Matlab中textscan函数用法
目录
语法
说明
示例
读取浮点数
读取不同类型的数据
删除字面文本
跳过每行的其余部分
指定分隔符和空值转换
指定要视为空或注释的文本
将重复的分隔符视为一个分隔符
指定重复的转换设定符并收集数值数据
读取或跳过引用文本和数值字段
读取外语日期
读取非默认的控制字符
恢复扫描
输入参数
输出参数
textscan函数的功能是从文本文件或字符串读取格式化数据。
语法
C = textscan(fileID,formatSpec)
C = textscan(fileID,formatSpec,N)
C = textscan(chr,formatSpec)
C = textscan(chr,formatSpec,N)
C = textscan(___,Name,Value)
[C,position] = textscan(___)说明
- C = textscan(fileID,formatSpec) 将已打开的文本文件中的数据读取到元胞数组 C。该文本文件由文件标识符fileID指示。使用 fopen 可打开文件并获取fileID值。完成文件读取后,请调用fclose(fileID) 来关闭文件。
- textscan 尝试将文件中的数据与formatSpec中的转换设定符匹配。textscan函数在整个文件中按formatSpec重复扫描数据,直至formatSpec找不到匹配的数据时才停止。
- C = textscan(fileID,formatSpec,N) 按 formatSpec 读取文件数据 N 次,其中 N 是一个正整数。要在N个周期后从文件读取其他数据,请使用原 fileID 再次调用textscan进行扫描。如果通过调用具有相同文件标识符 (fileID) 的textscan恢复文件的文本扫描,则 textscan 将在上次终止读取的点处自动恢复读取。
- C = textscan(chr,formatSpec) 将字符向量 chr 中的文本读取到元胞数组 C 中。从字符向量读取文本时,对 textscan 的每一次重复调用都会从开头位置重新开始扫描。要从上次位置重新开始扫描,需要指定 position 输出参数。
- textscan 尝试将字符向量 chr 中的数据与 formatSpec 中指定的格式匹配。
- C = textscan(chr,formatSpec,N) 按 formatSpec N 次,其中 N 是一个正整数。
C = textscan(___,Name,Value) 使用一个或多个 Name,Value 对组参数以及上述语法中的任何输入参数来指定选项。
- [C,position] = textscan(___) 在扫描结束时返回文件或字符向量中的位置作为第二个输出参数。对于文件,该值等同于调用 textscan 后再运行 ftell(fileID) 所返回的值。对于字符向量,position指示 textscan 读取了多少个字符。
示例
读取浮点数
读取包含浮点数的字符向量。
chr = '0.41 8.24 3.57 6.24 9.27';
C = textscan(chr,'%f');formatSpec中的设定符 '%f'指示textscan将chr中的每个字段与一个双精度浮点数进行匹配。
显示元胞数组 C 的内容。
celldisp(C)
C{1} =
0.4100
8.2400
3.5700
6.2400
9.2700读取相同字符向量,将每个值截短至一位小数。
C = textscan(chr,'%3.1f %*1d');设定符 %3.1f 指示字段宽度为 3 位数,精度为 1。textscan 函数读取全部 3 位数,包括小数点和小数点后的 1 位数。设定符 %*1d 指示 textscan 跳过其余位数。
显示元胞数组 C 的内容。
读取不同类型的数据
加载数据文件,并读取具有适当类型的每一列。
加载文件 scan1.dat 并在文本编辑器中预览其内容。屏幕截图如下所示。
filename = fullfile(matlabroot,'examples','matlab','scan1.dat');
打开文件,用正确的转换设定符读取每一列。textscan 返回一个 1-by-9 元胞数组 C。
fileID = fopen(filename);
C = textscan(fileID,'%s %s %f32 %d8 %u %f %f %s %f');
fclose(fileID);
whos C
Name Size Bytes Class Attributes
C 1x9 2249 cell 查看C中的每个元胞的 MATLAB® 数据类型。
C
C=1×9 cell
Columns 1 through 5
{3x1 cell} {3x1 cell} {3x1 single} {3x1 int8} {3x1 uint32}
Columns 6 through 9
{3x1 double} {3x1 double} {3x1 cell} {3x1 double}检查各个条目。请注意,C{1} 和 C{2} 为元胞数组。C{5} 的数据类型为 uint32,因此 C{5} 的前两个元素为 32 位无符号整数的最大值或 intmax('uint32')。
celldisp(C)
C{1}{1} =
09/12/2005
C{1}{2} =
10/12/2005
C{1}{3} =
11/12/2005
C{2}{1} =
Level1
C{2}{2} =
Level2
C{2}{3} =
Level3
C{3} =
12.3400
23.5400
34.9000
C{4} =
45
60
12
C{5} =
4294967295
4294967295
200000
C{6} =
Inf
-Inf
10
C{7} =
NaN
0.0010
100.0000
C{8}{1} =
Yes
C{8}{2} =
No
C{8}{3} =
No
C{9} =
5.1000 + 3.0000i
2.2000 - 0.5000i
3.1000 + 0.1000i删除字面文本
从前一示例的第二列数据的每个字段中删除字面文本 'Level'。下面显示文件的预览。

打开文件,并匹配 formatSpec 输入中的字面文本。
filename = fullfile(matlabroot,'examples','matlab','scan1.dat');
fileID = fopen(filename);
C = textscan(fileID,'%s Level%d %f32 %d8 %u %f %f %s %f');
fclose(fileID);
C{2}
ans = 3x1 int32 column vector
1
2
3
查看 C 中的第二个元胞的 MATLAB® 数据类型。1-by-9 元胞数组 C 的第二个元胞的数据类型现在为 int32。
disp( class(C{2}) )
int32跳过每行的其余部分
将前一示例中文件的第一列读取到元胞数组中,跳过行的其余部分。
filename = fullfile(matlabroot,'examples','matlab','scan1.dat');
fileID = fopen(filename);
dates = textscan(fileID,'%s %*[^\n]');
fclose(fileID);
dates{1}
ans = 3x1 cell array
{'09/12/2005'}
{'10/12/2005'}
{'11/12/2005'}textscan 返回一个日期元胞数组。
指定分隔符和空值转换
加载文件 data.csv 并在文本编辑器中预览其内容。屏幕截图如下所示。请注意该文件包含逗号分隔的数据以及空值。

读取该文件,将空元胞转换为 -Inf。
filename = fullfile(matlabroot,'examples','matlab','data.csv');
fileID = fopen(filename);
C = textscan(fileID,'%f %f %f %f %u8 %f',...
'Delimiter',',','EmptyValue',-Inf);
fclose(fileID);
column4 = C{4}, column5 = C{5}
column4 = 2×1
4
-Inf
column5 = 2x1 uint8 column vector
0
11
textscan 返回 1-by-6 元胞数组 C。textscan 函数将 C{4} 中的空值转换为 -Inf,其中 C{4} 与浮点格式关联。因为 MATLAB® 将无符号整数-Inf表示为 0,所以textscan将 C{5} 中的空值转换为 0 而不是 -Inf。
指定要视为空或注释的文本
加载文件 data2.csv并在文本编辑器中预览其内容。屏幕截图如下所示。请注意,该文件包含可以解释为注释和其他项(如 'NA' 或 'na')的数据,这些数据可能表示空字段。
filename = fullfile(matlabroot,'examples','matlab','data2.csv');
指定textscan应视为注释或空值的输入,并将该数据扫描到 C 中。
fileID = fopen(filename);
C = textscan(fileID,'%s %n %n %n %n','Delimiter',',',...
'TreatAsEmpty',{'NA','na'},'CommentStyle','//');
fclose(fileID);显示输出。
celldisp(C)
C{1}{1} =
abc
C{1}{2} =
def
C{2} =
2
NaN
C{3} =
NaN
5
C{4} =
3
6
C{5} =
4
7
将重复的分隔符视为一个分隔符
加载文件 data3.csv
filename = fullfile(matlabroot,'examples','matlab','data3.csv');
要将重复的逗号视为单个分隔符,请使用 MultipleDelimsAsOne 参数并将值设置为 1 (true)。
fileID = fopen(filename);
C = textscan(fileID,'%f %f %f %f','Delimiter',',',...
'MultipleDelimsAsOne',1);
fclose(fileID);
celldisp(C)
C{1} =
1
5
C{2} =
2
6
C{3} =
3
7
C{4} =
4
8
指定重复的转换设定符并收集数值数据
加载此示例的数据文件 grades.txt并在文本编辑器中预览其内容。屏幕截图如下所示。请注意,该文件包含重复的分隔符。
filename = fullfile(matlabroot,'examples','matlab','grades.txt');
使用格式 '%s' 四次读取列标题。
fileID = fopen(filename);
formatSpec = '%s';
N = 4;
C_text = textscan(fileID,formatSpec,N,'Delimiter','|');读取文件中的数值数据。
C_data0 = textscan(fileID,'%d %f %f %f')
C_data0=1×4 cell
{4x1 int32} {4x1 double} {4x1 double} {4x1 double}CollectOutput 的默认值是 0 (false),因此 textscan 以一个单独的数组返回每列数值数据。
将文件位置指示符设置为文件的开头。
frewind(fileID);重新读取文件并将 CollectOutput 设置为 1 (true),将相同类的连续列收集到一个单独的数组中。可以使用 repmat 函数指示 %f 转换设定符必须出现三次。当一种格式重复多次时,此方法很有用。
C_text = textscan(fileID,'%s',N,'Delimiter','|');
C_data1 = textscan(fileID,['%d',repmat('%f',[1,3])],'CollectOutput',1)
C_data1=1×2 cell
{4x1 int32} {4x3 double}测试分数(均为 double)被收集到一个单独的 4×3 数组中。
关闭文件。
fclose(fileID);读取或跳过引用文本和数值字段
读取文本文件的第一列数据和最后一列数据。跳过文本列和整数数据列。
加载文件 names.txt 并在文本编辑器中预览其内容。屏幕截图如下所示。请注意,该文件包含两列带引号的文本,后跟一个整数列,最后一列为浮点数。
filename = fullfile(matlabroot,'examples','matlab','names.txt');
读取该文件中的第一列数据和最后一列数据。使用转换设定符 %q 读取由双引号 (") 引起来的文本。%*q 跳过引用文本,%*d 跳过整数字段,而 %f 读取浮点数。使用 'Delimiter' 名称-值对组参数指定逗号分隔符。
fileID = fopen(filename,'r');
C = textscan(fileID,'%q %*q %*d %f','Delimiter',',');
fclose(fileID);显示输出。textscan 返回元胞数组 C,其中删除了文本前后的双引号。
celldisp(C)
C{1}{1} =
Smith, J.
C{1}{2} =
Bates, G.
C{1}{3} =
Curie, M.
C{1}{4} =
Murray, G.
C{1}{5} =
Brown, K.
C{2} =
71.1000
69.3000
64.1000
133.0000
64.9000读取外语日期
加载文件 german_dates.txt 并在文本编辑器中预览其内容。屏幕截图如下所示。请注意,第一列值包含德语的日期,第二列和第三列是数值。
filename = fullfile(matlabroot,'examples','matlab','german_dates.txt');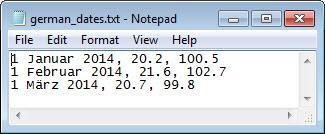
打开文件。将与文件关联的字符编码方案指定为 fopen 的最后输入。
fileID = fopen(filename,'r','n','ISO-8859-15');读取文件。使用 %{dd % MMMM yyyy}D 设定符指定文件中日期的格式。使用 DateLocale 名称-值对组参数指定日期的区域设置。
C = textscan(fileID,'%{dd MMMM yyyy}D %f %f',...
'DateLocale','de_DE','Delimiter',',');
fclose(fileID);查看 C 中第一个元胞的内容。日期以 MATLAB 使用的语言显示,具体取决于您的系统区域设置。
C{1}
ans = 3x1 datetime array
01 January 2014
01 February 2014
01 March 2014 读取非默认的控制字符
使用sprintf转换数据中的非默认转义序列。
创建包含换页符 \f 的文本。随后,要使用textscan读取文本,请调用sprintf显式转换换页符。
lyric = sprintf('Blackbird\fsinging\fin\fthe\fdead\fof\fnight');
C = textscan(lyric,'%s','delimiter',sprintf('\f'));
C{1}
ans = 7x1 cell array
{'Blackbird'}
{'singing' }
{'in' }
{'the' }
{'dead' }
{'of' }
{'night' }
textscan 返回元胞数组 C。
恢复扫描
从开头以外的位置恢复扫描。
如果恢复文本扫描,textscan 每次都会从开头读取。要从任何其他位置恢复扫描,请在 textscan 的初始调用中使用双输出参数语法。
例如,创建一个名为 lyric 的字符向量。读取该字符向量的第一个词,然后恢复扫描。
lyric = 'Blackbird singing in the dead of night';
[firstword,pos] = textscan(lyric,'%9c',1);
lastpart = textscan(lyric(pos+1:end),'%s');输入参数
fileID- 文件标识符
数值标量
已打开的文本文件的文件标识符,指定为数值。使用 textscan 读取文件之前,必须使用 fopen 打开文件并获取 fileID。
formatSpec- 数据字段的格式
字符向量 | 字符串
数据字段的格式,指定为由一个或多个转换设定符组成的字符向量或字符串。textscan在读取输入时,会尝试将数据与formatSpec中指定的格式进行匹配。如果 textscan未能匹配数据字段,它将会停止读取并在出错前返回读取的所有字段。
转换设定符的数量确定输出数组 C 中元胞的数量。
数值字段
下表列出了可用于数值输入的转换设定符。
| 数值输入类型 | 转换设定符 | 输出类 |
|---|---|---|
| 有符号整数 | %d |
int32 |
%d8 |
int8 |
|
%d16 |
int16 |
|
%d32 |
int32 |
|
%d64 |
int64 |
|
| 无符号整数 | %u |
uint32 |
%u8 |
uint8 |
|
%u16 |
uint16 |
|
%u32 |
uint32 |
|
%u64 |
uint64 |
|
| 浮点数 | %f |
double |
%f32 |
single |
|
%f64 |
double |
|
%n |
double |
非数值字段
下表列出了可用于包含非数值字符的输入的转换设定符。
| 非数值输入类型 | 转换设定符 | 详细信息 |
|---|---|---|
| 字符 | %c |
读取任何单个字符,包括分隔符。 |
| 文本数组 | %s |
读取为字符向量元胞数组。 |
%q |
读取为字符向量元胞数组。如果文本以双引号 ( 示例: |
|
| 日期和时间 | %D |
以与上面的 |
%{ |
以与上面的 有关日期时间显示格式的详细信息,请参阅日期时间数组的Format 属性。 示例: |
|
| 持续时间 | %T |
以与上面的 |
%{ |
以与上面的 有关持续时间显示格式的详细信息,请参阅持续时间数组的Format 属性。 示例: |
|
| 类别 | %C |
以与 |
| 模式匹配 | %[...] |
将方括号中的字符读取为字符向量元胞数组,直到遇到第一个不匹配的字符。要在集合中包括 示例: |
%[^...] |
排除方括号中的字符,直到读取到第一个匹配的字符。要排除 示例: |
可选运算符
formatSpec 中的转换设定符可以包含按以下顺序显示的可选运算符(包含为了表达清晰而保留的空格):

可选运算符包括:
-
要忽略的字段和字符
textscan按顺序读取文件中的所有字符,除非要求它忽略特定字段或字段中的某一部分。
在百分比字符 (%) 之后插入星号字符 (*),可跳过某个字段或字符字段中的某一部分。
运算符
采取的操作
%*k 跳过字段。k 是标识要跳过的字段的任何转换设定符。textscan 不会为任何此类字段创建输出元胞。
示例:'%s %*s %s %s %*s %*s %s'(空格为可选项)将文本
'Blackbird singing in the dead of night' 转换为四个输出元胞,即
'Blackbird' 'in' 'the' 'night''%*ns' 跳过 n 个字符,其中 n 是小于或等于字段中字符数的一个整数。
示例:'%*3s %s' 将 'abcdefg' 转换为 'defg'。如果分隔符为逗号,则同一分隔符将 'abcde,fghijkl' 转换为包含 'de';'ijkl' 的元胞数组。
'%*nc' 跳过 n 个字符,包括分隔符。
-
字段宽度
textscan读取字段宽度或精度指定的字符数或位数,或者读到第一个分隔符,以先出现者为准。小数点、符号(+ 或 -)、指数字符以及数字指数中的数字计为字段宽度中的字符和数字。对于复数,字段宽度指的是实部和虚部的各自宽度。对于虚部,字段宽度包括 + 或 −,但不包括 i 或 j。通过在转换设定符中的百分号 (%) 之后插入数字来指定字段宽度。
示例:%5f 将 '123.456' 读作 123.4。
示例:%5c 将 'abcdefg' 读作 'abcde'。
当字段宽度操作符与单个字符 (%c) 一起使用时,textscan 也会读取分隔符、空白和行尾字符。
示例:%7c 读取包括空白在内的 7 个字符,因此 'Day and night' 读作 'Day and'。 -
精度
对于浮点数(%n、%f、%f32、%f64),可以指定要读取的小数位数。
示例:%7.2f 将 '123.456' 读作 123.45。
-
要忽略的字面文本
textscan 忽略追加到 formatSpec 转换设定符的文本。
示例:Level%u8 将 'Level1' 读作 1。
示例:%u8Step 将 '2Step' 读作 2。
N- 要应用formatSpec的次数Inf(默认) | 正整数
要应用formatSpec的次数,指定为正整数。
chr- 输入文本
字符向量 | 字符串
要读取的输入文本。
名称-值对组参数
指定可选的、以逗号分隔的 Name,Value 对组参数。Name 为参数名称,Value 为对应的值。Name 必须放在引号中。采用任意顺序指定多个名称-值对组参数,如 Name1,Value1,...,NameN,ValueN 所示。
示例: C = textscan(fileID,formatSpec,'HeaderLines',3,'Delimiter',',') 跳过数据的前三行,然后读取其余数据,并将逗号视为分隔符。
名称不区分大小写。
确定数据串联的逻辑指示符,指定为由 'CollectOutput' 和 true/false 组成的逗号分隔对组。如果为 true,则导入函数会将同一 MATLAB® 基础类的连续输出元胞串联为单个数组。
用于指定要忽略的文本的符号,指定为逗号分隔的对组,其中包含 'CommentStyle' 和一个字符向量、字符向量元胞数组、字符串或字符串数组。
例如,指定一个字符(如 '%')以忽略同一行上此符号后面的文本。指定一个包含两个字符向量的元胞数组(如 {'/*','*/'}),以忽略这些序列之间的任何文本。
MATLAB 仅检查位于每个字段开头而不是字段中的注释。
示例: 'CommentStyle',{'/*','*/'}
'DateLocale'- 用于读取日期的区域设置
字符向量 | 字符串
用于读取日期的区域设置,指定为逗号分隔的对组,包含 'DateLocale' 和 xx_YY 格式的字符向量,其中 xx 是用于指定语言的小写 ISO 639-1 双字母代码,YY 是用于指定国家/地区的大写 ISO 3166-1 alpha-2 代码。有关区域设置的常见值的列表,请参阅datatime函数的 Locale 名称-值对组参数。
使用 DateLocale 指定 textscan 在使用 %D 格式设定符将文本以日期形式读取时,应采用何种区域设置来解释月份和星期名称以及缩写。
示例: 'DateLocale','ja_JP'
'Delimiter'- 字段分隔符
字符向量 | 字符向量元胞数组 | 字符串 | 字符串数组
字段分隔符,指定为由 'Delimiter' 以及一个字符向量或字符向量元胞数组组成的逗号分隔对组。在字符向量元胞数组中指定多个分隔符。
示例: 'Delimiter',{';','*'}
textscan 将重复的分隔符字符解释为多个分隔符,并向输出元胞返回一个空值。
在每一行数据中,默认字段分隔符是空白。空白可以是空格 (' ')、退格符 ('\b') 或制表符 ('\t') 的任意组合。如果未指定分隔符,则:
-
分隔符与空白字符相同。默认的空白字符为 ' '、'\b' 和 '\t'。使用 'Whitespace' 名称-值对组参数指定替代的空白字符。
-
textscan 将重复的空白字符解释为单个分隔符。
当以下转义序列之一指定为分隔符时,textscan将该序列转换成对应的控制字符:
\b |
退格符 |
\n |
换行符 |
\r |
回车符 |
\t |
制表符 |
\\ |
反斜杠 (\) |
NaN(默认) | 标量
被分隔的文本文件中空数值字段的返回值,指定为由 'EmptyValue' 和一个标量组成的逗号分隔对组。
行尾字符,指定为由 'EndOfLine' 和一个字符向量或字符串组成的逗号分隔对组。该字符向量必须为 '\r\n',或须指定单个字符。常用的行尾字符是换行符 ('\n') 或回车符 ('\r')。如果指定 '\r\n',则导入函数会将 \r 或 \n 以及两者的组合 (\r\n) 视为行尾字符。
默认的行尾序列是 \n、\r 或 \r\n,具体取决于文件的内容。
如果文件最后一行的结尾有缺失值和行尾序列,则导入函数会对这些字段返回空值。这样可确保输出元胞数组 C 中的各个元胞的大小相同。
示例: 'EndOfLine',':'
指数字符,指定为由 'ExpChars' 和一个字符向量或字符串组成的逗号分隔对组。默认的指数字符为 e、E、d 和 D。
'HeaderLines'- 标题行数0(默认) | 正整数
标题行数,指定为由 'HeaderLines' 和一个正整数组成的逗号分隔对组。textscan 会跳过标题行,包括当前行的剩余部分。
多分隔符处理,指定为由 'MultipleDelimsAsOne' 和 true/false 组成的逗号分隔对组。如果为 true,则导入函数将连续分隔符当作一个分隔符处理。由空白分隔的重复分隔符也被当作一个分隔符处理。还必须指定 Delimiter 选项。
示例: 'MultipleDelimsAsOne',1
'ReturnOnError'- 当textscan未能读取或转换数据时的行为1 (true)(默认) |0 (false)
当textscan未能读取或转换数据时的行为,指定为由 'ReturnOnError' 和 true/false 组成的逗号分隔对组。如果是true,则textscan终止,不产生错误,返回所有读取的字段。如果是false,则textscan终止,产生错误,不返回输出元胞数组。
'TreatAsEmpty'- 要作为空值处理的占位符文本
字符向量 | 字符向量元胞数组 | 字符串 | 字符串数组
要作为空值处理的占位符文本,指定为逗号分隔的对组,其中包含 'TreatAsEmpty' 和一个字符向量、字符向量元胞数组、字符串或字符串数组。此选项仅适用于数值字段。
'Whitespace'- 空白字符' \b\t'(默认) | 字符向量 | 字符串
空白字符,指定为由 'Whitespace' 和一个字符向量或字符串(包含一个或多个字符)组成的逗号分隔对组。textscan将空格字符 char(32) 添加到任何指定的Whitespace,除非Whitespace为空 ('') 并且formatSpec包含任何转换设定符。
当下面一个转义序列指定为任意空白字符时,textscan 会将该序列转换成对应的控制字符:
\b |
退格符 |
\n |
换行符 |
\r |
回车符 |
\t |
制表符 |
\\ |
反斜杠 (\) |
'TextType'- 文本的输出数据类型'char'(默认) |'string'
文本的输出数据类型,指定为逗号分隔的对组,其中包含 'TextType' 和 'char' 或 'string'。如果指定值 'char',textscan 将以字符向量元胞数组的形式返回文本。如果指定值 'string',textscan 将以 string 类型的数组形式返回文本。
输出参数
C- 文件或文本数据
元胞数组
文件或文本数据,以元胞数组形式返回。
对于 formatSpec 中的每个数值转换设定符,textscan 函数将一个 K×1 MATLAB 数值向量返回给输出元胞数组 C,其中 K 是 textscan 查找与此设定符匹配的字段的次数。
对于 formatSpec 中的每个文本转换设定符(%s、%q 或 %[...]),textscan 函数都返回一个 K×1 字符向量元胞数组,其中 K 是 textscan 查找与此设定符匹配的字段的次数。对于包含字段宽度操作符的每个字符转换,textscan 返回一个 K×M 字符数组,其中 M 是字段宽度。
对于 formatSpec 中的每个日期时间或分类转换设定符,textscan 函数将一个 K×1 日期时间或分类向量返回给输出元胞数组 C,其中 K 是 textscan 查找与此设定符匹配的字段的次数。
position- 文件或字符向量中的位置
整数
扫描结束时在文件或字符向量中的位置,以 double 类的整数形式返回。对于文件,该值等同于调用 textscan 后运行 ftell(fileID) 所返回的值。对于字符向量,position 指示 textscan 读取了多少个字符。
算法
textscan根据关于溢出、截断和使用 NaN、Inf 及 -Inf 的 MATLAB 规则将数值字段转换为指定的输出类型。例如,MATLAB 将整数 NaN 表示为零。如果textscan发现空白字段与整数格式设定符(如 %d 或 %u)相关联,则将空值作为零返回,而不是作为 NaN。
在将数据匹配到文本转换设定符时,textscan会一直读取到发现分隔符或行尾字符为止。在将数据匹配到数值转换设定符时,textscan会一直读取到发现非数值字符为止。如果textscan无法再将数据匹配到特定的转换设定符,它会尝试将数据匹配到formatSpec中的下一个转换设定符。符号(+ 或 -)、指数字符和小数点视为数值字符。
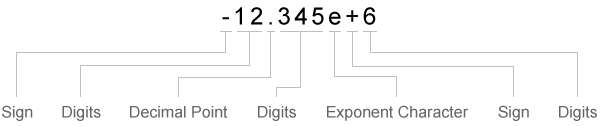
| 符号 | 数字 | 小数点 | 数字 | 指数字符 | 符号 | 数字 |
|---|---|---|---|---|---|---|
| 读取一个符号字符(如果存在)。 | 读取一个或多个数字。 | 读取一个小数点(如果存在)。 | 如果存在小数点,则读取紧跟小数点后的一个或多个数字。 | 读取一个指数字符(如果存在)。 | 如果存在指数字符,则读取一个符号字符。 | 如果存在指数字符,则读取该字符后面的一个或多个数字。 |
textscan将任何复数作为一个整体导入到复数字段中,将实部和虚部转换为指定的数字类型(如 %d 或 %f)。复数的有效形式如下:
± |
示例: |
± |
示例: |
不要在复数中包含嵌入的空白。textscan 将嵌入的空白解释为字段分隔符。