【狂神说Java】Mybatis-plus
✅作者简介:CSDN内容合伙人、信息安全专业在校大学生
系列专栏 :【狂神说Java】
新人博主 :欢迎点赞收藏关注,会回访!
舞台再大,你不上台,永远是个观众。平台再好,你不参与,永远是局外人。能力再大,你不行动,只能看别人成功!没有人会关心你付出过多少努力,撑得累不累,摔得痛不痛,他们只会看你最后站在什么位置,然后羡慕或鄙夷。
文章目录
-
-
-
- 前言
- 实体类实现可序列化接口
- 1、什么是Mybatis-Plus
- 2、Quick Start
-
-
- 思考问题
-
- 3、配置日志
- 4、CRUD拓展
-
- 插入操作
- **主键生成策略**
- 更新操作
- 自动填充
- 乐观锁
- 查询操作
- 分页查询
- 删除操作
- 逻辑删除
- 总结
- 5、性能分析插件
- 6、条件构造器
-
- 1、非空 大于
- 2、查询一个名字
- 3、使用between
- 4、like模糊查询
- 5、连接查询(内查询)
- 6、升序排序
- 7、代码自动生成器
-
-
前言
需要的基础:Mybayis、Spring、SpringMVC
为什么要学习Mybatis-Plus可以节省我们大量工作时间,所有的CRUD代码都可以自动化完成!
JPA, tk-mapper ,MyBatisPlus
什么是JPA
- Java Persistence API(Java 持久层 API):用于对象持久化的 API
- 作用:使得应用程序以统一的方式访问持久层
实体类实现可序列化接口
java.io.Serializable接口
Java实体类需要实现序列化,因此就要实现 java.io.Serializable接口 ( implements Serializable)
序列化是一种用来处理对象流的机制
所谓对象流就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决在对对象流进行读写操作时所引发的问题
什么时候使用序列化:
一:对象序列化可以实现分布式对象。主要应用例如:RMI(即远程调用Remote Method Invocation)要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
二:java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的"深复制",即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
三:序列化可以将内存中的类写入文件或数据库中。比如将某个类序列化后存为文件,下次读取时只需将文件中的数据反序列化就可以将原先的类还原到内存中。也可以将类序列化为流数据进行传输。总的来说就是将一个已经实例化的类转成文件存储,下次需要实例化的时候只要反序列化即可将类实例化到内存中并保留序列化时类中的所有变量和状态。
四: 对象、文件、数据,有许多不同的格式,很难统一传输和保存
序列化以后就都是字节流了,无论原来是什么东西,都能变成一样的东西,就可以进行通用的格式传输或保存,传输结束以后,要再次使用,就进行反序列化还原,这样对象还是对象,文件还是文件
因此JAVA中要将对象序列化 为 流 的 形式进行传输
1、什么是Mybatis-Plus
简介
Mybatis本来就是简化JDBC操作的!
官网:https://baomidou.com/ MybatisPlus,为简化开发而生
MyBatis-Plus(简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。


特性
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用 (自动帮你生成代码)
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 Sql 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
2、Quick Start
地址:https://baomidou.com/guide/quickstart.html#%E5%88%9D%E5%A7%8B%E5%8C%96%E5%B7%A5%E7%A8%8B
使用第三方组件:
- 导入对应的依赖
- 研究依赖如何配置
- 代码如何编写
- 提高拓展技术能力
步骤
- 创建数据库 mybatis_plus
- 创建user表
DROP TABLE IF EXISTS user;
CREATE TABLE user
(
id BIGINT(20) NOT NULL COMMENT '主键ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT(11) NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (id)
);
-- 在真实开发中:会存在 version(乐观锁)、delete(逻辑删除)、gmt_create(创建时间)
-- gmt_modify(修改时间)
- 插入数据
DELETE FROM user;
INSERT INTO user (id, name, age, email) VALUES
(1, 'Jone', 18, '[email protected]'),
(2, 'Jack', 20, '[email protected]'),
(3, 'Tom', 28, '[email protected]'),
(4, 'Sandy', 21, '[email protected]'),
(5, 'Billie', 24, '[email protected]');
- 搭建Springboot环境
- 导入依赖
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.0.5version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.22version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.18version>
dependency>
dependencies>
说明:我们使用mybatis-plus可以节省我们大量的代码,尽量不要同时带入mybatis跟mybatis-plus,可能会产生冲突
- 连接数据库! 这一步和mybatis相同url字段中 设置时区:serverTime=GMT%2b8 (%2b 就是+的意思,这里是指加8个小时,以北京东八区为准)
# mysql 8 驱动不同,需要增加时区设置
spring.datasource.username=root
spring.datasource.password=83821979Zs
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis_plus?useSSL=false&useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2b8
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
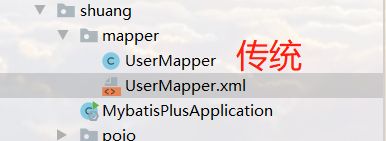
- pojo-dao(连接mybatis,配置mapper.xml文件)-service-controller使用了mybatis-plus之后
- pojo
- mapper接口
- 主启动类注意:我们需要去主启动类上去扫描我们的mapper包下的所有接口 @MapperScan(com.shuang.mapper)
- 测试类
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class User {
private Long id;
private String name;
private Integer age;
private String email;
}
// 在对应的Mapper上面实现基本的接口BaseMapper
@Repository // 代码持久层
@Mapper
public interface UserMapper extends BaseMapper<User> {
// 所有的CRUD操作都已经编写完成了
// 你不需要像以前那样配置一大堆文件了
}
// 扫描mapper文件夹
@MapperScan("com.shuang.mapper")
@SpringBootApplication
public class MybatisPlusApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisPlusApplication.class, args);
}
}
@SpringBootTest
class MybatisPlusApplicationTests {
// 继承了BaseMapper,所有的方法都来自自己的父类,我们也可以编写自己的扩展方法
@Autowired
private UserMapper userMapper;
@Test
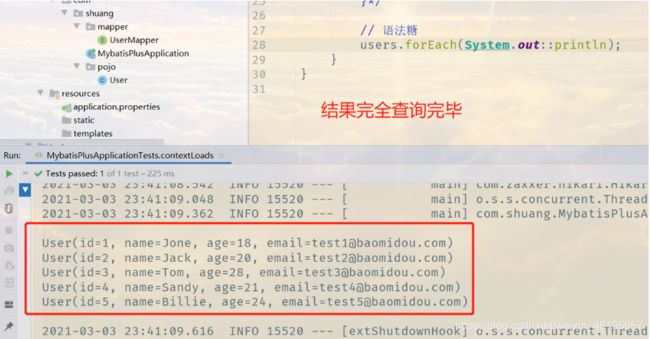
void contextLoads() {
// 查询全部用户
// selectList(参数) 这里的参数是一个Wrapper,条件构造器,这里我们先不用,写个null占着
List<User> users = userMapper.selectList(null);
/*for (User user : users) {
System.out.println(user);
}*/
// 语法糖
users.forEach(System.out::println);
}
}
思考问题
- Sql谁帮我们写的?Mybatis-Plus
- 方法哪里来的? Mybatis-Plus都帮我们写好了
3、配置日志
我们所有的Sql现在是不可见的,我们希望知道它是怎么执行的,所以我们必须要看日志!
# 配置日志
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
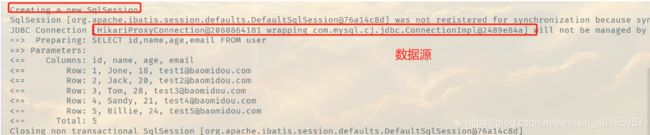
配置完毕日志之后,后面的学习就需要注意这个自动生成的SQL,我们也就会喜欢MyBatis-Plus!
4、CRUD拓展
插入操作
Insert
// 测试插入
@Test
public void testInsert(){
User user = new User();
user.setName("小爽帅到拖网速");
user.setAge(20);
user.setEmail("[email protected]");
int result = userMapper.insert(user); // 帮我们自动生成id
System.out.println(result); // 受影响的行数
System.out.println(user); // 发现,id自动回填
}

数据库插入id的默认值为:全局唯一ID 分布式id 雪花算法
主键生成策略
默认id_worker 全局唯一
分布式系统唯一ID生成方案:https://www.cnblogs.com/haoxinyue/p/5208136.html
雪花算法:
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。可以保证几乎全球唯一!
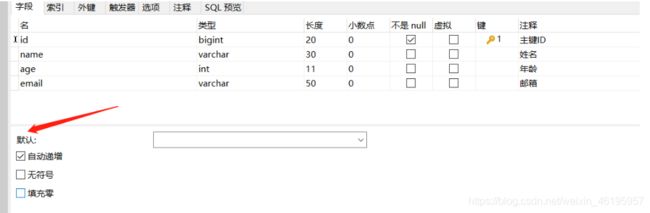
主键自增
我们需要配置主键自增:
1、实体类字段上增加 @TableId(type = IdType.AUTO)
2、数据库字段一定要是设置自增的!

其余的源码解释
public enum IdType {
AUTO(0), // 数据库id自增
NONE(1), // 未设置主键
INPUT(2), // 手动输入
ID_WORKER(3), // 默认的全局id
UUID(4), // 全局唯一id
ID_WORKER_STR(5); // ID_WORKER 字符串表示法
}
改为手动输入之后,就需要自己配置id
public class User {
// 对应数据库的主键(uuid、自增id、雪花算法、redis、zookeeper)
@TableId(type = IdType.INPUT) // 默认方案
private Long id;
private String name;
private Integer age;
private String email;
}

更新操作
update
// 测试更新
@Test
public void testUpdate(){
User user = new User();
user.setId(10L);
user.setName("小爽10L");
user.setAge(100);
// 注意: updateById 但是参数是一个对象
int i = userMapper.updateById(user);
User user1 = userMapper.selectById(10L);
System.out.println(user1);
System.out.println("受影响的行数"+i);
}
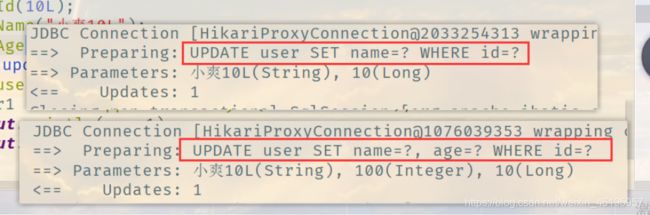
所有的sql都是自动帮你配置的!
自动填充
创建时间、修改时间!这些个操作一般都是自动化完成的,我们不希望手动更新!
阿里巴巴开发手册:所有的数据库表:gmt_create 、gmt_modify几乎所有的表都要配置上,而且需要自动化!
方式一:数据库级别的修改 (工作中是不允许你修改数据库)
1、在表中新增字段create_time、update_time
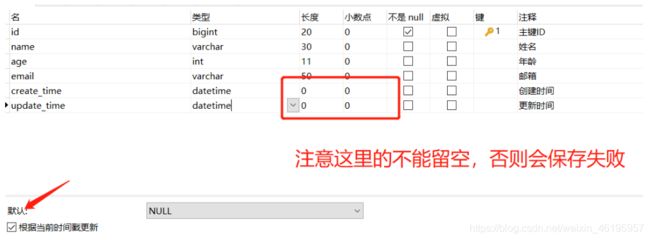
2、再次测试插入方法,我们需要先把实体类同步!
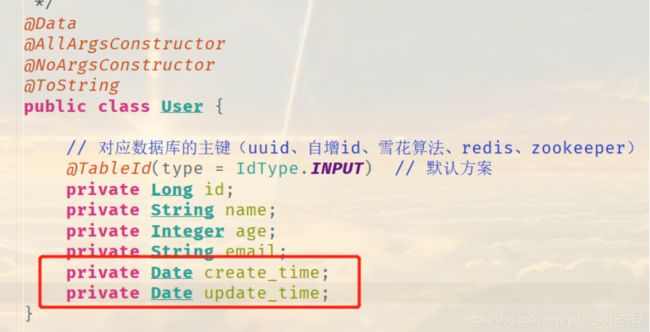
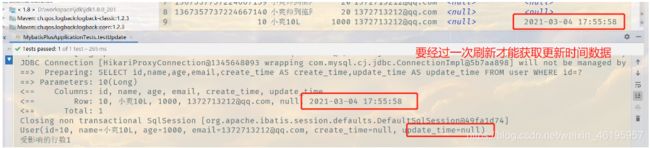
方式二:代码级别
- 删除数据库的默认值,更新操作

- 实体类字段属性上需要增加注解
// 字段添加填充内容
@TableField(fill = FieldFill.INSERT)
private Date create_time;
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date update_time;
- 编写处理器来处理这个注解即可!由于这个处理器在Springboot下面, mybatis会自动处理我们写的所有的处理器当我们执行插入操作的时候,自动帮我们通过反射去读取哪边有对应注解的字段,从而把处理器代码插入成功,会自动帮我把createTime,updateTime插入值
package com.shuang.handler;
import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.logging.Log;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.stereotype.Component;
import java.util.Date;
@Slf4j
@Component // 一定不要忘记把处理器加到IOC容器中!
public class MyMetaObjectHandler implements MetaObjectHandler {
// 插入时的填充策略
@Override
public void insertFill(MetaObject metaObject) {
log.info("start insert fill.....");
// setFieldValByName(String fieldName, Object fieldVal, MetaObject metaObject)
this.setFieldValByName("createTime",new Date(),metaObject);
this.setFieldValByName("updateTime",new Date(),metaObject);
}
// 更新时的填充策略
@Override
public void updateFill(MetaObject metaObject) {
this.setFieldValByName("updateTime",new Date(),metaObject);
}
}
注意:处理器指定字段中大写字母不能被识别成-小写字母的格式在填充策略中需修改为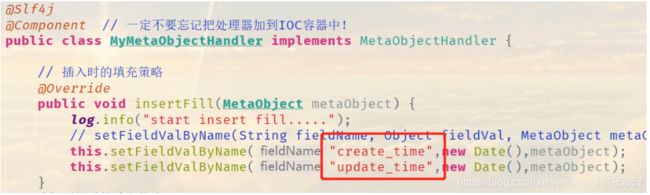
- 测试插入
- 测试更新、观察时间即可
乐观锁
在面试过程中,我们经常会被问道乐观锁,悲观锁,其实原理非常简单
乐观锁 OptimisticLockerInnerInterceptor
顾名思义十分乐观,它总是认为不会出现问题,无论干什么都不会上锁!如果出现问题就再次更新测试
这里引出 旧version 新version
乐观锁:当要更新一条记录的时候,希望这条记录没有被别人更新
乐观锁实现方式:
- 取出记录时,获取当前version
- 更新时,带上这个version
- 执行更新时, set version = newVersion where version = oldVersion
- 如果version不对,就更新失败‘
乐观锁:1、先查询,获得版本号 version = 1
-- A
update user set name = "xiaoshaung",version = version + 1
where id = 2 and version = 1
-- B 线程抢先完成,这个时候 version = 2 ,会导致 A 修改失败!
update user set name = "小爽",version = version + 1
where id = 2 and version = 1
测试Mybatis-Plus的乐观锁实现
1、给数据库中增加version字段
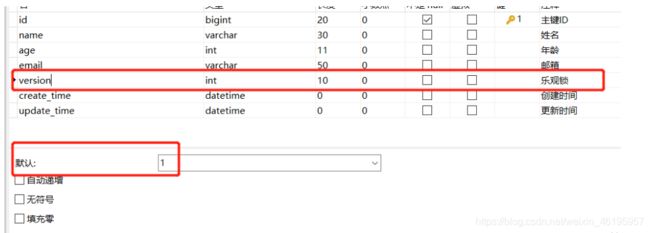
2、实体类加对应的字段
//乐观锁version注解
@Version
private Integer version;
3、注册组件
// 这个扫描本来是在我们 MybatisPlusApplication 主启动类中,现在我们把它放在配置类中
// 扫描mapper文件夹
@MapperScan("com.shuang.mapper")
@EnableTransactionManagement // 自动开启事务管理
@Configuration // 配置类
public class MybatisPlusConfig {
// 注册乐观锁插件
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor(){
return new OptimisticLockerInterceptor();
}
}
4、测试一下乐观锁的使用
// 测试乐观锁单线程成功
@Test
public void testOptimisticLock(){
// 1、查询用户信息
User user = userMapper.selectById(1);
// 2、修改用户信息
user.setName("xiaoshaung");
user.setEmail("[email protected]");
// 3、执行更新操作
userMapper.updateById(user);
}

// 测试乐观锁多线程失败 多线程
/*
线程1 虽然执行了赋值语句,但是还没进行更新操作,线程2就插队了抢先更新了,
由于并发下,可能导致线程1执行不成功
如果没有乐观锁就会覆盖线程2的值
*/
@Test
public void testOptimisticLock2(){
// 线程1
User user = userMapper.selectById(1);
user.setName("xiaoshaung111");
user.setEmail("[email protected]");
// 模拟另外一个线程执行了插队操作
// 线程2
User user2 = userMapper.selectById(1);
user2.setName("xiaoshaung222");
user2.setEmail("[email protected]");
userMapper.updateById(user2);
// 自旋锁来多次尝试提交
userMapper.updateById(user);
}
完成修改的是线程2
![]()

悲观锁
顾名思义十分悲观,它总是认为会出现问题,无论干什么都上锁!再去操作
我们这里主要讲究乐观锁机制
查询操作
// 测试查询
@Test
public void testSelectById(){
// 查询一个
User user = userMapper.selectById(1);
// 查询批量查询
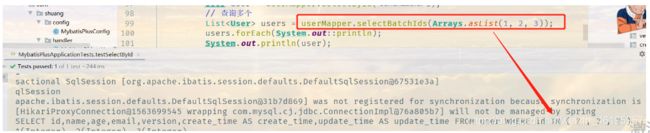
List<User> users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3));
users.forEach(System.out::println);
System.out.println(user);
}
// 条件查询 map
@Test
public void testSelectByBatchIds(){
HashMap<String, Object> map = new HashMap<>();
// 自定义要查询的条件
map.put("name","宇智波佐助");
List<User> users = userMapper.selectByMap(map);
users.forEach(System.out::println);
}

// 条件查询 map
@Test
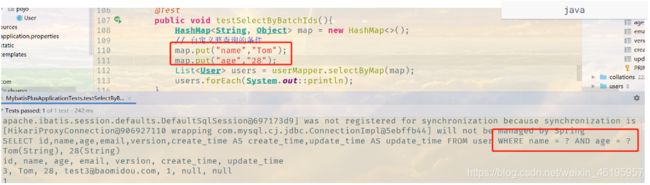
public void testSelectByBatchIds(){
HashMap<String, Object> map = new HashMap<>();
// 自定义要查询的条件
map.put("name","Tom");
map.put("age","28");
List<User> users = userMapper.selectByMap(map);
users.forEach(System.out::println);
}
分页查询
分页在网站使用的十分之多!
- 原始的limit 进行分页
- pageHepler 第三方插件
- Mybatis-Plus其实也内置了分页插件!
如何使用分页插件
1、拦截器组件即可
public class MybatisPlusConfig {
// 分页插件
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
}
2、直接使用Page对象即可!
// 测试分页查询
@Test
public void testPage(){
// 参数1 当前页 ;参数2 页面大小
Page<User> page = new Page<>(1,5);
userMapper.selectPage(page,null);
page.getRecords().forEach(System.out::println);
System.out.println("getCurrent()"+page.getCurrent());
System.out.println("page.getSize()"+page.getSize());
System.out.println("page.getTotal()"+page.getTotal());
}
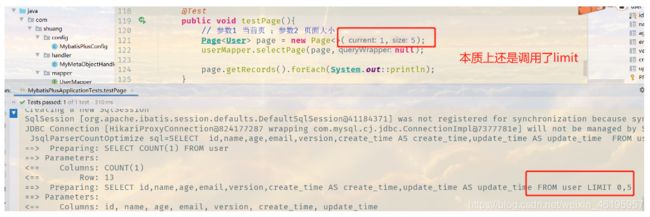
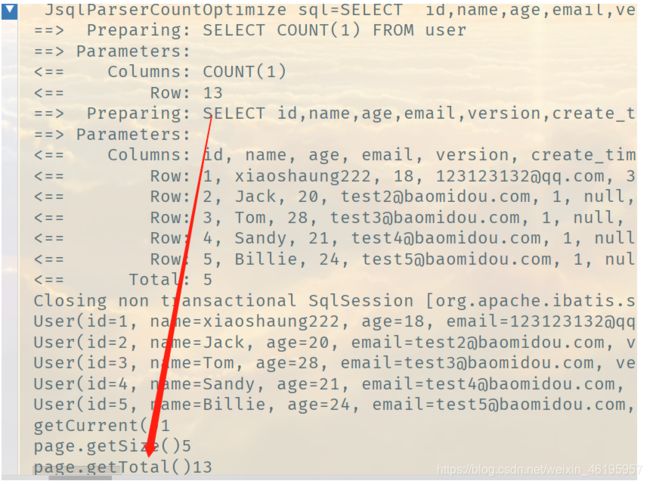
其实每次做分页查询之前都会进行总数查询
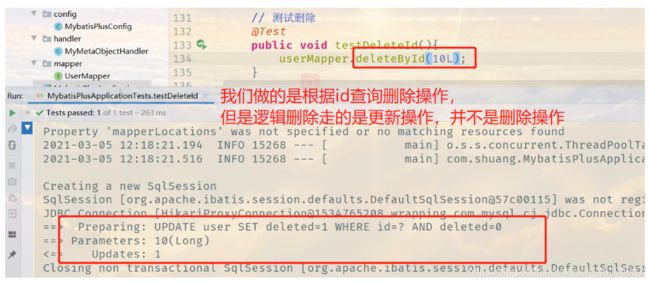
删除操作
1、根据id删除记录
// 测试删除
@Test
public void testDeleteId(){
userMapper.deleteById(1367357737224667139L );
}
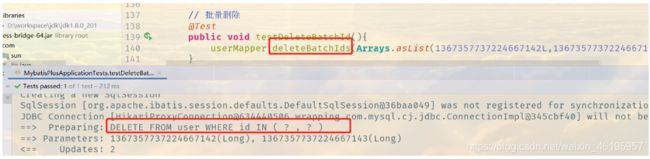
2、批量删除
// 批量删除
@Test
public void testDeleteBatchId(){
userMapper.deleteBatchIds(Arrays.asList(1367357737224667142L,1367357737224667143L));
}
3、通过map定制删除
//通过map删除
@Test
public void testDeleteMap(){
HashMap<String, Object> map = new HashMap<>();
map.put("id","1367357737224667144");
userMapper.deleteByMap(map);
}
逻辑删除
物理删除:从数据库中直接移除
逻辑删除:再数据库中没有被移除,而是通过一个变量来让它失效! deleted = 0 => deleted = 1
说明:
只对自动注入的sql起效:
- 插入: 不作限制
- 查找: 追加where条件过滤掉已删除数据,且使用 wrapper.entity 生成的where条件会忽略该字段
- 更新: 追加where条件防止更新到已删除数据,且使用 wrapper.entity 生成的where条件会忽略该字段
- 删除: 转变为 更新
例如:
- 删除: update user set deleted=1 where id = 1 and deleted=0
- 查找: select id,name,deleted from user where deleted=0
字段类型支持说明:
- 支持所有数据类型(推荐使用 Integer,Boolean,LocalDateTime)
- 如果数据库字段使用datetime,逻辑未删除值和已删除值支持配置为字符串null,另一个值支持配置为函数来获取值如now()
附录:
- 逻辑删除是为了方便数据恢复和保护数据本身价值等等的一种方案,但实际就是删除。
- 如果你需要频繁查出来看就不应使用逻辑删除,而是以一个状态去表示。
管理员可以查看被删除的记录! 防止数据的丢失,类似于回收站!
测试一下:
- 在数据表中增加一个deleted字段

- 实体类中增加字段
// 逻辑删除注解
@TableLogic
private Integer deleted;
- 配置
public class MybatisPlusConfig {
// 逻辑删除组件
@Bean
public ISqlInjector iSqlInjector(){
return new LogicSqlInjector();
}
}
7
# 配置逻辑删除
mybatis-plus.global-config.db-config.logic-delete-value= 1
mybatis-plus.global-config.db-config.logic-not-delete-value= 0
- 测试一下删除
让我们来查看一下数据库
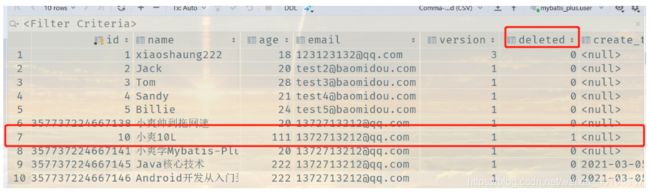
发现记录还在数据库中,但是deleted已经变化了
让我们来重新查询刚才被删除的记录
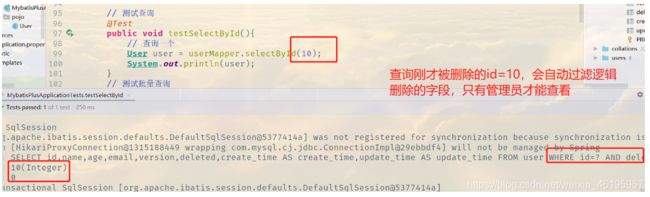
Creating a new SqlSession
SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@5377414a] was not registered for synchronization because synchronization is not active
JDBC Connection [HikariProxyConnection@1315188449 wrapping com.mysql.cj.jdbc.ConnectionImpl@29ebbdf4] will not be managed by Spring
==> Preparing: SELECT id,name,age,email,version,deleted,create_time AS create_time,update_time AS update_time FROM user WHERE id=? AND deleted=0 // 这里查询的是默认未被删除的 0
==> Parameters: 10(Integer)
<== Total: 0
总结
以上的所有CRUD操作以及其拓展操作,我们都必须精通掌握,会大大提高我们的工作和写项目的效率
5、性能分析插件
我们在平时的开发中,会遇到一些慢sql。测试 druid…
MP也提供性能分析插件,如果超过这个时间就停止运行!
- 导入插件
// SQL 执行效率插件
@Bean
@Profile({"dev","test"}) // 设置 dev test 环境开启, 保证我们的效率
public PerformanceInterceptor performanceInterceptor(){
PerformanceInterceptor performanceInterceptor = new PerformanceInterceptor();
// 在工作中,不允许用户等待
performanceInterceptor.setMaxTime(100); // 设置sql执行的最大时间,如果超过了则不执行
performanceInterceptor.setFormat(true); // 开启sql格式化
return performanceInterceptor;
}
- 配置Springboot测试环境为dev 或test
# 设置开发环境
spring.profiles.active=dev
- 测试使用
@Test
void contextLoads() {
// 查询全部用户
// selectList(参数) 这里的参数是一个Wrapper,条件构造器,这里我们先不用,写个null占着
List<User> users = userMapper.selectList(null);
/*for (User user : users) {
System.out.println(user);
}*/
// 语法糖
users.forEach(System.out::println);
}
只要超过了测试时间就会报错

这里还使用到了sql格式化工具

使用我们的性能分析插件就会提高的我们的效率
6、条件构造器
十分重要:Wrapper
我们写一些复杂的sql就可以使用它来替代!
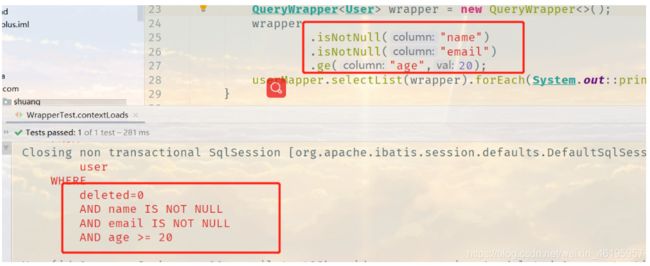
1、非空 大于
@Test
void contextLoads(){
// 查询 name 不为空的用户,并且邮箱不为空的用户,年龄大于等于20
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper
.isNotNull("name")
.isNotNull("email")
.ge("age",20);
userMapper.selectList(wrapper).forEach(System.out::println);
}
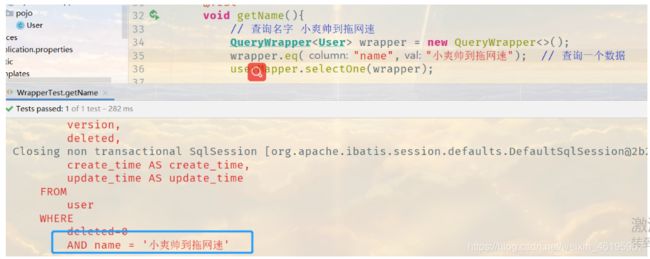
2、查询一个名字
@Test
void getOneName(){
// 查询名字 小爽帅到拖网速
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.eq("name","小爽帅到拖网速"); // 查询一个数据
userMapper.selectOne(wrapper);
}
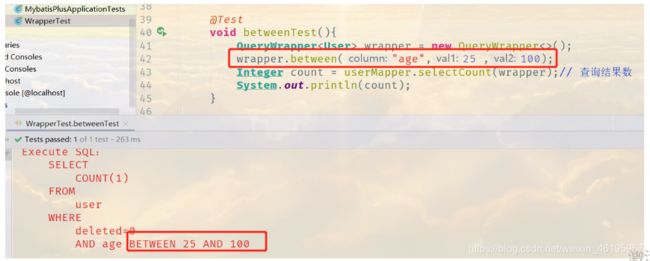
3、使用between
@Test
void betweenTest(){
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.between("age",25 ,100);
Integer count = userMapper.selectCount(wrapper);// 查询结果数
System.out.println(count);
}
4、like模糊查询
// 模糊查询
@Test
void likeTest(){
QueryWrapper<User> wrapper = new QueryWrapper<>();
// 左和右
wrapper.notLike("name","帅")
.likeRight("name","小");
List<Map<String, Object>> maps = userMapper.selectMaps(wrapper);
maps.forEach(System.out::println);
}
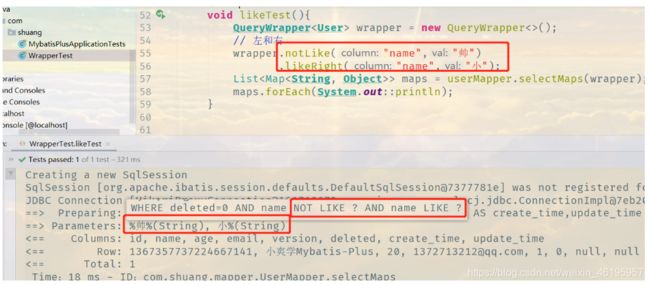
注意:这里查询的是 name 中不带“帅”字,且模糊查询为 “小%”,而在我们现在的数据库中有两个是符合查询条件,但是只查询出一个结果,原因是还有一个被我们逻辑删除了,deleted = 1
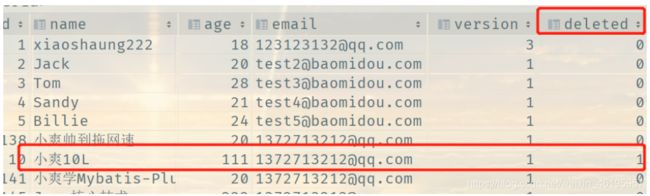
5、连接查询(内查询)
// 内查询
@Test
void innerJoinTest(){
QueryWrapper<User> wrapper = new QueryWrapper<>();
// id 在子查询中查找出来的
wrapper.inSql("id","select id from user where id<3");
List<Object> users = userMapper.selectObjs(wrapper);
users.forEach(System.out::println);
}

6、升序排序
// 通过id进行排序
@Test
void orderById(){
QueryWrapper<User> wrapper = new QueryWrapper<>();
//
wrapper.orderByDesc("id");
List<Object> objects = userMapper.selectObjs(wrapper);
objects.forEach(System.out::println);
}
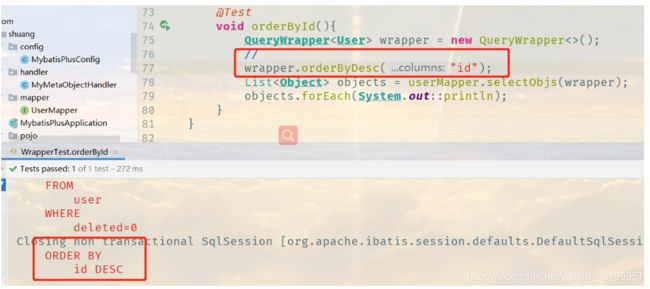
7、代码自动生成器
dao、pojo、service、controller 都自己编写完成
AutoGenerator 是 MyBatis-Plus 的代码生成器,通过 AutoGenerator 可以快速生成 Entity、Mapper、Mapper XML、Service、Controller 等各个模块的代码,极大的提升了开发效率。
注意:在全局配置中总有一句代码,怎么写都是爆红,我一开始以为是依赖冲突,一直去换依赖,步步排查才发现原来是有依赖导错了
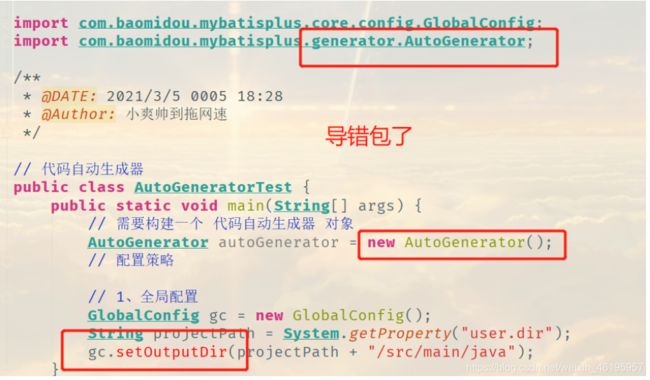
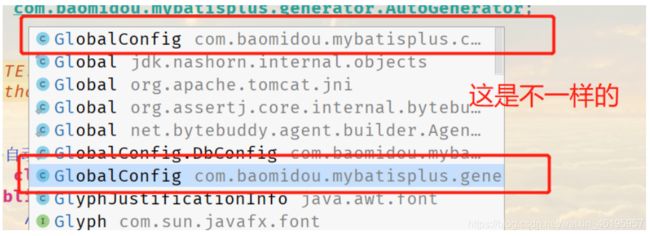
// 代码自动生成器
public class AutoGeneratorTest {
public static void main(String[] args) {
// 需要构建一个 代码自动生成器 对象
AutoGenerator mpg = new AutoGenerator();
// 配置策略
// 1、全局配置
GlobalConfig gc = new GlobalConfig();
String projectPath = System.getProperty("user.dir");
gc.setOutputDir(projectPath + "/src/main/java");
gc.setAuthor("小爽帅到拖网速");
gc.setOpen(false);
gc.setFileOverride(false); // 是否覆盖
gc.setServiceName("%Serive"); // 服务接口,去Service的I前缀
gc.setIdType(IdType.ID_WORKER); // 主键生成策略
gc.setDateType(DateType.ONLY_DATE);
gc.setSwagger2(true);
// 给代码自动生成器注入配置
mpg.setGlobalConfig(gc);
// 2、 设置数据源
DataSourceConfig dsc = new DataSourceConfig();
dsc.setUrl("jdbc:mysql://localhost:3306/mybatis_plus?useSSL=false&useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2b8");
dsc.setDriverName("com.mysql.cj.jdbc.Driver");
dsc.setUsername("root");
dsc.setPassword("83821979Zs");
dsc.setDbType(DbType.MYSQL);
mpg.setDataSource(dsc);
// 3、包的配置
PackageConfig pc = new PackageConfig();
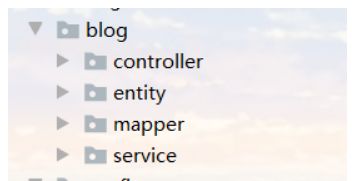
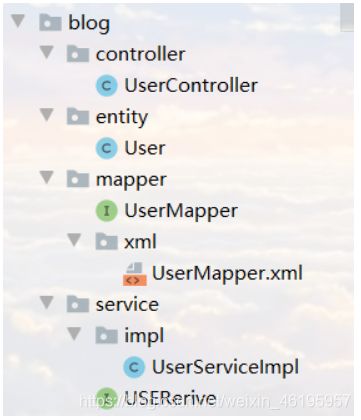
pc.setModuleName("blog");
pc.setParent("com.shuang");
pc.setEntity("entity");
pc.setMapper("mapper");
pc.setService("service");
pc.setController("controller");
mpg.setPackageInfo(pc);
// 4、策略配置
StrategyConfig strategy = new StrategyConfig();
strategy.setInclude("user"); // 设置要映射的表名
strategy.setNaming(NamingStrategy.underline_to_camel); // 内置下划线转驼峰命名
strategy.setColumnNaming(NamingStrategy.underline_to_camel);
strategy.setEntityLombokModel(true); // 自动Lombok
strategy.setLogicDeleteFieldName("deleted"); // 逻辑删除字段
// 自动填充策略
TableFill gmtCreate = new TableFill("gmt_create", FieldFill.INSERT);
TableFill gmtModifid = new TableFill("gmt_modifid", FieldFill.INSERT);
ArrayList<TableFill> tableFills = new ArrayList<>();
tableFills.add(gmtCreate);
tableFills.add(gmtModifid);
strategy.setTableFillList(tableFills);
// 乐观锁
strategy.setVersionFieldName("version");
strategy.setRestControllerStyle(true);
strategy.setControllerMappingHyphenStyle(true); // Localhost:8080/hello_id_2
mpg.setStrategy(strategy);
// 执行
mpg.execute();
}
}