2023年合成数据最大的利用价值
开发成功的 AI 和 ML 模型需要访问大量高质量数据。但是,收集此类数据具有挑战性,因为:
- AI/ML 模型可以解决的许多业务问题都需要访问敏感的客户数据,例如个人身份信息 (PII) 或个人健康信息 (PHI)。收集和使用敏感数据会引发隐私问题,并使企业容易受到数据泄露的影响。出于这个原因,GDPR 和 CCPA 等隐私法规限制了个人数据的收集和使用,并对违反这些法规的公司处以罚款。
- 某些类型的数据收集成本高昂,或者很少见。例如,为自动驾驶汽车收集代表各种真实道路事件的数据可能非常昂贵。另一方面,银行欺诈是罕见事件的一个例子。收集足够的数据来开发机器学习模型来预测欺诈易具有挑战性,因为欺诈易很少见。
因此,企业正在转向以数据为中心的 AI/ML 开发方法,包括合成数据来解决这些问题。
与收集大型数据集相比,生成合成数据的成本低廉,并且可以在不损害客户隐私的情况下支持 AI/深度学习模型开发或软件测试。据估计,到 2024 年,用于开发 AI 和分析项目的数据中有 60% 将以合成方式生成。

图 1:未来合成数据超过真实数据
什么是合成数据?
合成数据,顾名思义,是人工创建的数据,而不是由实际事件生成的数据。它通常是在算法的帮助下创建的,用于广泛的活动,包括作为新产品和工具的测试数据、模型验证和 AI 模型训练。合成数据是一种数据增强。
为什么合成数据现在很重要?
合成数据很重要,因为它可以被生成以满足现有(真实)数据中不可用的特定需求或条件。这在许多情况下都很有用,例如
- 当隐私要求限制数据可用性或数据的使用方式时
- 测试要发布的产品需要数据,但是这些数据要么不存在,要么测试人员无法获得
- 机器学习算法需要训练数据。然而,特别是在自动驾驶汽车的情况下,这些数据在现实生活中的生成成本很高。
虽然合成数据在 90 年代首次开始使用,但 2010 年代丰富的计算能力和存储空间带来了合成数据的更广泛使用。
它有哪些应用?
可以从合成数据中受益的行业:
- 汽车和机器人
- 金融服务
- 医疗
- 制造业
- 安全
- 社交媒体
可以从合成数据中受益的业务功能包括:
- 营销
- 机器学习
- 敏捷开发和 DevOps
- 人力资源
合成数据使我们能够继续开发新的和创新的产品和解决方案,否则所需的数据将不存在或不可用。
比较合成数据和真实数据的性能
数据用于应用程序,数据质量最直接的衡量标准是数据在使用时的有效性。机器学习是当今最常见的数据用例之一。麻省理工学院的科学家们希望衡量来自合成数据的机器学习模型是否能够像从真实数据构建的模型一样出色。在 2017 年的一项研究中,他们将数据科学家分为两组:一组使用合成数据,另一组使用真实数据。使用合成数据的时间组中有70%能够产生与使用真实数据的组相当的结果。这将使合成数据比其他隐私增强技术(PET)更具优势,例如数据屏蔽和匿名化。
合成数据的好处
能够生成模拟真实事物的数据似乎是创建测试和开发场景的无限方法。虽然这有很多道理,但重要的是要记住,任何从数据中得出的合成模型都只能复制数据的特定属性,这意味着它们最终只能模拟总体趋势。
但是,与真实数据相比,合成数据有几个好处:
- 克服实际数据使用限制:由于隐私规则或其他法规,真实数据可能受到使用限制。合成数据可以在不暴露真实数据的情况下复制真实数据的所有重要统计属性,从而消除了这个问题。
这些好处表明,随着我们的数据变得更加复杂和受到更严密的保护,合成数据的创建和使用只会增长。
合成数据生成/创建 101
在确定创建合成数据的最佳方法时,首先要考虑您打算拥有的合成数据类型非常重要。有三大类可供选择,每类都有不同的优点和缺点:
全合成:此数据不包含任何原始数据。这意味着几乎不可能重新识别任何单个单元,并且所有变量仍然完全可用。
部分合成:只有敏感数据才会被替换为合成数据。这需要严重依赖插补模型。这导致模型依赖性降低,但确实意味着由于数据集中保留的真实值,因此可以进行一些披露。
混合合成:混合合成数据源自真实数据和合成数据。在保证数据集中其他变量之间的关系和完整性的同时,研究了原始数据的底层分布,并形成了每个数据点的最近邻。为真实数据的每条记录选择合成数据中的近似记录,然后将两者连接起来以生成混合数据。
构建合成数据的两种常规策略包括:
从分布中抽取数字:这种方法通过观察真实的统计分布和复制虚假数据来工作。这还可以包括创建生成模型。
基于智能体的建模:为了在这种方法中获得合成数据,需要创建一个模型来解释观察到的行为,然后使用相同的模型重现随机数据。它强调理解智能体之间的交互对整个系统的影响。
深度学习模型:变分自动编码器和生成对抗网络 (GAN) 模型是合成数据生成技术,通过为模型提供更多数据来提高数据效用。请随意详细了解数据增强和合成数据如何支持深度学习。
合成数据的挑战
尽管合成数据具有各种好处,可以简化组织的数据科学项目,但它也有局限性:
- 可能缺少异常值:合成数据只能模仿真实世界的数据,它不是它的精确复制品。因此,合成数据可能无法涵盖原始数据所具有的一些异常值。然而,数据中的异常值可能比常规数据点更重要,正如纳西姆·尼古拉斯·塔勒布(Nassim Nicholas Taleb)在他的《黑天鹅》一书中深入解释的那样。
机器学习和合成数据:构建 AI
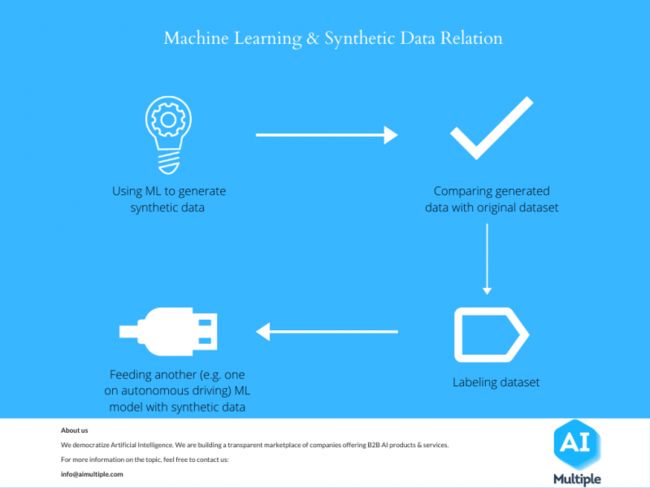
图 2:ML 和合成数据的关系
合成数据在机器学习中的作用正在迅速增加。这是因为机器学习算法使用大量数据进行训练,如果没有合成数据,这些数据可能难以获得或生成。它还可以在创建用于图像识别和类似任务的算法方面发挥重要作用,这些任务正在成为人工智能的基线。
使用合成数据来帮助开发机器学习还有其他几个好处:
- 建立初始合成模型/环境后,易于数据生成
- 标签的准确性是昂贵的,甚至不可能通过手工获得
- 合成环境的灵活性可根据需要进行调整,以改进模型
- 可用性可替代包含敏感信息的数据
在各自的机器学习社区中被广泛采用的 2 个合成数据用例是:
自动驾驶模拟
通过现实生活中的实验来学习在生活中是困难的,对算法来说也很难。
- 对于那些最终被自动驾驶汽车撞到的人来说,这尤其困难,就像优步在亚利桑那州发生的致命车祸一样。2虽然 Uber 缩减了他们在亚利桑那州的业务,但他们可能应该加强模拟来训练他们的模型。
为了最大限度地降低数据生成成本,谷歌等行业领导者一直依靠模拟来创建数百万小时的合成驾驶数据来训练他们的算法。3
生成对抗网络 (GAN)
这些网络也称为GAN或生成对抗神经网络,由Ian Goodfellow等人于2014年推出。这些网络是图像识别的最新突破。它们由一个鉴别器和一个生成器网络组成。虽然生成器网络生成尽可能接近现实的合成图像,但鉴别器网络旨在从合成图像中识别真实图像。这两个网络都构建了新的节点和层,以学习更好地完成任务。
虽然这种方法在图像识别中使用的神经网络中很受欢迎,但它的用途超出了神经网络。它也可以应用于其他机器学习方法。它通常被称为图灵学习,作为图灵测试的参考。在图灵测试中,人类与一个看不见的说话者交谈,试图了解它是机器还是人类。
合成数据工具
与合成数据相关的工具通常是为了满足以下需求之一而开发的:
- 用于软件开发和类似目的的测试数据
- 机器学习模型的训练数据
UnrealSynth 虚幻合成数据生成器 利用虚幻引擎的实时渲染能力搭建逼真的三维场景,为 YOLO 等 AI 模型的训练提供自动生成的图像和标注数据。UnrealSynth 生成的合成数据可用于深度学习模型的训练和验证,可以极大地提高各种行业细分场景中目标识别任务的实施效率,例如:安全帽检测、交通标志检测、施工机械检测、车辆检测、行人检测、船舶检测等。
UnrealSynth 生成合成数据的步骤:

1、将 GLB 文件添加到场景后,接下来就可以配置 UnrealSynth 合成数据生成参数,参数配置说明如下:
- 模型类别: 生成合成数据 synth.yaml 文件中记录物体的类型
- 环境变更 : 变更场景背景
- 截图数量 : 生成合成数据集 image 目录下的图像数量,在 train 和 val 目录下各自生成总数一半数量的图片
- 物体个数 : 设置场景中的物体个数,目前最多支持 5 个,并且是随机的选取模型的类别
- 随机旋转 : 场景中的物体随机旋转角度
- 随机高度 : 场景中的物体随机移动的高度
- 截图分辨率: 生成的 images 图像数据集中的图像分辨率
- 缩放 : 物体缩放调整大小
2、点击【确定】后会在本地目录中...\UnrealSynth\Windows\UnrealSynth\Content\UserData 自动生成两个文件夹以及一个 yaml 文件:images、labels、test.yaml 文件。
UnrealSynth\Windows\UnrealSynth\Content\UserData
|- images
|-train
|- 0.png
|- 1.png
|- 2.png
|- ...
|-val
|- 0.png
|- 1.png
|- 2.png
|- ...
|- labels
|-train
|- 0.txt
|- 1.txt
|- 2.txt
|- ...
|-val
|- 0.txt
|- 1.txt
|- 2.txt
|- ...
|- synth.yaml3、模型训练:数据集生成后有三个办法可以进行模型训练:使用 python 脚本、使用命令行、使用在线服务。
第一种是使用 python 脚本,需首先安装 ultralytics 包,训练代码如下所示:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.yaml') # build a new model from YAML
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
# Train the model
results = model.train(data='synth.yaml', epochs=100, imgsz=640)
第二种是使用命令行,需安装 YOLO 命令行工具,训练代码如下:
# Build a new model from YAML and start training from scratch
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
# Start training from a pretrained *.pt model
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
# Build a new model from YAML, transfer pretrained weights to it and start training
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
第三种是使用ultralytics hub 或者其他在线训练工具。
转载:2023年合成数据最大的利用价值 (mvrlink.com)