Node.js(一、Node.js基础、模块加载机制、包等)
Node.js(一、Node.js基础、模块加载机制、包等)
- 1、Node.js基础
-
- 1.1、Node是什么
- 1.2、Node环境安装失败解决方法
-
- 1.2.1、Node环境搭建
- 1.2.2、错误代码2502、2503
- 1.2.3、执行命令报错
- 1.2.4、PATH环境变量
- 1.2.5、Node程序执行
- 1.2.6、Node环境和浏览器环境区别
- 1.3、Node.js的组成
-
- 1.3.1、Node.js基础语法
- 1.3.2、Node.js全局对象global
- 2、模块加载及第三方包
-
- 2.1、Node.js模块化开发
-
- 2.1.1、模块成员导出
- 2.1.2、模块成员的导入
- 2.1.3、模块成员导出的另一种方式(exports和module.exports区别)
- 2.2、系统模块
-
- 2.2.1、什么是系统模块
- 2.2.2、系统模块fs 文件操作
- 2.2.3、系统模块path 路径操作
- 2.2.4、Buffer对象
- 2.2.5、HTTP模块
- 2.3、第三方模块(又称“包”)
-
- 2.3.1、什么是第三方模块
- 2.3.2、获取第三方模块
- 2.3.3、第三方模块nodemon
- 2.3.4、第三方模块nrm
- 2.3.5、cnpm使用
- 2.3.6、yarn使用
- 2.3.7、第三方模块Gulp
- 2.4、package.json
-
- 2.4.1、node_modules文件夹的问题
- 2.4.2、package.json文件的作用
- 2.4.3、项目依赖
- 2.4.4、开发依赖
- 2.4.5、package-lock.json文件的作用
- 2.5、Node.js中模块的加载机制
-
- 2.5.1、模块查找规则-当模块拥有路径但没有后缀时
- 2.5.2、==模块查找规则-当模块没有路径且没有后缀时==
1、Node.js基础
1.1、Node是什么
Node是一个基于Chrome V8引擎的Javascript代码运行环境。
什么是V8引擎?
V8引擎是一款专门解释和执行JS代码的虚拟机, 任何程序只要集成了V8引擎都可以执行JS代码
例如:
1、V8引擎嵌入到浏览器中,那么我们写的JavaScript代码就会被浏览器所执行;
2、将V8引擎嵌入到NodeJS中,那么我们写的JavaScript代码就会被NodeJS所执行。
什么是运行环境?
运行环境 就是 生存环境
地球是人类的生存环境
浏览器是网页的生存环境
windows是.exe应用程序的生存环境
Android是.apk应用程序的生存环境
也就是说运行环境就是特定事物的生存环境
NodeJS也是一个生存的环境, 由于NodeJS中集成了V8引擎
所以NodeJS是JavaScript应用程序的一个生存环境
总结
NodeJS不是一门编程语言, NodeJS是一个运行环境,由于这个运行环境集成了V8引擎, 所以在这个运行环境下可以运行我们编写的JS代码, 这个运行环境最大的特点就是提供了操作"操作系统底层的API",通过这些底层API我们可以编写出网页中无法实现的功能(诸如: 打包工具, 网站服务器等)
1.2、Node环境安装失败解决方法
1.2.1、Node环境搭建
- 搭建方式一:
1.官网下载.msi安装包: https://nodejs.org/zh-cn/
2.全程下一步
3.在命令行工具中输入 node -v - 搭建方式二:
1.官网下载.zip安装包: https://nodejs.org/zh-cn/
2.解压下载好的安装包
3.在"高级系统设置"中手动配置环境变量
4.在命令行工具中输入 node -v - 搭建方式三:
1.下载NVM: https://github.com/coreybutler/nvm-windows
2.在D盘创建dev目录
3.在Dev目中中创建两个子目录nvm和nodejs, 并且把nvm包解压进去nvm目录中
4.在install.cmd文件上面右键选择【以管理员身份运行】
在终端中直接按下回车
将弹出的文件另存为到NVM目录
5.打开settings.txt文件. 修改
root: D:\Developer\Dev\NVM
path: D:\Developer\Dev\Node
6.配置环境变量
NVM_HOME: D:\Developer\Dev\NVM
NVM_SYMLINK: D:\Developer\Dev\Node
在Path中添加 %NVM_HOME% %NVM_SYMLINK%
7.在命令行工具中输入 nvm version
8.NVM常用命令- nvm list 查看当前安装的Node.js所有版本
- nvm install 版本号 安装指定版本的Node.js
- nvm uninstall 版本号 卸载指定版本的Node.js
- nvm use 版本号 选择指定版本的Node.js
1.2.2、错误代码2502、2503
失败原因:系统账户权限不足。
解决方法:
1、以管理员身份运行powershell命令工具。
2、输入运行安装包命令 msiexec / package node 安装包位置。
1.2.3、执行命令报错
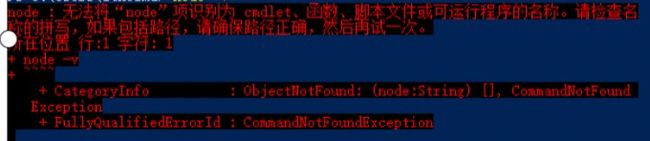
失败原因:Node安装目录写入环境变量失败。
解决方法:将Node安装目录添加到环境变量中。
1.2.4、PATH环境变量
存储系统中的目录,在命令行中执行命令的时候系统会自动去这些目录中查找命令的位置。

1.2.5、Node程序执行
Node程序执行方式:
- 由于浏览器中集成了V8引擎, 所以浏览器可以解释执行JS代码
1、可以直接在浏览器控制台中执行JS代码
2、可以在浏览器中执行JS文件中的JS代码 - 由于NodeJS中也集成了V8引擎, 所以浏览器可以解释执行JS代码
1、可以直接在命令行工具中编写执行JS代码(REPL – Read Eval Print Loop:交互式解释器)
2、可以在命令行工具中执行JS文件中的JS代码。
1.2.6、Node环境和浏览器环境区别
NodeJS环境和浏览器环境一样都是一个JS的运行环境, 都可以执行JS代码.
但是由于宿主不同所以特点也有所不同
- 内置对象不同
- 浏览器环境中提供了window全局对象
- NodeJS环境中的全局对象不叫window, 叫global
- this默认指向不同
- 浏览器环境中全局this默认指向window
- NodeJS环境中全局this默认指向空对象{}
- API不同
- 浏览器环境中提供了操作节点的DOM相关API和操作浏览器的BOM相关API
- NodeJS环境中没有HTML节点也没有浏览器, 所以NodeJS环境中没有DOM/BOM
1.3、Node.js的组成
- Javascript由三部分组成,ECMAScript、DOM、BOM。
- Node.js是由ECMScript及Node环境提供的一些附加API组成的,包括文件、网络、路径等等一些更强大的API。
1.3.1、Node.js基础语法
所有ECMAScript语法在Node环境中都可以使用。
在Node环境下执行代码,使用Node命令执行后缀为.js的文件即可。如:node test.js
1.3.2、Node.js全局对象global
在浏览器中全局对象是window,在Node中全局对象是global。
和浏览器一样Node环境中的全局对象也提供了很多方法属性供我们使用。Node中全局对象下有以下方法,可以在任何地方使用,global可以省略。
中文文档地址: http://nodejs.cn/api/
- console.log() 在控制台中输出
- setTimeout() 设置超时定时器
- clearTimeout() 清除超时时定时器
- setInterval() 设置间歇定时器
- clearInterval() 清除间歇定时器
- __dirname: 当前文件所在文件夹的绝对路径console.log(__dirname)
- __filename: 当前文件的绝对路径
- console : 和浏览器中window对象上的打印函数一样
2、模块加载及第三方包
2.1、Node.js模块化开发
什么是模块?
- 浏览器开发中的模块
在浏览器开发中为了避免命名冲突, 方便维护等等。
我们采用类或者立即执行函数的方式来封装JS代码, 来避免命名冲突和提升代码的维护性。
其实这里的一个类或者一个立即执行函数就是浏览器开发中一个模块。
let obj = {
模块中的业务逻辑代码
};
;(function(){
模块中的业务逻辑代码
window.xxx = xxx;
})();
存在的问题:没有标准没有规范 - NodeJS开发中的模块
- NodeJS采用CommonJS规范实现了模块系统。
- Node.js规定一个Javascript文件就是一个模块,模块内部定义的变量和函数默认情况下在外部无法得到
- 模块内部可以使用exports对象进行成员导出,使用require方法导入其他模块。
- CommonJS规范:
CommonJS规范规定了如何定义一个模块, 如何暴露(导出)模块中的变量函数, 以及如何使用定义好的模块- 在CommonJS规范中一个文件就是一个模块
- 在CommonJS规范中每个文件中的变量函数都是私有的,对其他文件不可见的
- 在CommonJS规范中每个文件中的变量函数必须通过exports暴露(导出)之后其它文件才可以使用
- 在CommonJS规范中想要使用其它文件暴露的变量函数必须通过require()导入模块才可以使用
2.1.1、模块成员导出
// a.js
// 在模块内部定义变量
let version = 1.0;
// 在模块内部定义方法
const sayHi = name => `${name}`;
// 向模块外部导出数据
exports.version = version;
exports.sayHi = sayHi;
在NodeJS中想要导出模块中的变量函数有三种方式:
- 通过exports.xxx = xxx导出
- 通过module.exports.xxx = xxx导出
- 通过global.xxx = xxx导出
注意点:
无论通过哪种方式导出, 使用时都需要先导入(require)才能使用
通过global.xxx方式导出不符合CommonJS规范, 不推荐使用。
2.1.2、模块成员的导入
// b.js
// 在b.js模块中导入模块a
let a = require('./b.js');
// 输出b模块中的version变量
console.log(a.version);
// 调用b模块中的sayHi方法,并输出其返回值
console.log(a.sayHi('lgg'));
导入模块时后缀可以省略
require注意点:
- require导入模块时可以不添加导入模块的类型
如果没有指定导入模块的类型, 那么会依次查找.js .json .node文件
无论是三种类型中的哪一种, 导入之后都会转换成JS对象返回给我们。 - 导入自定义模块时必须指定路径
require可以导入"自定义模块(文件模块)"、“系统模块(核心模块)”、“第三方模块”
导入"自定义模块"模块时前面必须加上路径
导入"系统模块"和"第三方模块"是不用添加路径 - 导入"系统模块"和"第三方模块"是不用添加路径的原因
如果是"系统模块"直接到环境变量配置的路径中查找
如果是"第三方模块"会按照module.paths数组中的路径依次查找
2.1.3、模块成员导出的另一种方式(exports和module.exports区别)
module.exports.version = version;
module.exports.sayHi = sayHi;
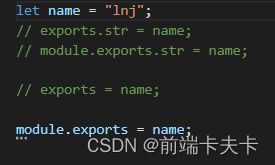

- exports是module.exports的别名(地址引用关系),导出对象最终以module.exports为准。
- exports只能通过 exports.xxx方式导出数据, 不能直接赋值。
- module.exports既可以通过module.exports.xxx方式导出数据, 也可以直接赋值。
注意点:
在企业开发中无论哪种方式都不要直接赋值, 这个问题只会在面试中出现。
2.2、系统模块
2.2.1、什么是系统模块
Node运行环境提供的API,因为这些API都是以模块化的方式进行开发的,所以我们又称Node运行环境提供的API为系统模块。
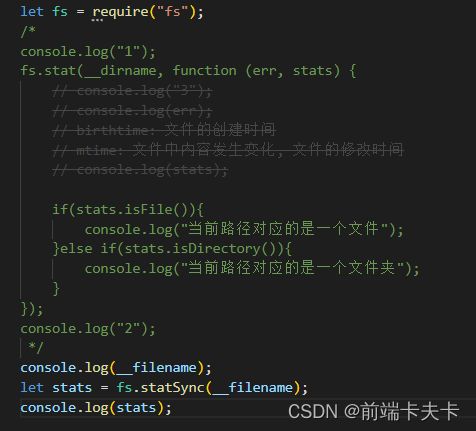
2.2.2、系统模块fs 文件操作
f: file文件,s: system系统,文件操作系统。封装了各种文件相关的操作。
注意:后面带Sync是同步方法,不带Sync是异步方法
- 查看文件状态
fs.stat(path[, options], callback)
fs.statSync(path[, options])
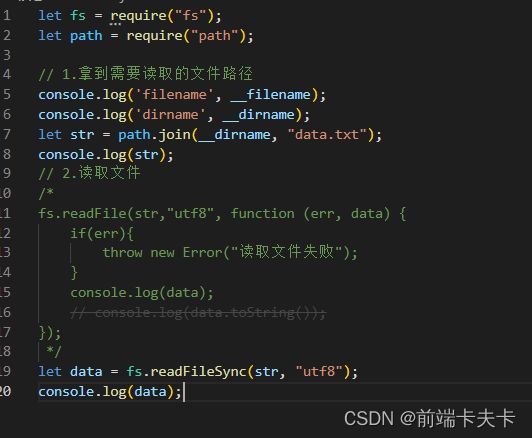
- 文件读取
fs.readFile(path[, options], callback)
fs.readFileSync(path[, options])
注意点:
没有指定第二个参数, 默认会将读取到的数据放到Buffer中
第二个参数指定为utf8, 返回的数据就是字符串。
- 文件写入
fs.writeFile(file, data[, options], callback)
fs.writeFileSync(file, data[, options])

- 追加写入
fs.appendFile(path, data[, options], callback)
fs.appendFileSync(path, data[, options])

- 大文件操作
前面讲解的关于文件写入和读取操作都是一次性将数据读入内存或者一次性写入到文件中。但是如果数据比较大, 直接将所有数据都读到内存中会导致计算机内存爆炸,卡顿,死机等。所以对于比较大的文件我们需要分批读取和写入。
fs.createReadStream(path[, options])
fs.createWriteStream(path[, options])
let fs = require("fs");
let path = require("path");
/* // 1.拼接读取的路径
let str = path.join(__dirname, "lnj.txt");
// 2.创建一个读取流
let readStream = fs.createReadStream(str, {encoding : "utf8", highWaterMark : 1});
// 3.添加事件监听
readStream.on("open", function () {
console.log("表示数据流和文件建立关系成功");
});
readStream.on("error", function () {
console.log("表示数据流和文件建立关系失败");
});
readStream.on("data", function (data) {
console.log("表示通过读取流从文件中读取到了数据", data);
});
readStream.on("close", function () {
console.log("表示数据流断开了和文件的关系, 并且数据已经读取完毕了");
}); */
/*
// 1.拼接写入的路径
let str = path.join(__dirname, "it666.txt");
// 2.创建一个写入流
let writeStream = fs.createWriteStream(str, {encoding : "utf8"});
// 3.监听写入流的事件
writeStream.on("open", function () {
console.log("表示数据流和文件建立关系成功");
});
writeStream.on("error", function () {
console.log("表示数据流和文件建立关系失败");
});
writeStream.on("close", function () {
console.log("表示数据流断开了和文件的关系");
});
let data = "abcdefghijk";
let index = 0;
let timerId = setInterval(function () {
let ch = data[index];
index++;
writeStream.write(ch);
console.log("本次写入了", ch);
if(index === data.length){
clearInterval(timerId);
writeStream.end();
}
}, 1000); */
/* // 1.生成读取和写入的路径
let readPath = path.join(__dirname, "test.mp4");
let writePath = path.join(__dirname, "abc.mp4");
// 2.创建一个读取流
let readStream = fs.createReadStream(readPath);
// 3.创建一个写入流
let writeStream = fs.createWriteStream(writePath);
// 4.监听读取流事件
readStream.on("open", function () {
console.log("表示数据流和文件建立关系成功");
});
readStream.on("error", function () {
console.log("表示数据流和文件建立关系失败");
});
readStream.on("data", function (data) {
// console.log("表示通过读取流从文件中读取到了数据", data);
writeStream.write(data);
});
readStream.on("close", function () {
console.log("表示数据流断开了和文件的关系, 并且数据已经读取完毕了");
writeStream.end();
});
// 5.监听写入流的事件
writeStream.on("open", function () {
console.log("表示数据流和文件建立关系成功");
});
writeStream.on("error", function () {
console.log("表示数据流和文件建立关系失败");
});
writeStream.on("close", function () {
console.log("表示数据流断开了和文件的关系");
}); */
// 1.生成读取和写入的路径
let readPath = path.join(__dirname, "test.mp4");
let writePath = path.join(__dirname, "abc.mp4");
// 2.创建一个读取流
let readStream = fs.createReadStream(readPath);
// 3.创建一个写入流
let writeStream = fs.createWriteStream(writePath);
// 利用读取流的管道方法来快速的实现文件拷贝
readStream.pipe(writeStream);
- 目录操作
1、创建目录
fs.mkdir(path[, mode], callback)
fs.mkdirSync(path[, mode])
2、读取目录
fs.readdir(path[, options], callback)
fs.readdirSync(path[, options])
3、删除目录
fs.rmdir(path, callback)
fs.rmdirSync(path)

2.2.3、系统模块path 路径操作
封装了各种路径相关的操作。和Buffer一样,NodeJS中的路径也是一个特殊的模块。不同的是Buffer模块已经添加到Global上了, 所以不需要手动导入。而Path模块没有添加到Global上, 所以使用时需要手动导入。
- 为什么进行路径拼接
- 不同操作系统的路径分隔符不统一
- /public/up/uploads/avatar
- Windows上是 \ /
- Linux上是 /
- path一些方法
1、获取路径的最后一部分
path.basename(path[, ext])
2、获取路径
path.dirname(path)
3、获取扩展名称
path.extname(path)
4、判断是否是绝对路径
path.isAbsolute(path)
5、获取当前操作系统路径分隔符
path.delimiter (windows是\ Linux是/)
6、获取当前路径环境变量分隔符
path.sep (windows中使用; linux中使用:)
7、路径的格式化处理
path.parse() string->obj
path.format() obj->string
8、拼接路径
path.join([…paths])
9、规范化路径
path.normalize(path)
10、计算相对路径
path.relative(from, to)
11、解析路径
path.resolve([…paths])
let path = require("path");
// basename用于获取路径的最后一个组成部分
// let res = path.basename('/a/b/c/d/index.html');
// let res = path.basename('/a/b/c/d');
// let res = path.basename('/a/b/c/d/index.html', ".html");
// console.log(res);
// dirname用于获取路径中的目录, 也就是除了最后一个部分以外的内容
// let res = path.dirname('/a/b/c/d/index.html');
// let res = path.dirname('/a/b/c/d');
// console.log(res);
// extname用于获取路径中最后一个组成部分的扩展名
// let res = path.extname('/a/b/c/d/index.html');
// let res = path.extname('/a/b/c/d');
// console.log(res);
/*
isAbsolute用于判断路径是否是一个绝对路径
注意点:
区分操作系统
在Linux操作系统中/开头就是绝对路径
在Windows操作系统中盘符开头就是绝对路径
在Linux操作系统中路径的分隔符是左斜杠 /
在Windows操作系统中路径的分隔符是右斜杠 \
* */
// let res = path.isAbsolute('/a/b/c/d/index.html'); // true
// let res = path.isAbsolute('./a/b/c/d/index.html'); // false
// let res = path.isAbsolute('c:\\a\\b\\c\\d\\index.html'); // true
// let res = path.isAbsolute('a\\b\\c\\d\\index.html'); // false
// console.log(res);
// path.sep用于获取当前操作系统中路径的分隔符的
// 如果是在Linux操作系统中运行那么获取到的是 左斜杠 /
// 如果是在Windows操作系统中运行那么获取到的是 右斜杠 \
console.log(11, path.sep); // 11 \
// path.delimiter用于获取当前操作系统环境变量的分隔符的
// 如果是在Linux操作系统中运行那么获取到的是 :
// 如果是在Windows操作系统中运行那么获取到的是 ;
console.log(path.delimiter); // ;
/*
path.parse(path): 用于将路径转换成对象
{
root: '/',
dir: '/a/b/c/d',
base: 'index.html',
ext: '.html',
name: 'index'
}
path.format(pathObject): 用于将对象转换成路径
* */
let obj = path.parse("/a/b/c/d/index.html");
console.log(obj);
/* {
root: '/',
dir: '/a/b/c/d',
base: 'index.html',
ext: '.html',
name: 'index'
} */
let obj11 = {
root: '/',
dir: '/a/b/c/d',
base: 'index.html',
ext: '.html',
name: 'index'
};
let str = path.format(obj11);
console.log(str); // /a/b/c/d\index.html
/*
path.join([...paths]): 用于拼接路径
注意点:
如果参数中没有添加/, 那么该方法会自动添加
如果参数中有.., 那么会自动根据前面的参数生成的路径, 去到上一级路径
* */
/*
// let str = path.join("/a/b", "c"); // /a/b/c
// let str = path.join("/a/b", "/c"); // /a/b/c
// let str = path.join("/a/b", "/c", "../"); // /a/b/c --> /a/b
// let str = path.join("/a/b", "/c", "../../"); // /a/b/c --> /a
// console.log(str);
*/
/*
path.normalize(path): 用于规范化路径
* */
let res11 = path.normalize("/a//b///cd/index.html");
console.log(22, res11); // \a\b\c\d\index.html
/*
path.relative(from, to): 用于计算相对路径
第一个参数: /data/orandea/test/aaa
第二个参数: /data/orandea/impl/bbb
/data/orandea/test/aaa --> ../ --> /data/orandea/test
/data/orandea/test --> ../ --> /data/orandea
..\..\impl\bbb
* */
let res111 = path.relative('/data/orandea/test/aaa', '/data/orandea/impl/bbb');
console.log(111, res111); // ..\..\impl\bbb
/*
path.resolve([...paths]): 用于解析路径
注意点: 如果后面的参数是绝对路径, 那么前面的参数就会被忽略
* */
let res33 = path.resolve('/foo/bar', './baz');
let res44 = path.resolve('/foo/bar', '../baz');
let res55 = path.resolve('/foo/bar', '/baz');
console.log(res33); // D:\foo\bar\baz
console.log(res44); // D:\foo\baz
console.log(res55); // D:\baz
相对路径VS绝对路径
- 大多数情况下使用绝对路径,因为相对路径有时候相对的是命令行工具的当前工作目录
- 在读取文件或者设置文件路径时都会选择绝对路径
- 使用__dirname获取当前文件所在的绝对路径
2.2.4、Buffer对象
-
准备知识
1、计算机只能识别0和1(因为计算机只认识通电和断电两种状态),
2、所有存储在计算机上的数据都是0和1组成的(数据越大0和1就越多)
3、计算机中的度量单位
1 B(Byte字节) = 8 bit(位)
// 00000000 就是一个字节
// 111111111 也是一个字节
// 10101010 也是一个字节
// 任意8个 0或1的组合都是一个字节
1 KB = 1024 B
1 MB = 1024KB
1 GB = 1024MB -
什么是Buffer?
Buffer是NodeJS全局对象上的一个类, 是一个专门用于存储字节数据的类。
NodeJS提供了操作计算机底层API, 而计算机底层只能识别0和1,所以就提供了一个专门用于存储字节数据的类。 -
如何创建一个Buffer对象
1、创建一个指定大小的Buffer
Buffer.alloc(size[, fill[, encoding]])
2、根据数组/字符串创建一个Buffer对象
Buffer.from(string[, encoding]) -
Buffer对象本质
本质就是一个数组。
注意点: 通过console.log();输出Buffer. 会自动将存储的内容转换成16进制再输出。
// let buf = Buffer.alloc(5);
// console.log(buf); // - Buffer实例方法
1、将二进制数据转换成字符串
返回: 转换后的字符串数据。
buf.toString()
2、往Buffer中写入数据
buf.write(string[, offset[, length]][, encoding])
string 要写入的 buf 的字符串。
offset 开始写入 string 之前要跳过的字节数。默认值: 0。
length 要写入的字节数。默认值: buf.length - offset。
encoding string 的字符编码。默认值: ‘utf8’。
返回: 已写入的字节数。
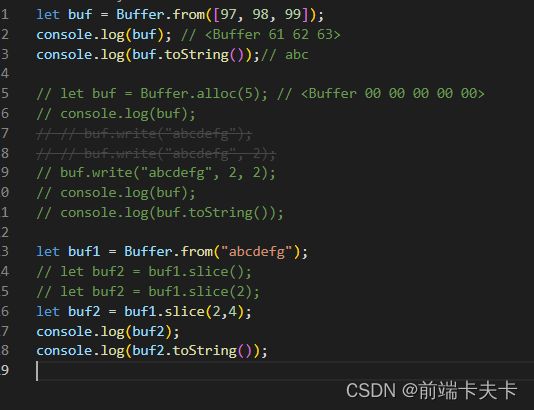
3、从指定位置截取新Buffer
start 新 Buffer 开始的位置。默认值: 0。
end 新 Buffer 结束的位置(不包含)
buf.slice([start[, end]])
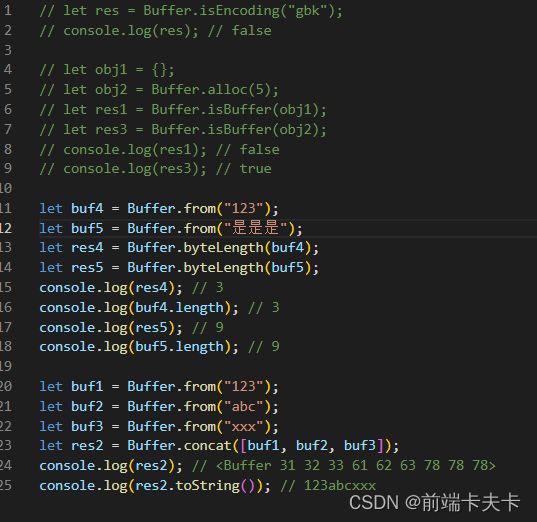
- Buffer静态方法
1、检查是否支持某种编码格式
Buffer.isEncoding(encoding)
2、检查是否是Buffer类型对象
Buffer.isBuffer(obj)
3、获取Buffer实际字节长度
Buffer.byteLength(string[, encoding])
注意点: 一个汉字占用三个字节
4、合并Buffer中的数据
Buffer.concat(list[, totalLength])
2.2.5、HTTP模块
- 什么是HTTP模块
通过Nodejs提供的http模块,我们可以快速的构建一个web服务器,也就是快速实现过去PHP服务器的功能(接收浏览器请求、响应浏览器请求等)。 - 通过HTTP模块实现服务器功能步骤
2.1 导入HTTP模块
2.2 创建服务器实例对象
2.3 绑定请求事件
2.4 监听指定端口请求
let http = require("http");
// 1.创建一个服务器实例对象
let server = http.createServer();
// 2.注册请求监听
server.on("request", function (req, res) {
// end方法的作用: 结束本次请求并且返回数据
// res.end("www.it666.com");
// writeHead方法的作用: 告诉浏览器返回的数据是什么类型的, 返回的数据需要用什么字符集来解析
res.writeHead(200, {
"Content-Type": "text/plain; charset=utf-8"
});
res.end("在在在");
});
// 3.指定监听的端口
server.listen(3000);
http.createServer(function (req, res) {
res.writeHead(200, {
"Content-Type": "text/plain; charset=utf-8"
});
res.end("在在在666");
}).listen(3000);
- 路径分发
3.1 什么是路径分发?
路径分发也称之为路由, 就是根据不同的请求路径返回不同的数据。
3.2 如何根据不同的请求路径返回不同的数据?
通过请求监听方法中的request对象, 我们可以获取到当前请求的路径。
通过判断请求路径的地址就可以实现不同的请求路径返回不同的数据。
let http = require("http");
// 1.创建一个服务器实例对象
let server = http.createServer();
// 2.注册请求监听
/*
req对象其实是http.IncomingMessage 类的实例
res对象其实是http.ServerResponse 类的实例
* */
server.on("request", function (req, res) {
res.writeHead(200, {
"Content-Type": "text/plain; charset=utf-8"
});
// console.log(req.url);
if(req.url.startsWith("/index")){
// 注意点: 如果通过end方法来返回数据, 那么只会返回一次
// res.end("首页1");
// res.end("首页2");
// 注意点: 如果通过write方法来返回数据, 那么可以返回多次
// write方法不具备结束本次请求的功能, 所以还需要手动的调用end方法来结束本次请求
res.write("首页1");
res.write("首页2");
res.end();
}else if(req.url.startsWith("/login")){
res.end("登录");
}else{
res.end("没有数据");
}
});
// 3.指定监听的端口
server.listen(3000);
/*
startsWith()方法用来判断当前字符串是否是以另外一个给定的子字符串“开头”的,根据判断结果返回 true 或 false。
str.startsWith(searchString [, position]);
1、searchString:要搜索的子字符串。
2、position:在 str 中搜索 searchString 的开始位置,默认值为 0,也就是真正的字符串开头处。
var str = "To be, or not to be, that is the question.";
alert(str.startsWith("To be")); // true
alert(str.startsWith("not to be")); // false
alert(str.startsWith("not to be", 10)); // true
*/
- 响应完整页面
拿到用户请求路径之后, 只需要利用fs模块将对应的网页返回即可。
let http = require("http");
let path = require("path");
let fs = require("fs");
// 1.创建一个服务器实例对象
let server = http.createServer();
// 2.注册请求监听
server.on("request", function (req, res) {
if(req.url.startsWith("/index")){
// let filePath = path.join(__dirname, "www", "index.html");
// let filePath = path.join(__dirname, "www", req.url);
// fs.readFile(filePath, "utf8", function (err, content) {
// if(err){
// res.end("Server Error");
// }
// res.end(content);
// });
readFile(req, res);
}else if(req.url.startsWith("/login")){
// let filePath = path.join(__dirname, "www", req.url);
// fs.readFile(filePath, "utf8", function (err, content) {
// if(err){
// res.end("Server Error");
// }
// res.end(content);
// });
readFile(req, res);
}else{
res.writeHead(200, {
"Content-Type": "text/plain; charset=utf-8"
});
res.end("没有数据");
}
readFile(req, res);
});
// 3.指定监听的端口
server.listen(3000);
function readFile(req, res) {
let filePath = path.join(__dirname, "www", req.url);
fs.readFile(filePath, "utf8", function (err, content) {
if(err){
res.end("Server Error");
}
res.end(content);
});
}
- 响应静态资源
在给浏览器返回数据的时候,如果没有指定响应头的信息,如果没有设置返回数据的类型,那么浏览器不一定能正确的解析。所以无论返回什么类型的静态资源都需要添加对应的响应头信息。
// let path = require("path");
let fs = require("fs");
let mime = require("./mime.json");
function readFile(req, res, rootPath) {
let filePath = path.join(rootPath, req.url);
// console.log(filePath);
/*
注意点:
1.加载其它的资源不能写utf8
2.如果服务器在响应数据的时候没有指定响应头, 那么在有的浏览器上, 响应的数据有可能无法显示
* */
let extName = path.extname(filePath);
let type = mime[extName];
if(type.startsWith("text")){
type += "; charset=utf-8;";
}
res.writeHead(200, {
"Content-Type": type
});
fs.readFile(filePath, function (err, content) {
if(err){
res.end("Server Error");
}
res.end(content);
});
}
exports.StaticServer = readFile;
let http = require("http");
let path = require("path");
// let fs = require("fs");
// let mime = require("./mime.json");
let ss = require("./15-StaticServer.js");
// 1.创建一个服务器实例对象
let server = http.createServer();
// 2.注册请求监听
server.on("request", function (req, res) {
// readFile(req, res);
// let rootPath = path.join(__dirname, "www");
let rootPath = "C:\\Users\\Desktop\\abc";
ss.StaticServer(req, res, rootPath);
});
// 3.指定监听的端口
server.listen(3000);
/*
function readFile(req, res) {
let filePath = path.join(__dirname, "www", req.url);
// console.log(filePath);
// 注意点:
// 1.加载其它的资源不能写utf8
// 2.如果服务器在响应数据的时候没有指定响应头, 那么在有的浏览器上, 响应的数据有可能无法显示
let extName = path.extname(filePath);
let type = mime[extName];
if(type.startsWith("text")){
type += "; charset=utf-8;";
}
res.writeHead(200, {
"Content-Type": type
});
fs.readFile(filePath, function (err, content) {
if(err){
res.end("Server Error");
}
res.end(content);
});
}
*/
- URL模块-Get参数处理
1、url.format(urlObject) 将路径转换为对象。
2、url.parse(urlString[, parseQueryString[, slashesDenoteHost]]) 将对象转换为路径。

- querystring模块-POST参数处理
1、querystring.parse(str[, sep[, eq[, options]]]) 将参数转换为对象。
2、querystring.stringify(obj[, sep[, eq[, options]]]) 将对象转换为参数。
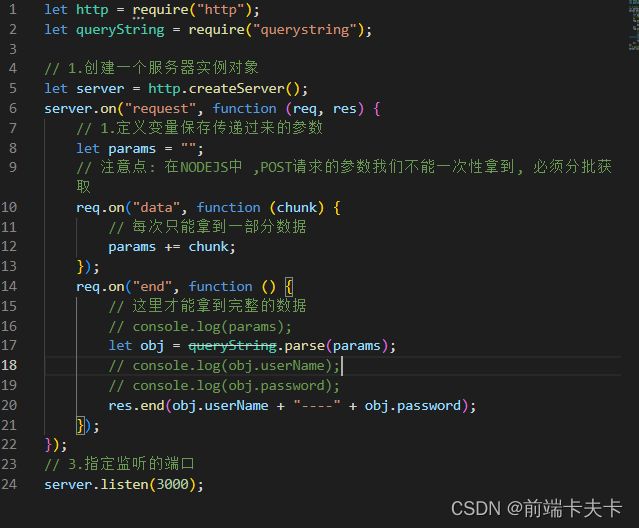
- 区分GET-POST请求
通过HTTP模块http.IncomingMessage 类的.method属性。
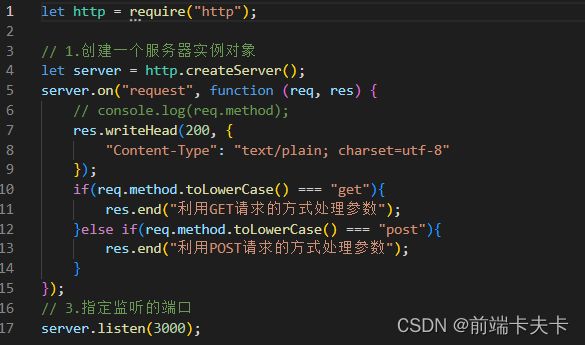
2.3、第三方模块(又称“包”)
2.3.1、什么是第三方模块
定义一:前面说过在编写代码的时候尽量遵守单一原则,也就是一个函数尽量只做一件事情。例如: 读取数据函数/写入数据函数/生成随机数函数等等。不要一个函数既读取数据又写入数据又生成随机数,这样代码非常容易出错, 也非常难以维护。在模块化开发中也一样, 在一个模块(一个文件中)尽量只完成一个特定的功能,但是有些比较复杂的功能可能需要由多个模块组成,例如: jQuery选择器相关的代码在A模块, CSS相关的代码在B模块, …我们需要把这些模块组合在一起才是完成的jQuery那么这个时候我们就需要一个东西来维护多个模块之间的关系。这个维护多个模块之间关系的东西就是"包"。
定义二:别人写好的、具有特定功能的、我们能直接使用的模块即第三方模块,由于第三方模块通常都是由多个文件组成并且被放置在一个文件夹中,所以又名包
第三方模块有两种存在形式:
- 以js文件的形式存在,提供实现项目具体功能的API接口。
- 以命令行工具形式存在,辅助项目开发。
简而言之: 一个模块是一个单独的文件, 一个包中可以有一个或多个模块
2.3.2、获取第三方模块
在NodeJS中为了方便开发人员发布、安装和管理包, NodeJS推出了一个包管理工具NPM(Node Package Manager)。NPM不需要我们单独安装, 只要搭建好NodeJS环境就已经自动安装好了。NPM就相当于电脑上的"QQ管家软件助手",,通过NPM我们可以快速找到我们需要的包,可以快速安装我们需要的包, 可以快速删除我们不想要的包等等。
npmjs.com: 第三方模块的存储和分发仓库。
npm(node package manager): node的第三方模块管理工具。
-
NPM包安装方式
-
全局安装 (一般用于安装全局使用的工具, 存储在全局node_modules中)
npm install -g 包名 (默认安装最新版本)
npm uninstall -g 包名
npm update -g 包名 (更新失败可以直接使用install) -
本地安装 (一般用于安装当前项目使用的包, 存储在当前项目node_modules中)
npm install 包名
npm uninstall 包名
npm update 包名
-
-
初始化本地包
npm init -> 初始化package.json文件
npm init -y -> 初始化package.json文件npm install 包名 --save
npm install 包名 --save-dev包描述文件 package.json, 定义了当前项目所需要的各种模块,以及项目的配置信息(比如名称、版本、许可证等元数据)。
npm install 命令根据这个配置文件,自动下载所需的模块,也就是配置项目所需的运行和开发环境注意点:package.json文件中, 不能加入任何注释。
- dependencies:生产环境包的依赖,一个关联数组,由包的名称和版本号组成
- devDependencies:开发环境包的依赖,一个关联数组,由包的名称和版本号组成
1、将项目拷贝给其它人, 或者发布的时候, 我们不会将node_modules也给别人, 因为太大。
2、因为有的包可能只在开发阶段需要, 但是在上线阶段不需要, 所以需要分开指定。
npm i 所有的包都会被安装
npm i --production 只会安装dependencies中的包
npm i --development 只会安装devDependencies中的包
2.3.3、第三方模块nodemon
nodemon是一个命令行工具,用以辅助项目开发。
在Node.js中,每次修改文件都要在命令行工具中重新执行该文件,非常繁琐。
1、使用npm install nodemon -g 下载它
2、在命令行工具中用nodemon命令代替node命令执行文件。
2.3.4、第三方模块nrm
nrm(npm registry manager): npm下载地址切换工具。
由于npm默认会去国外下载资源, 所以对于国内开发者来说下载会比较慢,所以就有人写了一个nrm工具, 允许你将资源下载地址从国外切换到国内。
使用步骤:
npm install -g nrm 安装NRM
nrm --version 查看是否安装成功
npm ls 查看允许切换的资源地址
npm use taobao 将下载地址切换到淘宝
PS:淘宝资源地址和国外的地址内容完全同步,。淘宝镜像与官方同步频率目前为 10分钟 一次以保证尽量与官方服务同步。
2.3.5、cnpm使用
由于npm默认回去国外下载资源, 所以对于国内开发者来说下载会比较慢。cnpm 就是将下载源从国外切换到国内下载, 只不过是将所有的指令从npm变为cnpm而已。
npm install cnpm -g –registry=https://registry.npm.taobao.org 安装CNPM
cnpm -v 查看是否安装成功
使用方式同npm, 例如: npm install jquery 变成cnpm install jquery 即可
2.3.6、yarn使用
-
什么是YARN?
Yarn是由Facebook、Google、Exponent 和 Tilde 联合推出了一个新的 JS 包管理工具
Yarn 是为了弥补 npm5.0之前 的一些缺陷而出现的。
注意点:
在npm5.0之前,yarn的优势特别明显.但是现在NPM已经更新到6.9.x甚至7.x了,
随着NPM的升级NPM优化甚至超越Yarn,所以个人还是建议使用NPM -
NPM的缺陷:
1、npm install的时候巨慢
npm 是按照队列执行每个 package,也就是说必须要等到当前 package 安装完成之后,才能继续后面的安装
2、同一个项目,npm install的时候无法保持一致性
“5.0.3”表示安装指定的5.0.3版本,
“~5.0.3”表示安装5.0.X中最新的版本,
“^5.0.3”表示安装5.X.X中最新的版本 -
YARN优点:
- 速度快:
1、并行安装: 而 Yarn 是同步执行所有任务,提高了性能。
2、离线模式:如果之前已经安装过一个软件包,用Yarn再次安装时之间从缓存中获取,就不用像npm那样再从网络下载了。 - 安装版本统一:
1、为了防止拉取到不同的版本,Yarn 有一个锁定文件 (lock file) 记录了被确切安装上的模块的版本号。
- 速度快:
-
YARN的安装
npm install -g yarn
yarn --version -
YARN使用
1、初始化包
npm init -y
yarn init -y
2、安装包
npm install xxx --save
yarn add xxx
npm install xxx --save-dev
yarn add xxx --dev
3、移除包
npm uninstall xxx
yarn remove xxx
4、更新包
npm update xxx
yarn upgrade xxx --latest
5、全局安装
npm install -g xxx
npm uninstall -g xxx
npm update -g xxx
yarn global add xxx
yarn global upgrade xxx
yarn global remove xxx
2.3.7、第三方模块Gulp
基于node平台开发的前端构建工具,将机械化操作编写成任务,想要执行机械化操作时,执行一个命令行命令任务就能自动执行了。用机器代替手工,提高开发效率。
1、Gulp能做什么
- 项目上线,HTML、CSS、JS文件压缩合并。
- 语法转换(es6、less、…)。
- 公共文件抽离。
- 修改文件浏览器自动刷新。
2、Gulp中提供的方法
- gulp.src(): 获取任务要处理的文件
- gulp.dest(): 输出文件
- gulp.task(): 建立gulp任务
- gulp.watch(): 监控文件的变化
const gulp = require('gulp');
// 使用gulp.task()方法建立任务
gulp.task('lgg', () => {
// 获取要处理的文件
gulp.src('./src/css/base.css')
// 将处理后的文件输出到dist目录
.pipe(gulp.dest('./dist/css')) // pipe通道
})
3、Gulp插件
- gulp-htmlmin: html文件压缩
- gulp-csso: 压缩css
- gulp-babel: JavaScript语法转化
- gulp-less: less语法转化
- gulp-uglify: 压缩混淆JavaScript
- gulp-file-include: 公共文件包括
- browsersync: 浏览器实时同步
2.4、package.json
2.4.1、node_modules文件夹的问题
1、文件夹以及文件过多过碎,当我们将项目整体拷贝给别人的时候,传输速度会很慢很慢。
2、复杂的模块依赖关系需要被记录,确保模版的版本和当前保持一致,否则会导致当前项目运行报错。
2.4.2、package.json文件的作用
项目描述文件,记录了当前项目信息,例如项目名称、版本、作者、GitHub地址、当前项目依赖了哪些第三方模块等。使用npm init -y(-y默认生成)命令生产。
2.4.3、项目依赖
- 在项目的开发阶段和线上运营阶段,都需要依赖的第三方包,称为项目依赖。
- 使用npm install 包名,命令下载的文件会默认被添加到package.json文件的dependencies字段中:
{
"dependencies": {
"jquery": "^3.3.0"
}
}
2.4.4、开发依赖
- 在项目的开发阶段需要依赖,线上运营阶段不需要依赖的第三方包,称为开发依赖。
- 使用npm install 包名 --save-dev,命令将包添加到package.json文件的devDependencies字段中:
{
"devDependencies": {
"gulp": "^4.0.0"
}
}
2.4.5、package-lock.json文件的作用
- 锁定包的版本,确保再次下载时不会因为包版本不同而产生问题。
- 加快下载速度,因为该文件中已经记录了项目所依赖第三方包的树状结构和包的下载地址,重新安装时只需下载即可,不需要做额外的工作。
2.5、Node.js中模块的加载机制
2.5.1、模块查找规则-当模块拥有路径但没有后缀时
require('./lgg.js');
require('./lgg')
1、require方法根据模块路径查找模块,如果是完整路径,直接引入模块。
2、如果模块后缀省略,先找同名JS文件再找同名JS文件夹。
3、如果找到了同名文件夹,找文件夹中的index.js。
4、如果文件夹中没有index.js就会去当前文件夹中的package.json文件中查找main选项中的入口文件。
5、如果找指定的入口文件不存在或者没有指定入口文件就会报错,模块没有被找到。
2.5.2、模块查找规则-当模块没有路径且没有后缀时
require('fs');
1、Node.js会假设它是系统模块。
2、Node.js会去node_modules文件夹中。
3、首先看是否有该名字的js文件。
4、再看是否有该名字的文件夹。
5、如果是文件夹看里面是否有index.js。
6、如果没有index.js查看该文件夹中的package.json中的main选项确定模块入口文件,找不到报错。