python 数据分析7 pandas数据输入与输出
系列文章:Python 数据分析
文章目录
-
- 七、pandas 数据输入输出
-
- 1、读写文本格式的数据
-
- 逐块读取文本文件
- 将数据写出到文本格式
- 处理分隔符格式
- JSON数据
- XML和HTML:Web信息收集
- 2、二进制数据格式
-
- 读取Microsoft Excel文件
七、pandas 数据输入输出
输入输出通常可以划分为几个大类:读取文本文件和其他更高效的磁盘存储格式,加载数据库中的数据,利用Web API操作网络资源。
1、读写文本格式的数据
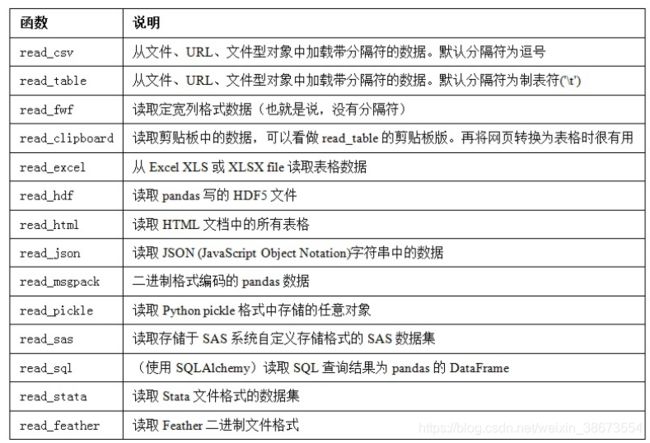
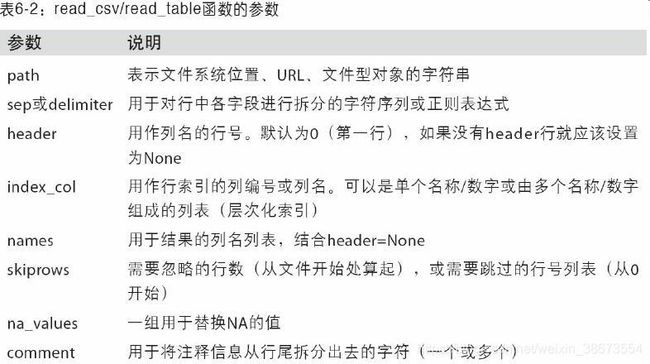
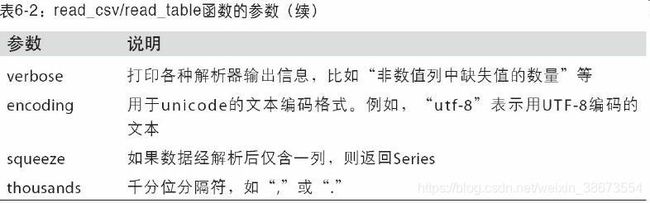
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。read_csv 和 read_table 用得最多。

逐块读取文本文件
只想读取文件的一小部分或逐块对文件进行迭代的情况:
只读几行(nrows):
pd.read_csv('examples/ex6.csv', nrows=5)
逐块读取(chunksize):
chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000)
将数据写出到文本格式
数据也可以被输出为分隔符格式的文本。
写到以逗号分割的文件:
data = pd.read_csv('examples/ex5.csv')
data.to_csv('examples/out.csv')
使用其他分隔符(仅输出):
import sys
data.to_csv(sys.stdout, sep='|')
缺失值在输出结果中会被表示为空字符串,可表示为其他:
data.to_csv(sys.stdout, na_rep='NULL')
禁用行和列的标签:
data.to_csv(sys.stdout, index=False, header=False)
以指定的顺序和列写出:
data.to_csv(sys.stdout, index=False, columns=['a', 'b', 'c'])
处理分隔符格式
直接使用Python内置的csv模块。将任意已打开的文件或文件型的对象传给 csv.reader:
reader = csv.reader(f, delimiter='|')

JSON数据
JSON(JavaScript Object Notation的简称)已经成为通过HTTP请求在Web浏览器和其他应用程序之间发送数据的标准格式之一。
json.loads:JSON->Python
import json
result = json.loads(obj)
json.dumps:Python->JSON
asjson = json.dumps(result)
pandas.read_json:JSON数组->Series/DataFrame(默认假设 JSON 数组中的每个对象是表格中的一行)
data = pd.read_json('examples/example.json')
to_json:pandas->JSON
data.to_json()
XML和HTML:Web信息收集
Python有许多可以读写常见的HTML和XML格式数据的库,包括lxml、Beautiful Soup和html5lib。lxml的速度比较快,但其它的库处理有误的HTML或XML文件更好。
pandas 有一个内置的功能,read_html,它可以使用 lxml 和 Beautiful Soup自动将 HTML 文件中的表格解析为 DataFrame 对象。
tables = pd.read_html('examples/fdic_failed_bank_list.html')
2、二进制数据格式
实现数据的高效二进制格式存储最简单的办法之一是使用Python内置的pickle序列化。pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle方法:
frame = pd.read_csv('examples/ex1.csv')
frame.to_pickle('examples/frame_pickle')
你可以通过pickle直接读取被pickle化的数据,或是使用更为方便的pandas.read_pickle:
pd.read_pickle('examples/frame_pickle')
读取Microsoft Excel文件
pandas 的 ExcelFile 类或 pandas.read_excel 函数支持读取存储在Excel 2003(或更高版本)中的表格型数据。
xlsx = pd.ExcelFile('examples/ex1.xlsx') # 创建ExcelFile实例
pd.read_excel(xlsx, 'Sheet1') # 读取表单数据
# 也可以
frame = pd.read_excel('examples/ex1.xlsx', 'Sheet1')
将 pandas 数据写入为 Excel 格式,首先创建一个 ExcelWriter,然后使用pandas 对象的 to_excel 方法将数据写入:
writer = pd.ExcelWriter('examples/ex2.xlsx') # 创建ExcelWriter实例
frame.to_excel(writer, 'Sheet1') # 写入到表单
writer.save()
# 也可以
frame.to_excel('examples/ex2.xlsx')