浅谈数据结构中的链表,以及内部实现方式
接下来,我们来谈谈线性结构中的链表。为什么要讲链表呢?这是因为java中有很多集合类底层都是通过链表来实现的。而且面试的时候,链表的实现是经常考的一个知识点。所以这篇文章的重点在于,如何使用代码去实现这些数据结构。
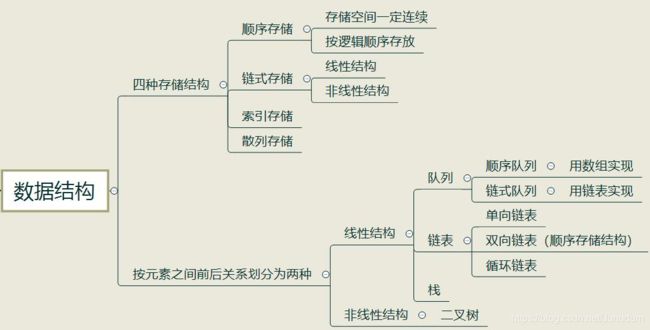
顺序存储结构:用一段地址连续的存储单元依次存储线性表的数据元素。
链式存储结构:地址可以连续也可以不连续的存储单元存储数据元素
链表实际上是线性表的链式存储结构,与数组不同的是,它是用一组任意的存储单元来存储线性表中的数据,存储单元不一定是连续的,
一.基本概念
链表是一系列的存储数据元素的单元通过指针串接起来形成的,因此每个单元至少有两个域,一个域用于数据元素的存储,另一个或两个域是指向其他单元的指针。这里具有一个数据域和多个指针域的存储单元通常称为节点(node)。
链表一般分为:单向链表,双向链表以及循环链表
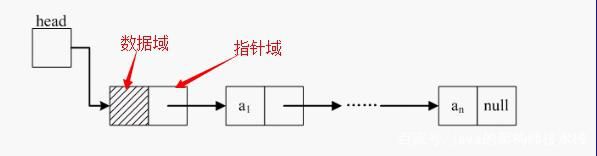
单向链表:每个节点中包含两个区域,分别是数据域(data)和指针域(pointer),单向列表中的特点是节点中包含下一个节点的指针,如下图:
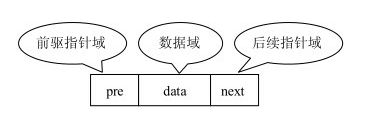
双向链表:和单向链表不同的是,双向链表的指针域中定义了前驱和后驱,分别映射到前后的节点,如下图:
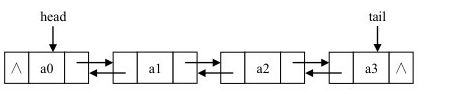
这个双向链表相对于单链表还是比较复杂的,毕竟每个节点多了一个前驱,因此对于插入和删除要格外小心。双向链表的优点在于对每个节点的相邻接点操作时候,效率会比较高。
循环链表:头节点和尾节点被连接在一起的链表称为循环链表,这种方式在单向和双向链表中皆可实现。循环链表中第一个节点之前就是最后一个节点,
单向循环:

双向循环:

结构就介绍到这了,接下来我们用java代码来实现以下单链表中的增删操作
首先,我们 要对节点(Node)进行一个定义
public class Node<T> {
public Node<T> pointer; // 指针域,指向下一个节点
private T data; // 数据域
public Node(T data,Node<T> pointer){
this.data = data;
this.pointer = pointer;
}
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
}
接下来,我们定义一个链表
public class LinkedList<T> {
private Node<T> head; // 头部节点
private Node<T> tail; // 尾部节点
private int size; // 链表长度
public LinkedList(){
head = null;
tail = null;
}
public int getSize() {
return size;
}
public boolean isEmpty(){
return size == 0;
}
/**
* 获取指定位置的节点
* @param index
* @return
*/
public Node<T> getNodeByIndex(int index){
if(index < 0 || index > size-1 ){
throw new IndexOutOfBoundsException("索引越界");
}
Node<T> node = head;
for(int i = 0,in = size-1;i<in;i++,node = node.pointer){
if (i == index) return node;
}
return null;
}
}
插入操作: 分三种场景:首部插入,中间插入,尾部插入

首部插入
/**
* 首部插入
* @param element
*/
public void addAtHead(T element){
head = new Node<T>(element,head);
if(tail == null){
tail = head;
}
size++;
}中间插入
/**
* 插入元素
* @param elememt
* @param index
*/
public void insert (T elememt,int index){
if(index < 0 || index > size){
throw new IndexOutOfBoundsException("索引越界");
}
if(index == 0){
addAtHead(elememt);
}else if(index>0 || index < size-1){
// 中间插入
Node<T> nextNode = null;
Node<T> insertNode = new Node<T>(elememt,nextNode);
nextNode = getNodeByIndex(index);
Node<T> parentNode = getNodeByIndex(index-1);
parentNode.pointer = insertNode;
insertNode.pointer = nextNode;
size++;
}else{
addAtTail(elememt);
}
}尾部插入
/**
* 尾部插入
* @param elememt
*/
public void addAtTail(T elememt){
if(head == null){
head = new Node<T>(elememt,null);
tail = head;
}else{
Node<T> node = new Node<T>(elememt,null);
tail.pointer = node; // 原来的尾节点指针要改为 最新的节点
tail = node; // 替换尾结点
}
size++;
}删除操作

/**
* 删除某个节点
* @param index
*/
public void delete(int index){
if(index < 0 || index > size-1){
throw new IndexOutOfBoundsException("索引越界");
}
Node<T> node = getNodeByIndex(index);
if(index-1 < 0){
// 删除首节点
head = head.pointer;
size--;
}else{
// 删除中间节点
Node<T> parentNode = getNodeByIndex(index-1);
parentNode.pointer = node.pointer;
if(index == size-1){
// 删除尾部节点
tail = parentNode;
}
size--;
}
}
// 移除最后一个节点
public remove(){
delete(size-1);
}小结:
像上面这种只包含一个指针域、由n个节点链接形成的链表,就称为线型链表或者单向链表,链表只能顺序访问,不能随机访问,链表这种存储方式最大缺点就是容易出现断链,
一旦链表中某个节点的指针域数据丢失,那么意味着将无法找到下一个节点,该节点后面的数据将全部丢失
链表与数组比较
数组(包括结构体数组)的实质是一种线性表的顺序表示方式,它的优点是使用直观,便于快速、随机地存取线性表中的任一元素,但缺点是对其进行 插入和删除操作时需要移动大量的数组元素,同时由于数组属于静态内存分配,定义数组时必须指定数组的长度,程序一旦运行,其长度就不能再改变,实际使用个数不能超过数组元素最大长度的限制,否则就会发生下标越界的错误,低于最大长度时又会造成系统资源的浪费,因此空间效率差
缺点:
1、比顺序存储结构的存储密度小 (每个节点都由数据域和指针域组成,所以相同空间内假设全存满的话顺序比链式存储更多)。
2、查找结点时链式存储要比顺序存储慢(每个节点地址不连续、无规律,导致按照索引查询效率低下)。
优点:
1、插入、删除灵活 (不必移动节点,只要改变节点中的指针,但是需要先定位到元素上)。
2、有元素才会分配结点空间,不会有闲置的结点。
常见面试题,你会几个?
1、单链表的创建和遍历本题上面已经给出答案,这里不再说了。
2、求单链表中节点的个数这一题相当于,遍历一遍链表
3、查找单链表中的倒数第k个结点 :先计算出链表的长度size,然后直接输出第(size-k)个节点就可以了
4、查找单链表中的中间结点你可以先获取整个链表的长度N,N/2就好了。
5、合并两个有序的单链表,合并之后的链表依然有序【出现频率高】这个类似于归并排序,你创建一个新链表,然后把上面两个链表依次比较,插入新链表
6、单链表的反转【出现频率最高】这个是对插入操作的考察,在上面写了三种插入操作实现方式,从头到尾遍历链表,取出当前链表节点,插入新链表的头结点。这样第一个取出的节点,在新链表就是最后一个
7、从尾到头打印单链表
8、判断单链表是否有环这里也是用到两个指针,如果一个链表有环,那么用一个指针去遍历,是永远走不到头的。因此,我们用两个指针去遍历:first指针每次走一步,second指针每次走两步,如果first指针和second指针相遇,说明有环。
9、取出有环链表中,环的长度
10、单链表中,取出环的起始点
11、判断两个单链表相交的第一个交点
12、 已知一个单链表中存在环,求进入环中的第一个节点