vector模拟实现
vector的模拟实现
- 一. vector的模拟实现
-
- 1.0 与string的区别
- 1.1 实现内容
- 实现方法
- 二. vector模拟中重点讲解内容(坑)
-
- 2.1 erase的使用问题
- 2.2 resize的特殊写法
- 2.3 operator =
- 2.4 reserve
- 三. 整体代码
一. vector的模拟实现
我们知道:
在STL中,我们上次学了string
但其实准确来说string并不算是STL中的成员。
因为string出现的比STL要早
所以string的设计相比于STL中其他的容器要麻烦的多。
但是今天带来的vector可以说是是完完全全的STL中的容器。
这里可能还有人不知道容器是什么东西。
容器准确来说是用来处理数据的
就比如我们之前学习进程的时候,在管理文件的时候
文件:文件内容+文件属性
本质都是数据,所以我们能看到很多的链表和顺序表的成分在。
而之后我们要学习的算法
作用则是:处理数据
存储数据+处理数据可以说是组成了程序
1.0 与string的区别
为什么这里要讲string和vector的区别?
因为string和vector一样实际上就是一个顺序表
但是还是有很大的区别:
而vector通过模板的功能来实现,能存储多种类型的数据
string相当于将char类型的数据拎出来,为它拓宽了很多接口的同时,为了兼容C语言,保留了很多字符串的特殊点。
所以:
i. string只能存储char类型
ii. string保留了末尾是’\0’的成分
而vector则是全新的对象,不需要兼容C语言。
i. 所以vector能存储各种类型
ii. 同时末尾不用添加’\0’
1.1 实现内容
我们模拟实现vector的目的:
是为了更好的了解vector来帮助我们更好的使用和学习。
所以这里就挑几个比较重要的接口进行实现
做到一个比较基础的vector。
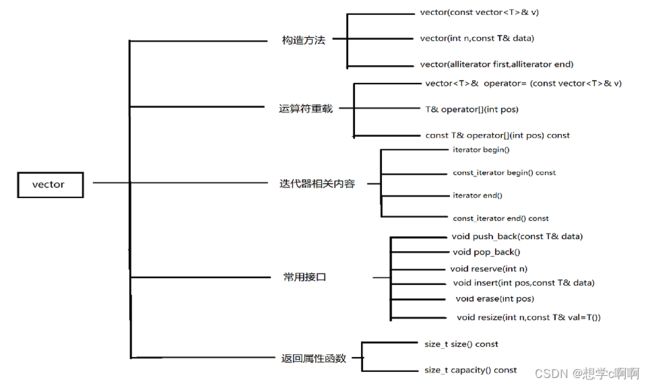
这个就是大致的实现内容。
因为这个和string的实现实在是太像了,所以就选几个比较重点的讲
其他未讲到的会后面会放在整体代码中。
实现方法
这里不同于string的capacity和data实现方法
这里vector用的是三个指针成员变量的实现方法,但是实际上没有相差多少,用string的同样可以实现。
class vector
{
public:
private:
iterator _start;
iterator _finish;
iterator _eofstorage;
};
这里的:
_start:就是开辟数组的开始指针
_finishi:就是开辟数组最后一个元素的指针
_eofstorage:数组开辟空间的空间的最后位置的地址
这个实现方法区别其实不重要,用string的实现方法依旧可以实现。
二. vector模拟中重点讲解内容(坑)
2.1 erase的使用问题
erase
这个函数的功能是:
删除指定位置的元素。
int main()
{
std::vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
std::vector<int>::iterator begin = v1.begin();
v1.erase(begin);
for (auto i : v1)
{
std::cout << i;
}
}

具体就是这样使用。
接下来就来演示erase的一个非常经典的错误用法。
这里用的是STL中的vector,因为官方的使用中,这个问题也是十分常见的。
#include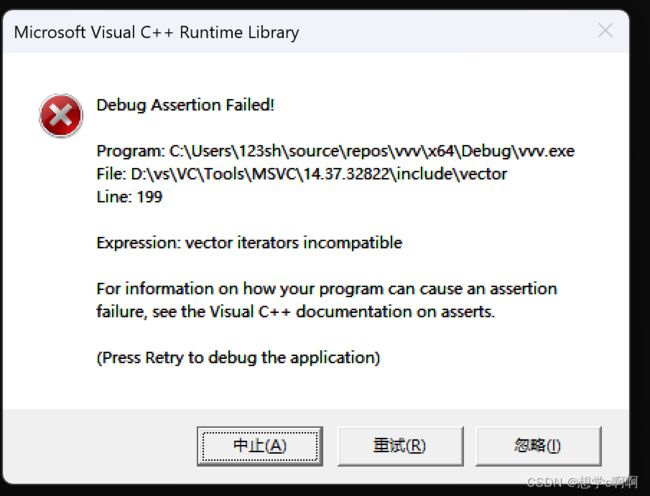
这里能发现程序崩掉了。
这是我们发现
这里我们把begin迭代器指定的内容删除后
然后继续使用了begin迭代器。
但是按照我们的道理来讲
这个begin的指向的方向应该还是老方向。
erase之后,各类元素会向前面补位,begin应该指向新补位的2了。
按道理来说这个begin应该是可以继续使用的。
因为在vs中,这个问题算是迭代器失效
在使用迭代器对象进行insert与erase之后。
vs会默认该迭代器无法继续使用
我们知道STL不同编译器下是不同的,因为官方给了一个STL的最基本的设定,具体的修改和实现方法是取决于公司自己
所以在linux中,可能就不会判断这个迭代器失效的效果。
这里我们来试一下。
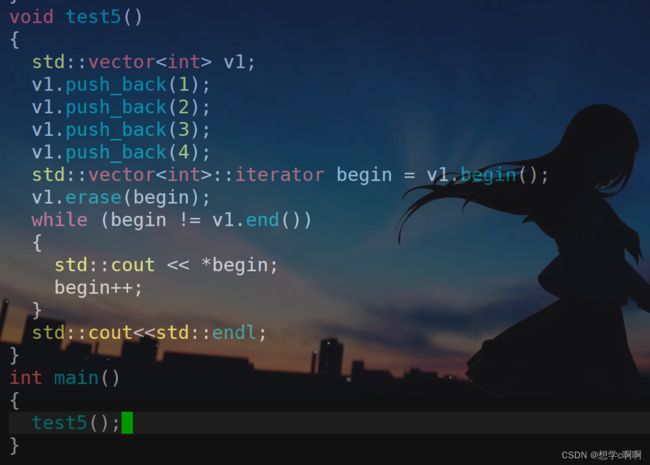
还是同样的代码

这里能发现在linux中能进行访问。
但是这样的话为什么vs要禁止用户使用呢?
这里就要讲下允许使用这个的坏处了。
这里我们在linux中用这个测试一道题:
删除数组中的所有偶数
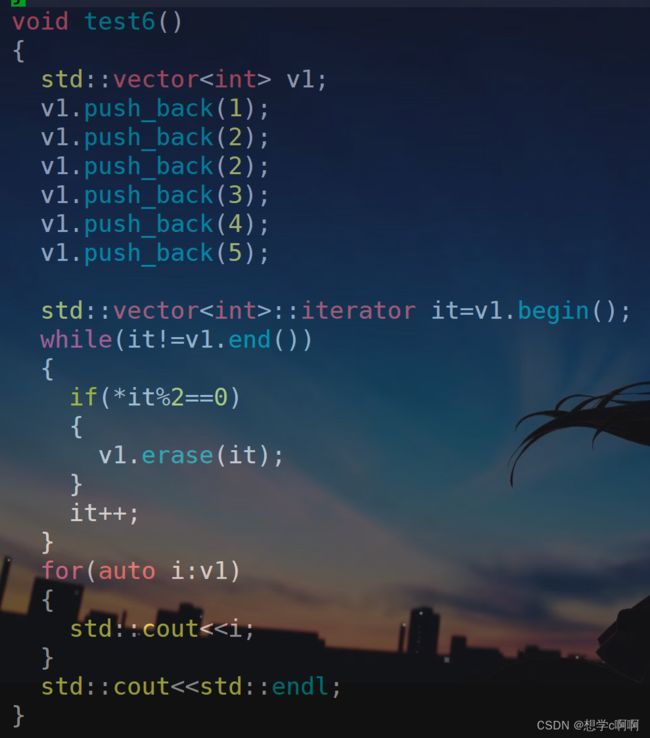

这里结果我们发现少删除了一个2。
这里其实仔细观察一下我们就能发现问题所在。
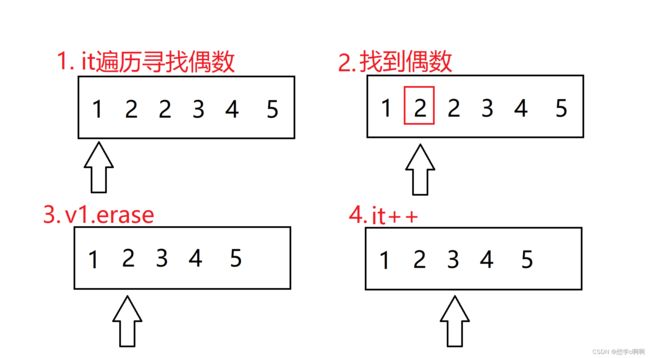
这里就能发现it删除完,还会进行一次++,会略过连续的偶数。
这里掠过算是比较ok一点的错误了,但是如果想象一下最后一位是偶数,这样的话会直接掠过数组的最后一位,直接向后面遍历,非常容易导致越界访问。
这里其实要解决也是很简单。
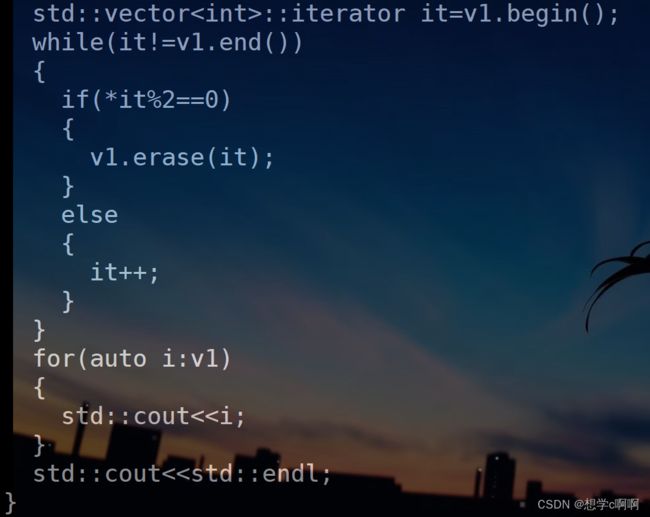
只要在其中加一个else就可以了。

但是这样虽然能解决问题,但是大大限制了它的平台可移植性。
所以这个情况也是开发者所在意的。
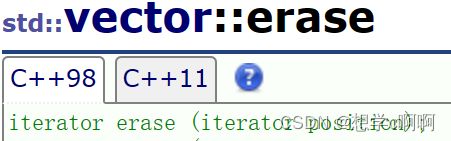
这里能发现erase有一个iterator 的返回值。
这个iterator是用来返回下一个位置的值的。
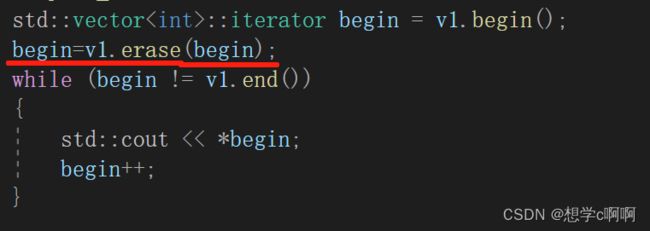
所以这里需要去接受一下返回值,才能继续用这个begin变量。
2.2 resize的特殊写法
void resize(int n, const T& val = T())
{
if (n < size())
{
_finish = _start + n;
}
else
{
reserve(n);
while (_finish != _start + n)
{
*_finish = val;
_finish++;
}
}
}
这个是resize的函数实现。
我们知道:
reserve:开辟空间,插入数据时不扩容
resize:开空间+初始化为指定值
但是resize初始化为指定值的时候,指定值有多种不同的类型。
但是有时候如果用户不输入初始化的值该怎么办?
void resize(int n, const T& val = T())
这个第二个参数,const T& val=T();
这个可以说是一个新写法,这个前面是类型
val=T();是缺省值。
那这个T();
其实就是调用T类型的构造函数的的意思。
那这样我们大致就能明白是什么意思了
如果用户没有给初始化值,那就去调用vector类型T的构造函数
2.3 operator =
这里的operator和string的的一样,要注意深浅拷贝的问题。
所以同样可以用到swap深拷贝函数。
void check_capacity()
{
if (_finish == _eofstorage)
{
if (_start == NULL)
reserve(4);
else
reserve(capacity() * 2);
}
}
2.4 reserve
void reserve(int n)
{
if (n > capacity())
{
int oldsize = capacity();
T* new_vec = new T[n];
if (_start != nullptr)
{
for(int i=0;i<oldsize;i++)
{
new_vec[i]=_start[i];
}
delete _start;
}
_start = new_vec;
_finish = _start + oldsize;
_eofstorage = _start + n;
}
}
这个是完成版的reserve
void reserve(int n)
{
if (n > capacity())
{
int oldsize = capacity();
T* new_vec = new T[n];
if (_start != nullptr)
{
memcpy(new_vec, _start, oldsize*sizeof(T));
delete _start;
}
_start = new_vec;
_finish = _start + oldsize;
_eofstorage = _start + n;
}
}
这个是改版前的reserve函数
这里发现只有一个地方发生了了改变。
if (_start != nullptr)
{
memcpy(new_vec, _start, oldsize*sizeof(T));
delete _start;
}
这里乍一看好像没有什么问题。
但是我们仔细想想,如果vector的类型是一个自定义类型,具有地址成员变量。
那memcpy对new_vec与_start进行改变时,就会这个是浅拷贝,无法进行深拷贝,就会发生严重的问题
所以就改成了
for(int i=0;i<oldsize;i++)
{
new_vec[i]=_start[i];
}
这里使用赋值重载来进行深度拷贝。
就没有这样的问题了
三. 整体代码
#include