TensorFlow学习笔记--MLP多层感知机识别手写数字1-9
# 简单粗暴tensorflow2.0合集 视频p7-p9 多层感知机(MLP)利用多层感知机MLP实现手写数字0-9的mnist数据集的识别
import tensorflow as tf
import numpy as np
# 数据的获取和预处理
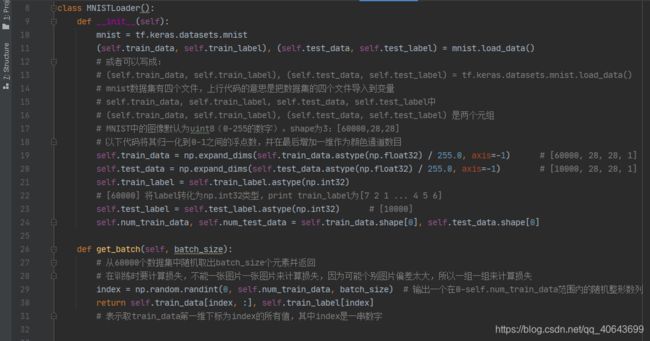
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = mnist.load_data()
# 或者可以写成:
# (self.train_data, self.train_label), (self.test_data, self.test_label) = tf.keras.datasets.mnist.load_data()
# mnist数据集有四个文件,上行代码的意思是把数据集的四个文件导入到变量
# self.train_data, self.train_label, self.test_data, self.test_label中
# (self.train_data, self.train_label), (self.test_data, self.test_label) 是两个元组
# MNIST中的图像默认为uint8(0-255的数字)。shape为3:[60000,28,28]
# 以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道数目
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1) # [60000, 28, 28, 1]
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1) # [10000, 28, 28, 1]
self.train_label = self.train_label.astype(np.int32)
# [60000] 将label转化为np.int32类型,print train_label为[7 2 1 ... 4 5 6]
self.test_label = self.test_label.astype(np.int32) # [10000]
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
# 从60000个数据集中随机取出batch_size个元素并返回
# 在训练时要计算损失,不能一张图片一张图片来计算损失,因为可能个别图片偏差太大,所以一组一组来计算损失
index = np.random.randint(0, self.num_train_data, batch_size) # 输出一个在0-self.num_train_data范围内的随机整形数列
return self.train_data[index, :], self.train_label[index]
# 表示取train_data第一维下标为index的所有值,其中index是一串数字
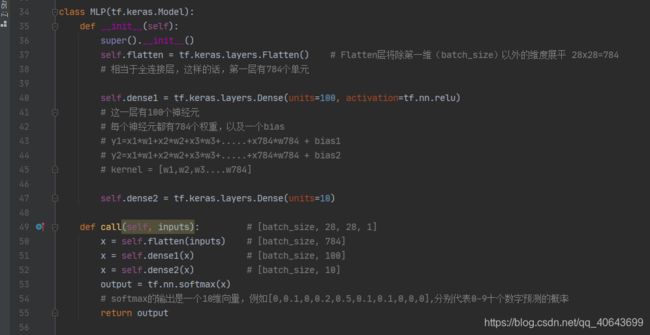
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten() # Flatten层将除第一维(batch_size)以外的维度展平 28x28=784
# 相当于全连接层,这样的话,第一层有784个单元
self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
# 这一层有100个神经元
# 每个神经元都有784个权重,以及一个bias
# y1=x1*w1+x2*w2+x3*w3+.....+x784*w784 + bias1
# y2=x1*w1+x2*w2+x3*w3+.....+x784*w784 + bias2
# kernel = [w1,w2,w3....w784]
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs): # [batch_size, 28, 28, 1]
x = self.flatten(inputs) # [batch_size, 784]
x = self.dense1(x) # [batch_size, 100]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
# softmax的输出是一个10维向量,例如[0,0.1,0,0.2,0.5,0.1,0.1,0,0,0],分别代表0-9十个数字预测的概率
return output
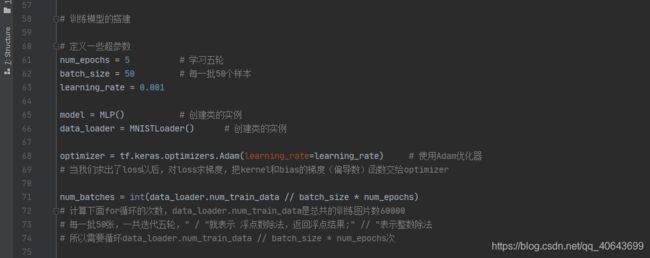
# 训练模型的搭建
# 定义一些超参数
num_epochs = 5 # 学习五轮
batch_size = 50 # 每一批50个样本
learning_rate = 0.001
model = MLP() # 创建类的实例
data_loader = MNISTLoader() # 创建类的实例
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate) # 使用Adam优化器
# 当我们求出了loss以后,对loss求梯度,把kernel和bias的梯度(偏导数)函数交给optimizer
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
# 计算下面for循环的次数,data_loader.num_train_data是总共的训练图片数60000
# 每一批50张,一共迭代五轮," / "就表示 浮点数除法,返回浮点结果;" // "表示整数除法
# 所以需要循环data_loader.num_train_data // batch_size * num_epochs次
# 开始训练
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size) # X是图像,y是标签
with tf.GradientTape() as tape:
y_pred = model(X) # y_pred是一个50行,10列的向量
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
# 交叉熵损失函数,例如每个图片的y_pred是[0,0.1,0,0.2,0.5,0.1,0.1,0,0,0],y为[0,1,0,0,0,0,0,0,0,0],经过交叉熵损失函数使得输出为一个数
# 因为是50张,所以输出为50维向量
loss = tf.reduce_mean(loss) # 对输出为50维的向量求平均
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables) # 对loss中每一个变量model.variables即kernel = [w1,w2,w3....w784]和bias求偏导
# 对录像带的功能,我自己的理解是上面循环输出的loss是一个一个的浮点数,录像带让这些数变成函数
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables)) # 梯度下降过程
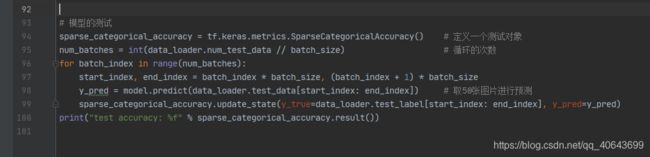
# 模型的测试
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() # 定义一个测试对象
num_batches = int(data_loader.num_test_data // batch_size) # 循环的次数
for batch_index in range(num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict(data_loader.test_data[start_index: end_index]) # 取50张图片进行预测
sparse_categorical_accuracy.update_state(y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
本文是通过自定义类来搭建网络的,没有使用TensorFlow内置的函数库api来搭建网络,灵活性更高。
1.定义加载数据集的类
1.1 第8-9行
class MNISTLoader():
def __init__(self):
def __init__(self)是构造函数,作用是数据集加载的初始化。在函数里需要加载数据集,数据集中像素值的归一化,增加色彩维度,以及其他一些备用张量的定义。当创建该类的实例时,构造函数将被自动执行。
1.2 第19-20行
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1) # [60000, 28, 28, 1] self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1) # [10000, 28, 28, 1]
数据集元素的初始化时除以255.0不是255
2. 自定义模型的类的创建
2.1 34行
class MLP(tf.keras.Model): 表示自定义的MLP类继承了tf.keras.Model父类
2.2 35行
def __init__(self):
super().__init__()
在自定义Mlp模型类的初始化函数中,要把模型中所有用到的层以及各层的参数定义好,注意self代表实例
2.3 49行
call方法:在 Python 中,对类的实例 myClass 进行形如 myClass() 的调用等价于 myClass.__call__(),在call方法内进行模型的搭建。
当定义类的实例: model = MLP(),等同于 model = MLP.__call__(),其括号内应该传入inputs
3. 模型训练前需要定义一些超参数
3.1 61行
epoch是指正在数据集被循环迭代的次数,epoch = 5 代表数据集被循环训练了5轮
3.2 71行
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
4. 开始训练

注意自定义的类里的变量与类外的变量名称不能一样,否则会警告
X 的shape为(50,28,28,1) y的shape为(50,10)