Java版Flink(二)部署模式
一、standalone 部署模式
1、下载安装包
下载安装包地址
有两种安装包类型:
第一种是带 Hadoop依赖的(整合YARN)
第二种是不带 Hadoop依赖的(Standalone模式)
本次部署选择 1.10.1 版本
2、相关配置介绍
2.1 核心目录介绍
bin:启动脚本
conf:配置文件
examples:样例程序
lib:jar存放地
log:日志存放地
2.2 bin 目录
flink:核心运行job
historyserver.sh:历史服务器启动停止脚本
start-cluster.sh:启动集群脚本
stop-cluster.sh:停止集群脚本
yarn-session.sh:运行job的一种模式
2.3、conf 目录
flink-conf.yaml:核心配置
masters:配置jobManager主机
slaves:配置taskManager主机
log4j.properties:配置日志
2.4、flink-conf.yaml 文件
# jobManager 服务主机
jobmanager.rpc.address: localhost
# jobManager 服务端口
jobmanager.rpc.port: 6123
# jobManager 堆大小 默认 1G
jobmanager.heap.size: 1024m
# taskManager 处理内存大小 包括堆内内存和堆外内存
taskmanager.memory.process.size: 1728m
# taskManager 的 slots 个数 默认1
taskmanager.numberOfTaskSlots: 1
# 并行度大小 并行度大小少于等于总共的 slots(taskManager 个数 * slots 个数)
parallelism.default: 1
# 前端页面端口
#rest.port: 8081
3、配置
3.1、配置 flink-conf.yaml
jobmanager.rpc.address: hadoop102
3.2、配置 master
可选:已经在 flink-conf.yaml 配置好
3.3、配置 slaves
hadoop103
hadoop104
4、启动
4.1、分发
4.2、启动
bin/start-cluster.sh
4.3、web 界面
http://hadoop102:8081
4.4、停止
bin/stop-cluster.sh
5、部署 wordcount
5.1、DeployWordcount
package com.tan.flink.deploy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class DeployWordcount {
public static void main(String[] args) throws Exception {
// 1、创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取 socket 数据
ParameterTool tool = ParameterTool.fromArgs(args);
String host = tool.get("host");
int port = tool.getInt("port");
DataStreamSource<String> inputDataStream = env.socketTextStream(host, port);
// 3、计算
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = input.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0)
.sum(1).setParallelism(2);
// 4、输出
resultDataStream.print();
// 5、启动 env
env.execute();
}
}
5.2、打包
5.3、web端提交
submit new job -> add new
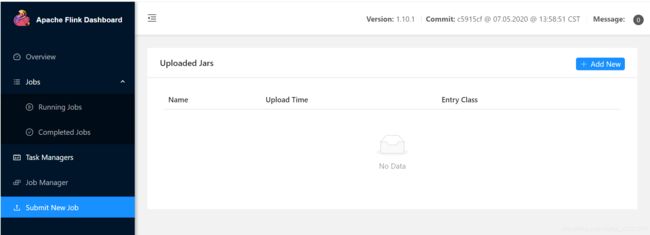
entry class:运行主类
parallelism:并行度 代码 > 页面设置 > 默认配置
program arguments:程序参数
savepoint path:检查点保存路径

填写相应的参数后 submit
程序的最大的并行度个数小于等于 集群的 slots总数 否则程序一直处于请求资源状态。
查看标准输出
taskMangers -> 选择其他一台(不确定)-> sdtout
5.4、命令行提交
上传 jar 包 lib 目录下
bin/flink run -c com.tan.flink.deploy.DeployWordcount -p 2 lib/flink-1.0-SNAPSHOT.jar --host 192.168.200.102 --port 9999
-c:运行类
-p:并行度
jar 包路径
程序参数
此时程序处于资源申请状态,一直处于Create状态。没有多余的slots可用
查看运行jobs:
bin/flink list
停止某个job
bin/flink cancel jobid
二、Yarn 部署模式
需要有 Hadoop相关依赖、启动 Hadoop
1、Session-cluster 模式
Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。
在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止。
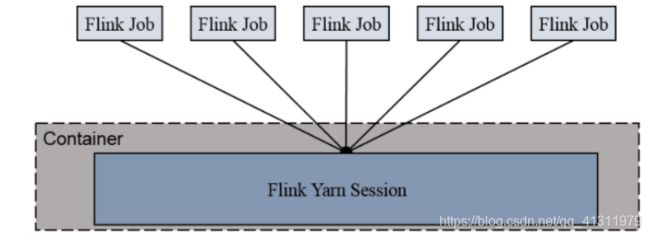
1.1 启动 session-cluster
bin/yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm yarn-deploy-wordcount -d
-n(–container):TaskManager 的数量。
-s(–slots): 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个taskmanager 的 slot 的个数为 1,有时可以多一些 taskmanager,做冗余。
-jm:JobManager 的内存(单位 MB)。
-tm:每个 taskmanager 的内存(单位 MB)。
-nm:yarn 的 appName(现在 yarn 的 ui 上的名字)。
-d:后台执行。
1.2 部署一个应用
bin/flink run -c com.tan.flink.deploy.DeployWordcount -p 2 lib/flink-1.0-SNAPSHOT.jar --host 192.168.200.102 --port 9999
1.3、查看Yarn 界面
http://ip:8088
1.4、停止 job
yarn application --kill application_1615631116563_0001
1.5、停止 session-cluster
kill -9 进程id
2、per job cluster
一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
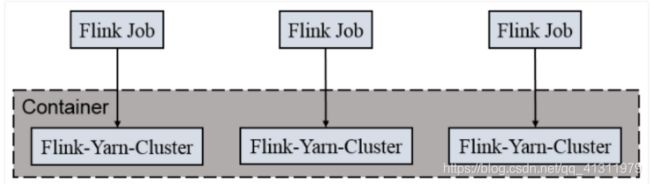
2.1 提交一个job
bin/flink run -m yarn-cluster -c com.tan.flink.deploy.DeployWordcount -p 2 lib/flink-1.0-SNAPSHOT.jar --host 192.168.200.102 --port 9999