4、目标检测
目标检测
- 一、分类和发展史
- 二、Anchor锚
- 三、anchor-based
-
- 1、one-stage
- 2、two-stage
- 四、anchor-free
- 五、YOLO系列
- 六、R-CNN系列
-
- **1、R-CNN**
- 2、Spp-Net
- 3、Fast-RCNN
- 4、Faster-RCNN
- 5、Mask-RCNN
一、分类和发展史
计算机视觉的任务很多,有图像分类、目标检测、图像分割(语义分割、实例分割和全景分割等)、图像生成。
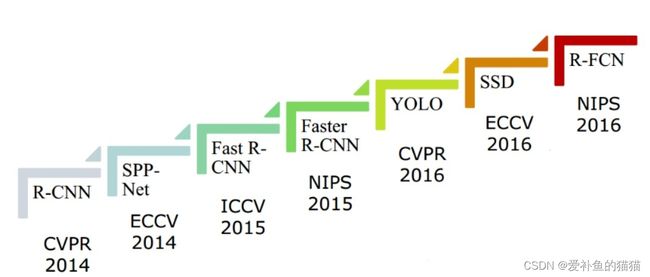
目标检测的发展脉络可以划分为两个周期:传统目标检测算法时期(1998年-2014年)和基于深度学习的目标检测算法时期(2014年-至今)。而基于深度学习的目标检测算法又发展成了两条技术路线:Anchor based方法(一阶段,二阶段)和Anchor free方法。下图2-1展示了从2001年至2021年目标检测领域中,目标检测发展路线图。
参考连接:https://zhuanlan.zhihu.com/p/393997909
1. anchor-free 和 anchor-based 区别
我们在学习Faster R-CNN的时候第一次遇到anchor的概念,它利用anchor匹配正负样本,从而缩小搜索空间,更准确、简单地进行梯度回传,训练网络。但是anchor也会对网络的性能带来影响,如巡训练匹配时较高的开销、有许多超参数需要人为尝试调节等。而anchor-free模型则摒弃或是绕开了锚的概念,用更加精简的方式来确定正负样本,同时达到甚至超越了两阶段anchor-based的模型精度,并拥有更快的速度。这也让one-stage和two-stage的边缘更加模糊。
参考链接:https://www.zhihu.com/question/356551927/answer/2474262336
深度学习目标检测通常都被建模成对一些候选区域进行分类和回归的问题。在单阶段检测器中,这些候选区域就是通过滑窗方式产生的 anchor;在两阶段检测器中,候选区域是 RPN 生成的 proposal,但是 RPN 本身仍然是对滑窗方式产生的 anchor 进行分类和回归。
anchor-free是通过另外一种手段来解决检测问题的。同样分为两个子问题,即确定物体中心和对四条边框的预测。预测物体中心时,将中心预测融入到类别预测的 target 里面,也可以预测一个 soft 的 centerness score。对于四条边框的预测,则比较一致,都是预测该像素点到 ground truth 框的四条边距离,不过会使用一些 trick 来限制 regress 的范围。
Anchor based: 如RetinaNet基于anchor的回归,首先计算来自不同尺度的anchor box与gt的IoU来确定正负样本;对于每个目标在所有IoU大于阈值k的anchor box中,选择最大的作为正样本,所有IoU小于阈值q的anchor box作为负样本,其余忽略不计;最后针对正样本的anchor回归相对偏移量Anchor free: 如FCOS基于center做回归,使用空间和尺度约束将anchor点分配到不同尺度上,通过判断特征图上的点是否落入gt中来确认正负样本,即将物体边框内的所有位置都定义为正样本;最后通过4个距离值和1个 中心点的分数来检测物体。

方法三大分类:
基于区域建议的目标检测与识别算法,如R-CNN, Fast-R-CNN, Faster-R-CNN
基于回归的目标检测与识别算法,如YOLO, SSD;
基于搜索的目标检测与识别算法,如基于视觉注意的AttentionNet,基于强化学习的算法。

基于区域的分类:

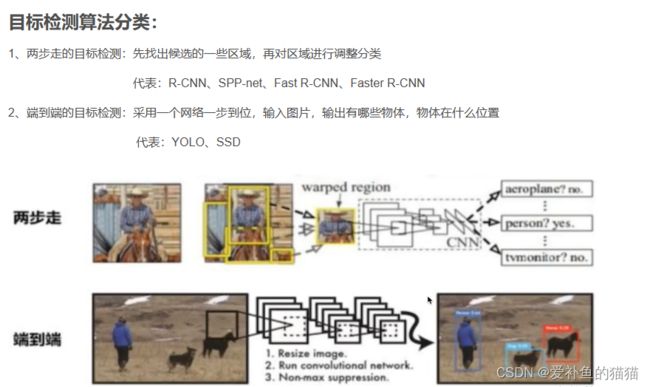

参考连接:https://blog.csdn.net/dfced/article/details/105005563
二、Anchor锚
在图片中以一定的步长选取一定的锚点。以每个中心点为框的中心画多个具有固定高度和宽度的框在图片中以一定的步长选取锚点。以每个中心点为框的中心设计多个具有固定高度和宽度的框,并对于每一个面积的框,衍生出三种不同长宽比的新的框
滑动窗口
传统识别算法,一个比较简单暴力的方法就是滑窗,我们使用不同大小、不同长宽比的候选框在整幅图像上进行穷尽式的滑窗(从左到右,从上到下),然后提取窗口内的特征(例如Haar、LBP、Hog等特征),再送入分类器(SVM、Adaboost等)判断该窗口内包含的是否为人脸。这种方法简单易理解,但是这类方法受限于手动设计的特征(大小比例人工设置),召回率和准确率通常不是很高。
滑动窗口技术。采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了。然而,这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的
Anchor
在深度学习时代,大名鼎鼎的RCNN和Fast RCNN依旧依赖滑窗来产生候选框,也就是Selective Search算法,该算法优化了候选框的生成策略,但仍旧会产生大量的候选框,导致即使Fast RCNN算法,在GPU上的速度也只有三、四帧每秒。直到Faster RCNN的出现,提出了RPN网络,使用RPN直接预测出候选框的位置。RPN网络一个最重要的概念就是anchor,启发了后面的SSD和YOLOv2等算法,虽然SSD算法称之为default box,也有算法叫做prior box,其实都是同一个概念,他们都是anchor的别称。
设置
在训练的时候,需要anchor的大小和长宽比与待检测的物体尺度基本一致,才可能让anchor与物体的IoU大于阈值,成为正样本,否则,可能anchor为正样本的数目特别少,就会导致漏检很多。anchor只有跟你要检测的物体的大小和长宽比更贴近,才能让模型的效果更好。
参考连接:https://zhuanlan.zhihu.com/p/112574936
常用的Anchor Box定义
Faster R-CNN 定义三组纵横比ratio = [0.5,1,2]和三种尺度scale = [8,16,32],可以组合处9种不同的形状和大小的边框。
YOLO V2 V3 则不是使用预设的纵横比和尺度的组合,而是使用k-means聚类的方法,从训练集中学习得到不同的Anchor
SSD 固定设置了5种不同的纵横比ratio=[1,2,3,1/2,1/3],由于使用了多尺度的特征,对于每种尺度只有一个固定的scale
三、anchor-based
一类是two-stage,two-stage检测算法将检测问题划分为两个阶段,首先产生候选区域(region proposals),然后对候选区域分类(一般还需要对位置精修),这一类的典型代表是R-CNN, Fast R-CNN, Faster R-CNN,Mask R-CNN家族。他们识别错误率低,漏识别率也较低,但速度较慢,不能满足实时检测场景。
另一类方式称为one-stage检测算法,其不需要region proposal阶段,直接产生物体的类别概率和位置坐标值,经过单次检测即可直接得到最终的检测结果,因此有着更快的检测速度,比较典型的算法如YOLO,SSD,YOLOv2,YOLOv3,Retina-Net德等。
速度快慢总结
one-stage网络生成的ancor框只是一个逻辑结构,或者只是一个数据块,只需要对这个数据块进行分类和回归就可以,不会像two-stage网络那样,生成的 ancor框会映射到feature map的区域(rcnn除外),然后将该区域重新输入到全连接层进行分类和回归,每个ancor映射的区域都要进行这样的分类和回归,所以它非常耗时。
1、one-stage
1.模型发展
YOLOv1(CVPR16)->SSD(ECCV16)->YOLOv2(CVPR17)->RetinaNet(ICCV17)->YOLOv3(18)->RefineDet(CVPR18)->RFB-Net(ECCV18)
2、two-stage
1.模型发展
RCNN(2013)->SPP-Net(ECCV14)->Fast-RCNN(ICCV15)->Faster-RCNN(NIPS15)->R-FCN(NIPS16)->FPN(CVPR17)->Mask-RCNN(ICCV17)->Cascade-RCNN(CVPR18)
四、anchor-free
1.模型发展
(DenseBox->)YOLOv1(2016)->CornerNet(18)->FoveaBox(19)->CenterNet:Objects as Points(19)->CenterNet(19)->FCOS(19)->Center and Scale Prediction(19)-> SAPD(20)
五、YOLO系列
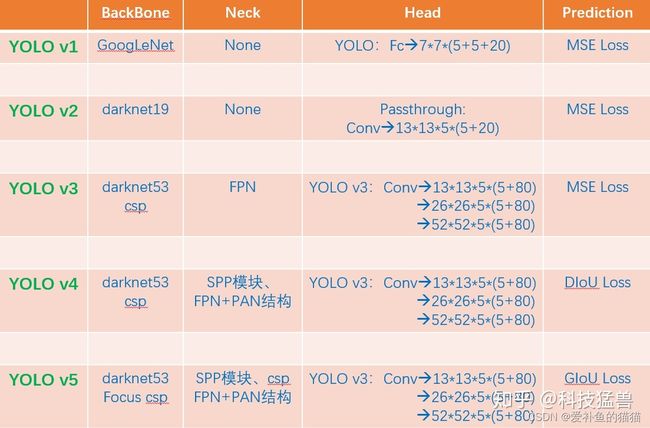
yolov1—yolov7差异:参考https://zhuanlan.zhihu.com/p/539932517
名词:convx(convince)卷积层 FC全连接层 cell(单元格)
V1
有全连接层,只能输入固定大小图片,格子最多只预测出一个物体
7x7*30 7x7(多少格,也就是步长) 30(两种大小框,20个类别)
缺点:重叠、长宽比固定、小物体
框数量:2
缺点:
输入尺寸固定:由于输出层为全连接层,因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率。其它分辨率需要缩放成此固定分辨率;
占比小的目标检测效果不好:虽然每个格子可以预测 2 个 bounding box,但是最终只选择只选择 IOU 最高的bbox作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
SDD
相比Yolo,SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层之后做检测。其实采用卷积直接做检测只是SSD相比Yolo的其中一个不同点,另外还有两个重要的改变,一是SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;二是SSD采用了不同尺度和长宽比的先验框。Yolo算法缺点是难以检测小目标,而且定位不准,但是这几点重要改进使得SSD在一定程度上克服这些缺点。
名词:darknet到底是一个类似于TensorFlow、PyTorch的框架,还是一个类似于AlexNet、VGG的模型?yolo是模型;darkent是框架。
v2
提高map:batch normalization(归一化)、舍去dropout、没FC、darkent、k-means聚类提取先验框、passthrough层(感受视野融合前面层特征)、约束预测边框的位置(预测框中心点偏移)
框数量:5
批归一化(BN):有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性,并且每个batch分别进行归一化的时候,起到了一定的正则化效果(YOLO2不再使用dropout),从而能够获得更好的收敛速度和收敛效果。每个卷积层之后包含一个批量归一化层和一个Leaky ReLU,加入这两个部分的目的是为了防止过拟合。
先验框:YOLO1并没有采用先验框,并且每个grid只预测两个bounding box
真实、先验、预测框
真实框,Ground truth box, 是人工标注的位置,存放在标注文件中
锚框,先设定好锚框的大小和形状,再以图像上某一个点为中心画出矩形框。
先验框,在同一位置生成不同形状和大小的多个锚框
预测框,Prediction box, 是由目标检测模型计算输出的框,微调先验框的长宽比
v3
多scale(不同大小)、 FPN多尺度预测(特征金字塔融合下采样)、resnet残差网络、没有池化和全连接、分类器不在使用Softmax,分类损失采用binary cross-entropy loss
框数量:9
cross-entropy loss:Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。Softmax可被独立的多个logistic分类器替代,且准确率不会下降。
多scale (多尺度)图像预测将图片进行不同尺度的缩放,得到图像金字塔,然后对每层图片提取不同尺度的特征,得到特征图。最后对每个尺度的特征都进行单独的预测。特点:不同尺度的特征都可以包含很丰富的语义信息,精度高 ,但 速度慢。
v4
数据增强(亮度,对比度,色调,缩放,剪切,翻转,旋转,CutMix和Mosaic数据增强)、dropblock与标签平滑(去除一些特征点连接)、ciou(预选框)、nms(去除一些预选框)、sppnet(所有特征层的叠加)、cspnet(改进resnet)、sam(注意力机制,权重矩阵)、FPN+PAN(上下采样)、激活函数(采用mish)
输入端:采用Mosaic数据增强;
Backbone:采用了CSPDarknet53、Mish激活函数、Dropblock等方式;
Neck:采用了SPP(按照DarknetAB的设定)、FPN+PAN结构;
输出端:采用CIOU_Loss、DIOU_Nms操作。
v5
(1)输入端:Mosaic数据增强、自适应锚框计算
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构(v4一样)
(4)Prediction:GIOU_Loss
V5四种网络
Yolov5代码中的四种网络都是以yaml的形式来呈现,而且四个文件的内容基本上都是一样的,只有最上方的depth_multiple和width_multiple两个参数不同。既csp和Focus的深度和宽度不同。
参考连接:
https://juejin.cn/post/7072723771156594701
https://blog.csdn.net/nan355655600/article/details/107852353


yolovx
① 输入端:Strong augmentation数据增强
② BackBone主干网络:主干网络没有什么变化,还是Darknet53。
③ Neck:没有什么变化,Yolov3 baseline的Neck层还是FPN结构。
④ Prediction:Decoupled Head、End-to-End YOLO(改进为无NMS)、Anchor-free(输出参数量)、Multi positives、SimOTA求解(标签分配)
(1)Decoupled head(解耦头)
YOLO系列自YOLOv3开始就没有大幅度更改过检测头相关的内容,而解耦头的设计已经在目标检测和目标分类的网络中被验证有效。解耦头有着分类任务和定位任务两个分支,而采用不同的分支进行运算,有利于效果的提升。由于多分支的加入,会导致网络的计算复杂度增高,YOLOX所提出的方案是先使用1×1的卷积进行降维,来加快运算速度和减小模型大小。
(2)anchor free[3]
YOLOv3,4,5都是使用anchor base的方法来提取候选框,而YOLOX中将原有的3个anchor候选框缩减至1个,即直接由每个location对box的4个参数进行预测。将每个对象的中心位置所在的location视为正样本,并且将每个对象分配到不同的FPN层中,使得每个对象只有一个location进行预测工作,这样的修改同样是减少了GFLOPs并加快了推理速度。
(3)multi positives[3]
如果每个对象只有一个location进行预测,会导致正负样本不均衡,且会抑制一些高质量的预测,YOLOX借鉴了FCOS的中心采样策略,将对象中心附近的location也纳入正样本的计算之中,此时每个对象就有了多个正样本的分布。
(4)SimOTA[4]
在旷视自己的OTA算法中,他们将标签分配任务看作网络内部的最优传输任务,即多个目标与多个候选框的相互匹配。不同于OTA的是,SimOTA将原本使用的Sinkhorn-Knopp算法替换,使用动态top-k策略去计算最优传输的问题。这样的方法不仅减少了模型的训练时间,而且避免了Sinkhorn-Knopp算法中的额外求解器超参数。
1.Focus层原理
Focus层原理和PassThrough层很类似。它采用切片操作把高分辨率的图片(特征图)拆分成多个低分辨率的图片/特征图,即隔列采样+拼接。原理图如下:

原始的640 × 640 × 3的图像输入Focus结构,采用切片(slice)操作,先变成320 × 320 × 12的特征图,拼接(Concat)后,再经过一次卷积(CBL(后期改为SiLU,即为CBS))操作,最终变成320 × 320 × 64的特征图。Focus层将w-h平面上的信息转换到通道维度,再通过3*3卷积的方式提取不同特征。采用这种方式可以减少下采样带来的信息损失 。
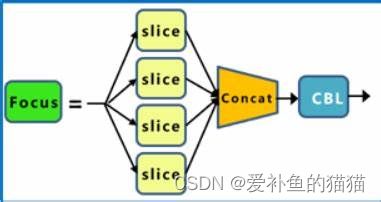
作用
Focus层将w-h平面上的信息转换到通道维度,再通过3*3卷积的方式提取不同特征。采用这种方式可以减少下采样带来的信息损失 。Focus的作用无非是使图片在下采样的过程中,不带来信息丢失的情况下,将W、H的信息集中到通道
上,再使用3 × 3的卷积对其进行特征提取,使得特征提取得更加的充分。虽然增加了一点点的计算量,
但是为后续的特征提取保留了更完整的图片下采样信息。
2.CSP结构
目的
解决以往工作中需要大量推理计算的问题。
做法 CSPNet和PRN都是一个思想,将feature map拆成两个部分,一部分进行卷积操作,另一部分和上
一部分卷积操作的结果进行concate。
要点
① 分类问题中,使用CSPNet可以降低计算量,但是准确率提升很小
② 在目标检测问题中,使用CSPNet作为Backbone带来的提升比较大,可以有效增强CNN的学习能
力,同时也降低了计算量。增强CNN的学习能力,能够在轻量化的同时保持准确性。降低计算瓶颈,降低内存成本。
3.SPP结构(金字塔池化)
SPP是空间金字塔池化的简称,其先通过一个标准卷积模块将输入通道减半,然后分别做kernel-size为5,9,13的maxpooling(对于不同的核大小,padding是自适应的)对三次最大池化的结果与未进行池化操作的数据进行concat,最终合并后channel数是原来的2倍。
作用:SPP是由微软研究院的何凯明大神提出,主要为了解决两个问题:
- 有效避免了对图像区域剪裁、缩放操作导致的图像失真等问题;
- 解决了卷积神经网络对图像重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
(1)对于不同尺寸的CNN_Pre输出能够输出固定大小的向量。
(2)可以提取不同尺寸的空间特征信息,可以提升模型对于空间布局和物体变性的鲁棒性。
(3)可以避免将图片resize、crop成固定大小输入模型的弊端。
4、FPN+PAN结构(多尺度特征融合的方式)
通过 FPN 和 PAN 对图像进行多尺度特征融合,其中上层特征图因为网络层数更深,包含的橙子语义信息也就更强,而下层特征因为经过的卷积层数较少,橙子的位置信息损失就更少,FPN 结构通过自顶向下进行上采样,使得底层特征图包含更强的图像强语义信息;PAN 结构自底向上进行下采样,使顶层特征包含图像位置信息,两个特征最后进行融合,使不同尺寸的特征图都包含图像语义信息和图像特征信息,保证了对不同尺寸的图片的准确预测。

FPN主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体检测的性能。通过高层特征进行上采样和低层特征进行自顶向下的连接,而且每一层都会进行预测。FPN(Feature Pyramid Network)算法同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,效果甚佳。
V6
YOLOv6是由美团推出的,所做的主要工作是为了更加适应GPU设备,将2021年的RepVGG结构引入到了YOLO。YOLOv6检测算法的思路类似YOLOv5(backbone+neck)+YOLOX(head)。
主要改动:
1.骨干网络由CSPDarknet换为了EfficientRep
2.Neck是基于Rep和PAN构建了Rep-PAN
3.检测头部分模仿YOLOX,进行了解耦操作,并进行了少许优化。
网络结构:
骨干网络: EfficientRep
Neck: FPN+RepPAN
检测头:类似YOLOX
tricks1:引入RepVGG
YOLOv6对YOLO系列的backbone和neck进行了全新的设计,参考RepVGG[5]网络设计了RepBlock来替代CSPDarknet53模块。YOLOv6中所有的激活函数都为ReLU,从而提升网络训练的速度,且使用transpose反卷积进行上采样,并将neck中的CSP模块也使用RepBlock进行替代(Rep-PAN),但仍然保留FPN-PAN的结构,这样的修改使得其训练的收敛速度更快,推理的速度也更快。
在head中仍然沿用了YOLOX的解耦头设计,不过并未对各个检测头进行降维的操作,而是选择减少网络的深度来减少各个部分的内存占用。此外,在anchor free的锚框分配策略中也沿用了SimOTA等方法来提升训练速度。参考了SloU边界框回归损失函数来监督网络的学习,通过引入了所需回归之间的向量角度,重新定义了距离损失,有效降低了回归的自由度,加快网络收敛,进一步提升了回归精度。
参考连接:https://blog.csdn.net/Pariya_Official/article/details/125794741
V7
概述:ELAN设计思想、MP降维组件、Rep结构的思考、正负样本匹配策略、辅助训练头
1、高效的聚合网络:E-ELAN采用expand、shuffle、merge cardinality结构,实现在不破坏原始梯度路径的情况下,提高网络的学习能力。
2、模型缩放:类似于YOLOv5、Scale YOLOv4、YOLOX,一般是对depth、width或者module scale进行缩放,实现扩大或缩小baseline的目的。
3、模型结构重参化:RepConv。用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均。一种是对不同迭代次数下模型权重进行加权平均。
4、引导标签分配策略:coarse-to-fine。将负责最终输出的Head为lead Head,将用于辅助训练的Head称为auxiliary Head
V8
- Backbone:
骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数。属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了 - Head:
Head部分较yolov5而言有两大改进:1)换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离 2)同时也从 Anchor-Based 换成了 Anchor-Free - Loss :
1.YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner正负样本匹配方式。2)并引入了 Distribution Focal Loss(DFL) - Train:训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
参考连接:
https://blog.csdn.net/qq_40716944/article/details/128609569
https://blog.csdn.net/zyw2002/article/details/128732494
C2f模块
我们不着急,先看一下C3模块的结构图,然后再对比与C2f的具体的区别。针对C3模块,其主要是借助CSPNet提取分流的思想,同时结合残差结构的思想,设计了所谓的C3 Block,这里的CSP主分支梯度模块为BottleNeck模块,也就是所谓的残差模块。同时堆叠的个数由参数n来进行控制,也就是说不同规模的模型,n的值是有变化的。
其实这里的梯度流主分支,可以是任何之前你学习过的模块,比如,美团提出的YOLOv6中就是用来重参模块RepVGGBlock来替换BottleNeck Block来作为主要的梯度流分支,而百度提出的PP-YOLOE则是使用了RepResNet-Block来替换BottleNeck Block来作为主要的梯度流分支。而YOLOv7则是使用了ELAN Block来替换BottleNeck Block来作为主要的梯度流分支。
六、R-CNN系列
各类方法主要的创新点
- 1.RCNN解决的是用CNN网络对每个proposal region进行特征提取
- 2.SPP-RCNN实现了对整个图片进行特征提取,然后再在feature map寻找特定的proposal region, 并提出了特征金字塔池化来解决不同大小proposal region输出到固定尺寸的问题。
- 3.Fast-RCNN实现了卷积网络的权重共享,使用RoI pooling来保持多尺度输入(SPP-RCNN), 并去除了SVM分类器,改用softmax实现了端到端。
- 4.Faster-RCNN提出了RPN, 用卷积层提取proposal region,实现了端到端训练
参考连接:https://blog.csdn.net/qq_34826149/article/details/109465069
1、R-CNN
选择性搜索候选框----正负样本提取(IOU筛选即nms)------抠图CNN提取特征----SVM分类(极大值抑制进一步筛选)-----边框回归(将筛选出来的进行调整)
候选区域提出阶段(Proposal):采用selective-search方法,从一幅图像生成1K~2K个候选区域;
特征提取:对每个候选区域,使用CNN进行特征提取;
分类:每个候选区域的特征放入分类器SVM,得到该候选区域的分类结果;
回归:候选区域的特征放入回归器,得到bbox的修正量。
R-CNN的简要步骤如下:
- 输入测试图像。
- 候选区域:利用选择性搜索Selective Search算法在图像中从下到上提取2000个左右的可能包含物体的候选区域Region Proposal。
- 特征提取:因为取出的区域大小各自不同,所以需要将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征。
- 分类:将每个Region Proposal提取到的CNN特征输入到SVM进行分类。
- 回归:候选区域的特征放入回归器,得到bbox的修正量。

1)Selective Search 选择性搜索
遵循简单即是美的原则,只负责快速地生成可能是物体的区域,而不做具体的检测。选择搜索算法的思路很简单,就是输入一个图像,然后通过一些图像分割算法将其分割为很多个小块,这些小块组成一个集合R。在R中对所有相邻的块求相似度,得到新的集合S。对集合S中相似度最高的两个块R1, R2进行合并可以得到新的块R_new,加入R中,同时删除S中所有与R1或R2有关的相似度,然后计算R_new和所有相邻区域的相似度,加入S。如此重复迭代计算,直到集合S中不再包含任何元素即可。
2)Region Proposal候选区域
使用了Selective Search1方法从一张图像生成约2000-3000个候选区域。基本思路如下: - 使用一种过分割手段,将图像分割成小区域,查看现有小区域,合并可能性最高的两个区域。重复直到整张图像合并成一个区域位置,输出所有曾经存在过的区域,候选区域生成和后续步骤相对独立,实际可以使用任意算法进行。
- 合并规则
优先合并以下四种区域:
颜色(颜色直方图)相近的
纹理(梯度直方图)相近的
合并后总面积小的
合并后,总面积在其BBOX中所占比例大的
3)crop&warp
CNN一般都含有卷积部分和全连接部分,其中,卷积层不需要固定尺寸的图像,而全连接层是需要固定大小的输入。所以当全连接层面对各种尺寸的输入数据时,就需要对输入数据进行crop(crop就是从一个大图扣出网络输入大小的patch,比如227×227),或warp(把一个边界框bounding box(红框)的内容resize成227×227)等一系列操作以统一图片的尺寸大小,比如224224(ImageNet)、3232(LenNet)、96*96等。

所以才如你在上文中看到的,在R-CNN中,“因为取出的区域大小各自不同,所以需要将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN”。
4)SVM分类
单个SVM实现的是二分类,分类器阶段由多个SVM组合而成。比如总共有20种不同的物体(加1种背景),那么分类阶段必须要有21个SVM:第1个SVM的输出是该候选区域属于分类1的概率;第2个SVM的输出是该候选区域属于分类2的概率;……;第21个SVM的输出是该候选区域属于背景的概率。
参考连接:
https://blog.csdn.net/weixin_41510260/article/details/99189794
https://blog.csdn.net/qq_32172681/article/details/100090365
瓶颈:
每一个region proposal 都需要resize成固定大小。
对每个region proposals 都做一次CNN计算,计算量太大。
每个region proposal经过CNN网络提取出来的特征得保留下来,用于训练SVM分类,占用过多的物理内存,训练分成多个阶段 region select + CNN特征提取 + SVM分类 + 边框回归。无法实现端到端训练。
2、Spp-Net
针对R-CNN瓶颈:每一个region proposal 都需要resize成固定大小;对每个region proposals 都做一次CNN计算,计算量太大。SPP-Net相对于R-CNN主要做了两点改进:1. 对整张图进行一次特征提取 2. 引用了空间金字塔

-
1.结合空间金字塔方法实现CNNs的多尺度输入。
SPP Net的第一个贡献就是在最后一个卷积层后,接入了金字塔池化层,保证传到下一层全连接层的输入固定。换句话说,在普通的CNN机构中,输入图像的尺寸往往是固定的(比如224*224像素),输出则是一个固定维数的向量。SPP Net在普通的CNN结构中加入了ROI池化层(ROI Pooling),使得网络的输入图像可以是任意尺寸的,输出则不变,同样是一个固定维数的向量。简言之,CNN原本只能固定输入、固定输出,CNN加上SSP之后,便能任意输入、固定输出。 -
2.只对原图提取一次卷积特征
在R-CNN中,每个候选框先resize到统一大小,然后分别作为CNN的输入,这样是很低效的。而SPP Net根据这个缺点做了优化:只对原图进行一次卷积计算,便得到整张图的卷积特征feature map,然后找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层,完成特征提取工作。
如此这般,R-CNN要对每个区域计算卷积,而SPPNet只需要计算一次卷积,从而节省了大量的计算时间,比R-CNN有一百倍左右的提速。
瓶颈:
缺点还是在于分类器使用SVM, 不能端到端训练,且需要磁盘存储大量的特征。
分阶段训练,训练过程复杂。
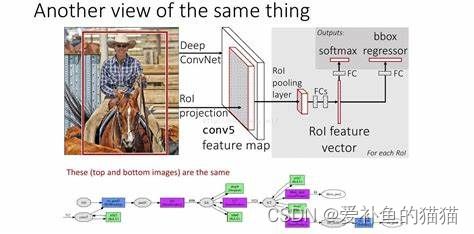
3、Fast-RCNN
Fast R-CNN的网络将图像和region proposal作为输入,经过卷积层得到feature map后,经过特定RoI pooling后输出固定大小的特征图,然后输入到全连接层,通过全连接层后的特征用SVM进行分类。
与R-CNN不同:
- 特征提取:对整张图片进行特征提取得到相应的特征图
- RoI Pooling:参照spp使用RoI pooling来保持多尺度的输入。利用特征池化(RoI Pooling) 的方法进行特征尺度变换, 这种方法可以有任意大小图片的输入, 使得训练过程更加灵活、 准确。
- 多任务损失:用同一个网络,同时进行分类和回归任务。 将分类与回归网络放到一起训练, 并且为了避免SVM分类器带来的单独训练与速度慢的缺点, 使用了Softmax函数进行分类。
瓶颈:
在region proposal模块还是用selective search, 并且只能在CPU中运行这个算法,这个阶段还可以改进。
4、Faster-RCNN
Faster RCNN是Fast RCNN的修改版本,二者之间的主要区别在于,Fast RCNN使用选择性搜索来生成感兴趣区域,而Faster RCNN使用“区域提议网络”,即RPN。RPN将图像特征映射作为输入,并生成一组提议对象,每个对象提议都以对象分数作为输出。
- 第一阶段生成图片中待检测物体的anchor矩形框(对背景和待检测物体进行二分类)
- 第二阶段对anchor框内待检测物体进行分类。
Faster RCNN可以看作 RPN+Fast RCNN,其中RPN使用CNN来生成候选区域,并且RPN网络可以认为是一个使用了注意力机制的候选区域选择器。
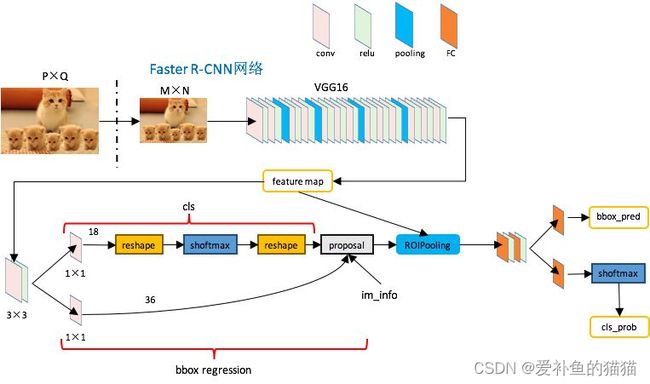
RPN
不同于耗时极长的选择性搜索,RPN网络使用神经网络进行候选框提取,这是Faster-RCNN的精髓。
将传统的候选区域生成方法使用卷积运算来代替,使用卷积来生成候选区域使得RPN具有一定注意力机制,效果与前几代的RCNN相比,提升明显。在生成候选区域的时候会生成anchors,然后内部通过判别函数判断anchors属于前景还是后景,然后通过边框回归来进行第一次调整anchors获取准确的候选区域。
首先,RPN网络接受任意尺寸大小的feat map作为输入,然后会生成9K个anchor,并且RPN有两个输出,一个是anchor的类别信息,也就是该anchor是背景还是前景(只要有要识别的物品就属于前景),还有一个输出是该anchor的位置偏移信息(如果该anchor是背景,则该输出不重要)。
瓶颈:商用的话速度依然是问题,需要模型轻量化或者one-stage算法
5、Mask-RCNN
简单直观:整个Mask R-CNN算法的思路很简单,就是在原始Faster-rcnn算法的基础上面增加了FCN来产生对应的MASK分支。即Faster-rcnn + FCN,更细致的是 RPN + ROIAlign + Fast-rcnn + FCN。
高速和高准确率:为了实现这个目的,作者选用了经典的目标检测算法Faster-rcnn和经典的语义分割算法FCN。Faster-rcnn可以既快又准的完成目标检测的功能;FCN可以精准的完成语义分割的功能,这两个算法都是对应领域中的经典之作。Mask R-CNN比Faster-rcnn复杂,但是最终仍然可以达到5fps的速度,这和原始的Faster-rcnn的速度相当。由于发现了ROI Pooling中所存在的像素偏差问题,提出了对应的ROIAlign策略,加上FCN精准的像素MASK,使得其可以获得高准确率。
易于使用:整个Mask R-CNN算法非常的灵活,可以用来完成多种任务,包括目标分类、目标检测、语义分割、实例分割、人体姿态识别等多个任务,这将其易于使用的特点展现的淋漓尽致。我很少见到有哪个算法有这么好的扩展性和易用性,值得我们学习和借鉴。除此之外,我们可以更换不同的backbone architecture和Head Architecture来获得不同性能的结果。
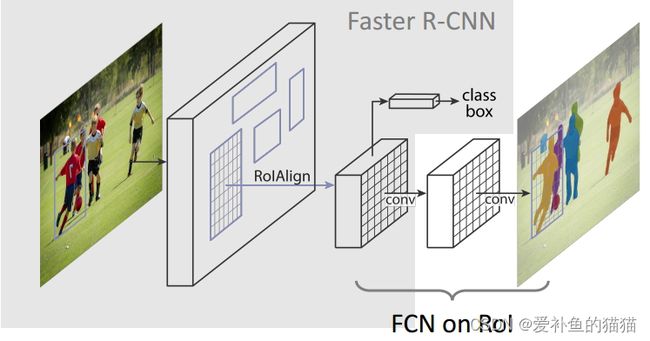
- Mask R-CNN算法步骤
首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
然后,将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
接着,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
接着,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)。 - Mask R-CNN架构分解
在这里,我将Mask R-CNN分解为如下的3个模块,Faster-rcnn、ROIAlign和FCN。然后分别对这3个模块进行讲解,这也是该算法的核心。 - Faster-rcnn
- FCN
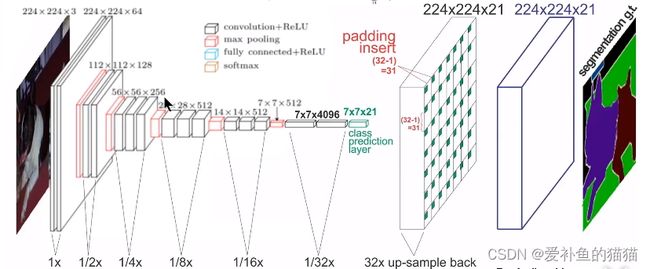
FCN算法是一个经典的语义分割算法,可以对图片中的目标进行准确的分割。其总体架构如上图所示,它是一个端到端的网络,主要的模快包括卷积和去卷积,即先对图像进行卷积和池化,使其feature map的大小不断减小;然后进行反卷积操作,即进行插值操作,不断的增大其feature map,最后对每一个像素值进行分类。从而实现对输入图像的准确分割。具体的细节请参考该链接。
参考连接:https://blog.csdn.net/WZZ18191171661/article/details/79453780