内核IO栈 | 反弹缓冲区、bio切分、完整性保护和蓄流
line17 ※1 反弹缓冲区
blk_queue_bounce函数的作用是,尝试创建一个反弹缓冲区,通常是在bio给定的内存区域在外围设备不可达(例如高端内存上执行DMA)的地址时才需要去创建这么一个特殊的区域,以确保内存区域是外围设备可达的,这是bio能够完成的必要条件。
static inline void blk_queue_bounce(struct request_queue *q, struct bio **bio)
{
if (unlikely(blk_queue_may_bounce(q) && bio_has_data(*bio))) // 携带数据才需要bounce
__blk_queue_bounce(q, bio);
}
void __blk_queue_bounce(struct request_queue *q, struct bio **bio_orig)
{
struct bio *bio;
int rw = bio_data_dir(*bio_orig);
struct bio_vec *to, from;
struct bvec_iter iter;
unsigned i = 0;
bool bounce = false;
int sectors = 0;
// 对bio的每一个数据段,检查是否需要bounce
bio_for_each_segment(from, *bio_orig, iter) {
if (i++ < BIO_MAX_VECS)
sectors += from.bv_len >> 9;
if (PageHighMem(from.bv_page))
bounce = true;
}
// 没有高端内存不需要bounce就直接返回了
if (!bounce)
return;
if (sectors < bio_sectors(*bio_orig)) {
bio = bio_split(*bio_orig, sectors, GFP_NOIO, &bounce_bio_split);
bio_chain(bio, *bio_orig);
submit_bio_noacct(*bio_orig);
*bio_orig = bio;
}
// bounce过程需要新建一个bio
bio = bounce_clone_bio(*bio_orig);
/*
* Bvec table can't be updated by bio_for_each_segment_all(),
* so retrieve bvec from the table directly. This way is safe
* because the 'bio' is single-page bvec.
* 这个循环遍历了bio关联的内存区域
*/
for (i = 0, to = bio->bi_io_vec; i < bio->bi_vcnt; to++, i++) {
struct page *bounce_page;
// 外围设备可以触达的地方就不需要移动
if (!PageHighMem(to->bv_page))
continue;
bounce_page = mempool_alloc(&page_pool, GFP_NOIO);
inc_zone_page_state(bounce_page, NR_BOUNCE);
// 如果是写操作的话,还需要将原来的不可触达的内存中的内容迁移到反弹缓冲区
if (rw == WRITE) {
flush_dcache_page(to->bv_page);
memcpy_from_bvec(page_address(bounce_page), to);
}
// 修改新的指向关系,bvec指向新页
to->bv_page = bounce_page;
}
trace_block_bio_bounce(*bio_orig);
// 标记这是一个bounce bio
bio->bi_flags |= (1 << BIO_BOUNCED);
// 替换为bounce特有的bio_end_io函数,里面会将对应的内存再做处理后调用原来bio的bio_end_io函数
if (rw == READ)
bio->bi_end_io = bounce_end_io_read;
else
bio->bi_end_io = bounce_end_io_write;
// 把原来的bio藏好
bio->bi_private = *bio_orig;
// 偷梁换柱,后面的流程就会处理反弹bio了
*bio_orig = bio;
}创建反弹缓冲区实际上是创建了一个新的bio,这个bio将原来外围设备无法触达的内存页替换为新的可以触达内存页,并设置了一个新的回调函数,在后续的过程中,将使用新的反弹bio代替原来的bio进行处理,为了将数据传递到正确位置,反弹时提供了一个新的bio完成回调函数,bio在完成后,将反弹缓冲区中的内容复制到原来的不可达内存区域后再调用原来bio的end_io函数。
可以发现,反弹缓冲区的引入导致了额外的数据传输,但是这是无法避免的。

line18 ※2 bio切分
这里所做的bio切分的目的是,特定的下层队列支持的最大数据段数目是不同的,对于超大的bio,要进行切分,切分就是将一个bio切分为多个bio,并将这些bio链接起来。
在这个函数里面会调用bio_split和bio_chain,这里的链接并不是采用bi_next链接,而是对所切分出来的新的bio使用bi_private域进行链接并且要进行特殊处理,因为首先,bi_next是用于bio的合并操作的,其次,如果将一个bio切分为若干个bio,它们的空间释放应当由块IO子系统层管理,且应该等待一个向上层能且只能调用原来的bio_end_io函数在所有被切分出来的bio都完成后报告一次,因此需要替换它们的bio_end_io函数,以下为实际实现:
void __blk_queue_split(struct bio **bio, unsigned int *nr_segs)
{
struct request_queue *q = (*bio)->bi_bdev->bd_disk->queue;
struct bio *split = NULL;
// 对不同的bio命令的特殊处理,最后都会调用到bio_split函数
switch (bio_op(*bio)) {
case REQ_OP_DISCARD:
case REQ_OP_SECURE_ERASE:
split = blk_bio_discard_split(q, *bio, &q->bio_split, nr_segs);
break;
case REQ_OP_WRITE_ZEROES:
split = blk_bio_write_zeroes_split(q, *bio, &q->bio_split,
nr_segs);
break;
case REQ_OP_WRITE_SAME:
split = blk_bio_write_same_split(q, *bio, &q->bio_split,
nr_segs);
break;
default:
/*
* All drivers must accept single-segments bios that are <=
* PAGE_SIZE. This is a quick and dirty check that relies on
* the fact that bi_io_vec[0] is always valid if a bio has data.
* The check might lead to occasional false negatives when bios
* are cloned, but compared to the performance impact of cloned
* bios themselves the loop below doesn't matter anyway.
*/
if (!q->limits.chunk_sectors &&
(*bio)->bi_vcnt == 1 &&
((*bio)->bi_io_vec[0].bv_len +
(*bio)->bi_io_vec[0].bv_offset) <= PAGE_SIZE) {
*nr_segs = 1;
break;
}
split = blk_bio_segment_split(q, *bio, &q->bio_split, nr_segs);
break;
}
if (split) {
/* there isn't chance to merge the splitted bio */
split->bi_opf |= REQ_NOMERGE;
// 在这里调用了bio_chain函数
bio_chain(split, *bio);
trace_block_split(split, (*bio)->bi_iter.bi_sector);
// 提交新生成的bio
submit_bio_noacct(*bio);
*bio = split;
blk_throtl_charge_bio_split(*bio);
}
}bio_split函数:函数功能是将输入的bio切分为两个,切分sectors大小作为第一个bio并作为返回值返回,剩余大小作为第二个bio,直接修改在输入的bio结构中。
struct bio *bio_split(struct bio *bio, int sectors,
gfp_t gfp, struct bio_set *bs)
{
struct bio *split;
BUG_ON(sectors <= 0);
BUG_ON(sectors >= bio_sectors(bio));
/* Zone append commands cannot be split */
if (WARN_ON_ONCE(bio_op(bio) == REQ_OP_ZONE_APPEND))
return NULL;
split = bio_clone_fast(bio, gfp, bs);
if (!split)
return NULL;
split->bi_iter.bi_size = sectors << 9;
if (bio_integrity(split))
bio_integrity_trim(split);
// 将原来的bio跨越第一个bio
bio_advance(bio, split->bi_iter.bi_size);
if (bio_flagged(bio, BIO_TRACE_COMPLETION))
bio_set_flag(split, BIO_TRACE_COMPLETION);
return split;
}bio_chain函数:将bio链接起来,修改回调函数,会确保chain上所有bio都完成了才能向上报告。
void bio_chain(struct bio *bio, struct bio *parent)
{
BUG_ON(bio->bi_private || bio->bi_end_io);
bio->bi_private = parent; // 使用bi_private串起来
bio->bi_end_io = bio_chain_endio; // 修改end_io,里面会检查链上是否都完成,注意,链最前面的一个的end_io是不会被修改的
bio_inc_remaining(parent); // 原子性操作修改__bi_remaining域
}
static inline void bio_inc_remaining(struct bio *bio)
{
bio_set_flag(bio, BIO_CHAIN);
smp_mb__before_atomic();
atomic_inc(&bio->__bi_remaining); // 原子性操作
}
static void bio_chain_endio(struct bio *bio)
{
bio_endio(__bio_chain_endio(bio));
}
// 这个函数的作用是释放自己的一个引用计数,返回链前一个bio
static struct bio *__bio_chain_endio(struct bio *bio)
{
struct bio *parent = bio->bi_private;
// bi_status == 0 means BLK_STS_OK
if (bio->bi_status && !parent->bi_status)
parent->bi_status = bio->bi_status; // 错误报告是需要继承的
bio_put(bio); // 释放自己的一个引用计数
return parent;
}
endio中会检查是否全部完成:
void bio_endio(struct bio *bio)
{
again:
if (!bio_remaining_done(bio)) // 检查bio链是否全部完成
return;
if (!bio_integrity_endio(bio)) // 完整性保护
return;
if (bio->bi_bdev && bio_flagged(bio, BIO_TRACKED))
rq_qos_done_bio(bio->bi_bdev->bd_disk->queue, bio);
if (bio->bi_bdev && bio_flagged(bio, BIO_TRACE_COMPLETION)) {
trace_block_bio_complete(bio->bi_bdev->bd_disk->queue, bio);
bio_clear_flag(bio, BIO_TRACE_COMPLETION);
}
/*
* Need to have a real endio function for chained bios, otherwise
* various corner cases will break (like stacking block devices that
* save/restore bi_end_io) - however, we want to avoid unbounded
* recursion and blowing the stack. Tail call optimization would
* handle this, but compiling with frame pointers also disables
* gcc's sibling call optimization.
*/
if (bio->bi_end_io == bio_chain_endio) { // 当前没有位于链条第一个!
bio = __bio_chain_endio(bio); // 会一直获取到链条第一个,只有它的bio_end_io才是真的
goto again; // bio_remaining_done 需要重新判断
}
blk_throtl_bio_endio(bio);
/* release cgroup info */
bio_uninit(bio);
if (bio->bi_end_io)
bio->bi_end_io(bio); // 调用真正的endio
}
static inline bool bio_remaining_done(struct bio *bio)
{
/*
* If we're not chaining, then ->__bi_remaining is always 1 and
* we always end io on the first invocation.
*/
if (!bio_flagged(bio, BIO_CHAIN)) // 如果不是链条上的bio,直接返回true
return true;
BUG_ON(atomic_read(&bio->__bi_remaining) <= 0);
// 如果是链上的bio,原子化使得__bi_remaining -1,如果为0,消除BIO_CHAIN标签
if (atomic_dec_and_test(&bio->__bi_remaining)) {
bio_clear_flag(bio, BIO_CHAIN);
return true;
}
// 不为0,说明这个链条后面还有没有完成的bio,返回false
return false;
// 但是前面仍然可能有没有完成的bio,会在endio里面跳转again递归处理
// 一次递归后,会将该bio整个链条在这bio之前的部分的__bi_remaining都减去1
// 如果第一个都减到0了,才会调用endio
}line20 ※3 完整性保护
设计存储系统的最大挑战在于提供用户所期望的可靠性和可用性。由于硬件原因导致的数据损坏是比较容易被检测和发现的,但是由于软件原因写入错误带来的“沉默的数据破坏”更加棘手,因为当应用程序最终读回数据而检测到数据被破坏时,正确的数据已经永久丢失了。
为了防止数据破坏常用的技术是:在穿越IO栈时,在数据后追加一些额外的信息,用来检测数据的完整性,我们我们称之为完整性元数据(Integrity MetaData)或保护信息(Protection Information)。
为了支持完整性保护,SCSI协议族增加了新的SCSI特性,允许在控制器和磁盘之间交换额外的保护信息(数据完整性域,Data Integrity Field,DIF),Linux内核进一步拓展,可以让文件系统在IO请求上加上完整性数据(数据完整性拓展,Data Integrity Extension,DIX)。DIF和DIX结合可以实现从应用程序到磁盘驱动器的完整IO路径上的“端对端”数据保护。
更多的细节暂时不在本文了解,但是我们知道,上层发送到块IO子系统的数据请求是使用bio来表示的,因此,对应的完整性数据也会关联到bio。因此bio中有一个bio_integrity_payload类型的指针字段,指向保存完整性元数据的bio完整性载荷:
struct bio_integrity_payload {
struct bio *bip_bio; /* parent bio */
struct bvec_iter bip_iter; // 与bio功能相似的迭代器
unsigned short bip_vcnt; /* # of integrity bio_vecs */
unsigned short bip_max_vcnt; /* integrity bio_vec slots */
unsigned short bip_flags; /* control flags */
struct bvec_iter bio_iter; /* for rewinding parent bio */
struct work_struct bip_work; /* I/O completion 用于io完成的工作队列*/
struct bio_vec *bip_vec; // 与bio功能相似,数据起点
struct bio_vec bip_inline_vecs[];/* embedded bvec array */
};该结构作为一种额外负载,额外表示了完整性数据在内存中的位置及一些其他的记账信息。
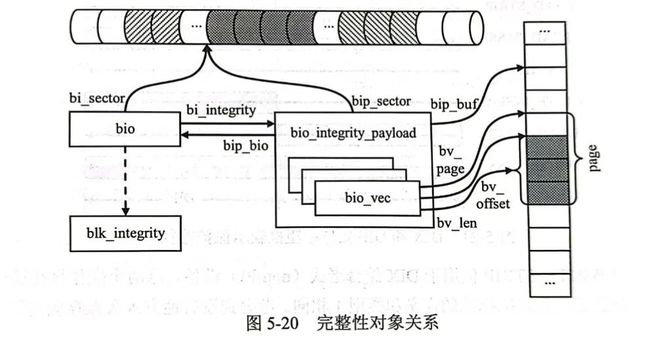
因此,第20行bio_integrity_prep(bio)函数正在为bio准备完整性数据。
bool bio_integrity_prep(struct bio *bio)
{
struct bio_integrity_payload *bip;
struct blk_integrity *bi = blk_get_integrity(bio->bi_bdev->bd_disk);
void *buf;
unsigned long start, end;
unsigned int len, nr_pages;
unsigned int bytes, offset, i;
unsigned int intervals;
blk_status_t status;
if (!bi)
return true;
if (bio_op(bio) != REQ_OP_READ && bio_op(bio) != REQ_OP_WRITE)
return true;
if (!bio_sectors(bio))
return true;
/* Already protected? */
if (bio_integrity(bio))
return true;
if (bio_data_dir(bio) == READ) {
if (!bi->profile->verify_fn ||
!(bi->flags & BLK_INTEGRITY_VERIFY))
return true;
} else {
if (!bi->profile->generate_fn ||
!(bi->flags & BLK_INTEGRITY_GENERATE))
return true;
}
intervals = bio_integrity_intervals(bi, bio_sectors(bio));
/* 为完整性保护数据申请内核空间 */
len = intervals * bi->tuple_size;
buf = kmalloc(len, GFP_NOIO);
status = BLK_STS_RESOURCE;
if (unlikely(buf == NULL)) {
printk(KERN_ERR "could not allocate integrity buffer\n");
goto err_end_io;
}
end = (((unsigned long) buf) + len + PAGE_SIZE - 1) >> PAGE_SHIFT;
start = ((unsigned long) buf) >> PAGE_SHIFT;
nr_pages = end - start;
/* Allocate bio integrity payload and integrity vectors */
bip = bio_integrity_alloc(bio, GFP_NOIO, nr_pages);
if (IS_ERR(bip)) {
printk(KERN_ERR "could not allocate data integrity bioset\n");
kfree(buf);
status = BLK_STS_RESOURCE;
goto err_end_io;
}
bip->bip_flags |= BIP_BLOCK_INTEGRITY;
bip->bip_iter.bi_size = len;
bip_set_seed(bip, bio->bi_iter.bi_sector);
if (bi->flags & BLK_INTEGRITY_IP_CHECKSUM)
bip->bip_flags |= BIP_IP_CHECKSUM;
/* Map it */
offset = offset_in_page(buf);
for (i = 0 ; i < nr_pages ; i++) {
int ret;
bytes = PAGE_SIZE - offset;
if (len <= 0)
break;
if (bytes > len)
bytes = len;
ret = bio_integrity_add_page(bio, virt_to_page(buf),
bytes, offset);
if (ret == 0) {
printk(KERN_ERR "could not attach integrity payload\n");
status = BLK_STS_RESOURCE;
goto err_end_io;
}
if (ret < bytes)
break;
buf += bytes;
len -= bytes;
offset = 0;
}
/* Auto-generate integrity metadata if this is a write */
// 对于写入需要调用相应方法生成完整性数据
if (bio_data_dir(bio) == WRITE) {
bio_integrity_process(bio, &bio->bi_iter,
bi->profile->generate_fn);
} else {
bip->bio_iter = bio->bi_iter;
}
return true;
err_end_io:
bio->bi_status = status;
bio_endio(bio);
return false;
}如果校验完整性出现错误,那么可以提前感知到软件数据破坏,整体上提高系统的可靠性,更多的细节不再了解。
plug ※4 蓄流
我们前面说到,bio的设计天然就是可合并的,但是如果来了一个bio我们马上就去处理了,也就是说我们的“bio池子”里面永远只有一个bio的话,那拿什么东西来做合并呢?因此块设备层使用了一种称为“蓄流/泄流”(Plugging/Unplugging)的技术来改进吞吐率。
我们相当于使用了一个蓄水池将bio阻塞一段时间,使得我们的池子里面有多个bio,而一部分lba连续的bio就有可能被合并,减少下发的io数量,提高整体吞吐率。
在以前的linux版本中,当一个块设备的请求队列开启了蓄流,它将会有一个泄流定时器,根据所设置的unplug_delay来定时的泄流,服务kblockd_workqueue工作队列的kblockd内核线程被唤醒,执行对应q->unplug_work函数,执行泄流操作,这个函数中又会调用对应q->requst_fn函数,这个函数被设计来处理掉请求队列中的所有请求。
但是在当前blk-mq机制下,经过查阅源码,已经不这么玩了。
当前机制下,调用blk_start_plug函数来初始化一个blk_plug,这个函数向块层指示出调用方打算批量提交多个IO请求的意图,块层可以根据这个提示,将调用方的IO请求推迟到调用blk_finish_plug()函数之前。但是块层在一些特殊的情况下也能提前提交请求:
plug的io数量超过最大值;
io大小超过最大值。
anyway,现在常见的蓄流泄流方式就像:
int blkdev_issue_discard(struct block_device *bdev, sector_t sector,
sector_t nr_sects, gfp_t gfp_mask, unsigned long flags)
{
struct bio *bio = NULL;
struct blk_plug plug;
int ret;
blk_start_plug(&plug);
ret = __blkdev_issue_discard(bdev, sector, nr_sects, gfp_mask, flags,
&bio);
if (!ret && bio) {
ret = submit_bio_wait(bio);
if (ret == -EOPNOTSUPP)
ret = 0;
bio_put(bio);
}
blk_finish_plug(&plug);
return ret;
}blk_start_plug和blk_finish_plug总是配对使用的。实际执行时,最终调用blk_mq_flush_plug_list函数将请求提交到IO调度队列中。
void blk_finish_plug(struct blk_plug *plug)
{
if (plug != current->plug)
return;
blk_flush_plug_list(plug, false);
current->plug = NULL;
}
void blk_flush_plug_list(struct blk_plug *plug, bool from_schedule)
{
flush_plug_callbacks(plug, from_schedule);
if (!list_empty(&plug->mq_list))
blk_mq_flush_plug_list(plug, from_schedule);
}
void blk_mq_flush_plug_list(struct blk_plug *plug, bool from_schedule)
{
LIST_HEAD(list);
if (list_empty(&plug->mq_list))
return;
list_splice_init(&plug->mq_list, &list);
if (plug->rq_count > 2 && plug->multiple_queues)
list_sort(NULL, &list, plug_rq_cmp);
plug->rq_count = 0;
do {
struct list_head rq_list;
struct request *rq, *head_rq = list_entry_rq(list.next);
struct list_head *pos = &head_rq->queuelist; /* skip first */
struct blk_mq_hw_ctx *this_hctx = head_rq->mq_hctx;
struct blk_mq_ctx *this_ctx = head_rq->mq_ctx;
unsigned int depth = 1;
list_for_each_continue(pos, &list) {
rq = list_entry_rq(pos);
BUG_ON(!rq->q);
if (rq->mq_hctx != this_hctx || rq->mq_ctx != this_ctx)
break;
depth++;
}
list_cut_before(&rq_list, &list, pos);
trace_block_unplug(head_rq->q, depth, !from_schedule);
blk_mq_sched_insert_requests(this_hctx, this_ctx, &rq_list,
from_schedule);
} while(!list_empty(&list));
}可以看到蓄流的结果最终调用blk_mq_sched_insert_requests函数进入到io调度环节。
在蓄流过程中,可能发生一次合并,例如上面的blk_mq_submit_bio函数中,就先调用了blk_attempt_plug_merge函数,尝试进行了合并操作。
blk_attempt_plug_merge函数最终将会调用:
static enum bio_merge_status blk_attempt_bio_merge(struct request_queue *q,
struct request *rq,
struct bio *bio,
unsigned int nr_segs,
bool sched_allow_merge)
{
if (!blk_rq_merge_ok(rq, bio))
return BIO_MERGE_NONE;
switch (blk_try_merge(rq, bio)) {
case ELEVATOR_BACK_MERGE: // 向后合并
if (!sched_allow_merge || blk_mq_sched_allow_merge(q, rq, bio))
return bio_attempt_back_merge(rq, bio, nr_segs);
break;
case ELEVATOR_FRONT_MERGE: // 向前合并
if (!sched_allow_merge || blk_mq_sched_allow_merge(q, rq, bio))
return bio_attempt_front_merge(rq, bio, nr_segs);
break;
case ELEVATOR_DISCARD_MERGE: // DISCARD方式合并
return bio_attempt_discard_merge(q, rq, bio);
default:
return BIO_MERGE_NONE;
}
return BIO_MERGE_FAILED;
}
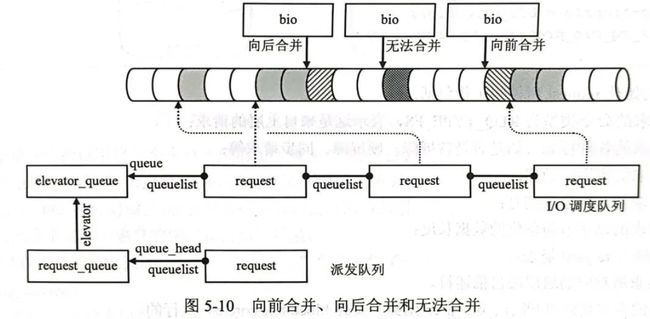
enum elv_merge blk_try_merge(struct request *rq, struct bio *bio)
{
if (blk_discard_mergable(rq))
return ELEVATOR_DISCARD_MERGE;
else if (blk_rq_pos(rq) + blk_rq_sectors(rq) == bio->bi_iter.bi_sector)
return ELEVATOR_BACK_MERGE;
else if (blk_rq_pos(rq) - bio_sectors(bio) == bio->bi_iter.bi_sector)
return ELEVATOR_FRONT_MERGE;
return ELEVATOR_NO_MERGE;
}分别对应于如下的情况: