NeurIPS 2023 | 对比损失深度刨析!三星研究院提出全新连续性对比损失CMCL

论文名称: CWCL: Cross-Modal Transfer with Continuously Weighted Contrastive Loss 论文链接: https://arxiv.org/abs/2309.14580
一些通过大规模预训练的跨模态表示对齐模型(例如CLIP和LiT)往往能够展示出非常强大的跨领域zero-shot能力,这种能力是我们通向通用人工智能的重要步骤。目前较为常用的技术手段都是使用标准的对齐训练损失从大规模的正例样本和负例样本对中挖掘不同模态之间的语义交互。但是这种方式也存在一个明显的缺陷,即训练集中有一定数量的样本对相似性具有更加连续的性质,因此简单的使用二元对比损失来进行优化是不全面的。
本文介绍一篇发表在人工智能顶级会议NeurIPS 2023上的一篇文章,本文作者团队来自三星研究院,本文在原有标准对比损失的基础上提出了一种新型连续加权对比损失(Continuously Weighted Contrastive Loss,CWCL),CWCL使用了一种连续的相似性度量,可以在连续性空间中将两个不同模态的嵌入空间进行对齐。作者通过大量的实验发现,基于函数的连续性质,CWCL不仅可以在图像-文本模态对之间实现性能提升(提高5~8%),在语音-文本模态对之间也表现出了优越的性能(提高20~30%)。
01. 引言
目前,视觉图像和文本模态已经存在一些很强大的预训练模型,例如CLIP[1]和LiT[2]。但其他模态仍然缺乏这类模型,例如语音音频领域,与视觉语言模型可以通过zero-shot的形式推广到新任务的迁移范式不同,语音和音频模型仍然需要使用特定任务的数据进行微调训练。并且,在语音领域收集和标注数据集也存在一定的难度,例如如何进行质量控制、消除噪声等。此外,即使是在图像预训练模态,也存在具有挑战性的子模态,例如医学成像领域,直接使用自然图像的预训练模型也存在问题。
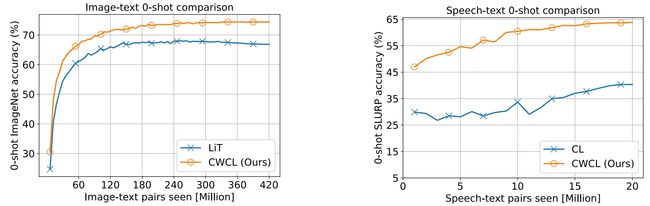
因此本文主要着重于如何更好的从一个大规模预训练模型中向其他模态进行知识迁移,目前的常用做法是使用标准对比损失从配对数据集中以监督学习的方式进行,然而,监督模式中可能有许多相似的样本,并且相似程度不同。为了缓解这种低效率迁移的局限,本文提出了一种连续加权对比损失CWCL,用于多模态模型的对比训练。作者使用了图像-文本和语音-文本两种模态对来进行研究,上图展示了CWCL与LiT的对齐性能对比,可以看到在两种模态对中,CWCL均展现出了更好的zero-shot能力,尤其是在语音-文本模态。
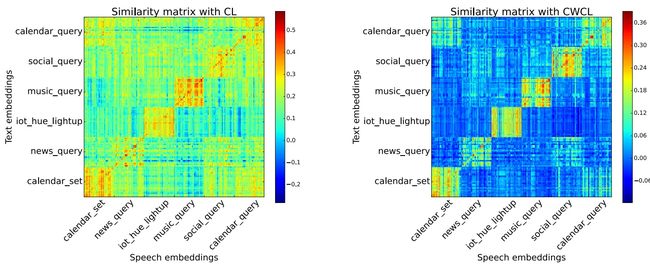
此外,下图展示了使用CWCL对齐后的两种模态之间的相似性矩阵(对角线区域的相似性更加显著),从图中可以看出,即使在迁移训练时没有提供任何标签,CWCL相比普通损失函数实现了更好的模态对齐效果。
02. 本文方法
2.1 现有的对比训练框架和损失函数

2.2 CWCL损失函数定义

2.3 如何获得模态内相似权重?
03. 实验效果
本文的实验主要针对两种模态转换进行,即图像-文本和语音-文本。对于图像-文本对,作者进行了图像分类和图像/文本检索的zero-shot迁移实验。在这两项任务中,CWCL的zero-shot迁移性能都超过了目前的SOTA方法。而对于语音-文本模态,作者进行了语音-意图分类和关键字查询任务,下面将分别介绍这些实验的细节。
3.1 zero-shot图像分类
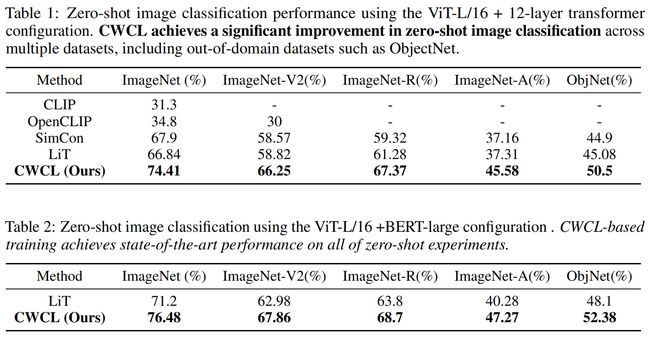
对于零样本图像分类任务,作者在5个数据集上进行了实验:ImageNet、ImageNetV2、ImageNet-R、ImageNet-A和ObjNet。下表中展示了具体的实验结果,其中作者使用SimCon和LiT等方法作为对比基线,可以看到CWCL在ViT+transformer和ViT+BERT两种不同架构上都获得了更好的零样本分类性能。
3.2 zero-shot图像-文本检索
此外,作者还进行了零样本图像文本检索实验,实验数据集选用MS-COCO验证集,下表展示了具体的实验结果,模型架构同样使用ViT+BERT,可以看到使用CWCL对比训练得到的模型性能明显优于使用标准对比损失函数训练的模型。

3.3 zero-shot提示模板的鲁棒性分析
在完成对CWCL的zero-shot分类和检索实验之后,作者还对CWCL的提示鲁棒性进行了分析,例如在zero-shot图像分类中,可以将标签直接转换为文本提示,以便将分类任务调整为对齐任务,因此作者设置了数量为 k个的文本提示模板,并且在构建分类器时将这些模板句子全部输入模型,例如"这是......的照片"、"这是......的图片"等,并且对 k=1,5,10个模板进行了实验,下图展示了CWCL和普通CL损失在不同数量模板设置时的表现情况。
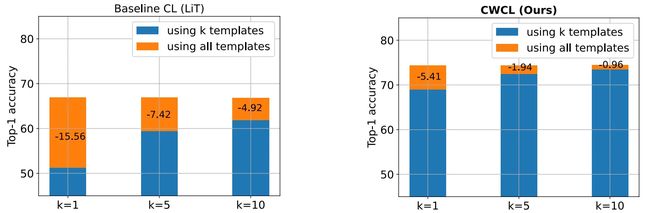
可以看出,使用CWCL损失训练的模型在使用较少的模板数量时就可以获得峰值性能,这表明CWCL在面对不同的文本提示时具有更强的鲁棒性。
3.4 zero-shot语音到意图分类
而对于语音到意图分类任务,作者遵循了ASR-NLU的pipeline,即首先通过ASR(语音-文本)进行转录,然后使用NLU(文本-文本)将转录分类为意图,下表展示了本文方法与其他方法的对比效果。
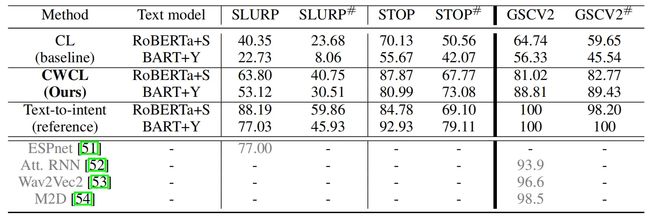
可以看到,在所有的实验设置下,使用CWCL损失的多模态训练均优于CL损失。在SLURP数据集上,使用RoBERTa+S与BART+Y作为文本模型架构会带来更加显著的性能提升。
04. 总结
本文提出了一种新型的用于跨模态对比学习范式中损失函数,称为连续加权对比损失CWCL,CWCL的设计目标是从传统对比损失的固有缺陷出发,作者发现传统损失在使用预训练模型进行跨模态对齐时监督效率较低,对训练数据中具有连续性相似的样本完全忽略。CWCL重点考虑了同一批次中所有样本的相似性信息来增强对比监督。作者在两种模态迁移的zero-shot下游任务中验证了本文方法的性能。
参考
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
[2] Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer, “Lit: Zero-shot transfer with locked-image text tuning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18123–18133.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区