三分钟搞懂MySQL5.6优化&索引下推
如果你在面试中,听到MySQL5.6”、“索引优化” 之类的词语,你就要立马get到,这个问的是“索引下推”。
什么是索引下推
索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,它能减少回表查询次数,提高查询效率。
索引下推优化的原理
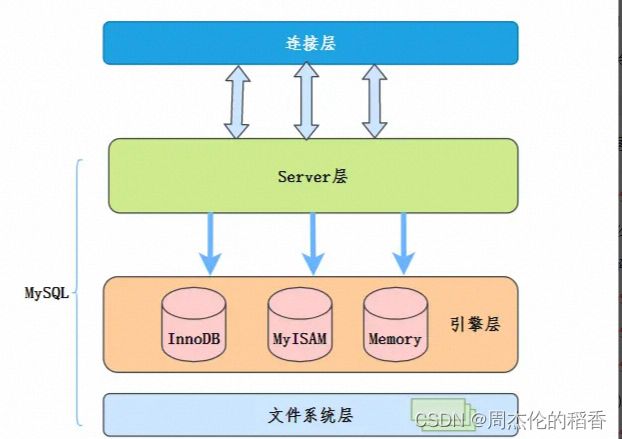
我们先简单了解一下MySQL大概的架构:
如果现在有一个需求:检索出表中名字是张三,而且年龄是10岁的用户。那么,SQL语句是这么写的:
select * from user where name='张三' and age=10;假如你了解索引最左匹配原则,那么就知道这个语句在搜索索引树的时候,只能用张三,找到的第一个满足条件的记录id为1。
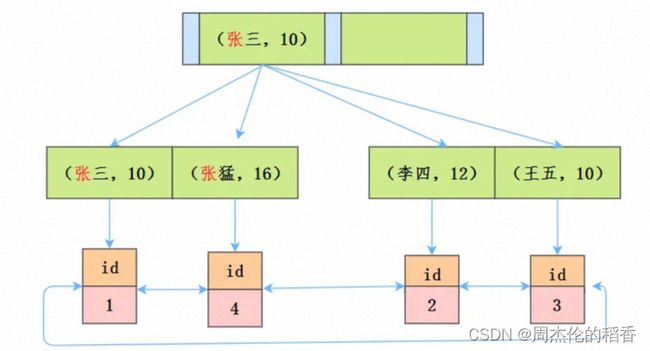
那接下来的步骤是什么呢?
没有使用ICP
在MySQL 5.6之前,存储引擎根据通过联合索引找到name=张三的主键id(1、4),逐一进行回表扫描,去聚簇索引找到完整的行记录,server层再对数据根据age=10进行筛选。
我们看一下示意图:
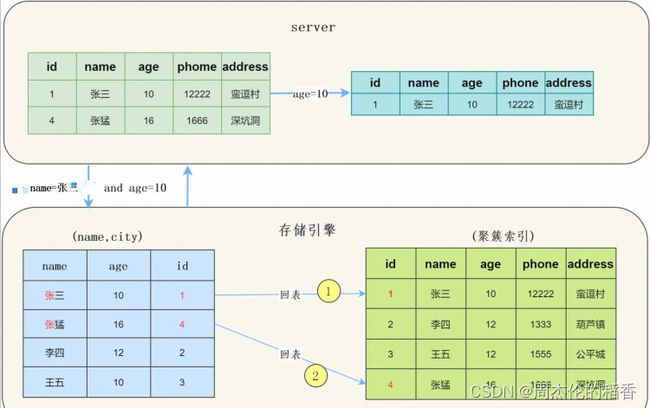
可以看到需要回表两次,把我们联合索引的另一个字段age浪费了。
使用ICP
而MySQL 5.6 以后, 存储引擎根据(name,age)联合索引,找到name=张三,由于联合索引中包含age列,所以存储引擎直接再联合索引里按照age=10过滤。按照过滤后的数据再一一进行回表扫描。
我们看一下示意图:
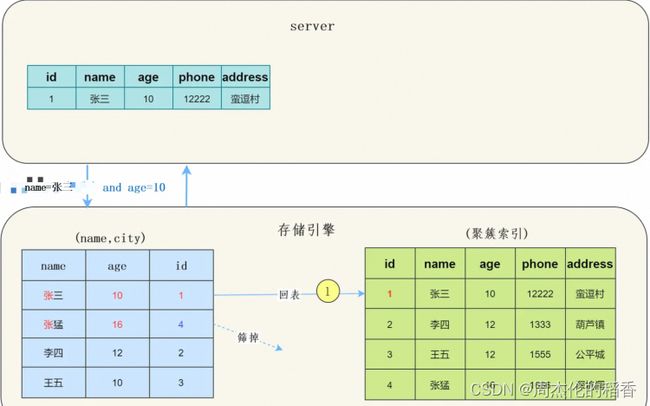
可以看到只回表了一次。
除此之外我们还可以看一下执行计划,看到Extra一列中有Using index condition 这就是用到了索引下推。
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | tuser | NULL | range | na_index | na_index | 102 | NULL | 2 | 25.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+
使用索引下推的前提条件
- 只能用于InnoDB和MyISAM存储引擎及其分区表
- 对于InnoDB存储引擎来说,索引下推只适用于二级索引(也叫辅助索引)
- 只能用于range、 ref、 eq_ref、ref_or_null访问方法;
1.Range(范围访问):
当查询涉及范围、不等于或者某些特定的值时,MySQL可能会使用Range访问方法。典型的情况是在SQL语句中使用了比较运算符(如 >、<、>=、<=)或者 BETWEEN 等操作符,这些操作需要检索一个范围内的值。
SELECT * FROM users WHERE age > 25 AND age < 35;2.Ref(索引查找访问):
当查询通过普通的非唯一索引进行查找时,MySQL可能会使用Ref访问方法。这通常发生在查询条件中包含了被索引列的等值匹配(=)情况,也就是一般的索引查找。
SELECT * FROM users WHERE username = 'john';3.Eq_ref(唯一索引查找):
当查询通过唯一索引进行查找时,MySQL可能会使用Eq_ref访问方法。这种情况通常发生在查询条件中包含了主键或者唯一索引列的等值匹配(=)情况。
SELECT * FROM users WHERE id = 100;4.Ref_or_null(索引查找或者NULL值查找):
当查询条件中包含了对索引列的等值匹配或者 NULL 值匹配时,MySQL可能会使用Ref_or_null访问方法。这种情况通常发生在索引列允许为空(NULL)的情况下。
SELECT * FROM users WHERE username = 'alice' OR username IS NULL;
- 在某些情况下,引用了子查询的条件不能下推
当涉及到子查询的条件下推时,让我们通过一个具体的例子来说明这个概念。
假设我们有两个表:orders(订单表)和 customers(顾客表)。orders表包含了订单信息,其中包括订单号(order_id)、顾客ID(customer_id)和订单金额(amount)等字段;customers表包含了顾客信息,其中包括顾客ID(customer_id)、顾客姓名(customer_name)等字段。
现在,我们想要查询出所有订单金额大于某个特定顾客的平均订单金额的订单。换句话说,我们需要找出那些订单金额高于某个特定顾客平均订单金额的订单。
一种实现这个查询的方式是使用子查询:
SELECT * FROM orders WHERE amount > ( SELECT AVG(amount) FROM order WHERE customer_id = '123' );在这个查询中,子查询 SELECT AVG(amount) FROM orders WHERE customer_id = '123' 用于计算顾客ID为'123'的平均订单金额,然后外部查询根据这个平均金额来筛选出符合条件的订单。
然而,在这种情况下,子查询的条件无法被完全下推到数据存储引擎层执行。因为外部查询引用了子查询的结果,数据库系统需要先计算子查询的结果,然后才能将外部查询的条件应用到子查询的结果上。这可能会导致性能问题,特别是在订单表非常大的情况下。
为了优化这个查询,我们可以重写查询,将子查询的结果作为一个变量引入外部查询,从而避免对子查询的引用。或者,我们也可以考虑使用连接或其他更有效的查询方式来实现相同的逻辑,以减少对子查询的依赖,从而提高查询性能。
当然一些简单的子查询也是可以进行下推的
特别是对于能够被转换成连接或者关联子查询的简单子查询,数据库系统通常能够将其条件下推到数据存储引擎层执行。
例如,考虑以下简单的子查询示例:
SELECT * FROM orders WHERE customer_id IN SELECT customer_id FROM customers WHERE customer_name = 'Alice' );在这个查询中,子查询 SELECT customer_id FROM customers WHERE customer_name = 'Alice' 返回了顾客名为'Alice'的顾客ID列表,外部查询根据这个列表来筛选出对应顾客的订单。
对于这种简单的子查询,数据库系统通常能够将子查询的条件下推到数据存储引擎层执行,以提高查询性能。因为这种情况下,子查询可以被优化成连接操作,使得条件可以在数据存储引擎层执行,而不需要额外的计算和数据传输开销。
总的来说,对于简单的、能够被转换成连接或者关联子查询的子查询,数据库系统通常能够进行下推优化,以提高查询性能。然而,在涉及复杂逻辑或者依赖外部查询条件的子查询时,就可能会遇到条件无法下推的情况,影响查询性能。因此,在实际编写查询语句时,需要考虑查询的复杂度和优化方式,以提高查询性能。
- 引用了存储函数的条件不能下推,因为存储引擎无法调用存储函数。
当涉及存储函数时,我们可以举一个简单的例子来说明。假设我们有一个数据库中包含了订单信息的表 orders,其中包括订单号(order_id)、订单金额(amount)等字段。此外,我们在数据库中创建了一个存储函数 calculate_discount,它接受订单金额作为参数,并返回折扣金额。这个存储函数的逻辑可能是根据订单金额的不同区间来计算不同的折扣金额。
下面是一个简化的示例:
CREATE FUNCTION calculate_discount(amount DECIMAL) RETURNS DECIMAL BEGIN DECLARE discount DECIMAL; IF amount > 100 THEN SET discount = amount * 0.1; -- 10% discount for amount over 100 ELSE SET discount = 0; END IF; RETURN discount; END;在这个例子中,calculate_discount 存储函数接受订单金额作为参数,并根据订单金额的不同情况返回对应的折扣金额。这是一个非常简单的示例,实际的存储函数可能会更复杂,包括更多的逻辑和计算。
现在,假设我们想要查询出折扣金额大于某个特定值的订单,我们可能会编写类似以下的查询:
SELECT * FROM orders WHERE calculate_discount(amount) > 5;在这个查询中,我们在条件中使用了 calculate_discount 存储函数,来筛选出折扣金额大于5的订单。由于存储函数的计算需要在数据库引擎外部进行,数据库系统无法将这个条件下推到数据存储引擎层执行,从而可能影响查询性能。
因此,当涉及到存储函数时,需要注意查询的性能,并考虑是否有其他方式可以重写查询以避免对存储函数的依赖,或者通过其他手段来优化查询性能。
相关系统参数
索引条件下推默认是开启的,可以使用系统参数optimizer_switch来控制器是否开启。
查看默认状态:
mysql> select @@optimizer_switch\G
*************************** 1. row ***************************
@@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=on
1 row in set (0.01 sec)开启和关闭索引下推
#关闭
set optimizer_switch="index_condition_pushdown=off";
#开启
set optimizer_switch="index_condition_pushdown=on";