Spring实例化之推断构造方法
Spring实例化之推断构造方法
- 前言
- 推断构造方法原理
-
- @AutoWired推导构造方法
- Xml中构造方法推导
- @ConstructorProperties
- 推断构造方法源码解析
-
- 实例化createBeanInstance(构造方法推断)
- Supplier用法
- @AutoWired后置处理器推断构造方法
- 构造方法自动注autowireConstructor
前言
Spring中在生命周期中有一个非常重要的阶段就是推断构造方法,Bean的生命周期中,不管是单例的对象还是原型的对象都有实例化这个阶段,spring在扫描的阶段,也就是上篇笔记中所提到的spring使用插件的机制去扫描配置类,最后解析成BeanDefinition,spring的扫描是通过Asm字节码技术完成了bean的扫描工作,在扫描完成过后,生成的BeanDefinition中的BeanclassName是一个普通类的全限定名,这个类没有加载到jvm中的,只是把符合条件的类的全限定名作为className放入了BeanDefinition的属性中,所以在实例化阶段就需要加载到jvm中,然后进行实例化,在实例化的阶段就需要进行构造方法的推导,spring推导bean的构造方法过程非常复杂,考虑到了很多情况,这篇笔记就主要记录下spring是如何推导构造方法的。
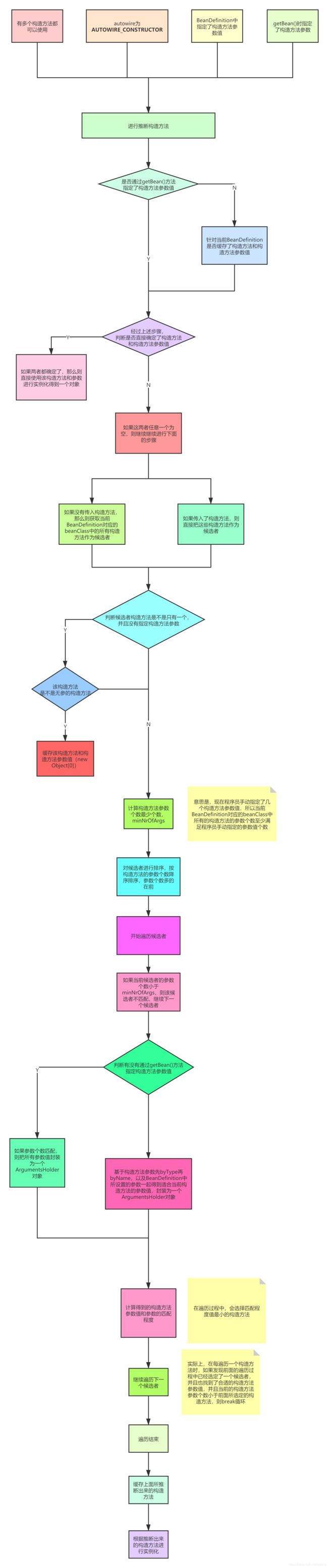
推断构造方法原理
Spring中在推断构造方法的时候,流程分为两大步:
第一步:通过spring提供的插件机制,也就是spring的bean后置处理器去决定构造方法的个数,决定构造方法的个数的逻辑为:
1.找到bean中的所有构造方法
2.循环每个构造方法,如果是实现了@AutoWired的就加入到候选candidates集合中;
3.如果说找到了两个@AutoWired的方法,那么就报错;
4.如果说构造方法中有@AutoWired的,但是也找到了一个默认的无参数构造,那么也加入到candidates,但是这个时候只有@AutoWired中的required为false才会加入,也就是说如果
找到了一个默认无参数构造,一个@AutoWired=true的构造,那么这个默认的无参数构造就会被舍弃,只有找到的@AutoWired=false,那么又找到了一个无参数构造,
才会加入到candidates中,也就是说如果找到了@AutoWired=false的构造和一般的无参数构造一样,都加入到了后续列表中,spring把它当成了一个不确定的因素,需要后续继续推导;
5.如果说找到的构造方法只有一个,并且这个构造方法的参数是大于0的,那么就返回这个构造方法;
6.如果前三个都不能满足,也就说是bean中存在2个以上的构造方法,但是都没有加@AutoWired注解的构造,那么直接返回null;
第二步是根据推导出的构造方法再去推导最终的构造方法,然后去实例化,在做换个过程中很很多推导条件:
首先开发者是否传入了参数,如果传入了参数,就算前面一步推导出的构造方法为空,那么有了参数,那么可以直接实例化;
如果开发者没有传入参数,那么这个时候就要再次推导构造方法,如果这个时候的构造方法只有一个,那么你在BeanDefinition中也没有定义参数,那么就可以直接通过无参数构造方法进行实例化;
如果有参数,并且存在多个构造方法,并且没有默认无参的构造方法,就会报错。
这推导构造方法的逻辑有点绕,写起来也比较难写,不晓得怎么写才能表述的更清楚。
当构造方法大于1个的时候,如果不加@AutoWried来决定使用的构造方法,那么你没有无参数的构造,那么spring最后无法决定你采用的构造方法,会采用默认的构造方法,但是你有没有写默认的构造方法,那么这个时候就会报错,比如:
@Component
public class UserService {
public UserService(User user){
System.out.println("one");
}
public UserService(User user,User user1){
System.out.println("two");
}
}

如果这样修改代码:
public UserService(){
System.out.println("non");
}
public UserService(User user,User user1){
System.out.println("two");
}
就可以的
再者如果多个构造方法,开发者通过getBean传入参数并且是原型的也是可以的
@Component
@Scope("prototype")
public class UserService {
public UserService(User user){
System.out.println("one");
}
public UserService(User user,User user1){
System.out.println("two");
}
}
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(AppConfig.class);
ac.refresh();
System.out.println(ac.getBean(UserService.class, new User()));
}
那么这个时候会去执行一个参数的构造方法,但是需要你的bean的作用域是原型的,因为单例的在容器启动就会实例化推导构造方法,这个时候是无法确定的,只有原型的或者懒加载的时候每次getBean去获取的时候才行。
还有中就是bean中的构造方法只有一个,这个时候如果构造方法的参数也大于0也是可以的,spring也是可以推导出来,因为只有一个,肯定得用这个,如果有两个,无法确定,spring就会去尝试使用无参数的构造,最终导致的就是如果你没有无参数构造就会报错,比如一个有参数的构造如下:
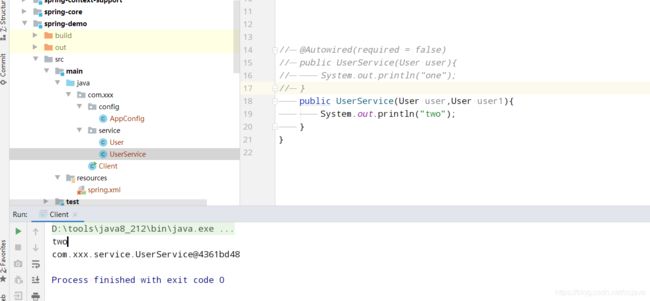
当一个bean中的构造方法有1个以上,但是必须要包含一个无参数的构造,因为spring是这样规定的,如果一个bean中的构造方法有1个以上,但是这些构造都没有使用@AutoWried来决定使用哪个哪个构造,那么第一步的推断构造方法返回的就是null,这个时候就要重新去推导,根据是否输入参数,参数个数,构造的个数和一些权重来决定了,但是必须要有一个无参数的构造,否则就要报错,如:
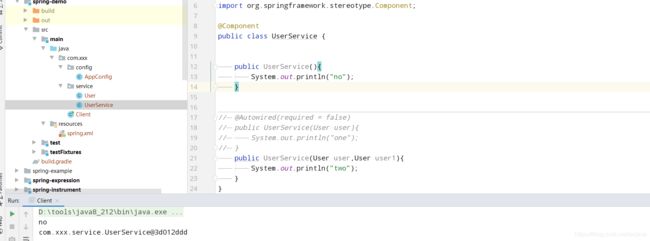
上面的这种情况就是使用了默认的构造方法
@AutoWired推导构造方法
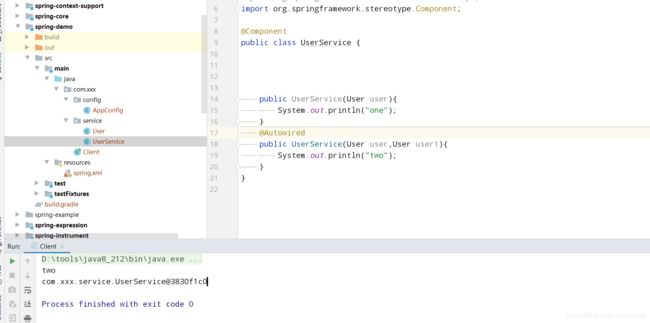
@AutoWired在spring的属性依赖注入的时候使用的比较多,但是在一个bean中的多个构造方法也可以通过@Autowred去决定使用哪个构造方法,但是要注意的时候,如果一个bean中的构造方法使用了@AutoWired修饰了,那么这个bean的其他构造方法不能再加@Autowired注解了,因为既然使用@AutoWried来决定使用的构造方法,那么你多个构造方法都用@Autowried修饰,那么你是几个意思?就算@AutoWried的required为false也不行。如果@AutoWried都设置为false,也是可以的,因为对于spring来说,在构造方法中@AutoWried如果设置required为false,那么它只能是候选者中的一个,不是决定性因素,所以在一个bean中的构造方法,只能存在一个@AutoWried,属性required为true的一个构造方法,存在了一个@AutoWried,属性为required=true的构造方法,就不能再有其他的@AutoWried,即使其他的required为false也不行。这是spring的设计者规定的
Xml中构造方法推导
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context-2.5.xsd">
<bean name="a2" class="com.xxx.service.UserService" autowire="constructor" >
</bean>
</beans>
spring中xml配置文件中的注入方式为构造方法注入,这个时候sprin的选择就不一样了, spring会选择一个最多参数的构造方法作为注入点,这个在源码里面已经体现了。
public class UserService {
public UserService(){
System.out.println("no");
}
public UserService(User user){
System.out.println("one");
}
public UserService(User user,User user1){
System.out.println("two");
}
}
还有下面这种方式:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context-2.5.xsd">
<bean name="a2" class="com.xxx.service.UserService" >
<constructor-arg index="0" ref="user" />
</bean>
</beans>
那么它就回去找到指定的构造方法进行注入,注入的模式多种多样,推导的范式也多种多样,这个不要去记,只要理解它的思想和理念就可以了。比如不加@AutoWried的时候怎么卖推导的,加了@AutoWried时候怎么推导的就可以了,不用去死记硬背。
@ConstructorProperties
在spring中的构造方法注入的情况中,spring会获取构造方法的参数去容器中找bean,和之前创建bean的过程一样,先byType,在byname,这样的话效率上有一定的影响,spring提供了一种新的方式可以让你手动指定参数中对应的beanname,然后根据beanName去获取bean,这样的方式就相当于去容器中getBean一样,性能非常高,但是这种方式spring在没有找到的情况下也是去byType和byName去获取,所以如果你要用这个注解,那么就要把bean的名字对应好,否则用了也白用,spring找不到对应的bean还是会走之前的逻辑,具体用法如下:
@Component
public class UserService {
public UserService(){
System.out.println("0");
}
@ConstructorProperties({"user","person"})
@Autowired
public UserService(User user,Person person){
System.out.println("2");
}
}
上面的用法如果说spirng在推断构造方法推到出来的构造方法是加了 @ConstructorProperties注解的,那么就很简单了,就直接获取 @ConstructorProperties的名字数组,然后依次去容器中getBean得到参数注入的对象,但是一定要写对,否则还是走以前的逻辑,这个参数就毫无意义了。
推断构造方法源码解析
推断构造方法就在spring实例化bean的时候进行的,实例化bean是在bean的生命周期中的,在spring调用createBean的过程中,我们看下入口在哪里
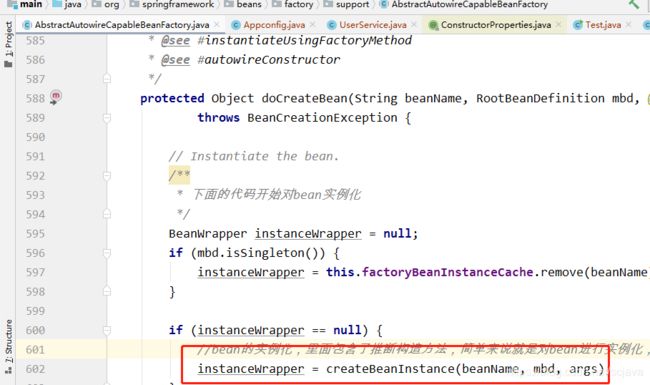
在这里对bean进行实例化,在实例化前就需要推到构造方法,实例化都是对构造方法进行推断,推断出一个最符合的构造方法进行实例化,如果在推到过程中发现无法确定一个构造方法就会报错,比如说你getBean传入了参数,但是在你的bean中根本就没有这样的一个构造方法,就会报错,或者说推断完成过后,构造方法都不能满足,就会去调用bean中的默认的无参数构造方法,但是这个默认无参数的构造方法又没有,也会报错,在spring中如果存在多个构造方法,可以通过@AutoWired来指定我们要使用这个构造方法,是可以来确定的,否则就只有让spring从众多的构造方法中去确定一个唯一可用的构造方法,推到的流程非常复杂,我们先来看下它的具体源码,这里的源码只关注下大概的流程解析,太细的地方需要下面细细研究。
实例化createBeanInstance(构造方法推断)
/**
* Create a new instance for the specified bean, using an appropriate instantiation strategy:
* factory method, constructor autowiring, or simple instantiation.
* @param beanName the name of the bean
* @param mbd the bean definition for the bean
* @param args explicit arguments to use for constructor or factory method invocation
* @return a BeanWrapper for the new instance
* @see #obtainFromSupplier
* @see #instantiateUsingFactoryMethod
* @see #autowireConstructor
* @see #instantiateBean
* 创建bean的实例,这里也是spring推断构造方法的核心所在
* args:表示程序员通过getBean传入的参数,如果使用getBean(Class reuqireType,Object[]args)
* 那么传入的参数就会传入到这里
*/
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
// Make sure bean class is actually resolved at this point.
//加载class,将Beanclass中的类的全限定名加载到jvm中,得到class对象,使用了的是默认的类加载器或者程序员自己设置的类加载器
Class<?> beanClass = resolveBeanClass(mbd, beanName);
//如果beanClass不是一各public的构造方法并且nonPublicAccessAllowed这个属性表示不是公共的构造方法不允许创建的话
//那么这里直接报错nonPublicAccessAllowed默认是true,也就是说你没有修改这个参数的值,那么默认是私有的构造方法也是实例化
if (beanClass != null && !Modifier.isPublic(beanClass.getModifiers()) && !mbd.isNonPublicAccessAllowed()) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean class isn't public, and non-public access not allowed: " + beanClass.getName());
}
/**
* 下面这个jdk8有的饿一个函数Supplier,也就是说你通过ApplicationContext注册一个bean的时候如果使用的是
* Supplier来创建的,那么spring就会调用你提供的Supplier方法来获取一个对象,就 表示是自己来构建这个对象,不是
* spring来给你推断构造方法实例化得到对象,这个也是一个小的知识点吧,但是我觉得很少有人用,但是你知道了可以根据自己的业务
* 场景来实现,比如我们后置处理器中干预BeanDefinition的时候可以手动创建一个Beanhuo,然后通过Supplier来自己构建
* 要放入单例池的对象,不用spring给我们去推断构造方法实例化得到对象,具体用法如:
* applicationContext.registerBean(A1.class, new Supplier() {
* @Override
* public A1 get() {
* return new A1();
* } });
*
* 那么你的BeanDefinition中就有了一个属性instanceSupplier是Supplier的类型,所以spring在这里创建对象的时候
* 就会直接调用你的Supplier对象中的get来返回一个对象
*/
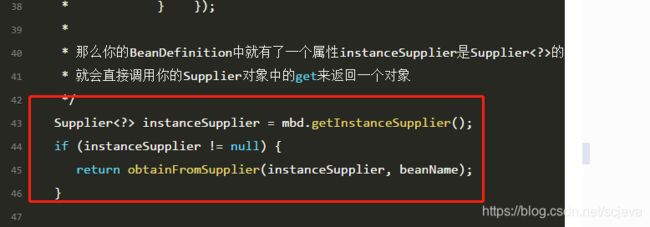
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
if (instanceSupplier != null) {
return obtainFromSupplier(instanceSupplier, beanName);
}
/**
* 这里是处理@Bean,就是说如果在配置类中加了@Bean注解的方法在上一步的配置类解析注册的时候会注册
* factoryBean 和factoryMethod,比如Appconfig中有一个@Bean方法test,那么factoryBean就是Appconfig
* 而FactoryMethod就是test,这里的逻辑是说如果factoryMethod不为空,那么就是@Bean来创建的,而在上一步的BeanDefinition
* 注册的时候是没有去调用@Bean注解的方法,所以@Bean注册的BeanDefinition的beanClass是等于空的,所以这里通过
* FactoryBean和factoryMethod去调用方法将返回值作为bean返回对象
*/
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
// Shortcut when re-creating the same bean...
boolean resolved = false;
boolean autowireNecessary = false;
//这里表示当你使用getBean传入的参数为空的时候进入下面的这个逻辑
if (args == null) {
//这里是把之前的构造方法和参数都缓存起来了,如果下次来调用发现有缓存,就直接取出上一次的构造方法名称和参数
//设置resolved为true
synchronized (mbd.constructorArgumentLock) {
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
//表示从缓存中已经找到了,并且时候一个屋参数的构造方法
if (resolved) {
if (autowireNecessary) {
return autowireConstructor(beanName, mbd, null, null);
}
else {
return instantiateBean(beanName, mbd);
}
}
// Candidate constructors for autowiring?
/**
* 下面的这个方法是去决定一组如何调节的构造方法,是从Bean的后置处理器中去决定的
* 什么意思呢?就是说从去调用bean的后置处理器器去决定一组构造方法,在spring中,
* 可以使用@AutoWired让程序员决定使用哪个构造方法,如果你在某个构造方法上面加了@AutoWired注解,
* 那么就是告诉spring,你要强制使用这个构造方法,但是在一个bean的所有构造方法中不能加两个@Autowired注解的
* 构造方法,因为这个时候spring也不知道你要用哪个了,所以只能加一个,具体的逻辑如下:
* 1.bean的后置处理器使用的是SmartInstantiationAwareBeanPostProcessor中的determineCandidateConstructors方法
* 这个方法只有AutoWiredBeanPostProcessor实现了它的逻辑,其他子类都没有实现;
* 2.在这个后置处理器中去找到构造方法的候选者,简单总结就是:
* a.bean中的构造方法只能有一个@autoWired的构造;
* b.如果有两个构造加了@AutoWired,直接报错;
* c.如果有一个构造@AutoWired=false,加入后续列表,如果这个时候有一个无参数构造,也加入到后续列表,如果只有一个@AutoWired,则返回这个构造;
* d.如果构造方法大于1个,但是都没有@AutoWired,那么返回null;
*/
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
//下面的条件进入autowireConstructor的逻辑为:
/**
* 1.找到的构造方法不为空;
* 2.bean的注入模式是通过构造方法注入;
* 3.bean中设置了构造的参数值(xm中);
* 4.或者说开发者通过getBean传入了参数的值;
* 上面的4个条件只要满足一个就进入autowireConstructor
*/
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
/**
* 构造方法推导
* ctors:上面找到的构造方法集合,在这里这个值可能为空null,可能为一个,可能为多个,如果有2个以上的构造没有加@AutoWired,那么返回null;如果有
* 有@AutoWried的注解,如果包含了required为ture的情况,就只能有一个构造返回,如果说@AutoWried都是否false的情况下,那么可能返回多个,在都是false的情况
* 下,如果还有一个默认的构造,那么ctors返回的就是@AutoWired的数量+默认的无参数构造函数
* args:就是开发者通过getBean传入的参数args
* 就是说如果ctors不为null 或者注入模式为构造方法或者xml中《Bean》
* 设置了构造参数或者getBean传入的参数不为空都会进入这里。
*/
return autowireConstructor(beanName, mbd, ctors, args);
}
// Preferred constructors for default construction?
ctors = mbd.getPreferredConstructors();
if (ctors != null) {
return autowireConstructor(beanName, mbd, ctors, null);
}
/**
* 这个最后的这个逻辑是spring用来保证bean的实例化在一定程度上能够成功,也就是最后的选择
* 如果上面的都不能满足的情况下,用默认的无参数构造方法来实例化,因为上面的筛选条件中如果你定义了2个以上的构造方法,但是没有加@AutoWired,spring就不知道用那个了
* 所以返回的ctors为null,比如一个空构造,一个有参数的构造,都没有加@AutoWired
* 而且也不能满足一定的条件进入autowireConstructor,所以代码逻辑就到了这里,就调用一个默认的构造
*/
// No special handling: simply use no-arg constructor.
return instantiateBean(beanName, mbd);
}
这个方法的参数这里简单说明下:
beanName:这个是实例化的Bean的名字,也就是beanName
mbd:bean所在的BeanDefinition;
args:这个参数很多情况下都是没有的,只有你通过getBean的时候才会传入,简单说下就是getBean如果传入了构造方法的参数,但是这个bean是懒加载的单例bean或者是原型的bean才会有效果,否则单例bean在实例化的时候是没有参数的,会直接放入单例池。
Supplier用法
上面的代码中有一个Supplier的用法,这里单独来说明一下,就是说我们可以通过手动注册一个bean,但是这个bean我不想要spirng来给实例化,需要我自己来实例化,也就是我们不想要spring去推断构造方法了,开发者自己去实例化,用法简单了解一下:
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new
AnnotationConfigApplicationContext();
ac.register(Appconfig.class);
ac.refresh();
ac.registerBean(User.class, new Supplier<User>() {
@Override
public User get() {
return new User();
}
});
}
就是可手动注册一个bean,这个bean的的实例是我们在回调方法Supplier中去调用的,当使用这种方式去注册一个bean的时候,其实是在BeanDefinition中设置了一个属性InstanceSupplier的,具体看下面截图:
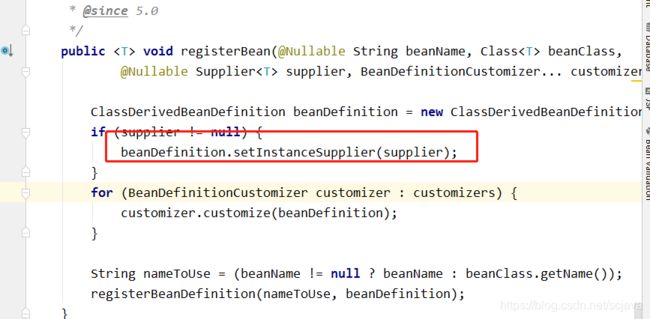
,当spring执行到
这里的时候判断你是否设置了Supplier类型的bean,如果是的话,那么就会调用Supplier中的get方法直接返回一个实例化后的对象,也就不需要spring进行推断了。
@AutoWired后置处理器推断构造方法
在推断构造方法的时候,spring会先通过bean的后置处理器先去确定一些符合条件的构造方法,然后再对这些构造方法进行判断;
@Override
@Nullable
public Constructor<?>[] determineCandidateConstructors(Class<?> beanClass, final String beanName)
throws BeanCreationException {
// Let's check for lookup methods here...
//这个是Lockup的逻辑,现在这里暂时不用管
if (!this.lookupMethodsChecked.contains(beanName)) {
if (AnnotationUtils.isCandidateClass(beanClass, Lookup.class)) {
try {
Class<?> targetClass = beanClass;
do {
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
Lookup lookup = method.getAnnotation(Lookup.class);
if (lookup != null) {
Assert.state(this.beanFactory != null, "No BeanFactory available");
LookupOverride override = new LookupOverride(method, lookup.value());
try {
RootBeanDefinition mbd = (RootBeanDefinition)
this.beanFactory.getMergedBeanDefinition(beanName);
mbd.getMethodOverrides().addOverride(override);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(beanName,
"Cannot apply @Lookup to beans without corresponding bean definition");
}
}
});
targetClass = targetClass.getSuperclass();
}
while (targetClass != null && targetClass != Object.class);
}
catch (IllegalStateException ex) {
throw new BeanCreationException(beanName, "Lookup method resolution failed", ex);
}
}
this.lookupMethodsChecked.add(beanName);
}
// Quick check on the concurrent map first, with minimal locking.
//决定一组构造方法的逻辑代码,candidateConstructorsCache是一个构造方法候选者的集合,就是说如果找到了符合条件的构造方法
//都会缓存到这个集合中,表示是符合条件的构造方法的候选者集合
//这里先从缓存中去取,如果缓存中没有,就去推断出符合的记录添加到缓存中
Constructor<?>[] candidateConstructors = this.candidateConstructorsCache.get(beanClass);
if (candidateConstructors == null) {
// Fully synchronized resolution now...
synchronized (this.candidateConstructorsCache) {
//先从缓存中去取,如果有,就直接返回了,如果没有,就去找
candidateConstructors = this.candidateConstructorsCache.get(beanClass);
if (candidateConstructors == null) {
Constructor<?>[] rawCandidates;
try {
//这个是得到一个Bean中的声明的所有的构造方法列表,是一个数组,数组里面是bean中的所有构造方法
rawCandidates = beanClass.getDeclaredConstructors();
}
catch (Throwable ex) {
throw new BeanCreationException(beanName,
"Resolution of declared constructors on bean Class [" + beanClass.getName() +
"] from ClassLoader [" + beanClass.getClassLoader() + "] failed", ex);
}
//构建一个候选者列表的构造方法集合
List<Constructor<?>> candidates = new ArrayList<>(rawCandidates.length);
//表示一个加了@AutoWired注解并且require=true的构造方法
Constructor<?> requiredConstructor = null;
//表示是一个默认的构造方法,是一个空参数的构造方法
Constructor<?> defaultConstructor = null;
//找Primary的构造
Constructor<?> primaryConstructor = BeanUtils.findPrimaryConstructor(beanClass);
int nonSyntheticConstructors = 0;
//循环上面得到的构造方法列表
for (Constructor<?> candidate : rawCandidates) {
if (!candidate.isSynthetic()) {
nonSyntheticConstructors++;
上面代码逻辑如下:
1.找到bean中的所有构造方法
2.循环每个构造方法,如果是实现了@AutoWired的就加入到候选candidates集合中;
3.如果说找到了两个@AutoWired的方法,那么就报错;
4.如果说构造方法中有@AutoWired的,但是也找到了一个默认的无参数构造,那么也加入到candidates,但是这个时候只有@AutoWired中的required为false才会加入,也就是说如果
找到了一个默认无参数构造,一个@AutoWired=true的构造,那么这个默认的无参数构造就会被舍弃,只有找到的@AutoWired=false,那么又找到了一个无参数构造,
才会加入到candidates中,也就是说如果找到了@AutoWired=false的构造和一般的无参数构造一样,都加入到了后续列表中,spring把它当成了一个不确定的因素,需要后续继续推导;
5.如果说找到的构造方法只有一个,并且这个构造方法的参数是大于0的,那么就返回这个构造方法;
6.如果前三个都不能满足,也就说是bean中存在2个以上的构造方法,但是都没有加@AutoWired注解的构造,那么直接返回null。
构造方法自动注autowireConstructor
这个方法很长,
public BeanWrapper autowireConstructor(String beanName, RootBeanDefinition mbd,
@Nullable Constructor<?>[] chosenCtors, @Nullable Object[] explicitArgs) {
BeanWrapperImpl bw = new BeanWrapperImpl();
this.beanFactory.initBeanWrapper(bw);
//构造方法,真正使用的构造方法,最后使用的
Constructor<?> constructorToUse = null;
//参数holder对象
ArgumentsHolder argsHolderToUse = null;
//参数的对象列表,真正调用构造方法传进去的参数数组
Object[] argsToUse = null;
//如果开发者通过getBean传入了参数,那么这里把开发者传入的参数赋值给真正要是用的参数列表
if (explicitArgs != null) {
argsToUse = explicitArgs;
}
else {
//从缓存中获取构造方法和参数列表,如果第一次肯定是没有缓存的,如果是第二次,相同的这个bd肯定是可以从缓存获取的,这里如果没有缓存,本次执行完成过后会放入到缓存中
Object[] argsToResolve = null;
synchronized (mbd.constructorArgumentLock) {
constructorToUse = (Constructor<?>) mbd.resolvedConstructorOrFactoryMethod;
if (constructorToUse != null && mbd.constructorArgumentsResolved) {
// Found a cached constructor...
argsToUse = mbd.resolvedConstructorArguments;
if (argsToUse == null) {
argsToResolve = mbd.preparedConstructorArguments;
}
}
}
if (argsToResolve != null) {
argsToUse = resolvePreparedArguments(beanName, mbd, bw, constructorToUse, argsToResolve, true);
}
}
/**
* 如果上面的代码如果开发者没有通过getBean传入参数,如果开发者传入了参数,那么都不需要推导构造方法,直接调用即可;
* 如果说开发者没有传入参数,构造方法和参数在缓存中也没有获取到,那么这里就进入到下面的一大串的逻辑去处理
*/
if (constructorToUse == null || argsToUse == null) {
// Take specified constructors, if any.
//chosenCtors是这个方法传入的参数,就是前面的方法中通过bean的后置处理器去决定构造方法得到的构造方法列表,是可能为空的
Constructor<?>[] candidates = chosenCtors;
//这个if就是为了构建我们的构造方法列表,如果没有,就重新从beanclass中获取构造方法列表
if (candidates == null) {
/**
* 在bean的后置处理器中得到的构造方法为空的情况下,就是你的bean中的构造方法定义了至少两个,都没有@AutoWired注解,反正就是有好几个构造方法,spring无法决定
* 而这个时候有可能是自动注入的或者开发者getBean传入了参数或者xml中在BeanDefinition中设置了入参的参数,所以会进到这里
*/
Class<?> beanClass = mbd.getBeanClass();
try {
//那么这里得到beanclass中的所有构造方法列表,isNonPublicAccessAllowed表示是获取声明的构造方法列表,否则就是默认所有的构造方法列表
candidates = (mbd.isNonPublicAccessAllowed() ?
beanClass.getDeclaredConstructors() : beanClass.getConstructors());
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Resolution of declared constructors on bean Class [" + beanClass.getName() +
"] from ClassLoader [" + beanClass.getClassLoader() + "] failed", ex);
}
}
//如果构造方法列表中只有一个并且开发者没有传入参数并且在BeanDefinition中没有设置参数(典型的就是在xml中没有设置
//constructor-arg,什么意思呢??就是说spring给我们找到了一个构造方法,而且开发者没有传入参数,在定义bean的
//过程中也没有设置参数,那么就进入下面的逻辑
if (candidates.length == 1 && explicitArgs == null && !mbd.hasConstructorArgumentValues()) {
Constructor<?> uniqueCandidate = candidates[0];
//满足上面的条件过后,还需要说这个构造方法是一个没有参数的构造方法,也就是无参的构造
if (uniqueCandidate.getParameterCount() == 0) {
//放缓存
synchronized (mbd.constructorArgumentLock) {
mbd.resolvedConstructorOrFactoryMethod = uniqueCandidate;
mbd.constructorArgumentsResolved = true;
mbd.resolvedConstructorArguments = EMPTY_ARGS;
}
//实例化,得到的构造方法是uniqueCandidate,参数是EMPTY_ARGS,就可以很简单的实例化了
/**
* 简单来说就是spring找到了一个构造方法,这个构造方法是一个默认的无参数构造,开发者没有传入参数
* BeanDefinition中也没有设置参数,就直接调用默认的构造去实例化
*/
bw.setBeanInstance(instantiate(beanName, mbd, uniqueCandidate, EMPTY_ARGS));
return bw;
}
}
// Need to resolve the constructor.
//如果上面的没有满足,代码逻辑到这里,如果说获取的构造方法不为空,并且BeanDefinition中的注入模式是构造方法注入
boolean autowiring = (chosenCtors != null ||
mbd.getResolvedAutowireMode() == AutowireCapableBeanFactory.AUTOWIRE_CONSTRUCTOR);
ConstructorArgumentValues resolvedValues = null;
/**
* minNrOfArgs=????,什么意思呢,就是说它代表的意思就是一个构造方法中最小的参数个数
* 如果开发者传入了参数,那么这个值就是参数的个数,如果没有传入,那么spring就要去推导怎么取值
* 比如在xml中设置了constructor-arg 中的index=‘1’,那么spring就知道这个构造函数的参数至少为2,所以这个
* 值就是2,就是表示构造函数中的参数个数的最小值
*/
int minNrOfArgs;
if (explicitArgs != null) {
//如果开发者传入了参数这个值就是开发者传入的参数的个数
minNrOfArgs = explicitArgs.length;
}
else {
//否则这里就去计算得到参数个数的最小值,也就是说参数个数的最小值,最小能有几个
/**
* 比如bean中有两个构造,一个构造2个参数,一个构造3个参数,其中第二个参数的类型一致,那么你在xml中注入的时候
*
ConstructorArgumentValues cargs = mbd.getConstructorArgumentValues();
resolvedValues = new ConstructorArgumentValues();
//计算
minNrOfArgs = resolveConstructorArguments(beanName, mbd, bw, cargs, resolvedValues);
}
//这里对得到的构造方法进行排序,排序的依据是构造方法的参数个数进行排序,比如有两个构造方法,一个2个参数,一个3个参数
// 那么3个参数排在最前面,也就是说优先是参数的多的构造方法最新执行
AutowireUtils.sortConstructors(candidates);
//得到最小的权重,用于计算后续的最后推导构造方法
int minTypeDiffWeight = Integer.MAX_VALUE;
Set<Constructor<?>> ambiguousConstructors = null;
LinkedList<UnsatisfiedDependencyException> causes = null;
//循环这个构造方法列表
for (Constructor<?> candidate : candidates) {
int parameterCount = candidate.getParameterCount();
/**
* 这是一个循环,第一次循环不会进这个if,也就是说在循环中如果已经找到了一个给开发者使用的构造方法
* constructorToUse,并且构造方法的参数也定了,并且找到的构造方法的参数的个数是大于当前循环的这个
* 构造方法的参数就会使用,什么意思呢?
* 比如有两个构造方法,一个2个参数,一个3个参数,3个参数最先执行,在第一次循环的时候固定了构造方法和参数都已经定好了
* ,第二次循环的时候发现构造函数也不为空,参数也不为空,并且上一次找到的参数个数3个也大于当前循环的参数个数2个
* 就进入下面的这个if,退一万步说上面的排序没有成功,那么参数个数为2先循环,那么也不会进入下面的if,还是会在第二次
* 循环来决定采用了有三个参数的构造,所以这就是spring在推导构造方法的时候采用的是最多参数个数为准的构造
*/
if (constructorToUse != null && argsToUse != null && argsToUse.length > parameterCount) {
// Already found greedy constructor that can be satisfied ->
// do not look any further, there are only less greedy constructors left.
break;
}
//这里的这个判断是为了更严谨而设置的条件,其实根本不会进,你想哈,在循环外已经决定了参数的个数minNrOfArgs最小为多少个
//也就是说它能够找到了你的所有构造函数里面的最多参数的构造参数的个数赋值给它,所以这里是为了更严谨一点儿设置的一个条件
if (parameterCount < minNrOfArgs) {
continue;
}
ArgumentsHolder argsHolder;
Class<?>[] paramTypes = candidate.getParameterTypes();
//resolvedValues这个值是在上面设置的,设置的条件就是开发者没有传入参数设置的一个对象,换句话说就是
//下面的if进入的条件就是开发者没有传入参数
if (resolvedValues != null) {
try {
//下面的这个逻辑就是看你有没有在构造方法上加@ConstructorProperties注解,就是设置构造方法参数
//的名字,如果设置了,就简单了,获取整个名字数组然后去bean工厂取bean就可以了,如果没有设置
//那么通过java8的提供的功能获取方法的参数名字paramNames
//说白了paramNames就是bean中的名字,通过不同的方式获取的
//1.通过配置@ConstructorProperties得到;
//2.通过java8的方式得到
String[] paramNames = ConstructorPropertiesChecker.evaluate(candidate, parameterCount);
if (paramNames == null) {
ParameterNameDiscoverer pnd = this.beanFactory.getParameterNameDiscoverer();
if (pnd != null) {
paramNames = pnd.getParameterNames(candidate);
}
}
//通过方法参数的名字和类型和构造方法去获取每个参数对应的value,也就是这些value都在bean工厂中
///最后返回一个argsHolder对象,作为整个构造方法,构造参数的一个对象,最后会根据权重来计算
//该使用哪个构造方法和参数,这里面也是先byType,再byName
argsHolder = createArgumentArray(beanName, mbd, resolvedValues, bw, paramTypes, paramNames,
getUserDeclaredConstructor(candidate), autowiring, candidates.length == 1);
}
catch (UnsatisfiedDependencyException ex) {
if (logger.isTraceEnabled()) {
logger.trace("Ignoring constructor [" + candidate + "] of bean '" + beanName + "': " + ex);
}
// Swallow and try next constructor.
if (causes == null) {
causes = new LinkedList<>();
}
causes.add(ex);
continue;
}
}
else {
// Explicit arguments given -> arguments length must match exactly.
if (parameterCount != explicitArgs.length) {
continue;
}
argsHolder = new ArgumentsHolder(explicitArgs);
}
//计算权重,根据权重来确定唯一的一个构造方法
int typeDiffWeight = (mbd.isLenientConstructorResolution() ?
argsHolder.getTypeDifferenceWeight(paramTypes) : argsHolder.getAssignabilityWeight(paramTypes));
// Choose this constructor if it represents the closest match.
if (typeDiffWeight < minTypeDiffWeight) {
constructorToUse = candidate;
argsHolderToUse = argsHolder;
argsToUse = argsHolder.arguments;
minTypeDiffWeight = typeDiffWeight;
ambiguousConstructors = null;
}
else if (constructorToUse != null && typeDiffWeight == minTypeDiffWeight) {
if (ambiguousConstructors == null) {
ambiguousConstructors = new LinkedHashSet<>();
ambiguousConstructors.add(constructorToUse);
}
ambiguousConstructors.add(candidate);
}
}
//如果到这里还没有确定一个唯一的构造方法就直接报错
if (constructorToUse == null) {
if (causes != null) {
UnsatisfiedDependencyException ex = causes.removeLast();
for (Exception cause : causes) {
this.beanFactory.onSuppressedException(cause);
}
throw ex;
}
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Could not resolve matching constructor " +
"(hint: specify index/type/name arguments for simple parameters to avoid type ambiguities)");
}
else if (ambiguousConstructors != null && !mbd.isLenientConstructorResolution()) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Ambiguous constructor matches found in bean '" + beanName + "' " +
"(hint: specify index/type/name arguments for simple parameters to avoid type ambiguities): " +
ambiguousConstructors);
}
//将推断出来的构造方法缓存起来,方便下次使用
if (explicitArgs == null && argsHolderToUse != null) {
argsHolderToUse.storeCache(mbd, constructorToUse);
}
}
Assert.state(argsToUse != null, "Unresolved constructor arguments");
//最后听过构造方法,参数调用实例化完成Bean对象的赋值
bw.setBeanInstance(instantiate(beanName, mbd, constructorToUse, argsToUse));
return bw;
}
代码中的注释写的很详细了,这里就不多说了,首先明白的是:
1.先通过bean后置处理器去确定构造方法;
2.然后对确定的构造方法进行处理,如果确定的构造方法为空,那么需要从新去确定,比如根据参数、开发者是否传入了参数,BeanDefinition中是否有参数值得设定,最后对确定好的构造方法列表进行排序(依据方法参数的个数,参数个数最多的排在最前面);如果用户没有传入参数,那么对确定的多个构造方法还需要计算权重值,根据权重值来选择一个合适的构造方法,最后如果都还不能确定一个构造方法,就不报错,比如确定的构造方法的权重值一样,没有找到合适的构造方法。