描述的各类信息最终都需要加载到虚拟机后才能运行和使用。JVM 把描述类的数据从 Class 文件加载到内存,并对数据进行校验、解析和初始化,最终形成可以被虚拟机直接使用的 Java类型,这个过程被称为虚拟机的类加载机制。与其他在编译时需要连接的语言不同,Java 中类型的加载、连接和初始化都是在程序运行期间完成的,这种策略让 Java 进行类加载时增加了性能开销,但却为 Java 应用提供了极高的扩展性和灵活性,Java 可以动态扩展的语言特性就是依赖运行期动态加载和动态连接这个特点实现的。
一个类型从被加载到虚拟机内存开始,到卸载出内存为止,整个生命周期将会经历加载、验证、准备、解析、初始化、使用和卸载七个阶段,其中验证、解析和初始化三个部分统称为连接。加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持 Java 语言的动态绑定特性。
关于何shuyu时需要开始类加载的第一个阶段"加载",《 Java 虚拟机规范》没有强制约束,但对于初始化严格规定了有且只有6种情况:
- 遇到 new、getstatic、putstatic 或 invokestatic 这四条字节码指令时,如果类型没有初始化则需要先触发初始化。典型场景有:① 使用new关键字实例化对象。② 读取或设置一个类型的静态字段。③ 调用一个类型的静态方法。
- 对类型进行反射调用时,如果类型没有初始化则需要先触发初始化。
- 当初始化类时,如果其父类没有初始化则需要先触发父类的初始化。
- 当虚拟机启动时,用户需要指定一个要执行的主类即包含 main 方法的类,虚拟机会先初始化该类。
- 当使用 JDK 7 新加入的动态语言支持时,如果 MethodHandle 实例的解析结果为指定类型的方法句柄且这个句柄对应的类没有进行过初始化,则需要先触发其初始化。
- 当一个接口定义了默认方法时,如果该接口的实现类发生初始化,那接口要在其之前初始化。
除了这六种情况外其余所有引用类型的方式都不会触发初始化,称为被动引用。被动引用的实例:① 子类使用父类的静态字段时,只有直接定义这个字段的父类会被初始化。② 通过数组定义使用类。③ 常量在编译期会存入调用类的常量池,不会初始化定义常量的类。
接口的加载过程和类真正有所区别的是当初始化类时,如果其父类没有初始化则需要先触发其父类的初始化,但在一个接口初始化时并不要求其父接口全部完成了初始化,只有在真正使用到父接口时(如引用接口中定义的常量)才会初始化。
P14:类加载过程
加载
加载是类加载的第一个阶段,在该阶段虚拟机需要完成三件事:① 通过一个类的全限定类名来获取定义此类的二进制字节流。② 将这个字节流所代表的静态存储结构转化为方法区的运行时数据区结构。③ 在内存中生成对应该类的 Class 实例,作为方法区这个类的各种数据的访问入口。加载与连接的部分动作是交叉进行的,加载尚未完成时连接可能已经开始。
验证
验证是连接的第一步,目的是确保 Class 文件的字节流中包含的信息符合约束要求,保证这些信息不会危害虚拟机的安全。如果虚拟机不检查输入的字节流,很可能因为载入了有错误或恶意企图的字节流而导致整个系统受攻击。验证主要包含了四个阶段:文件格式验证、元数据验证、字节码验证、符号引用验证。
验证对于虚拟机的类加载机制来说是一个非常重要但非必需的阶段,因为验证只有通过与否的区别,只要通过了验证其后就对程序运行期没有任何影响了。如果程序运行的全部代码都已被反复使用和验证过,在生产环境的就可以考虑关闭大部分类验证措施缩短类加载时间。
准备
准备是正式为类静态变量分配内存并设置零值的阶段,该阶段进行的内存分配仅包括类变量,而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在 Java 堆中。如果变量被final修饰,编译时 Javac 会为变量生成 ConstantValue 属性,那么在准备阶段虚拟机就会将该变量的值设为程序员指定的值。
解析
解析是将常量池内的符号引用替换为直接引用的过程。
- 符号引用:符号引用以一组符号描述引用目标,可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。与虚拟机内存布局无关,引用目标并不一定是已经加载到虚拟机内存中的内容。
- 直接引用:直接引用是可以直接指向目标的指针、相对偏移量或者能间接定位到目标的句柄。和虚拟机的内存布局直接相关,引用目标必须已在虚拟机的内存中存在。
解析部分主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符这7类符合引用进行。
初始化
初始化是类加载过程的最后一步,直到该阶段,JVM 才真正开始执行类中编写的代码。准备阶段时变量已经赋过一次系统零值,而在初始化阶段会根据程序员的编码去初始化类变量和其他资源。初始化阶段就是执行类构造方法中的 方法,该方法是 Javac 编译器自动生成的。
P15:类加载器和双亲委派模型
类加载阶段中"通过一个类的全限定名来获取描述该类的二进制字节流"的动作被设计为放到 JVM 外部实现,以便让应用程序自己决定如何获取所需的类,实现这个动作的代码就是类加载器。
自 JDK1.2 起 Java 一直保持着三层类加载器、双亲委派的类加载模型:
- 启动类加载器
启动类加载器在 JVM 启动时创建,负责加载最核心的类,例如 Object、System、String 等。启动类加载器无法被 Java 程序直接引用,如果用户需要把加载请求委派给启动类加载器,直接使用 null 代替即可,因为启动类加载器通常由操作系统相关的本地代码实现,并不存在于 JVM 体系中。 - 平台类加载器
从 JDK9 开始从扩展类加载器更换为平台类加载器,负载加载一些扩展的系统类,比如 XML、加密、压缩相关的功能类等。 - 应用类加载器
也称系统类加载器,负载加载用户类路径上的所有类库,可以直接在代码中使用。如果应用程序中没有自定义类加载器,一般情况下应用类加载器就是中默认的类加载器。自定义类加载器通过继承 ClassLoader 并重写 findClass 方法,调用 defineClass 方法实现。
双亲委派模型
类加载器具有等级制度,但并非继承关系,以组合的方式来复用父加载器的功能,这也符合组合优先原则。双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应该有自己的父加载器。
如果一个类加载器收到了类加载请求,它不会自己去尝试加载这个类,而首先将该请求委派给自己的父加载器完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成请求时,子加载器才会尝试自己完成加载。
好处是 Java 中的类跟随它的类加载器一起具备了一种带有优先级的层次关系,可以保证某个类在程序的各个类加载器环境中都是同一个类,对于保证程序的稳定运行极为重要。
比较两个类是否相等
对于任意一个类,都必须由加载它的类加载器和这个类本身一起共同确立其在虚拟机中的唯一性,每一个类加载器都拥有一个独立的类名称空间。只有在两个类是由同一个类加载器加载的前提下才有意义,否则即使两个类来源于同一个 Class 文件,被同一个 JVM 加载,只要加载它们的类加载器不同,那这两个类就必定不相等。