Tensorflow 学习笔记-1
设计理念
-
TensorFlow 将图的定义和图的运行完全分开(符号主义)
- 符号式编程涉及很多的嵌入式和优化,不易理解和调试,但运行速度相对有所提升。
- 符号式计算一般是先定义各种变量,然后建立一个数据流图,在数据流图中规定各种变量之间的计算关系,最后需要对数据流图进行编译,但此时数据流图还是个空壳,里面没有任何实际数据,只有把需要运算的输入放进去之后,才能在整个模型中形成数据流,从而形成输出值。
import tensorflow as tf t = tf.add(8,9) print(t) # Tensor("Add:0", shape=(), dtype=int32) 感觉就是函数参数都定义好了,但是不执行- TensorFlow 中涉及的运算都要放在图中,而图的运行只发生在会话(session )中。开启会话后,就可以用数据取填充节点,进行运算;关闭会话后,就不能进行计算了。
import tensorflow as tf t = tf.add(8,9) sess = tf.Session() print(sess.run(t)) sess.close()
编程模型
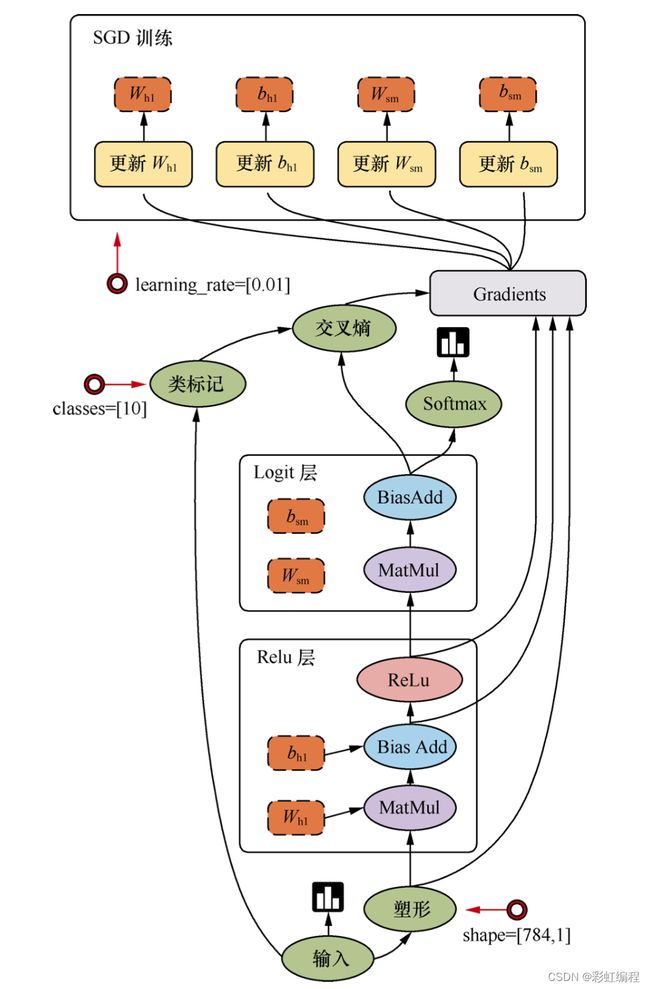
上图为一个简单的回归模型
计算过程:
首先中输入开始,经过塑形后,一层一层进行前向传播计算。Relu 层(隐藏层)里会有两个参数( W h 1 W_{h1} Wh1 和 b h 1 b_{h1} bh1),在输出前使用 Relu(Rectified Linear Units)激活函数做非线性处理。然后进入 Logit 层(输出层),学习两个参数 W s m W_{sm} Wsm 和 b s m b_{sm} bsm 。用Softmax 来计算出结果中各个类别的概率分布。用交叉熵来度量两个概率分布(原样本和输出结果的概率分布)之间的相似性。然后开始计算梯度,这里需要 W h 1 W_{h1} Wh1 、 b h 1 b_{h1} bh1 、 W s m W_{sm} Wsm 、 b s m b_{sm} bsm 以及交叉熵后的结果。随后进入 SGD 训练(反向传播),从上往下计算每一层的参数,依次进行训练。
边
TensorFlow 的边有两种连接关系:数据依赖、控制依赖
数据依赖
一般画成实线边,表示数据依赖,代表数据,即张量。任意维度的数据统称为张量。
在机器学习算法中,张量在数据流图中从前往后流动一遍就完成了一次前向传播,而残差(数理统计中,实际观察值与训练估计值之间的差)从后往前流动一遍就完成了一次反向传播。
控制依赖
一般画成虚线边,表示控制依赖。用于控制操作的运行,用来确保 happen-before 关系,这类边上没有数据流过,但源节点必须在目的节点执行前完成执行。
节点
图中节点(算子),代表一个操作(OP),一般用来表示施加的数学运算,也可以表示数据输入(feed in)的起点以及输出(push out)的终点,或许是读取/写入持久变量(persistent variable)的终点。
图
把操作任务描述成有向无环图。
如何构建一个图:
第一步,创建各个节点
# 创建一个常量操作运算符,产生一个 1*2 的矩阵
matrix1 = tf.constant([[3.,3.]])
# 创建一个常量操作运算符,产生一个 2*1 的矩阵
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法运算,把matrix1,matrix2作为输入
# 返回值 product 代表矩阵乘法的结果
product = tf.matmul(matrix1,matrix2)
会话
启动图的第一步:创建Session 对象,会话提供在图中执行操作的一些方法。
一般模式是,建立会话,此时会生成一张空图,在会话中添加节点和边,形成一张图,然后执行。
# 会话
with tf.Session() as sess:
result = sess.run([product])
print(result)
在调用 Session 对象的 run方法执行图时,传入一些 tensor,这个过程叫填充(feed);返回的结果类型根据输入的结果类型而定,这个过程叫取回(fetch)。
会话是图交互的桥梁,一个会话可以有多个图,会话可以修改图的结构,也可以往图中注入数据进行计算。因此,Session 有两个 API:Extend(在 Graph 中添加节点和边)、run(输入计算的节点和必要的数据后,进行计算,并输出运算的结果)
设备
是指一块可以用来运算并且拥有自己的地址空间的硬件,如 CPU、GPU。
TensorFlow 为了实现分布式执行操作,充分利用计算机资源,可以明确指定在那个设备上执行。
with tf.Session() as sess:
with tf.device('\gpu:0'):
matrix1 = tf.constant([[3.,3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1,matrix2)
变量
变量(variable)是一种特殊的数据,在图中有固定位置,不像普通张量一样可以流动。
例如创建一个变量张量,使用 tf.Variable()构造函数,这个构造函数需要一个初始值,初始值的形状和类型决定这个变量的形状和类型。
# 创建一个变量,初始化为标量 0
state = tf.Variable(0,name='counter')
TensorFlow 还提供了填充机制,可以在构建图时使用 tf.placeholder()临时替代任意操作的张量,在调用 Session 对象的 run()方法去执行图时,使用填充数据作为调用的参数,调用结束后,填充数据就消失。
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1,input2)
with tf.Session() as sess:
print(sess.run([output],feed_dict={input1:[7.],input2:[2.]}))
内核
内核是能够运行在特定设备上的一种对操作的实现。因此,同一个操作可能会对应多个内核。当自定义一个操作时,需要把新操作和内核通过注册的方式添加到系统中。