超快速结构感知深度巷道检测(Ultra Fast Structure-aware Deep Lane Detection )
超快速结构感知深度巷道检测 ? 秦泽群、王焕宇、李曦??[0000−0003−3023−1662] 计算机科学与技术学院, 浙江大学,中国杭州 [email protected], {huanyuhello,xilizju}@zju.edu.cn
中文 (简体)翻译。
抽象。现代方法主要将车道检测视为像素分割问题,难以解决具有挑战性的场景和速度问题。受人类感知的启发,在严重遮挡和极端照明条件下对车道的识别主要基于上下文和全局信息。在这种观察的激励下,我们提出了一种新颖,简单但有效的公式,旨在极快的速度和具有挑战性的场景。具体而言,我们将车道检测过程视为使用全局特征的基于行的选择问题。在基于行的选择的帮助下,我们的配方可以显着降低计算成本。在全局特征上使用较大的接受字段,我们还可以处理具有挑战性的场景。此外,基于该公式,我们还提出了一种结构损失,以明确地对车道的结构进行建模。在两个车道检测基准数据集上的广泛实验表明,我们的方法可以在速度和精度方面实现最先进的性能。轻量级版本甚至可以在相同的分辨率下达到每秒300多帧,这比以前最先进的方法至少快4倍。我们的代码可在 https://github.com/cfzd/Ultra-Fast-Lane-Detection 获得。
中文 (简体)翻译。
介绍 车道检测在计算机视觉领域有着悠久的研究历史,是一个基本问题,具有广泛的应用[8](例如ADAS和自动驾驶)。对于车道检测,主流方法有两种,分别是传统的图像处理方法[2,28,1]和深度分割方法[11,22,21]。最近,深度分割方法由于具有很强的代表性和学习能力,在该领域取得了巨大的成功。仍然有一些重要和具有挑战性的问题有待解决。
中文 (简体)翻译。
作为自动驾驶的基本组成部分,车道检测算法被大量执行。这需要极低的车道检测计算成本。 此外,目前的自动驾驶解决方案通常配备多个 ? 本研究由教育部重点科技创新研究项目、浙江省自然科学基金(LR19F020004)、百度人工智能前沿技术联合研究计划、浙江大学曹克普高新技术发展基金资助。??通讯作者。

中文 (简体)翻译。
图例.1. 车道检测中的困难图示。不同的车道用不同的颜色标记。大多数具有挑战性的场景在各种照明条件下都会被严重遮挡或扭曲,导致很少或根本没有车道的视觉线索可用于车道检测。 相机输入,这通常要求每个相机输入的计算成本更低。通过这种方式,更快的管道对于车道检测至关重要。为此,提出SAD [9]通过自我蒸馏(self-distilling)来解决这个问题。由于基于分割的SAD的密集预测特性,该方法的计算成本很高。
中文 (简体)翻译。
车道检测的另一个问题称为无视觉线索,如图1所示。具有严重遮挡和极端照明条件的挑战性场景对应于车道检测的另一个关键问题。在这种情况下,车道检测迫切需要对车道进行更高层次的语义分析。深度分割方法自然比传统的图像处理方法具有更强的语义表示能力,并成为主流。此外,SCNN [22]通过提出相邻像素之间的消息传递机制来解决这个问题,这显着提高了深度分割方法的性能。由于密集的像素级通信,这种消息传递需要更多的计算成本。
中文 (简体)翻译。
此外,还存在一种现象,即车道表示为分段的二元要素,而不是线或曲线。虽然深度分割方法在车道检测领域占主导地位,但这种表示使得这些方法难以明确地利用车道的刚性和平滑度等先验信息。
中文 (简体)翻译。
基于上述动机,我们提出了一种新颖的车道检测公式,旨在以极快的速度为目标,解决无视觉线索问题。同时,基于中文 (简体)翻译。 在所提出的公式中,我们提出了一个结构损失,以明确利用车道的先验信息。具体而言,我们的公式建议使用全局特征在图像的预定义行中选择车道的位置,而不是基于局部感受场分割泳道的每个像素,从而显着降低计算成本。位置选择的图示如图2所示。
中文 (简体)翻译。
对于无视觉线索问题,我们的方法也可以获得良好的性能,因为我们的公式是根据全局特征进行行选择的过程。借助全局特征,我们的方法具有整个图像的接受域。与基于有限感受野sd的分割相比,可以学习和利用来自不同位置的视觉线索和信息。通过这种方式,

中文 (简体)翻译。
图例.2. 在左右车道上选择的图示。在右侧部分,详细显示了行的选择。行锚点是预定义的行位置,我们的公式定义为对每个行锚点进行水平选择。在图像的右侧,引入了一个背景网格单元格,以指示此行中没有通道。
中文 (简体)翻译。
我们的新公式可以同时解决速度和无视觉线索问题。此外,根据建议的公式,车道表示为不同行上的选定位置,而不是分割地图。因此,我们可以通过优化选定位置的关系(即结构损失)来直接利用车道的特性,如刚性和平滑度。这项工作的贡献可以总结为三个部分:
中文 (简体)翻译。 中文 (简体)翻译。
我们提出了一种新颖,简单,但有效的车道检测公式,旨在以极快的速度并解决无视觉线索问题。与深度分割方法相比,我们的方法是选择车道的位置而不是分割每个像素,并且工作在不同的维度上,这是非常快的。此外,我们的方法使用全局特征进行预测,其感受野比分割公式更大。通过这种方式,也可以解决无视觉线索问题。
中文 (简体)翻译。
基于所提出的公式,我们提出了一种结构损失,该结构损失明确地利用了车道的先验信息。据我们所知,这是在深度车道检测方法中明确优化此类信息的第一次尝试。
所提方法在具有挑战性的CULane数据集上实现了精度和速度方面的最新性能。我们方法的轻量级版本甚至可以达到300 +FPS,并具有可比的性能相同的分辨率,比以前最先进的方法至少快4倍。
中文 (简体)翻译。
2.相关工作中文 (简体)翻译。
传统方法 传统方法通常基于视觉信息解决车道检测问题。这些方法的主要思想是通过图像处理(如HSI颜色模型[25]和边缘提取算法[29,27])来利用视觉线索。当视觉信息不够强大时,跟踪是另一种流行的后处理解决方案[28,13]。除跟踪外,马尔可夫和条件随机场[16]也用作后处理方法。随着机器学习的发展,提出了一些采用模板匹配、支持向量机等算法的方法[15,6,20]。 深度学习模型 随着深度学习的发展,一些基于深度神经网络的方法[12,11]显示出在车道检测中的优越性。这些方法通常通过将问题视为语义分割任务来使用相同的公式。例如,VPGNet [17]提出了一个多任务网络,由消失点引导,用于车道和道路标记检测。为了更有效地使用视觉信息,SCNN [22]在分割模块中使用了特殊的卷积运算。它通过处理切片特征并将它们逐个添加在一起来聚合来自不同维度的信息,这类似于递归神经网络(RNN)。一些作品试图探索实时应用的轻量级方法。自注意蒸馏(SAD)[9]就是其中之一。它应用了注意力蒸馏机制,其中高层和低层的注意力分别被视为教师和学生。
中文 (简体)翻译。
除了主流的分割公式外,还提出了其他公式,如顺序预测和聚类。在[18]中,采用长短期记忆(LSTM)网络来处理车道的长线结构。使用相同的原理,Fast-Draw [24]预测每个车道点的车道方向,并按顺序将其绘制出来。在[10]中,车道检测问题被视为对二进制段的聚类。[30]中提出的方法也使用聚类方法来检测车道。与以往作品的二维视图不同,提出一种三维公式[4]中的车道检测方法,以解决不平坦地面的问题。
中文 (简体)翻译。
3.
方法 在本节中,我们将描述我们方法的细节,包括新配方和车道结构损失。此外,还描述了一种用于高级语义和低级视觉信息的特征聚合方法。
3.1中文 (简体)翻译。 车道检测的新配方
中文 (简体)翻译。
如介绍部分所述,快速和无视觉线索问题对于车道检测非常重要。因此,如何有效地处理这些问题是良好性能的关键。在本节中,我们通过解决速度和无视觉线索问题来展示我们公式的推导。为了更好地说明,表1显示了下面使用的一些表示法。
中文 (简体)翻译。
为了应对上述问题,我们提出将车道检测制定为基于全局图像特征的基于行的选择方法。换句话说,我们的方法是使用全局特征在每个预定义的行上选择正确的车道位置。在我们的公式中,车道表示为预定义行处的一系列水平位置,即行锚点。为了表示位置,第一步是网格化。在每个行锚点上,位置被划分为多个单元格。通过这种方式,通道的检测可以被描述为在预定义的行锚点上选择某些单元格,如图3(a)所示。
假设最大通道数为 C,行锚点数为 h,网格化单元格数为 w。假设 X 是全局图像特征,fij 是
Table 1. Notation.
| Variable |
Type |
Definition |
| H |
Scalar |
Height of image |
| W |
Scalar |
Width of image |
| h |
Scalar |
Number of row anchors |
| Scalar |
Number of gridding cells |
|
| Scalar |
Number of lanes |
|
| Tensor |
The global features of image |
|
| Function |
The classifier for selecting lane locations |
|
| Tensor |
Group prediction |
|
| T ∈RC×h×(w+1) |
Tensor |
Group target |
| Prob∈RC×h×w |
Tensor |
Probability of each location |
| Loc∈RC×h |
Matrix |
Locations of lanes |
中文 (简体)翻译。
分类器用于选择第i条车道上的车道位置,第j行锚点。那么车道的预测可以写成:
Pi,j,: = fij(X), s.t. i ∈ [1,C],j ∈ [1,h],
中文 (简体)翻译。
其中 Pi,j,: 是 (w +1) 维向量表示为第 i 个通道,第 j 行锚点选择 (w + 1) 网格化单元格的概率。假设 Ti,j,: 是正确位置的单热标签。然后,我们配方的优化对应于:
C h
Lcls = XXLCE(Pi,j,:,Ti,j,:), (2)
i=1 j=1
中文 (简体)翻译。
其中LCE是交叉熵损失。我们使用额外的维度来指示没有车道,因此我们的公式由(w + 1)维而不是w维分类组成。
中文 (简体)翻译。
从等式 1 中,我们可以看到,我们的方法根据全局特征预测每个行锚点上所有位置的概率分布。因此,可以根据概率分布选择正确的位置。
中文 (简体)翻译。
配方如何实现快速我们的配方和分割之间的差异如图3所示。可以看出,我们的配方比常用的分割要简单得多。假设图像大小为 H × W。通常,预定义的行锚点的数量和网格大小远远小于图像的大小,也就是说,并且。这样,原始的分割公式需要进行(C + 1)维的H×W分类,而我们的公式只需要解决(w + 1)维的C×h分类问题。通过这种方式,计算规模可以大大降低,因为我们的公式的计算成本是C×h×(w+ 1),而用于分割的计算成本是H ×W ×(C +1)。例如,使用 CULane 数据集 [22] 的常见设置,我们方法的理想计算成本为 1.7 × 104 次计算,而用于分割的计算成本为 1.15×106 次计算。计算成本大大降低,我们的配方可以达到极快的速度。

中文 (简体)翻译。
(a) 我们的提法 (b) 细分
中文 (简体)翻译。
图例.3. 我们的配方和常规分割的图示。我们的公式是选择行上的位置(网格),而分割是对每个像素进行分类。用于分类的尺寸也不同,标记为红色。该公式显著降低了计算成本。此外,拟议的配方使用全球中文 (简体)翻译。 特征作为输入,其感受场大于分割,从而解决了无视觉线索问题
中文 (简体)翻译。
公式如何处理无视觉线索问题 为了处理非视觉线索问题,利用来自其他位置的信息很重要,因为非视觉线索意味着目标位置没有信息。例如,车道被汽车遮挡,但我们仍可以通过来自其他车道、道路形状甚至汽车方向的信息来定位车道。通过这种方式,利用来自其他位置的信息是解决无视觉线索问题的关键,如图1所示。
中文 (简体)翻译。
从感受野的角度来看,我们的配方具有整个图像的接受场,这比分割方法要大得多。来自图像其他位置的上下文信息和消息可用于解决无视觉线索问题。从学习的角度来看,也可以使用基于我们公式的结构损失来学习车道形状和方向等先验信息,如第3.2节所示。通过这种方式,可以在我们的公式中处理无视觉线索问题。
中文 (简体)翻译。
另一个显著的好处是,这种公式以基于行的方式对车道位置进行建模,这使我们有机会明确地建立不同行之间的关系。由低级像素建模和车道高层次长线结构造成的原始语义差距是可以弥合的。
中文 (简体)翻译。
3.2 车道结构损耗
中文 (简体)翻译。
除分类损失外,我们还提出了两个损失函数,旨在对车道点的位置关系进行建模。通过这种方式,可以鼓励学习结构信息。
中文 (简体)翻译。
第一个是从车道是连续的这一事实中推导出来的,也就是说,相邻行锚点中的车道点应该彼此靠近。在我们的公式中,泳道(the location of the lane)的位置由分类向量表示。因此,连续属性是通过约束分类向量在相邻行锚点上的分布来实现的。这样,相似性损失函数可以是:
C h−1
Lsim = XXkPi,j,: − Pi,j+1,:k1 , (3)
i=1 j=1
中文 (简体)翻译。
其中 Pi,j,: 是第 j 行锚点上的预测,k·k1 表示 L1 范数。
中文 (简体)翻译。
另一个结构损失函数侧重于车道的形状。一般来说,大多数车道都是直的。即使对于弯道,大部分仍然是直的,中文 (简体)翻译。 由于透视效果。在这项工作中,我们使用二阶差分方程来约束车道的形状,对于直线情况,该形状为零。
要考虑形状,需要计算每行锚点上的车道位置。直观的想法是通过找到最大响应峰从分类预测中获取位置。对于任何车道索引 i 和行锚点索引 j,位置 Loci,j 可以表示为:
Loci,j = argmax Pi,j,k , s.t. k ∈ [1,w] (4)
k
其中 k 是表示位置索引的整数。应该注意的是,我们不在后台网格单元格中计数,并且位置索引k的范围仅从1到w,而不是w + 1
中文 (简体)翻译。
但是,argmax 函数不可微分,不能与进一步的约束一起使用。此外,在分类公式中,类没有明显的顺序,并且很难在不同的行锚点之间建立关系。为了解决这个问题,我们建议使用预测的期望作为位置的近似值。我们使用 softmax 函数来获取不同位置的概率:
Probi,j,: = softmax(Pi,j,1:w),
中文 (简体)翻译。
其中 Pi,j,1:w 是 w 维向量,Probi,j,: 表示每个位置的概率。出于与等式 4 相同的原因,不包括背景网格单元格,计算范围仅为 1 到 w。然后,位置的期望可以写为:
w
Loci,j = Xk · Probi,j,k (6)
k=1
中文 (简体)翻译。
其中 Probi,j,k 是第 i 个通道、第 j 行锚点和第 k 个位置的概率。这种本地化方法的好处是双重的。第一个是期望函数是可微分的。另一个是此操作使用离散随机变量恢复连续位置。
根据等式 6,二阶差分约束可以写为:
C h−2
Lshp = XXk(Loci,j − Loci,j+1)
i=1 j=1 (7)
− (Loci,j+1 − Loci,j+2)k1,
中文 (简体)翻译。
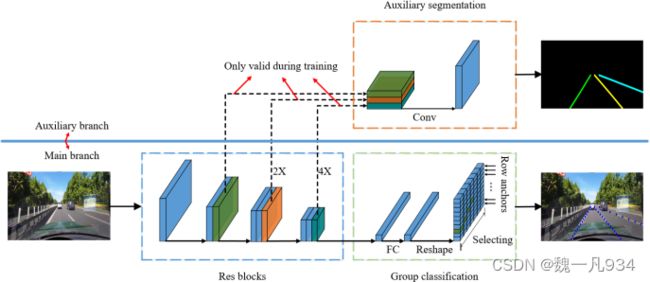
图例.4. 整体架构。辅助分支显示在上部,仅在训练时有效。特征提取器显示在蓝色框中。基于分类的预测和辅助分割任务分别在绿色和橙色框中进行了说明。组分类在每个行锚点上执行。
中文 (简体)翻译。
其中 Loci,j 是第 i 个车道上的位置,即第 j 行锚点。我们之所以使用二阶差而不是一阶差,是因为在大多数情况下,一阶差值不为零。因此,网络需要额外的参数来学习车道位置的一阶差的分布。此外,二阶差值的约束比一阶差值的约束相对弱,因此当车道不直时,影响较小。最后,整体结构损失可以是:
Lstr = Lsim + λLshp, (8)
中文 (简体)翻译。
其中λ是损耗系数。
中文 (简体)翻译。
3.3 特征聚合
中文 (简体)翻译。
在第3.2节中,损耗设计主要关注车道的内部关系。在本节中,我们提出了一种对全局上下文和局部特征执行的辅助特征聚合方法。提出一种利用多尺度特征的辅助分割任务对局部特征进行建模。我们使用交叉熵作为辅助分割损失。通过这种方式,我们方法的整体损失可以写为:
Ltotal = Lcls + αLstr + βLseg, (9)
其中Lseg是分割损失,α和β是损失系数。整体架构如图4所示
中文 (简体)翻译。
需要注意的是,我们的方法在训练阶段只使用辅助分割任务,在测试阶段会去掉。这样,即使我们添加了额外的分割任务,我们方法的运行速度也不会受到影响。它与没有辅助分段任务的网络相同。
4. 中文 (简体)翻译。
实验 在本节中,我们通过广泛的实验证明了我们方法的有效性。以下各节主要集中在三个方面:1)实验设置。2)我们方法的消融研究。3) 两个主要车道检测数据集的结果。
Table 2. Datasets description
| Dataset #Frame Train Validation |
Test Resolution #Lane #Scenarios |
environment |
||
| TuSimple 6,408 3,268 358 |
2,782 1280×720 |
≤5 |
1 |
highway |
| CULane 133,235 88,880 9,675 |
34,680 1640×590 |
≤4 |
9 |
urban and highway |
4.1 Experimental setting
中文 (简体)翻译。
数据。为了评估我们的方法,我们对两个广泛使用的基准数据集进行了实验:TuSimple Lane检测基准[26]和CULane数据集[22]。在高速公路的稳定光照条件下采集 TuSimple 数据集。CULane数据集由城市区域的法线、人群、曲线、眩光、夜景、无线、阴影、箭头等9种不同场景组成。有关数据集的详细信息,请参见表 2。 评估指标。两个数据集的官方评估指标不同。对于 TuSimple 数据集,主要的评估指标是准确性。精度的计算公式为:
, (10),
其中 Cclip 是正确预测的车道点数,Sclip 是每个剪辑中地面实线的总数。至于 CULane 的评估指标,每个通道都被视为一条 30 像素宽的线。然后计算地面实况和预测之间的交集并集 (IoU)。IoUs 大于 0.5 的预测被视为真阳性。F1 度量值作为评估指标,表述如下:
, (11)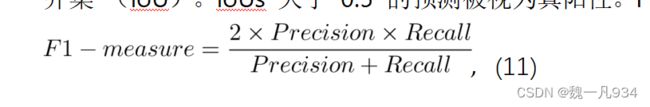
where is the true positive, FP is the false positive, and FN is the false negative.

中文 (简体)翻译。
其中是真阳性,FP 是假阳性,FN 是假阴性。
中文 (简体)翻译。
实现详细信息。对于这两个数据集,我们使用数据集定义的行锚点。具体而言,Tusimple 数据集的行锚点(其中图像高度为 720)的范围为 160 到 710,步长为 10。CULane 数据集的对应值范围为 260 到 530,步长与 Tusimple 相同。CULane 数据集的图像高度为 540。格网像元的数量在 Tusimple 数据集上设置为 100,在 CULane 数据集上设置为 150。对 Tusimple 数据集的相应消融研究可以在第 4.2 节中看到。
中文 (简体)翻译。
在优化过程中,图像大小按照[22]调整为288×800。我们使用 Adam [14] 来训练我们的模型,该模型使用 4e-4 初始化的余弦衰变学习速率策略 [19]。方程 8 和 9 中的损耗系数 λ、α 和 β 均设置为 1。批量大小设置为 32,对于 TuSimple 数据集,训练周期的总数设置为 100,对于 CULane 数据集,训练周期的总数设置为 50。我们之所以选择如此大量的纪元(epochs),是因为我们保持结构的数据增强需要长时间的学习。我们的数据增强方法的细节将在下文中讨论。所有型号均使用pytorch [23]和nvidia GTX 1080Ti GPU进行训练和测试。
中文 (简体)翻译。
数据扩充。由于通道的固有结构,基于分类的网络很容易过度拟合训练集,并在验证集上显示较差的性能。为了防止这种现象并获得泛化能力,利用了一种由旋转,垂直和水平偏移组成的增强方法。此外,为了保留车道结构,车道被延伸到图像的边界。增强的结果可以在图5中看到。

中文 (简体)翻译。
(a) 原始分析 (b) 增强结果
中文 (简体)翻译。
图例.5. 增强的演示。右图中的车道被扩展以保持车道结构,该结构用红色椭圆标记。
中文 (简体)翻译。
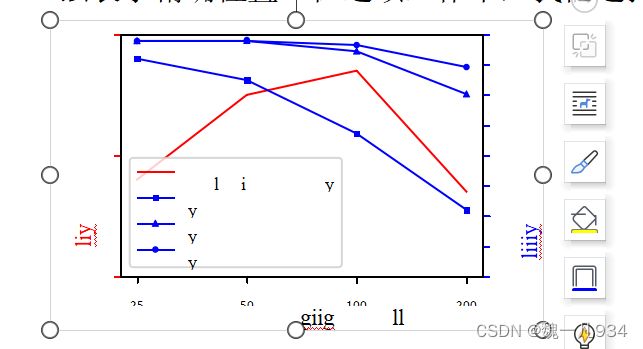
4.2 消融研究 在本节中,我们通过几项消融研究验证了我们的方法。实验均采用与第4.1节相同的设置进行。 网格化单元格数量的影响。如第 3.1 节所述,我们使用网格化和选择来建立车道结构信息与基于分类的配方之间的关系。通过这种方式,我们进一步尝试使用不同数量的网格化单元来尝试我们的方法,以证明对我们方法的影响。我们使用列中的25,50,100和200个单元格来划分图像。结果如图所示。6.
中文 (简体)翻译。
随着网格化单元格数量的增加,我们可以看到top1,top2和top3分类精度都逐渐下降。这是因为更多的网格化单元需要更细粒度和更难的分类。但是,评估准确性并非严格单调。尽管网格化像元数量越少意味着分类精度越高,但定位误差会更大,因为格网像元太大而无法表示精确位置。在这项工作中,我们选择 100 作为元简单数据集上的网格化单元数。
中文 (简体)翻译。
图例.6. 在 Tusimple 数据集上不同数量的网格化单元格下的性能。评估准确性是指在 Tusimple 基准测试中建议的评估指标,而分类准确性是标准精度。Top1、top2 和 top3 精度分别是预测距离和地面实况小于 1、2 和 3 时的指标。在此图中,top1 精度相当于标准分类精度。
中文 (简体)翻译。
本地化方法的有效性。由于我们的方法将泳道检测表述为群分类问题,因此一个自然的问题是分类和回归之间的区别是什么。为了以回归方式进行测试,我们将图 4 中的组分类头替换为类似的回归头。我们使用四个实验设置,分别是REG,REG Norm,CLS和CLS Exp.CLS表示基于分类的方法,而REG表示基于回归的方法。CLS和CLS Exp之间的区别在于它们的定位方法不同,分别是等式4和等式6。REG规范设置是REG的变体,它使学习目标规范化。
中文 (简体)翻译。
表 3.在 Tusimple 数据集上进行分类和回归的比较。REG 和 REG 范数是基于回归的方法,而 REG 范数的基真值量表是归一化的。CLS 表示使用等式 4 中的定位方法进行标准分类,CLS Exp 表示具有等式 6 的分类。
| Type |
REG |
REG Norm |
CLS |
CLS Exp |
| Accuracy |
71.59 |
67.24 |
95.77 |
95.87 |
中文 (简体)翻译。
结果示于表3中。我们可以看到,与标准方法相比,具有期望的分类可以获得更好的性能。这个结果也证明了等式6中的分析,即基于期望的定位比argmax运算更精确。同时,基于分类的方法可以始终如一地优于基于回归的方法。
中文 (简体)翻译。
拟议模块的有效性。为了验证所提出模块的有效性,我们进行了定性和定量实验。
首先,我们展示模块的定量结果。如表4所示,实验是在相同的训练设置和不同的模块组合下进行的。
从表4中可以看出,与细分配方相比,新配方获得了显著的性能改进。此外,两个车道结构 表 4.使用Resnet-34骨干网在Tumsimple基准测试上对所提出的模块进行实验。基线代表常规分割公式。
| Baseline |
New formulation |
Structural loss |
Feature aggregation |
Accuracy |
| X |
92.84 |
|||
| X |
95.64(+2.80) |
|||
| X |
X |
95.96(+3.12) |
||
| X |
X |
95.98(+3.14) |
||
| X |
X |
X |
96.06(+3.22) |
中文 (简体)翻译。
损耗和特征聚合可以提高性能,证明了所提模块的有效性。
中文 (简体)翻译。
(a) 无相似性损失 (b) 无相似性损失
中文 (简体)翻译。
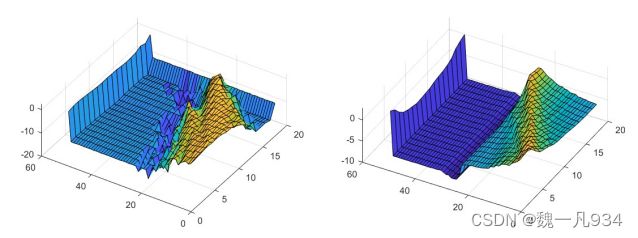
图例.7. 相似性损失的定性比较。图中显示了同一通道的组分类的预测分布。图(a)显示了没有相似性损失的分布的可视化,而图(b)显示了具有相似性损失的对应物。
中文 (简体)翻译。
其次,我们在方程3中说明了车道相似性损失的有效性。结果如图7所示。我们可以看到,相似性损失使分类预测更加平滑,从而获得了更好的性能。
中文 (简体)翻译。
4.3 结果 在本节中,我们将展示两个泳道检测数据集的结果,这两个数据集是 Tusimple 泳道检测基准和 CULane 数据集。在这些实验中,Resnet-18和Resnet-34 [7]被用作我们的骨干模型。
对于 Tusimple 巷道检测基准测试,使用七种方法进行比较,包括 Res18-Seg [3]、Res34-Seg [3]、LaneNet [21]、EL-GAN [5]、SCNN [22] 和 SAD [9]。在此实验中比较了元简单函数的评估精度和运行时。我们方法的运行时记录在 100 次运行的平均时间中。
结果示于表5中。
从表5中,我们可以看到我们的方法实现了与最先进的方法相当的性能,而我们的方法可以非常快地运行。我们的方法和SCNN之间最大的运行时差距是,我们的方法可以推断出速度快41.7倍。即使与第二快的网络SAD相比,我们的方法仍然快2倍以上。
表 5.与 TuSimple 测试集上的其他方法进行比较。运行时倍数的计算基于最慢方法 SCNN。
| Method |
Accuracy Runtime(ms) Multiple |
||
| Res18-Seg [3] |
92.69 |
25.3 |
5.3x |
| Res34-Seg [3] |
92.84 |
50.5 |
2.6x |
| LaneNet [21] |
96.38 |
19.0 |
7.0x |
| EL-GAN [5] |
96.39 |
>100 |
<1.3x |
| SCNN [22] |
96.53 |
133.5 |
1.0x |
| SAD [9] |
96.64 |
13.4 |
10.0x |
| Res34-Ours |
96.06 |
5.9 |
22.6x |
| Res18-Ours |
95.87 |
3.2 |
41.7x |
中文 (简体)翻译。
我们应该注意到的另一个有趣的现象是,当骨干网络与普通分段相同时,我们的方法既能获得更好的性能,又能获得更快的速度。这一现象表明,我们的方法优于普通分割,验证了我们制剂的有效性。
对于 CULane 数据集,使用四种方法(包括 Seg[3]、SCNN [22]、FastDraw [24] 和 SAD [9])进行比较。比较 F1 度量值和运行时。我们方法的运行时也记录在 100 次运行的平均时间中。结果可以在表6中看到。
表 6.IoU 阈值 = 0.5 的 CULane 测试集上的 F1 测量和运行时比较。对于十字路口,仅显示误报。越少越好。“-”表示结果不可用。
| Category |
Res50-Seg[3] SCNN[22] FD-50[24] Res34-SAD SAD[9] Res18-Ours Res34-Ours |
||||||
| Normal |
87.4 |
90.6 |
85.9 |
89.9 |
90.1 |
87.7 |
90.7 |
| Crowded |
64.1 |
69.7 |
63.6 |
68.5 |
68.8 |
66.0 |
70.2 |
| Night |
60.6 |
66.1 |
57.8 |
64.6 |
66.0 |
62.1 |
66.7 |
| No-line |
38.1 |
43.4 |
40.6 |
42.2 |
41.6 |
40.2 |
44.4 |
| Shadow |
60.7 |
66.9 |
59.9 |
67.7 |
65.9 |
62.8 |
69.3 |
| Arrow |
79.0 |
84.1 |
79.4 |
83.8 |
84.0 |
81.0 |
85.7 |
| Dazzlelight |
54.1 |
58.5 |
57.0 |
59.9 |
60.2 |
58.4 |
59.5 |
| Curve |
59.8 |
64.4 |
65.2 |
66.0 |
65.7 |
57.9 |
69.5 |
| Crossroad |
2505 |
1990 |
7013 |
1960 |
1998 |
1743 |
2037 |
| Total |
66.7 |
71.6 |
- |
70.7 |
70.8 |
68.4 |
72.3 |
| Runtime(ms) |
- |
133.5 |
- |
50.5 |
13.4 |
3.1 |
5.7 |
| Multiple |
- |
1.0x |
- |
2.6x |
10.0x |
43.0x |
23.4x |
| FPS |
- |
7.5 |
- |
19.8 |
74.6 |
322.5 |
175.4 |

Image with annotation Prediction Label
中文 (简体)翻译。
图例.8. 在 Tusimple 和 CULane 数据集上进行可视化。前两行是 Tusimple 数据集上的结果,其余行是 CULane 数据集上的结果。从左到右,结果是图像,预测和标签。在图像中,预测标记为蓝色,地面实况标记为红色。由于我们的方法仅在预定义的行锚点上进行预测,因此图像和标签在垂直方向上的刻度并不相同。
中文 (简体)翻译。
在表6中观察到,我们的方法在精度和速度方面都实现了最佳性能。它证明了所提出的公式和结构损失在这些具有挑战性的场景中的有效性,因为我们的方法可以利用全局和结构信息来解决无视觉线索和速度问题。我们配方的最快型号达到322.5 FPS,分辨率为288×800,与其他比较方法相同。
中文 (简体)翻译。
我们的方法在 Tusimple 和 CULane 数据集上的可视化如图 8 所示。我们可以看到我们的方法在各种条件下表现良好。
中文 (简体)翻译。
5. 结论 在本文中,我们提出了一种具有结构损耗的新公式,并实现了显着的速度和准确性。该公式将车道检测视为使用全局特征进行基于行的选择问题。通过这种方式,可以解决速度和无视觉线索的问题。此外,还提出了用于车道先验信息显式建模的结构损耗。我们的配方的有效性和结构损失通过定性和定量实验都得到了充分的证明。特别是,我们使用Resnet-34骨干网的模型可以实现最先进的准确性和速度。我们方法的轻量级Resnet-18版本甚至可以在相同的分辨率下以可比的性能实现322.5 FPS。