DeepLabV3+模型训练全过程
一、DeepLabV3+介绍
Deeplabv3+模型是由谷歌在2021年提出来的一个用于语义分割的模型,它可以进行多分类语义分割也可以进行实例分割,在公共数据集PASCAL VOC 2012和Cityscapes上达到了89.0%及82.1%的精度,同时也是一个较为轻便的模型,因此Deeplabv3+是一个兼具了速度和精度的模型。此次,我选用了resnet101为主干模型的DeeplapV3+。
二、数据集制作:
1)首先把图片和json文件分开,自己编写代码。
# coding:utf-8
import os
import random
import argparse
import shutil
'''
把一个文件夹中的图片和json文件按照比例分为训练集和测试集
'''
def split1(path,trainPath,testPath):
trainval_percent = 1.0
train_percent = 0.8
total_path = os.listdir(path)
num = len(total_path)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
print("训练集数量:",len(train))
print("测试集数量:",len(total_path)- len(train))
for i in list_index:
old_jpg_path = path + total_path[i]
name = total_path[i].split(".")[0]
old_json_path = path + name + ".json"
if i in train:
new_jpg_path = trainPath + total_path[i]
new_json_path = trainPath + name + ".json"
print("___",old_jpg_path,old_json_path,"----",new_jpg_path,new_json_path)
else:
new_jpg_path = testPath + total_path[i]
new_json_path = testPath + name + ".json"
print(old_jpg_path,old_json_path,"----",new_jpg_path,new_json_path)
shutil.copyfile(old_jpg_path, new_jpg_path)
shutil.copyfile(old_json_path, new_json_path)
if __name__ == "__main__":
split1(r"F:\xinda\datasets\stone\22\JPEGImages\\",r"F:\xinda\datasets\stone\22\coco\train2014\\",r"F:\xinda\datasets\stone\22\coco\val2014\\")
2)将json文件转成PNG图
参考:labelme批量json转png数据集教程_this script is aimed to demonstrate how to convert_脱发小白龙的博客-CSDN博客
转成功以后,每个图是在不同的文件夹,如下图。所以需要把所有的图放到同一个文件夹下,自己编写代码。
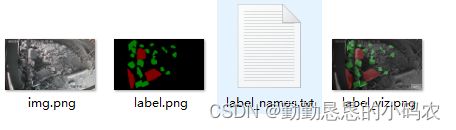
import cv2
import shutil
import os
'''
把生成的每个掩模图放到同一个文件夹中
'''
def leave(path,imagesPath):
imgList = os.listdir(path)
for i in imgList:
imageName= i.split("_json")[0]
old_path = path + i + "\\label.png"
new_path = imagesPath + imageName + ".png"
print(old_path)
shutil.copyfile(old_path, new_path) # 复制图片
if __name__ == "__main__":
path1 = "F:\\xinda\\datasets\\stone\\22\\json1\\json_data\\"
leave(path1,"F:\\xinda\\datasets\\stone\\22\\json1\\mask\\")3)将待训练的所有jpg图片全部放入JPEGImages文件夹中,将所有png图片全部放入SegmentationClass文件夹中。
4)在ImageSets文件夹中新建Segmentation文件夹,在Segmentatin文件夹中新建train.txt ,val.txt 和 trainval.txt。然后将要数据集中的图片,按照一定的比例分为训练集和验证集,将训练集和验证集的图片的名字写入对应的txt文件中就可以了。具体形式如下图:
- 环境配置
硬件环境:RTX3090
所需包如下:torch==2.0.1
Torchvision==0.15.2
Numpy==1.24.3
Pillow==9.2.0
scikit-learn==1.3.0
Tqdm==4.65.0
Matplotlib==3.2.2
Visdom==0.2.4
- 模型训练
代码地址:
https://github.com/VainF/DeepLabV3Plus-Pytorch
参考博客:
【图像语义分割】DeepLabv3+(Pytorch版) 源码复现—Kitti数据集_kitti语义分割数据集_Duuu7的博客-CSDN博客
多分类影像分割(语义分割)模型 DeepLabV3_plus pytorch版本 深度学习模型复现 网络配置及训练自己的数据集_persist_ence的博客-CSDN博客
官方权重进行测试:
命令行:
python predict.py --input testImg11 --dataset voc --model deeplabv3plus_resnet101 --ckpt checkpoints/best_deeplabv3plus_resnet101_voc_os16.pth --save_val_results_to test_results注意:不同的预训练权重对应不同的数据集和模型,一定要对应好,否则会报错。下面这条语句对应的数据集是voc,模型是deeplabv3plus_resnet101。
训练的命令行:
python main.py --model deeplabv3plus_resnet101 --gpu_id 0 --year 2012 --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16步骤:
1)可视化在服务器上实现不了,数据集格式要和给的格式一样,例如:
2)然后修改main.py 里面的data_root为下载的数据集的路径,这里我用的相对路径“./datasets/data”。

3)设置好输入数据之后就可以点击运行main.py了。如果有报错的话,可以试试是不是需要去掉--enable_vis --vis_port 28333。加了以后报错,无法使用port 28333,换成其他的port也不行,所以不加这两条。
4)加预训练模型或者模型中断之后接着训练。
如果模型中断,需要接着上面的继续训练或者添加别人训练好的预训练模型,需要修改“ckpt”,将其修改为你存储模型的那个路径,我这里是用的相对路径“./checkpoints/best_deeplabv3plus_xception_voc_os16.pth”,然后修改“continue_training”为“True”。然后运行main.py就可以了。

训练效果如下:

四、模型推理:
命令行:
python predict.py --input testImg --dataset voc --model deeplabv3plus_resnet101 --ckpt best_deeplabv3plus_resnet101_voc_os16.pth --save_val_results_to test_results模型推理或者模型预测用到的是predict.py。
需要修改以下几个参数:
"input"修改为自己的要预测的数据的路径;
"save_val_results_to"修改为自己要存放的预测结果的路径;默认保存在test_results文件夹中了。
"ckpt"修改为自己训练好的模型的路径。
推理效果如下:

遇到的问题及解决措施:
- 刚开始找了一个版本的deeplabV3+的代码,但是推理和训练都出现报错,无法解决,所以找了另一个版本的代码。
- 把json文件转成PNG图片时,转换失败。
解决办法:把labelme包中的labelme_json_to_dataset.py替换掉,再执行另一段代码。
参考:labelme批量json转png数据集教程_this script is aimed to demonstrate how to convert_脱发小白龙的博客-CSDN博客
- 转换后的PNG图片分别在不同的文件夹中
解决办法:自己编写一段代码,把图片复制到同一个文件夹中。
- 进行官方推理时,权重和模型没有对应上,导致推理失败。经过修改模型参数,就能执行成功了。
- 训练时,串口无法使用。
解决措施:不采用可视化。
- 推理时,生成的是掩模图,不是掩模图和原图的结合。
解决措施:使用cv2.addWeighted()函数,将二者相加,生成结合后的图。