TensorFlow学习笔记----3.常用函数2
一.Gradient tape
我们可以在with结构中,使用Gradient tape实现某个函数对指定参数的求导运算 配合上一个文件讲的variable函数可以实现损失函数loss对参数w的求导计算 with结构记录计算过程,gradient求出张量的梯度
with tf.GradientTape()as tape:
若干个计算过程
grad=tape.gradient(函数,对谁求导)
with tf.GradientTape() as tape:
w=tf.Variable(tf.constant(3.0))#w的初始值=3
# 损失函数是w的平方,损失函数对w求导就是2w
loss=tf.pow(w,2)
grad=tape.gradient(loss,w)
print(grad)运行结果:
![]()
二.enumerate
enumerate是Python的内建函数,它可遍历每个元素(如列表、元组或字符串),
组合为:索引 元素,常在for循环中使用
enumerate(列表名)
seq=['one','two','three']
for i,element in enumerate(seq):
print(i,enumerate)运行结果:

三.tf.one_hot
独热编码(one-hot encoding):在实现分类问题时,我们常用独热码来做标签
标记类型:1表示是,0表示非
(0狗尾鸢尾 1杂色鸢尾 2弗吉尼亚鸢尾)
标签:1
独热码:(0,1,0)
tf.one_hot()函数将待转换数据,转换为one-hot形式的数据输出
tf.one_hot(待转换数据,depth=几分类)
# 比如:3分类
classes=3
labels=tf.constant([1,0,2])#输出的元素值最小为0,最大为2
output=tf.one_hot(labels,depth=classes)
print("output=",output)运行结果:

四.tf.nn.softmax

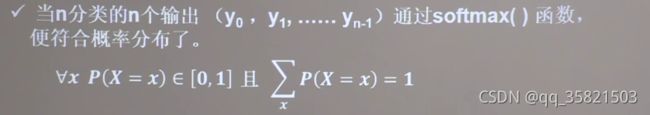
softmax函数可以使n分类的n个输出y0,y1,...,yn-1符合概率分布,即每个输出值变为0到1之间的概率值。这些概率值的和为1。
# 把神经网络前向传播结果1.01 2.01 -0.66,组成张量y,送入softmax函数
y=tf.constant([1.01,2.01,-0.66])
y_pro=tf.nn.softmax(y)
# 输出是这些符合概率分布的值
print("after softmax,y_pro is:",y_pro)运行结果:
![]()
五.assign_sub

assign_sub函数常用于参数的自更新,等待更新的w,要先被指定为可更新可训练,也就是variable类型,才可以实现自更新
w=tf.Variable(4)#先定义一个初值为4的variable类型的值
w.assign_sub(1)#对w做自减操作,自减的内容写在括号里,此处:w-=1
print(w)![]()
六.tf.argmax
tf.argmax可以返回指定操作轴方向最大值的索引号
axis=0表示纵向,axis=1表示横向
import numpy as np
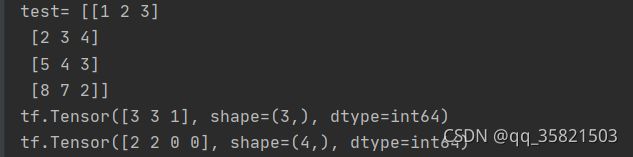
test=np.array([[1,2,3],[2,3,4],[5,4,3],[8,7,2]])
print("test=",test)
print(tf.argmax(test,axis=0))#返回每一列最大的索引
print(tf.argmax(test,axis=1))#返回每一行最大的索引运行结果: