【性能测试】数据库索引问题定位/分析+ 架构优化+ SQL优化+ 代码优化(详全)
目录:导读
-
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
索引问题定位与分析
1、数据库服务器添加慢查询配置
1)my.cnf文件添加监控慢查询配置
cd /etc/my.cnf
vi my.cnf
添加如下配置:
slow_query_log=1
long_query_time=0.01

2)重启数据库服务器
systemctl restart mysqld
3)检查配置是否生效
show variables like '%slow_query_log%';

cd /var/lib/mysql

2、慢查询日志分析
1)打印查询次数前20的sql语句
mysqldumpslow -s at -t 20 huangshao-slow.log

2)对慢查询sql语句进行执行计划分析
在navicat里面拷贝慢查询语句,执行前加explain表示分析sql

Const:表中只有一个匹配行,用到primary key或unique key
Eq_ref:唯一性索引扫描,key的所有部分被连接联接查询使用,且key是unique或primary key
ref:非唯一性索引扫描,或只使用了联合索引的最左前缀
Range:索引范围扫描,在索引列上进行给定范围内的检索,如between,in(1,100) Index:遍历索引…
All:全表扫描
Prossible key:使用哪个索引能找到行
Keys:sql语句使用的索引
rows:mysql 根据索引选择情况,估算查找数据所需读取的行数
3、优化方案
1)添加索引
选择sql语句中where字句中的字段添加索引,并保存索引

索引类型:
Normal:普通索引,允许重复数据
Unique:非普通索引,不允许重复数据
Fulltext:全文索引,适用于大字段

2)sql执行计划分析
explain
select
id, user_name, password, age, gender, phone_num, email, address, create_time, update_time
from user
where user_name = 'user_100'

3)优化效果对比
Tps提升10倍,响应时间减少90%
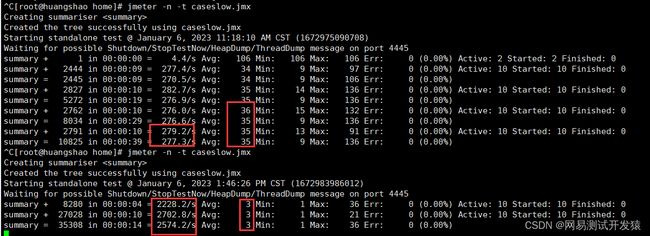
应用服务器cpu使用率提升65%

数据库服务器cpu使用率提升80%

数据库架构优化
1、分库分表
1)整除取余
比如有user有10个库,每个库有100张表
userid=100087存放的数据库和表格的路径
100087%10=7 第7个库
10087%100=87 第87张表
2)根据id最后1位和两位插入数据库和表
Id的最后1位为数据库的位置
Id的最后两位为表格的位置
2、读写分离,主从配置
主数据库进行写的操作
从数据库进行读的操作
Sql语句优化
1、在where及order by后的字段,添加索引。避免全表扫描。一般不要超4个
2、避免索引失效:
避免where字句中对字段进行null值判断,
避免where字句中对字段进行函数或者表达式的操作
避免where字句中对字段进行左右模糊查询
3、查询语句避免*,减少内存使用
4、用union或者union all 替代or
5、适当添加冗余字段,减少联表查询
6、建表的时候,使用数字类型的字段。比如type,status
7、尽量减少子查询,使用关联查询(left join,right join,inner join)替代
代码优化
1、使用对象池减少对重复对象的创建,比如tcp链接、数据库链接、多线程
2、调整连接数,连接池、数据库链接数、tomcat、nginx连接数
3、利用缓存技术增加缓存、本地缓存(tomcat内存之中,不走网络)、redis缓存
4、串行改并行,即单线程改多线程
5、同步改异步,使用场景:
本次调用接口的结果会影响后续操作的流程和结果;
本次调用接口的结果不会影响后续的操作的流程和结果;
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通

二、接口自动化项目实战

三、Web自动化项目实战

四、App自动化项目实战
五、一线大厂简历

六、测试开发DevOps体系

七、常用自动化测试工具

八、JMeter性能测试

九、总结(尾部小惊喜)
坚定的信念和不屈的毅力是成功的关键,只要你怀揣着梦想,敢于冒险并不断努力奋斗,就一定能够创造属于自己的辉煌人生。
相信自己的力量,坚持不懈地追逐梦想,即使面对困难和挑战,也要勇往直前,因为只有奋斗才能让生命绽放出最美的光芒。
在漫长的人生旅程中,不要畏惧失败与挫折,每一次跌倒都是一次成长,坚持追逐梦想,奋斗不止,你将绽放出属于自己的绚丽光芒。