Redis 中文文档(三)——User interface
用户界面
了解如何使用Redis接口
Redis命令行接口(Redis-cli)是一个终端程序,用于向Redis服务器发送命令和从Redis服务器读取回复。它有两种主要模式:交互式Read-Eval-Print-Loop(REPL)模式,用户在其中键入Redis命令并接收回复;命令模式,使用附加参数执行Redis-cli,并将回复打印到标准输出。
RedisInsight将图形用户界面与Redis CLI相结合,让您可以使用任何Redis部署。您可以直观地浏览数据并与之交互,利用诊断工具,通过示例进行学习等等。最棒的是,RedisInsight是免费的。
Redis CLI(Redis CLI)
redis-cli概述,redis命令行界面
在交互模式下,reds-cli具有基本的行编辑功能,可以提供熟悉的键入体验。
要在特殊模式下启动程序,可以使用几个选项,包括:
- 模拟复制副本并打印它从主复制副本接收的复制流。
- 检查Redis服务器的延迟并显示统计信息。
- 请求延时样本和频率的ASCII艺术频谱图。
本主题涵盖了reds-cli的不同方面,从最简单的功能开始,到更高级的功能结束。
命令行用法
要运行Redis命令并在终端返回标准输出,请包含要作为reds-cli的单独参数执行的命令:
$ redis-cli INCR mycounter
(integer) 7
命令的回复是“7”。由于Redis的回复是类型化的(字符串、数组、整数、nil、error等),所以可以在括号之间看到回复的类型。当redis-cli的输出必须用作另一个命令的输入或重定向到文件中时,这些附加信息可能并不理想。
reds-cli仅在检测到标准输出是tty或终端时显示附加信息以提高可读性。对于所有其他输出,它将自动启用原始输出模式,如下例所示:
$ redis-cli INCR mycounter > /tmp/output.txt
$ cat /tmp/output.txt
8
请注意,输出中省略了(integer),因为redis-cli检测到输出不再写入终端。您甚至可以使用–raw选项在终端上强制原始输出:
$ redis-cli --raw INCR mycounter
9
在向文件或管道中写入其他命令时,可以使用–no-raw强制执行可读输出。
字符串引用和转义
当redis-cli解析命令时,空格字符会自动对参数进行分隔。在交互模式中,换行符发送用于解析和执行的命令。若要输入包含空格或不可打印字符的字符串值,可以使用带引号和转义字符串。
带引号的字符串值用双(“)或单(')引号括起来。转义序列用于将不可打印的字符放入字符和字符串文字中。
转义序列包含一个反斜杠(\)符号,后跟一个转义序列字符。
双引号字符串支持以下转义序列:
\"- double-quote\n- newline\r- carriage return 回车\t- horizontal tab\b- backspace 退格\a- alert 警报\\- backslash\xhh- any ASCII character represented by a hexadecimal number (hh)由十六进制数字(hh)表示的任何ASCII字符
单引号假定字符串为文字,并且只允许以下转义序列:
\'- single quote\\- backslash
For example, to return Hello World on two lines:
127.0.0.1:6379> SET mykey "Hello\nWorld"
OK
127.0.0.1:6379> GET mykey
Hello
World
当您输入包含单引号或双引号的字符串时,例如在密码中可能会对字符串进行转义,如下所示:
127.0.0.1:6379> AUTH some_admin_user ">^8T>6Na{u|jp>+v\"55\@_;OU(OR]7mbAYGqsfyu48(j'%hQH7;v*f1H${*gD(Se'"
主机、端口、密码和数据库
默认情况下,redis-cli通过端口6379连接到地址127.0.0.1的服务器。您可以使用几个命令行选项更改端口。要指定不同的主机名或IP地址,请使用-h选项。要设置不同的端口,请使用-p。
$ redis-cli -h redis15.localnet.org -p 6390 PING
PONG
If your instance is password protected, the -a option will perform authentication saving the need of explicitly using the AUTH command:
如果您的实例受密码保护,-a<password>选项将执行身份验证,从而省去显式使用AUTH命令的需要:
$ redis-cli -a myUnguessablePazzzzzword123 PING
PONG
注意:出于安全原因,请通过REDISCLI_AUTH环境变量自动为redis-cli提供密码。
最后,可以使用-n<dbnum>选项发送一个命令,该命令对默认数字零以外的数据库数字进行操作:
$ redis-cli FLUSHALL
OK
$ redis-cli -n 1 INCR a
(integer) 1
$ redis-cli -n 1 INCR a
(integer) 2
$ redis-cli -n 2 INCR a
(integer) 1
这些信息中的部分或全部也可以通过使用-u选项和uri模式来提供redis://user:password@host:port/dbnum:
$ redis-cli -u redis://LJenkins:p%[email protected]:16379/0 PING
PONG
SSL/TLS协议
默认情况下,redis-cli使用纯TCP连接来连接redis。您可以使用–TLS选项以及–cacert或–cacertdir来启用SSL/TLS,以配置受信任的根证书捆绑包或目录。
如果目标服务器需要使用客户端证书进行身份验证,则可以使用–cert和–key指定证书和相应的私钥。
从其他程序获取输入
有两种方法可以使用redis-cli,以便通过标准输入接收来自其他命令的输入。一种是使用目标负载作为stdin的最后一个参数。例如,为了将Redis密钥net_services设置为来自本地文件系统的文件/etc/services的内容,请使用-x选项:
$ redis-cli -x SET net_services < /etc/services
OK
$ redis-cli GETRANGE net_services 0 50
"#\n# Network services, Internet style\n#\n# Note that "
在上述会话的第一行中,使用-x选项执行了redis-cli,并将一个文件重定向到cli的标准输入,作为满足SET net_services命令短语的值。这对于编写脚本非常有用。
另一种方法是向reds-cli提供一系列在文本文件中编写的命令:
$ cat /tmp/commands.txt
SET item:3374 100
INCR item:3374
APPEND item:3374 xxx
GET item:3374
$ cat /tmp/commands.txt | redis-cli
OK
(integer) 101
(integer) 6
"101xxx"
commands.txt中的所有命令都由reds-cli连续执行,就好像它们是用户在交互模式下键入的一样。如果需要,可以在文件中引用字符串,这样就可以使用带有空格、换行符或其他特殊字符的单个参数:
$ cat /tmp/commands.txt
SET arg_example "This is a single argument"
STRLEN arg_example
$ cat /tmp/commands.txt | redis-cli
OK
(integer) 25
连续运行相同的命令
可以在用户选择的执行之间暂停的情况下执行指定次数的单个命令。这在不同的上下文中很有用,例如,当我们想要持续监控一些关键内容或INFO字段输出时,或者当我们想要模拟一些重复发生的写入事件时,例如每5秒将一个新项目推入列表。
此功能由两个选项控制:-r<count>和-i<delay>。-r选项说明运行一个命令的次数,-i以秒为单位设置不同命令调用之间的延迟(可以指定0.1等值来表示100毫秒)。
默认情况下,间隔(或延迟)设置为0,因此只需尽快执行命令:
$ redis-cli -r 5 INCR counter_value
(integer) 1
(integer) 2
(integer) 3
(integer) 4
(integer) 5
要无限期地运行同一命令,请使用-1作为计数值。要随时间监控RSS内存大小,可以使用以下命令:
$ redis-cli -r -1 -i 1 INFO | grep rss_human
used_memory_rss_human:2.71M
used_memory_rss_human:2.73M
used_memory_rss_human:2.73M
used_memory_rss_human:2.73M
... a new line will be printed each second ...
使用redis cli大规模插入数据
使用redis-cli的大规模插入在单独的一页中介绍,因为它本身就是一个有价值的主题。请参阅我们的批量插入指南mass insertion guide。
CSV输出
redis-cli中存在CSV(逗号分隔值)输出功能,用于将数据从redis导出到外部程序。
$ redis-cli LPUSH mylist a b c d
(integer) 4
$ redis-cli --csv LRANGE mylist 0 -1
"d","c","b","a"
请注意,.csv标志只能用于单个命令,而不能用于导出整个数据库。
运行Lua脚本
redis-cli广泛支持使用Lua脚本的调试功能,redis 3.2及以后版本提供了该功能。有关此功能,请参阅Redis-Lua调试器文档。
即使不使用调试器,redis-cli也可以用于从文件中运行脚本作为参数:
$ cat /tmp/script.lua
return redis.call('SET',KEYS[1],ARGV[1])
$ redis-cli --eval /tmp/script.lua location:hastings:temp , 23
OK
Redis EVAL命令将脚本使用的键列表和其他非键参数作为不同的数组。当拨打EVAL时,您可以将钥匙的数量作为数字提供。
当使用上面的–eval选项调用reds-cli时,不需要显式指定键的数量。相反,它使用了用逗号分隔键和参数的约定。这就是为什么在上面的调用中,您看到location:hastings:temp,23作为参数。
所以location:hastings:temp将填充KEYS数组,23填充ARGV数组。
–eval选项在编写简单脚本时非常有用。对于更复杂的工作,建议使用Lua调试器。这两种方法可以混合使用,因为调试器也可以从外部文件执行脚本。
交互模式
我们已经探讨了如何将Redis CLI用作命令行程序。这对脚本和某些类型的测试很有用,但大多数人将大部分时间花在redis-cli中使用其交互模式。
在交互模式下,用户在提示下键入Redis命令。命令被发送到服务器,进行处理,回复被解析回并呈现为更简单的阅读形式。
在交互模式下运行redis-cli不需要任何特殊的东西,只需在不带任何参数的情况下执行即可
$ redis-cli
127.0.0.1:6379> PING
PONG
字符串127.0.0.1:6379>是提示。它显示连接的Redis服务器实例的主机名和端口。
当连接的服务器发生更改或在不同于数据库编号0的数据库上操作时,提示会更新:
127.0.0.1:6379> SELECT 2
OK
127.0.0.1:6379[2]> DBSIZE
(integer) 1
127.0.0.1:6379[2]> SELECT 0
OK
127.0.0.1:6379> DBSIZE
(integer) 503
处理连接和重新连接
在交互模式下使用CONNECT命令可以通过指定要连接的主机名和端口来连接到不同的实例:
127.0.0.1:6379> CONNECT metal 6379
metal:6379> PING
PONG
正如您所看到的,当连接到不同的服务器实例时,提示会相应地更改。如果尝试连接到无法访问的实例,则redis-cli将进入断开连接模式,并尝试使用每个新命令重新连接:
127.0.0.1:6379> CONNECT 127.0.0.1 9999
Could not connect to Redis at 127.0.0.1:9999: Connection refused
not connected> PING
Could not connect to Redis at 127.0.0.1:9999: Connection refused
not connected> PING
Could not connect to Redis at 127.0.0.1:9999: Connection refused
通常,在检测到断开连接后,redis-cli总是尝试透明地重新连接;如果尝试失败,则显示错误并进入断开连接状态。以下是断开连接和重新连接的示例:
127.0.0.1:6379> INFO SERVER
Could not connect to Redis at 127.0.0.1:6379: Connection refused
not connected> PING
PONG
127.0.0.1:6379>
(now we are connected again)
执行重新连接时,redis cli会自动重新选择最后一个选定的数据库编号。但是,有关连接的所有其他状态都会丢失,例如在MULTI/EXEC事务中:
$ redis-cli
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> PING
QUEUED
( here the server is manually restarted )
127.0.0.1:6379> EXEC
(error) ERR EXEC without MULTI
当在交互模式下使用reds-cli进行测试时,这通常不是问题,但应该知道这个限制。
编辑、历史、完成和提示
由于redis-cli使用linenoise行编辑库linenoise line editing library,因此它始终具有行编辑功能,而不依赖于libreadline或其他可选库。
可以访问命令执行历史记录,以避免按下箭头键(向上和向下)重新键入命令。在CLI重新启动之间,历史记录将保存在用户主目录内名为.redispi_history的文件中,由home环境变量指定。可以通过设置REDISCLI_HISTFILE环境变量来使用不同的历史文件名,并通过将其设置为/dev/null来禁用它。
redis-cli还可以通过按TAB键来完成命令名,如下例所示:
127.0.0.1:6379> Z
127.0.0.1:6379> ZADD
127.0.0.1:6379> ZCARD
在提示符处输入Redis命令名后,Redis-cli将显示语法提示。与命令历史记录一样,可以通过redis-cli首选项打开和关闭此行为。
首选项
有两种方法可以自定义redis-cli行为。启动时,CLI会加载主目录中的.resclirc文件。通过将REDISCLI_RCFILE环境变量设置为替代路径,可以替代文件的默认位置。还可以在CLI会话期间设置首选项,在这种情况下,它们将仅持续会话的持续时间。
要设置首选项,请使用special:set命令。可以设置以下首选项,方法是在CLI中键入命令或将其添加到.redisplrc文件中:
- :set hints-启用语法提示
- :set nohints-禁用语法提示
运行同一命令N次
通过在命令名称前加一个数字,可以在交互模式下多次运行同一命令:
127.0.0.1:6379> 5 INCR mycounter
(integer) 1
(integer) 2
(integer) 3
(integer) 4
(integer) 5
显示有关Redis命令的帮助
redis-cli使用help命令为大多数 Redis commands 提供联机帮助。该命令有两种形式:
-
HELP @shows all the commands about a given category. The categories are:
@generic@string@list@set@sorted_set@hash@pubsub@transactions@connection@server@scripting@hyperloglog@cluster@geo@stream
-
HELPshows specific help for the command given as argument.
For example in order to show help for the PFADD command, use:
127.0.0.1:6379> HELP PFADD
PFADD key element [element ...]
summary: Adds the specified elements to the specified HyperLogLog.
since: 2.8.9
Note that HELP supports TAB completion as well. 请注意,HELP也支持TAB完成。
清除终端屏幕
在交互模式下使用CLEAR(清除)命令可清除终端的屏幕。
特殊操作模式
到目前为止,我们看到了redis-cli的两种主要模式。
- Redis命令的命令行执行。
- 交互式“REPL”用法。
CLI执行与Redis相关的其他辅助任务,这些任务将在下一节中进行解释:
- 用于显示Redis服务器的连续统计数据的监控工具。
- 正在扫描Redis数据库以查找非常大的密钥。
- 带图案匹配的钥匙空间扫描仪。
- 充当订阅频道的Pub/Sub 客户端。
- 监控Redis实例中执行的命令。
- 以不同的方式检查Redis服务器的延迟latency。
- 正在检查本地计算机的计划程序延迟。
- 从远程Redis服务器本地传输RDB备份。
- 充当Redis复制副本,显示复制副本接收到的内容。
- 模拟 LRU 工作负载,以显示按键命中的统计数据。
- Lua调试器的客户端。
连续统计模式
持续统计模式可能是redis-cli实时监控redis实例的一个鲜为人知但非常有用的功能。要启用此模式,请使用–stat选项。输出非常清楚CLI在此模式下的行为:
$ redis-cli --stat
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
506 1015.00K 1 0 24 (+0) 7
506 1015.00K 1 0 25 (+1) 7
506 3.40M 51 0 60461 (+60436) 57
506 3.40M 51 0 146425 (+85964) 107
507 3.40M 51 0 233844 (+87419) 157
507 3.40M 51 0 321715 (+87871) 207
508 3.40M 51 0 408642 (+86927) 257
508 3.40M 51 0 497038 (+88396) 257
在这种模式下,每秒钟打印一行新的行,其中包含有用的信息和旧数据点之间的请求值差异。使用这个辅助的Redis-cli工具,可以很容易地了解有关连接的Redis数据库的内存使用情况、客户端连接计数和各种其他统计信息。
在这种情况下,-i<interval>选项用作修改器,以更改发射新线的频率。默认值为1秒。
正在扫描大密钥 Scanning for big keys
在这种特殊模式下,redis-cli充当密钥空间分析器。它扫描数据集中的大键,但也提供了有
关数据集所包含的数据类型的信息。此模式通过–bigkeys选项启用,并产生详细输出:
$ redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.01 to sleep 0.01 sec
# per SCAN command (not usually needed).
[00.00%] Biggest string found so far 'key-419' with 3 bytes
[05.14%] Biggest list found so far 'mylist' with 100004 items
[35.77%] Biggest string found so far 'counter:__rand_int__' with 6 bytes
[73.91%] Biggest hash found so far 'myobject' with 3 fields
-------- summary -------
Sampled 506 keys in the keyspace!
Total key length in bytes is 3452 (avg len 6.82)
Biggest string found 'counter:__rand_int__' has 6 bytes
Biggest list found 'mylist' has 100004 items
Biggest hash found 'myobject' has 3 fields
504 strings with 1403 bytes (99.60% of keys, avg size 2.78)
1 lists with 100004 items (00.20% of keys, avg size 100004.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
1 hashs with 3 fields (00.20% of keys, avg size 3.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
在输出的第一部分中,报告遇到的每一个比上一个更大的键(相同类型)更大的新键。摘要部分提供了Redis实例内部数据的一般统计信息。
该程序使用SCAN命令,因此可以在繁忙的服务器上执行,而不会影响操作,但是可以使用-i选项来为每个SCAN命令限制指定的几分之一秒的扫描过程。
例如,-i 0.01将大大降低程序的执行速度,但也会将服务器上的负载减少到微不足道的程度。
请注意,摘要还以更简洁的形式报告了每次找到的最大密钥。如果针对非常大的数据集运行,最初的输出只是尽快提供一些有趣的信息。
Getting a list of keys
也可以扫描密钥空间,同样以不阻塞Redis服务器的方式(当您使用KEYS*之类的命令时会发生这种情况),并打印所有密钥名称,或过滤它们以获取特定模式。该模式与–bigkeys选项一样,使用SCAN命令,因此如果数据集正在更改,则可能会多次报告密钥,但如果自迭代开始以来就存在密钥,则不会丢失任何密钥。因为它使用的命令,所以这个选项被称为–scan。
$ redis-cli --scan | head -10
key-419
key-71
key-236
key-50
key-38
key-458
key-453
key-499
key-446
key-371
请注意,head -10用于只打印输出的前十行。
扫描可以使用SCAN命令的底层模式匹配功能和–pattern选项。
$ redis-cli --scan --pattern '*-11*'
key-114
key-117
key-118
key-113
key-115
key-112
key-119
key-11
key-111
key-110
key-116
通过wc命令对输出进行管道传输可用于按关键字名称对特定类型的对象进行计数:
$ redis-cli --scan --pattern 'user:*' | wc -l
3829433
您可以使用-i 0.01来添加SCAN命令调用之间的延迟。这将使命令速度变慢,但会显著降低服务器上的负载。
Pub/sub mode
CLI可以使用publish命令在Redis Pub/Sub通道中发布消息。订阅频道以接收消息是不同的——终端被阻止并等待消息,因此这在redis-cli中被实现为一种特殊模式。与其他特殊模式不同,此模式不是通过使用特殊选项来启用的,而是通过使用SUBSCRIBE或PSUBSCRIBE命令来启用,这些命令在交互或命令模式中可用:
$ redis-cli PSUBSCRIBE '*'
Reading messages... (press Ctrl-C to quit)
1) "PSUBSCRIBE"
2) "*"
3) (integer) 1
阅读消息消息显示我们已进入Pub/Sub模式。当另一个客户端在某个通道中发布某些消息时,例如使用命令redis cli PUBLISH mychannel mymessage,处于Pub/Sub模式的cli将显示以下内容:
1) "pmessage"
2) "*"
3) "mychannel"
4) "mymessage"
这对于调试Pub/Sub问题非常有用。要退出发布/子模式,只需处理CTRL-C。
Redis中执行的监控命令
与发布/订阅模式类似,一旦使用MONITOR命令,就会自动进入监控模式。活动Redis实例接收到的所有命令都将打印到标准输出中:
$ redis-cli MONITOR
OK
1460100081.165665 [0 127.0.0.1:51706] "set" "shipment:8000736522714:status" "sorting"
1460100083.053365 [0 127.0.0.1:51707] "get" "shipment:8000736522714:status"
请注意,可以使用来管道输出,因此可以使用grep等工具监视特定的模式。
监控Redis实例的延迟
Redis通常用于延迟非常关键的环境中。延迟涉及应用程序中的多个移动部分,从客户端库到网络堆栈,再到Redis实例本身。
redis-cli具有多种功能,用于研究redis实例的延迟,并了解延迟的最大值、平均值和分布。
基本的延迟检查工具是–latency选项。使用此选项,CLI将运行一个循环,其中PING命令将发送到Redis实例,并测量接收回复的时间。这种情况每秒发生100次,统计数据在控制台中实时更新:
$ redis-cli --latency
min: 0, max: 1, avg: 0.19 (427 samples)
统计数据以毫秒为单位提供。通常,由于运行redis-cli本身的系统的内核调度器导致的延迟,非常快的实例的平均延迟往往被高估了一点,因此0.19以上的平均延迟可能很容易为0.01或更小。然而,这通常不是什么大问题,因为大多数开发人员对几毫秒或更长时间的事件感兴趣。
有时,研究最大和平均延迟是如何在一段时间内演变的是有用的。–latency history选项用于此目的:它的工作原理与–latency完全相同,但每15秒(默认情况下)就会从头开始一个新的采样会话:
$ redis-cli --latency-history
min: 0, max: 1, avg: 0.14 (1314 samples) -- 15.01 seconds range
min: 0, max: 1, avg: 0.18 (1299 samples) -- 15.00 seconds range
min: 0, max: 1, avg: 0.20 (113 samples)^C
采样会话的长度可以使用-i<interval>选项更改。
最先进的延迟研究工具,也是非经验用户最复杂的解释工具,是使用彩色终端来显示一系列延迟的能力。您将看到一个彩色输出,它指示不同的样本百分比,以及不同的ASCII字符,它们指示不同的延迟数字。此模式是使用–latency dist选项启用的:
$ redis-cli --latency-dist
(output not displayed, requires a color terminal, try it!)
reds-cli内部实现了另一个非常不寻常的延迟工具。它不检查Redis实例的延迟,而是检查运行Redis-cli的计算机的延迟。这种延迟是内核调度程序、虚拟化实例情况下的系统管理程序等固有的。
Redis称之为内在延迟,因为它对程序员来说大多是不透明的。如果Redis实例的延迟很高,而不管所有明显的原因是什么,那么值得检查一下,通过在运行Redis服务器的系统中直接以这种特殊模式运行Redis-cli,您的系统能做的最好的事情是什么。
通过测量固有延迟,您知道这是基线,Redis无法超越您的系统。为了在此模式下运行CLI,请使用–international latency<test time>。请注意,测试时间以秒为单位,并规定测试应该运行多长时间。
$ ./redis-cli --intrinsic-latency 5
Max latency so far: 1 microseconds.
Max latency so far: 7 microseconds.
Max latency so far: 9 microseconds.
Max latency so far: 11 microseconds.
Max latency so far: 13 microseconds.
Max latency so far: 15 microseconds.
Max latency so far: 34 microseconds.
Max latency so far: 82 microseconds.
Max latency so far: 586 microseconds.
Max latency so far: 739 microseconds.
65433042 total runs (avg latency: 0.0764 microseconds / 764.14 nanoseconds per run).
Worst run took 9671x longer than the average latency.
重要提示:此命令必须在运行Redis服务器实例的计算机上执行,而不是在其他主机上执行。它不连接到Redis实例,而是在本地执行测试。
在上述情况下,系统在最坏情况下的延迟不能超过739微秒,因此可以预期某些查询偶尔会运行不到1毫秒。
RDB文件的远程备份
在Redis复制的第一次同步过程中,主副本和副本以RDB文件的形式交换整个数据集。redis cli利用此功能提供远程备份功能,允许将RDB文件从任何redis实例传输到运行redis cli的本地计算机。要使用此模式,请使用–rdb<dest filename>选项调用CLI:
$ redis-cli --rdb /tmp/dump.rdb
SYNC sent to master, writing 13256 bytes to '/tmp/dump.rdb'
Transfer finished with success.
这是一种简单但有效的方法,可以确保Redis实例中存在灾难恢复RDB备份。在脚本或cron作业中使用此选项时,请确保检查命令的返回值。如果它不是零,则出现错误,如以下示例所示:
$ redis-cli --rdb /tmp/dump.rdb
SYNC with master failed: -ERR Can't SYNC while not connected with my master
$ echo $?
1
复制副本模式 Replica mode
CLI的复制副本模式是一项高级功能,对Redis开发人员和调试操作非常有用。它允许检查主复制流中发送到其副本的内容,以便将写入传播到其副本。选项名称简单地为–replica。以下是一个工作示例:
$ redis-cli --replica
SYNC with master, discarding 13256 bytes of bulk transfer...
SYNC done. Logging commands from master.
"PING"
"SELECT","0"
"SET","last_name","Enigk"
"PING"
"INCR","mycounter"
该命令首先丢弃第一次同步的RDB文件,然后以CSV格式记录接收到的每个命令。
如果您认为某些命令没有在副本中正确复制,这是检查发生了什么的好方法,也是改进错误报告的有用信息。
执行LRU模拟 Performing an LRU simulation
Redis经常被用作LRU eviction的缓存。根据键的数量和为缓存分配的内存量(通过maxmemory指令指定),缓存命中和未命中的数量将发生变化。有时,模拟命中率对于正确配置缓存非常有用。
redis-cli有一个特殊的模式,它在请求模式中使用80-20%的幂律分布来执行GET和SET操作的模拟。这意味着20%的密钥将被请求80%的次数,这是缓存场景中的常见分布。
从理论上讲,考虑到请求的分布和Redis内存开销,应该可以用数学公式解析计算命中率。然而,Redis可以配置不同的LRU设置(样本数量),并且LRU的实现(在Redis中近似)在不同版本之间变化很大。类似地,每个键的内存量可能在不同版本之间发生变化。这就是为什么要构建这个工具:它的主要动机是测试Redis的LRU实现的质量,但现在也有助于测试给定版本在最初用于部署的设置下的行为。
要使用此模式,请指定测试中的密钥数量,并配置一个合理的maxmemory设置作为第一次尝试。
重要提示:在Redis配置中配置maxmemory设置至关重要:如果最大内存使用量没有上限,则命中率最终将为100%,因为所有密钥都可以存储在内存中。如果指定了太多具有最大内存的密钥,最终将使用所有计算机RAM。还需要配置适当的maxmemory策略;大多数情况下,allkeys lru被选中。
在以下示例中,配置了100MB的内存限制和使用1000万个密钥的LRU模拟。
警告:该测试使用流水线,会给服务器带来压力,不要将其用于生产实例。
Home
Documentation
User interfaces
Redis CLI
Redis CLI
Overview of redis-cli, the Redis command line interface
In interactive mode, redis-cli has basic line editing capabilities to provide a familiar typing experience.
To launch the program in special modes, you can use several options, including:
Simulate a replica and print the replication stream it receives from the primary.
Check the latency of a Redis server and display statistics.
Request ASCII-art spectrogram of latency samples and frequencies.
This topic covers the different aspects of redis-cli, starting from the simplest and ending with the more advanced features.
Command line usage
To run a Redis command and return a standard output at the terminal, include the command to execute as separate arguments of redis-cli:
$ redis-cli INCR mycounter
(integer) 7
The reply of the command is "7". Since Redis replies are typed (strings, arrays, integers, nil, errors, etc.), you see the type of the reply between parentheses. This additional information may not be ideal when the output of redis-cli must be used as input of another command or redirected into a file.
redis-cli only shows additional information for human readability when it detects the standard output is a tty, or terminal. For all other outputs it will auto-enable the raw output mode, as in the following example:
$ redis-cli INCR mycounter > /tmp/output.txt
$ cat /tmp/output.txt
8
Note that (integer) is omitted from the output because redis-cli detects the output is no longer written to the terminal. You can force raw output even on the terminal with the --raw option:
$ redis-cli --raw INCR mycounter
9
You can force human readable output when writing to a file or in pipe to other commands by using --no-raw.
String quoting and escaping
When redis-cli parses a command, whitespace characters automatically delimit the arguments. In interactive mode, a newline sends the command for parsing and execution. To input string values that contain whitespaces or non-printable characters, you can use quoted and escaped strings.
Quoted string values are enclosed in double (") or single (') quotation marks. Escape sequences are used to put nonprintable characters in character and string literals.
An escape sequence contains a backslash (\) symbol followed by one of the escape sequence characters.
Doubly-quoted strings support the following escape sequences:
\" - double-quote
\n - newline
\r - carriage return
\t - horizontal tab
\b - backspace
\a - alert
\\ - backslash
\xhh - any ASCII character represented by a hexadecimal number (hh)
Single quotes assume the string is literal, and allow only the following escape sequences:
\' - single quote
\\ - backslash
For example, to return Hello World on two lines:
127.0.0.1:6379> SET mykey "Hello\nWorld"
OK
127.0.0.1:6379> GET mykey
Hello
World
When you input strings that contain single or double quotes, as you might in passwords, for example, escape the string, like so:
127.0.0.1:6379> AUTH some_admin_user ">^8T>6Na{u|jp>+v\"55\@_;OU(OR]7mbAYGqsfyu48(j'%hQH7;v*f1H${*gD(Se'"
Host, port, password, and database
By default, redis-cli connects to the server at the address 127.0.0.1 with port 6379. You can change the port using several command line options. To specify a different host name or an IP address, use the -h option. In order to set a different port, use -p.
$ redis-cli -h redis15.localnet.org -p 6390 PING
PONG
If your instance is password protected, the -a option will perform authentication saving the need of explicitly using the AUTH command:
$ redis-cli -a myUnguessablePazzzzzword123 PING
PONG
NOTE: For security reasons, provide the password to redis-cli automatically via the REDISCLI_AUTH environment variable.
Finally, it's possible to send a command that operates on a database number other than the default number zero by using the -n option:
$ redis-cli FLUSHALL
OK
$ redis-cli -n 1 INCR a
(integer) 1
$ redis-cli -n 1 INCR a
(integer) 2
$ redis-cli -n 2 INCR a
(integer) 1
Some or all of this information can also be provided by using the -u option and the URI pattern redis://user:password@host:port/dbnum:
$ redis-cli -u redis://LJenkins:p%[email protected]:16379/0 PING
PONG
SSL/TLS
By default, redis-cli uses a plain TCP connection to connect to Redis. You may enable SSL/TLS using the --tls option, along with --cacert or --cacertdir to configure a trusted root certificate bundle or directory.
If the target server requires authentication using a client side certificate, you can specify a certificate and a corresponding private key using --cert and --key.
Getting input from other programs
There are two ways you can use redis-cli in order to receive input from other commands via the standard input. One is to use the target payload as the last argument from stdin. For example, in order to set the Redis key net_services to the content of the file /etc/services from a local file system, use the -x option:
$ redis-cli -x SET net_services < /etc/services
OK
$ redis-cli GETRANGE net_services 0 50
"#\n# Network services, Internet style\n#\n# Note that "
In the first line of the above session, redis-cli was executed with the -x option and a file was redirected to the CLI's standard input as the value to satisfy the SET net_services command phrase. This is useful for scripting.
A different approach is to feed redis-cli a sequence of commands written in a text file:
$ cat /tmp/commands.txt
SET item:3374 100
INCR item:3374
APPEND item:3374 xxx
GET item:3374
$ cat /tmp/commands.txt | redis-cli
OK
(integer) 101
(integer) 6
"101xxx"
All the commands in commands.txt are executed consecutively by redis-cli as if they were typed by the user in interactive mode. Strings can be quoted inside the file if needed, so that it's possible to have single arguments with spaces, newlines, or other special characters:
$ cat /tmp/commands.txt
SET arg_example "This is a single argument"
STRLEN arg_example
$ cat /tmp/commands.txt | redis-cli
OK
(integer) 25
Continuously run the same command
It is possible to execute a single command a specified number of times with a user-selected pause between executions. This is useful in different contexts - for example when we want to continuously monitor some key content or INFO field output, or when we want to simulate some recurring write event, such as pushing a new item into a list every 5 seconds.
This feature is controlled by two options: -r and -i . The -r option states how many times to run a command and -i sets the delay between the different command calls in seconds (with the ability to specify values such as 0.1 to represent 100 milliseconds).
By default the interval (or delay) is set to 0, so commands are just executed ASAP:
$ redis-cli -r 5 INCR counter_value
(integer) 1
(integer) 2
(integer) 3
(integer) 4
(integer) 5
To run the same command indefinitely, use -1 as the count value. To monitor over time the RSS memory size it's possible to use the following command:
$ redis-cli -r -1 -i 1 INFO | grep rss_human
used_memory_rss_human:2.71M
used_memory_rss_human:2.73M
used_memory_rss_human:2.73M
used_memory_rss_human:2.73M
... a new line will be printed each second ...
Mass insertion of data using redis-cli
Mass insertion using redis-cli is covered in a separate page as it is a worthwhile topic itself. Please refer to our mass insertion guide.
CSV output
A CSV (Comma Separated Values) output feature exists within redis-cli to export data from Redis to an external program.
$ redis-cli LPUSH mylist a b c d
(integer) 4
$ redis-cli --csv LRANGE mylist 0 -1
"d","c","b","a"
Note that the --csv flag will only work on a single command, not the entirety of a DB as an export.
Running Lua scripts
The redis-cli has extensive support for using the debugging facility of Lua scripting, available with Redis 3.2 onwards. For this feature, refer to the Redis Lua debugger documentation.
Even without using the debugger, redis-cli can be used to run scripts from a file as an argument:
$ cat /tmp/script.lua
return redis.call('SET',KEYS[1],ARGV[1])
$ redis-cli --eval /tmp/script.lua location:hastings:temp , 23
OK
The Redis EVAL command takes the list of keys the script uses, and the other non key arguments, as different arrays. When calling EVAL you provide the number of keys as a number.
When calling redis-cli with the --eval option above, there is no need to specify the number of keys explicitly. Instead it uses the convention of separating keys and arguments with a comma. This is why in the above call you see location:hastings:temp , 23 as arguments.
So location:hastings:temp will populate the KEYS array, and 23 the ARGV array.
The --eval option is useful when writing simple scripts. For more complex work, the Lua debugger is recommended. It is possible to mix the two approaches, since the debugger can also execute scripts from an external file.
Interactive mode
We have explored how to use the Redis CLI as a command line program. This is useful for scripts and certain types of testing, however most people will spend the majority of time in redis-cli using its interactive mode.
In interactive mode the user types Redis commands at the prompt. The command is sent to the server, processed, and the reply is parsed back and rendered into a simpler form to read.
Nothing special is needed for running the redis-cli in interactive mode - just execute it without any arguments
$ redis-cli
127.0.0.1:6379> PING
PONG
The string 127.0.0.1:6379> is the prompt. It displays the connected Redis server instance's hostname and port.
The prompt updates as the connected server changes or when operating on a database different from the database number zero:
127.0.0.1:6379> SELECT 2
OK
127.0.0.1:6379[2]> DBSIZE
(integer) 1
127.0.0.1:6379[2]> SELECT 0
OK
127.0.0.1:6379> DBSIZE
(integer) 503
Handling connections and reconnections
Using the CONNECT command in interactive mode makes it possible to connect to a different instance, by specifying the hostname and port we want to connect to:
127.0.0.1:6379> CONNECT metal 6379
metal:6379> PING
PONG
As you can see the prompt changes accordingly when connecting to a different server instance. If a connection is attempted to an instance that is unreachable, the redis-cli goes into disconnected mode and attempts to reconnect with each new command:
127.0.0.1:6379> CONNECT 127.0.0.1 9999
Could not connect to Redis at 127.0.0.1:9999: Connection refused
not connected> PING
Could not connect to Redis at 127.0.0.1:9999: Connection refused
not connected> PING
Could not connect to Redis at 127.0.0.1:9999: Connection refused
Generally after a disconnection is detected, redis-cli always attempts to reconnect transparently; if the attempt fails, it shows the error and enters the disconnected state. The following is an example of disconnection and reconnection:
127.0.0.1:6379> INFO SERVER
Could not connect to Redis at 127.0.0.1:6379: Connection refused
not connected> PING
PONG
127.0.0.1:6379>
(now we are connected again)
When a reconnection is performed, redis-cli automatically re-selects the last database number selected. However, all other states about the connection is lost, such as within a MULTI/EXEC transaction:
$ redis-cli
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> PING
QUEUED
( here the server is manually restarted )
127.0.0.1:6379> EXEC
(error) ERR EXEC without MULTI
This is usually not an issue when using the redis-cli in interactive mode for testing, but this limitation should be known.
Editing, history, completion and hints
Because redis-cli uses the linenoise line editing library, it always has line editing capabilities, without depending on libreadline or other optional libraries.
Command execution history can be accessed in order to avoid retyping commands by pressing the arrow keys (up and down). The history is preserved between restarts of the CLI, in a file named .rediscli_history inside the user home directory, as specified by the HOME environment variable. It is possible to use a different history filename by setting the REDISCLI_HISTFILE environment variable, and disable it by setting it to /dev/null.
The redis-cli is also able to perform command-name completion by pressing the TAB key, as in the following example:
127.0.0.1:6379> Z
127.0.0.1:6379> ZADD
127.0.0.1:6379> ZCARD
Once Redis command name has been entered at the prompt, the redis-cli will display syntax hints. Like command history, this behavior can be turned on and off via the redis-cli preferences.
Preferences
There are two ways to customize redis-cli behavior. The file .redisclirc in the home directory is loaded by the CLI on startup. You can override the file's default location by setting the REDISCLI_RCFILE environment variable to an alternative path. Preferences can also be set during a CLI session, in which case they will last only the duration of the session.
To set preferences, use the special :set command. The following preferences can be set, either by typing the command in the CLI or adding it to the .redisclirc file:
:set hints - enables syntax hints
:set nohints - disables syntax hints
Running the same command N times
It is possible to run the same command multiple times in interactive mode by prefixing the command name by a number:
127.0.0.1:6379> 5 INCR mycounter
(integer) 1
(integer) 2
(integer) 3
(integer) 4
(integer) 5
Showing help about Redis commands
redis-cli provides online help for most Redis commands, using the HELP command. The command can be used in two forms:
HELP @ shows all the commands about a given category. The categories are:
@generic
@string
@list
@set
@sorted_set
@hash
@pubsub
@transactions
@connection
@server
@scripting
@hyperloglog
@cluster
@geo
@stream
HELP shows specific help for the command given as argument.
For example in order to show help for the PFADD command, use:
127.0.0.1:6379> HELP PFADD
PFADD key element [element ...]
summary: Adds the specified elements to the specified HyperLogLog.
since: 2.8.9
Note that HELP supports TAB completion as well.
Clearing the terminal screen
Using the CLEAR command in interactive mode clears the terminal's screen.
Special modes of operation
So far we saw two main modes of redis-cli.
Command line execution of Redis commands.
Interactive "REPL" usage.
The CLI performs other auxiliary tasks related to Redis that are explained in the next sections:
Monitoring tool to show continuous stats about a Redis server.
Scanning a Redis database for very large keys.
Key space scanner with pattern matching.
Acting as a Pub/Sub client to subscribe to channels.
Monitoring the commands executed into a Redis instance.
Checking the latency of a Redis server in different ways.
Checking the scheduler latency of the local computer.
Transferring RDB backups from a remote Redis server locally.
Acting as a Redis replica for showing what a replica receives.
Simulating LRU workloads for showing stats about keys hits.
A client for the Lua debugger.
Continuous stats mode
Continuous stats mode is probably one of the lesser known yet very useful features of redis-cli to monitor Redis instances in real time. To enable this mode, the --stat option is used. The output is very clear about the behavior of the CLI in this mode:
$ redis-cli --stat
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
506 1015.00K 1 0 24 (+0) 7
506 1015.00K 1 0 25 (+1) 7
506 3.40M 51 0 60461 (+60436) 57
506 3.40M 51 0 146425 (+85964) 107
507 3.40M 51 0 233844 (+87419) 157
507 3.40M 51 0 321715 (+87871) 207
508 3.40M 51 0 408642 (+86927) 257
508 3.40M 51 0 497038 (+88396) 257
In this mode a new line is printed every second with useful information and differences of request values between old data points. Memory usage, client connection counts, and various other statistics about the connected Redis database can be easily understood with this auxiliary redis-cli tool.
The -i option in this case works as a modifier in order to change the frequency at which new lines are emitted. The default is one second.
Scanning for big keys
In this special mode, redis-cli works as a key space analyzer. It scans the dataset for big keys, but also provides information about the data types that the data set consists of. This mode is enabled with the --bigkeys option, and produces verbose output:
$ redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.01 to sleep 0.01 sec
# per SCAN command (not usually needed).
[00.00%] Biggest string found so far 'key-419' with 3 bytes
[05.14%] Biggest list found so far 'mylist' with 100004 items
[35.77%] Biggest string found so far 'counter:__rand_int__' with 6 bytes
[73.91%] Biggest hash found so far 'myobject' with 3 fields
-------- summary -------
Sampled 506 keys in the keyspace!
Total key length in bytes is 3452 (avg len 6.82)
Biggest string found 'counter:__rand_int__' has 6 bytes
Biggest list found 'mylist' has 100004 items
Biggest hash found 'myobject' has 3 fields
504 strings with 1403 bytes (99.60% of keys, avg size 2.78)
1 lists with 100004 items (00.20% of keys, avg size 100004.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
1 hashs with 3 fields (00.20% of keys, avg size 3.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
In the first part of the output, each new key larger than the previous larger key (of the same type) encountered is reported. The summary section provides general stats about the data inside the Redis instance.
The program uses the SCAN command, so it can be executed against a busy server without impacting the operations, however the -i option can be used in order to throttle the scanning process of the specified fraction of second for each SCAN command.
For example, -i 0.01 will slow down the program execution considerably, but will also reduce the load on the server to a negligible amount.
Note that the summary also reports in a cleaner form the biggest keys found for each time. The initial output is just to provide some interesting info ASAP if running against a very large data set.
Getting a list of keys
It is also possible to scan the key space, again in a way that does not block the Redis server (which does happen when you use a command like KEYS *), and print all the key names, or filter them for specific patterns. This mode, like the --bigkeys option, uses the SCAN command, so keys may be reported multiple times if the dataset is changing, but no key would ever be missing, if that key was present since the start of the iteration. Because of the command that it uses this option is called --scan.
$ redis-cli --scan | head -10
key-419
key-71
key-236
key-50
key-38
key-458
key-453
key-499
key-446
key-371
Note that head -10 is used in order to print only the first ten lines of the output.
Scanning is able to use the underlying pattern matching capability of the SCAN command with the --pattern option.
$ redis-cli --scan --pattern '*-11*'
key-114
key-117
key-118
key-113
key-115
key-112
key-119
key-11
key-111
key-110
key-116
Piping the output through the wc command can be used to count specific kind of objects, by key name:
$ redis-cli --scan --pattern 'user:*' | wc -l
3829433
You can use -i 0.01 to add a delay between calls to the SCAN command. This will make the command slower but will significantly reduce load on the server.
Pub/sub mode
The CLI is able to publish messages in Redis Pub/Sub channels using the PUBLISH command. Subscribing to channels in order to receive messages is different - the terminal is blocked and waits for messages, so this is implemented as a special mode in redis-cli. Unlike other special modes this mode is not enabled by using a special option, but simply by using the SUBSCRIBE or PSUBSCRIBE command, which are available in interactive or command mode:
$ redis-cli PSUBSCRIBE '*'
Reading messages... (press Ctrl-C to quit)
1) "PSUBSCRIBE"
2) "*"
3) (integer) 1
The reading messages message shows that we entered Pub/Sub mode. When another client publishes some message in some channel, such as with the command redis-cli PUBLISH mychannel mymessage, the CLI in Pub/Sub mode will show something such as:
1) "pmessage"
2) "*"
3) "mychannel"
4) "mymessage"
This is very useful for debugging Pub/Sub issues. To exit the Pub/Sub mode just process CTRL-C.
Monitoring commands executed in Redis
Similarly to the Pub/Sub mode, the monitoring mode is entered automatically once you use the MONITOR command. All commands received by the active Redis instance will be printed to the standard output:
$ redis-cli MONITOR
OK
1460100081.165665 [0 127.0.0.1:51706] "set" "shipment:8000736522714:status" "sorting"
1460100083.053365 [0 127.0.0.1:51707] "get" "shipment:8000736522714:status"
Note that it is possible to use to pipe the output, so you can monitor for specific patterns using tools such as grep.
Monitoring the latency of Redis instances
Redis is often used in contexts where latency is very critical. Latency involves multiple moving parts within the application, from the client library to the network stack, to the Redis instance itself.
The redis-cli has multiple facilities for studying the latency of a Redis instance and understanding the latency's maximum, average and distribution.
The basic latency-checking tool is the --latency option. Using this option the CLI runs a loop where the PING command is sent to the Redis instance and the time to receive a reply is measured. This happens 100 times per second, and stats are updated in a real time in the console:
$ redis-cli --latency
min: 0, max: 1, avg: 0.19 (427 samples)
The stats are provided in milliseconds. Usually, the average latency of a very fast instance tends to be overestimated a bit because of the latency due to the kernel scheduler of the system running redis-cli itself, so the average latency of 0.19 above may easily be 0.01 or less. However this is usually not a big problem, since most developers are interested in events of a few milliseconds or more.
Sometimes it is useful to study how the maximum and average latencies evolve during time. The --latency-history option is used for that purpose: it works exactly like --latency, but every 15 seconds (by default) a new sampling session is started from scratch:
$ redis-cli --latency-history
min: 0, max: 1, avg: 0.14 (1314 samples) -- 15.01 seconds range
min: 0, max: 1, avg: 0.18 (1299 samples) -- 15.00 seconds range
min: 0, max: 1, avg: 0.20 (113 samples)^C
Sampling sessions' length can be changed with the -i option.
The most advanced latency study tool, but also the most complex to interpret for non-experienced users, is the ability to use color terminals to show a spectrum of latencies. You'll see a colored output that indicates the different percentages of samples, and different ASCII characters that indicate different latency figures. This mode is enabled using the --latency-dist option:
$ redis-cli --latency-dist
(output not displayed, requires a color terminal, try it!)
There is another pretty unusual latency tool implemented inside redis-cli. It does not check the latency of a Redis instance, but the latency of the computer running redis-cli. This latency is intrinsic to the kernel scheduler, the hypervisor in case of virtualized instances, and so forth.
Redis calls it intrinsic latency because it's mostly opaque to the programmer. If the Redis instance has high latency regardless of all the obvious things that may be the source cause, it's worth to check what's the best your system can do by running redis-cli in this special mode directly in the system you are running Redis servers on.
By measuring the intrinsic latency, you know that this is the baseline, and Redis cannot outdo your system. In order to run the CLI in this mode, use the --intrinsic-latency . Note that the test time is in seconds and dictates how long the test should run.
$ ./redis-cli --intrinsic-latency 5
Max latency so far: 1 microseconds.
Max latency so far: 7 microseconds.
Max latency so far: 9 microseconds.
Max latency so far: 11 microseconds.
Max latency so far: 13 microseconds.
Max latency so far: 15 microseconds.
Max latency so far: 34 microseconds.
Max latency so far: 82 microseconds.
Max latency so far: 586 microseconds.
Max latency so far: 739 microseconds.
65433042 total runs (avg latency: 0.0764 microseconds / 764.14 nanoseconds per run).
Worst run took 9671x longer than the average latency.
IMPORTANT: this command must be executed on the computer that runs the Redis server instance, not on a different host. It does not connect to a Redis instance and performs the test locally.
In the above case, the system cannot do better than 739 microseconds of worst case latency, so one can expect certain queries to occasionally run less than 1 millisecond.
Remote backups of RDB files
During a Redis replication's first synchronization, the primary and the replica exchange the whole data set in the form of an RDB file. This feature is exploited by redis-cli in order to provide a remote backup facility that allows a transfer of an RDB file from any Redis instance to the local computer running redis-cli. To use this mode, call the CLI with the --rdb option:
$ redis-cli --rdb /tmp/dump.rdb
SYNC sent to master, writing 13256 bytes to '/tmp/dump.rdb'
Transfer finished with success.
This is a simple but effective way to ensure disaster recovery RDB backups exist of your Redis instance. When using this options in scripts or cron jobs, make sure to check the return value of the command. If it is non zero, an error occurred as in the following example:
$ redis-cli --rdb /tmp/dump.rdb
SYNC with master failed: -ERR Can't SYNC while not connected with my master
$ echo $?
1
Replica mode
The replica mode of the CLI is an advanced feature useful for Redis developers and for debugging operations. It allows for the inspection of the content a primary sends to its replicas in the replication stream in order to propagate the writes to its replicas. The option name is simply --replica. The following is a working example:
$ redis-cli --replica
SYNC with master, discarding 13256 bytes of bulk transfer...
SYNC done. Logging commands from master.
"PING"
"SELECT","0"
"SET","last_name","Enigk"
"PING"
"INCR","mycounter"
The command begins by discarding the RDB file of the first synchronization and then logs each command received in CSV format.
If you think some of the commands are not replicated correctly in your replicas this is a good way to check what's happening, and also useful information in order to improve the bug report.
Performing an LRU simulation
Redis is often used as a cache with LRU eviction. Depending on the number of keys and the amount of memory allocated for the cache (specified via the maxmemory directive), the amount of cache hits and misses will change. Sometimes, simulating the rate of hits is very useful to correctly provision your cache.
The redis-cli has a special mode where it performs a simulation of GET and SET operations, using an 80-20% power law distribution in the requests pattern. This means that 20% of keys will be requested 80% of times, which is a common distribution in caching scenarios.
Theoretically, given the distribution of the requests and the Redis memory overhead, it should be possible to compute the hit rate analytically with a mathematical formula. However, Redis can be configured with different LRU settings (number of samples) and LRU's implementation, which is approximated in Redis, changes a lot between different versions. Similarly the amount of memory per key may change between versions. That is why this tool was built: its main motivation was for testing the quality of Redis' LRU implementation, but now is also useful for testing how a given version behaves with the settings originally intended for deployment.
To use this mode, specify the amount of keys in the test and configure a sensible maxmemory setting as a first attempt.
IMPORTANT NOTE: Configuring the maxmemory setting in the Redis configuration is crucial: if there is no cap to the maximum memory usage, the hit will eventually be 100% since all the keys can be stored in memory. If too many keys are specified with maximum memory, eventually all of the computer RAM will be used. It is also needed to configure an appropriate maxmemory policy; most of the time allkeys-lru is selected.
In the following example there is a configured a memory limit of 100MB and an LRU simulation using 10 million keys.
WARNING: the test uses pipelining and will stress the server, don't use it with production instances.
$ ./redis-cli --lru-test 10000000
156000 Gets/sec | Hits: 4552 (2.92%) | Misses: 151448 (97.08%)
153750 Gets/sec | Hits: 12906 (8.39%) | Misses: 140844 (91.61%)
159250 Gets/sec | Hits: 21811 (13.70%) | Misses: 137439 (86.30%)
151000 Gets/sec | Hits: 27615 (18.29%) | Misses: 123385 (81.71%)
145000 Gets/sec | Hits: 32791 (22.61%) | Misses: 112209 (77.39%)
157750 Gets/sec | Hits: 42178 (26.74%) | Misses: 115572 (73.26%)
154500 Gets/sec | Hits: 47418 (30.69%) | Misses: 107082 (69.31%)
151250 Gets/sec | Hits: 51636 (34.14%) | Misses: 99614 (65.86%)
该程序每秒显示统计数据。在最初的几秒钟内,缓存开始填充。未命中率随后稳定为可预期的实际数字:
The program shows stats every second. In the first seconds the cache starts to be populated. The misses rate later stabilizes into the actual figure that can be expected:
120750 Gets/sec | Hits: 48774 (40.39%) | Misses: 71976 (59.61%)
122500 Gets/sec | Hits: 49052 (40.04%) | Misses: 73448 (59.96%)
127000 Gets/sec | Hits: 50870 (40.06%) | Misses: 76130 (59.94%)
124250 Gets/sec | Hits: 50147 (40.36%) | Misses: 74103 (59.64%)
59%的未命中率对于某些用例来说可能是不可接受的,因此100MB的内存是不够的。观察一个使用半GB内存的示例。几分钟后,输出稳定在以下数字:
A miss rate of 59% may not be acceptable for certain use cases therefor 100MB of memory is not enough. Observe an example using a half gigabyte of memory. After several minutes the output stabilizes to the following figures:
140000 Gets/sec | Hits: 135376 (96.70%) | Misses: 4624 (3.30%)
141250 Gets/sec | Hits: 136523 (96.65%) | Misses: 4727 (3.35%)
140250 Gets/sec | Hits: 135457 (96.58%) | Misses: 4793 (3.42%)
140500 Gets/sec | Hits: 135947 (96.76%) | Misses: 4553 (3.24%)
With 500MB there is sufficient space for the key quantity (10 million) and distribution (80-20 style).
500MB有足够的空间用于密钥数量(1000万)和分发(80-20样式)。
RedisInsight
可视化和优化Redis数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CWXRG0Bz-1689071082335)(https://img.shields.io/discord/697882427875393627?style=flat-square)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hybOwpYU-1689071082336)(https://img.shields.io/static/v1?label=&message=repository&color=5961FF&logo=github)]
RedisInsight是一个强大的工具,用于在Redis或Redis Stack中可视化和优化数据,使实时应用程序开发比以往任何时候都更容易、更有趣。RedisInsight允许您在功能齐全的桌面GUI客户端中进行基于GUI和CLI的交互。
Download the latest RedisInsight
- 在这下载最新的 RedisInsight
- RedisInsight 发布说明
Overview 概述
连接管理
- 自动发现并添加本地Redis或Redis Stack数据库(使用独立连接类型,不需要身份验证)。
- 在Redis Enterprise Cluster中发现您的数据库,在Redis Cloud中发现具有灵活计划的数据库。
- 使用表单输入您的连接详细信息,并添加任何运行在任何地方的Redis数据库(包括OSS Cluster、Sentinel)。
浏览器
浏览、过滤和可视化您的关键价值Redis数据结构。
-
CRUD support for lists, hashes, strings, sets, sorted sets, and streams
-
CRUD support for JSON
-
Group keys according to their namespaces 根据密钥的名称空间对其进行分组
-
使用格式化程序以可读格式查看、验证和管理您的键值,这些格式化程序可以在浏览器工具中美化和突出显示不同格式(例如,Unicode、JSON、MessagePack、HEX和ASCII)的数据。
Profiler 性能分析器
Analyze every command sent to Redis in real time. 实时分析发送给Redis的每个命令。

CLI
CLI可以在应用程序中随时访问。
-
采用综合帮助提供直观的帮助
-
与一个方便的命令助手一起使用,可以搜索和阅读Redis命令。

工作台
高级命令行界面,具有智能命令自动完成和复杂数据可视化功能。
-
内置指南(Built-in guides):使用内置指南,您可以方便地发现Redis和Redis Stack的功能。
-
命令自动完成对Redis和Redis statck中所有功能的支持。 Command auto-complete support for all features in Redis and Redis Stack.
-
索引、查询和聚合(indexes, queries, and aggregations)的可视化。
-
可视化(Visualizations)您的时间序列 time series数据。
工具
数据库分析
使用数据库分析工具来优化(optimize)Redis数据库的性能和内存使用情况(the performance and memory usage)。检查数据类型分布和内存分配,并查看 key 过期时间和随时间释放的内存的摘要。分别检查按消耗的内存或 keys长度和keys 计数排序的顶部 keys 和命名空间。通过查看历史分析报告来捕获和跟踪数据库中的更改。下图显示了一个示例数据库分析报告。

Redis Streams支持
通过按时间戳添加、删除和筛选条目来创建和管理流。要查看和使用新条目,请启用和自定义自动刷新率。enable and customize the automatic refresh rate.
查看和管理使用者组的列表。查看给定使用者名称中的现有使用者以及最后传递给他们的消息。检查挂起消息的列表,明确确认已处理的项目,或通过RedisInsight声明未处理的消息。
[外链图片转存中…(img-xc7Smydl-1689071082338)]
Search features 搜索功能
如果您正在使用 Redis Stack的索引、查询或全文搜索功能(indexing, querying, or full-text search features),RedisInsight提供了UI控件,可以根据预先选择的索引快速方便地运行搜索查询。您还可以在专用窗格中创建数据的辅助索引。
Bulk actions 批量操作
轻松快速地批量删除相同类型和/或具有相同 keys 名称模式的多个 key。要执行此操作,请在“列表” List或“树” Tree视图中,按 key 类型或 key 名称设置筛选器,然后打开“批量操作”部分。该部分显示所有 key 的摘要,以及将根据设置的筛选器删除的预期key数。
批量删除完成后,RedisInsight会显示此操作的结果以及处理的 key 数量和批量删除 key 所花费的时间。根据Redis数据库分析的结果,使用批量删除来优化数据库的使用。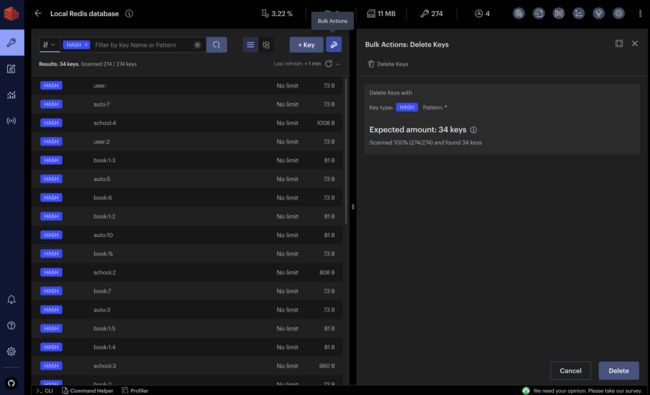
Slow Log 慢日志
慢日志工具显示SLOWLOG命令捕获的日志列表,以分析超过指定运行时间的所有命令,这有助于解决性能问题。指定Slowlog的运行时间和最大长度(这是服务器配置)以配置记录的命令列表,并设置自动刷新间隔以自动更新显示的命令列表。

Plugins
使用RedisInsight,您现在还可以通过构建自己的数据可视化来扩展核心功能。See our plugin documentation for more information.
Telemetry 遥测
RedisInsight includes an opt-in telemetry system. This help us improve the developer experience of the app. We value your privacy; all collected data is anonymized.
RedisInsight包括一个选择加入遥测系统。这有助于我们改善应用程序的开发体验。我们重视您的隐私;所有收集的数据都是匿名的。
Feedback 反馈
To provide your feedback, open a ticket in our RedisInsight repository.
提供您的反馈,请在我们的RedisInsight存储库中打开票证。
License 许可证
RedisInsight is licensed under SSPL license.
Manage streams and consumer groups in RedisInsight
Learn how to manage streams and consumer groups in RedisInsight
RedisInsight根据SSPL获得许可证。
在RedisInsight中管理流和消费者组
了解如何在RedisInsight中管理流和消费者组
在RedisInsight中管理流和消费者组
了解如何在RedisInsight中管理流和消费者组
stream是一个仅追加的日志文件。当你向它添加数据时,你无法更改它。这似乎是一个缺点;然而,一个流充当一个日志或单一的真相来源。它还可以用作以不同速度工作且不需要了解彼此的进程之间的缓冲区。有关流的更多概念信息,请参阅RRedis streams。
在本主题中,您将学习如何在RedisInsight中添加和使用流以及消费者组。
这是一个模拟温度和湿度传感器的流。与流交互的进程执行两个角色之一:消费者和生产者。流的意义在于它不会结束,因此您无法捕获整个数据集并对其进行一些处理。
在这个流中,传感器被视为广播数据的“生产者”。消费者从流中读取并对其进行一些处理。例如,如果温度高于某个阈值,它会发出一条消息,打开该单元的空调或通知维修人员。

可以让多个消费者做不同的工作,一个测量湿度,另一个在一段时间内测量温度。Redis将整个数据集的副本存储在内存中,这是一个有限的资源。为了避免数据失控,可以在向流中添加内容时对其进行修剪。使用XADD添加到流时,您可以选择指定流应修剪为特定数量或近似数量的最新条目,或者仅包括ID高于指定ID的条目。您还可以使用密钥过期来管理流式传输数据所需的存储。例如,通过将每天的数据写入Redis中自己的流,并在一段时间后(例如一周)使每个流的密钥过期。ID可以是任何数字,但流中的每个新条目都必须具有一个ID,该ID的值高于添加到流中的上一个ID。
Adding new entries 添加新条目
使用XADD用“*”表示ID,让Redis自动为您生成一个新的ID,该ID由毫秒精度的时间戳、短划线和序列号组成。例如“1656416957625-0”。然后提供要存储在新流条目中的字段名称和值。
有几种检索东西的方法。您可以按时间范围检索条目,也可以询问自指定的时间戳或ID以来发生的一切。使用一个命令,你可以在给定的一天从10:30到11:15要求任何事情。
Consumer groups 消费者组
一个更现实的用例是一个具有许多温度传感器的系统,Redis将这些传感器的数据放入流中,记录它们到达的时间,并对它们进行订购。 
在右侧,我们有两个读取流的消费者。其中一个是在温度超过一定数值时发出警报,并给维修人员发短信说他们需要做点什么,另一个是数据仓库,它正在获取数据并将其放入数据库。
它们彼此独立运行。在右边,我们有另一种任务。让我们假设警报和数据仓库非常快。您会收到一条消息,说明温度是否大于特定值,这可能需要一毫秒的时间。警报可以跟上数据流。扩展使用者的一种方法是consumergroups,它允许同一使用者或同一代码的多个实例作为一个团队来处理流。
Managing streams in RedisInsight
You can add a stream in RedisInsight in two ways: create a new stream or add to an existing stream.
要创建流,请首先选择key类型(流)。您不能设置生存时间(TTL),因为它不能放在流中的消息上;它只能在Redis key 上完成。将流命名为mystream。然后,将Entry ID设置为“*”以默认为时间戳。如果您有自己的ID生成策略,请输入序列中的下一个ID。请记住,ID必须高于流中任何其他条目的ID。
然后,使用+输入字段和值以添加多个字段和值(例如,名称和位置)。现在,您有一个流出现在Streams视图中,您可以继续向其中添加字段和值。
RedisInsight为您运行读取命令,以便您可以在Streams视图中查看流条目。消费者组视图显示了给定消费者组中的每个消费者以及Redis上次分配消息的时间、消息的ID是什么以及该过程发生了多少次,以及消费者是否已经使用XACK告诉Redis您已经完成了该任务命令。
Monitor temperature and humidity from sensors in RedisInsight
通过RedisInsight中的传感器监测温度和湿度
This example shows how to bring an existing stream into RedisInsight and work with it.
此示例显示如何将现有流引入RedisInsight并使用它。
Setup
- Install RedisInsight.
- Download and install Node.js (LTS version).
- Install Redis. In Docker, check that Redis is running locally on the default port 6379 (with no password set).
- Clone the code repository for this example. See the README for more information about this example and installation tips.
- On your command-line, navigate to the folder containing the code repository and install the Node.js package manager (npm).
1.安装RedisInsight。
2.下载并安装Node.js(LTS版本)。
3.安装Redis。在Docker中,检查Redis是否在默认端口6379上本地运行(没有设置密码)。
4.克隆代码库对于这个例子。请参阅自述文件 README有关此示例和安装提示的更多信息。
5.在命令行上,导航到包含代码存储库的文件夹,然后安装Node.js包管理器(npm)。
npm install
Run the producer
To start the producer, which will add a new entry to the stream every few seconds, enter:
要启动生产者,每隔几秒钟就会向流中添加一个新条目,请输入:
npm run producer
> [email protected] producer
> node producer.js
Starting producer...
Adding reading for location: 62, temperature: 40.3, humidity: 36.5
Added as 1632771056648-0
Adding reading for location: 96, temperature: 15.4, humidity: 70
Added as 1632771059039-0
...
The producer runs indefinitely. Select Ctrl+C to stop it. You can start multiple instances of the producer if you want to add entries to the stream faster.
生产商无限期运行。选择“Ctrl+C”停止它。如果你想更快地将条目添加到流中,你可以启动生产者的多个实例。
Run the consumer
To start the consumer, which reads from the stream every few seconds, enter:
要启动每隔几秒钟从流中读取一次的使用者,请输入:
npm run consumer
> [email protected] consumer
> node consumer.js
Starting consumer...
Resuming from ID 1632744741693-0
Reading stream...
Received entry 1632771056648-0:
[ 'location', '62', 'temp', '40.3', 'humidity', '36.5' ]
Finished working with entry 1632771056648-0
Reading stream...
Received entry 1632771059039-0:
[ 'location', '96', 'temp', '15.4', 'humidity', '70' ]
The consumer stores the last entry ID that it read in a Redis string at the key consumer:lastid. It uses this string to pick up from where it left off after it is restarted. Try this out by stopping it with Ctrl+C and restarting it.
Once the consumer has processed every entry in the stream, it will wait indefinitely for instances of the producer to add more:
使用者将其读取的最后一个条目ID存储在Redis字符串中的关键字“consumer:lastid”处。它使用这个字符串从重新启动后停止的位置开始。试着用“Ctrl+C”停止它,然后重新启动它。
一旦使用者处理了流中的每个条目,它将无限期地等待生产者的实例添加更多:
Reading stream...
No new entries since entry 1632771060229-0.
Reading stream...
No new entries since entry 1632771060229-0.
Reading stream...
Stop it using Ctrl+C.
Run a consumer group
A consumer group consists of multiple consumer instances working together. Redis manages allocation of entries read from the stream to members of a consumer group. A consumer in a group will receive a subset of the entries, with the group as a whole receiving all of them. When working in a consumer group, a consumer process must acknowledge receipt/processing of each entry.
Using multiple terminal windows, start three instances of the consumer group consumer, giving each a unique name:
一个消费者组由多个共同工作的消费者实例组成。Redis管理从流中读取的条目分配给使用者组的成员。组中的消费者将接收条目的一个子集,整个组将接收所有条目。在消费者组中工作时,消费者流程必须确认每个条目的接收/处理。
使用多个终端窗口,启动消费者组消费者的三个实例,为每个实例提供一个唯一的名称:
npm run consumergroup consumer1
> [email protected] consumergroup
> node consumer_group.js -- "consumer1"
Starting consumer consumer1...
Consumer group temphumidity_consumers exists, not created.
Reading stream...
Received entry 1632771059039-0:
[ 'location', '96', 'temp', '15.4', 'humidity', '70' ]
Acknowledged processing of entry 1632771059039-0.
Reading stream...
In a second terminal:
npm run consumergroup consumer2
And in a third:
npm run consumergroup consumer3
The consumers will run indefinitely, waiting for new messages to be added to the stream by a producer instance when they have collectively consumed the entire stream. Note that in this model, each consumer instance does not receive all of the entries from the stream, but the three members of the group each receive a subset.
消费者将无限期地运行,等待生产者实例在他们共同消费了整个流后将新消息添加到流中。请注意,在这个模型中,每个使用者实例并不接收流中的所有条目,而是组的三个成员各自接收一个子集。
View the stream in RedisInsight
- Launch RedisInsight. 启动RedisInsight。
- Select
localhost:6379 - Select STREAM. Optionally, select full screen from the upper right corner to expand the view. (可选)从右上角选择全屏以展开视图。

您现在可以在 Stream 和 Consumer Groups 视图之间切换以查看您的数据。正如本主题前面提到的,流是一个仅追加的日志,因此您不能修改条目的内容,但可以删除整个条目。一个有用的例子是,如果出现所谓的“毒丸信息” poison-pill message,可能会导致消费者崩溃。您可以在Streams视图中物理删除此类消息,也可以使用XDEL命令行界面(CLI)上的命令。
您可以在CLI中继续与流交互。例如,要获取流的当前长度,请使用XLEN命令:
XLEN ingest:temphumidity
使用流审计和处理(auditing and processing)银行、游戏、供应链、物联网、社交媒体等领域的事件。
Related topics 相关主题
- Redis Streams
- Introducing Redis Streams with RedisInsight, node.js, and Python (video)