UE4 优化
目录
1. 材质
2. 静止光线
3. 顶点/网格:
4. 渲染相关:
5. 特殊的性能提升建议
6. 代码编译优化
7. 灯光优化
8. 阴影优化
9. 材质优化
10. 植被优化
11. 物理与碰撞优化
12. 动画优化
13. UI优化
14. 位移优化
15. 特效优化
16. AI优化
17. Dedicated Server优化
1. 材质
(1)纹理采样器:减少数量优化;
(2)mip map:优化大纹理远距离小部分采样。
2. 静止光线
(1)重叠:(大于等于5个的静止光线重叠,拥有最小半径的静止光线会开始投射动态阴影)
3. 顶点/网格:
(1)使用DCC工具或者UE4支持的网格简化工具来减少网格中的顶点数量。
(2)网格合并拆分:有功能性拆分,无功能性合并;(防止单独处理变换和碰撞)
(3)经常不可见,不可见之前不执行:Components.Add()方法,这样可以节省许多处理器周期;
RegisterComponent()方法,避免每帧更新;
(4)不需要碰撞:ChildMeshComponent > SetCollisionProfileName ( UCollisionProfile :: NoCollision_ProfileName );
(5)不需要重叠:MeshComponent > bGenerateOverlapEvents = false;
(6)统一用父级边界检测:ChildMeshComponent > bUseAttachParentBound = true ;
(7)避免网格单独打光:bLightAttachmentsAsGroup为true,你可以选择在你的对象的每个网格中使用相同的间接照明缓存信息,这会节省独立更新网格的时间。
4. 渲染相关:
(1)查看渲染系统决定不绘制的初始量的数量:Frustum Culled初始量值
查看方式一:视口左上角▼—>stat—>Advance—>…
方式二:命令ToggleDebugCamera,快捷键F
(2)性能可视化工具
(2.1)线框视图模式
可以告诉你场景和独立网格中有多少顶点和三角形
快捷键:F1;
命令:viewmode wireframe
(2.2)着色器复杂性可视化
当你的场景中存在很多材质时,可能很难确定哪些是复杂的;
快捷键:F5
命令:viewmode shadercomplexity
这里的暗绿色区域比浅绿色区域含有更复杂的着色程序逻辑,红色和白色区域也仍有更加复杂的着色逻辑。着色复杂性最大的原因通常是:当多重透明材质重叠时,需要为所有重叠区域计算着色。
材质编辑器中,stats,查看
1)着色器的说明数量:减少数量可优化性能;
2)纹理缓存:纹理采样器过多,增加写入写出负担;可减少纹理采样器数量优化;
3)锥形纹理技术(mip map):优化大纹理远距离小部分采样。(
Detail Of Level —>Mip Gen Settings)
(2.3)光线复杂度视图模式
显示了影响你的几何图形的非静态光线的数量;
快捷键:F9
按键:视口左上角▼—>Light Complexity
一个光线可以被剔除的方式有很多,包括半径削减、z型交叉、摄像头背对光源、光函数是0等等;
(2.4)静止光线重叠视图模式
静止光线重叠视图模式用红色显示了哪些静止光线正被迫移动。
按键:视口左上角▼—>Stationary Light Overlay
静止光线一次最多只允许4次重叠。一旦你有了大于等于5个的静止光线重叠,拥有最小半径的那个静止光线会开始投射动态阴影,这会产生很高的性能代价。
(2.5)其他Stats视图
在Window>Statistics菜单中有一些其他统计数据视图:
(2.5.1)纹理Stats (检查大纹理及使用次数优化)
工具显示了在当前关卡下使用的所有纹理,它们的分辨率、使用次数和游戏中出现的时间。如果你的场景中有高分辨率的纹理并且没有被很多使用次或者不常见,它们不仅会占据很多不必要的内存,而且也会造成GPU处理缓慢,增加GPU渲染场景花费的时间。
(2.5.2)初始量Stats(检查线框细节,顶点数量优化)
许多有用信息,开始是在你的骨骼网格、静态网格和场景中有多少三角形初始量。如果你在你的场景中定义了一个对象,它的三角形数量很多,试着在线框层次上观察这个角色。
可视化用来观察线框在一个正常的观察距离外是否保持着实线(或接近实线),这意味着在你的网格中你有比你需要的更多的细节,你可以使用DCC工具或者UE4支持的网格简化工具来减少网格中的顶点数量。
(3)分析器
也许在优化性能时应该熟悉的两个最重要的工具是CPU分析器和GPU分析器。(程序独立而非编辑器状态运行,屏蔽编辑器处理带来的影响)
(3.1)CPU分析器
UnrealFrontend.exe,在UE4/Engine/Binaries 文件夹中。你可以看到如下的界面,先在导航找到Session前端标签,之后找到分析器标签
准备:测试建立(Test Buid)
无论是何种原因,如果你不能完成测试建立或者烘焙(需要烘焙来让你的内容作为独立游戏来运行,这可以通过Unreal编辑器的File Menu > Cook Content for*Platform*完成,或者你可以为其他平台给你的内容打包)你的内容,你可以完成一个开发编辑器建立,带着游戏选项运行,这会为很好地为你显示不同特征的相对性能代价,但是一个含有烘焙内容的测试建立对于得到最终数据是最佳选择。
(3.2)GPU分析器
启动:
控制台输入profilegpu来启动GPU分析器或者按Ctrl+Shift+, 来启动,这会打开GPU观察器:
5. 特殊的性能提升建议
(1)合并网格 (合并:拼接模型无特殊要求合并处理;拆分:部分可见整体渲染;)
多个网格集合图形的网格可能会分别单独调用GPU来绘制,也因为UE4会为每个网格单独保存和更新变换信息,而且可能检查这些独立网格间的碰撞。所以,如果没有功能性的原因来设置单独网格的话,应该考虑在把它们引入UE4之前在DCC工具中选择合并它们。
关于合并网格反对的说法是:一个单独的网格可能不能被部分剔除,所以如果它的任何一部分是可见的,整个网格都会渲染。由于这个原因,可能把你的整个关卡都合并成一个单独网格可能不是一个好主意,但是让每一个三角形都成为一个单独网格同样也不是最理想的,所以在两种极端中取得平衡至关重要。
(2)由大量网格组成的单一对象
一些建议,来避免在这些事情上浪费不必要的CPU和GPU的周期。
- 经常不可见,不可见之前不执行:Components.Add()方法,这样可以节省许多处理器周期;RegisterComponent()方法,避免每帧更新;
- 不需要碰撞:ChildMeshComponent > SetCollisionProfileName ( UCollisionProfile ::NoCollision_ProfileName );
- 不需要重叠:MeshComponent > bGenerateOverlapEvents = false;
- 统一用父级边界检测:ChildMeshComponent > bUseAttachParentBound = true ;
- 避免网格单独打光:bLightAttachmentsAsGroup为true,你可以选择在你的对象的每个网格中使用相同的间接照明缓存信息,这会节省独立更新网格的时间。
(3)推荐的光线性能设置
动态对象的每个对象阴影可以通过不选关卡平行光中的bUseInsetShadowsForMovableObjects 的flag来禁用,这会提升性能。
在你的关卡的平行光属性中,通常减少动态阴影级联的数量不会对阴影外观产生非常大的影响,但是会提升性能,默认的是5,但是减少至大约3的样子就会产生大致差不多的效果。
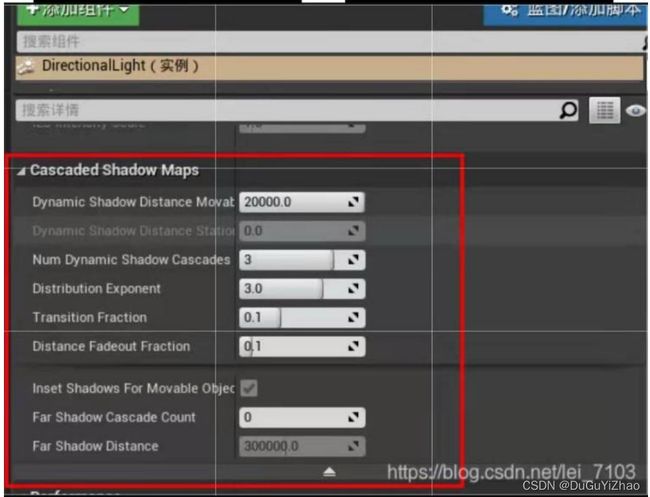
(4)动态阴影
动态阴影的代价可能很大,尤其是全局动态阴影。这是因为三角形必须得为动态阴影映射重新渲染。如果你在移动光源上需要许多动态阴影来使多边形尽可能少,如果你想要更多多边形,那就试着少用带有动态阴影的可移动光线。(可移动光线.动态阴影与多边形数量权衡)
记住,设置了4个以上的重叠固定光线会迫使半径最小的那个变成可移动的,这样就会开始投射动态阴影。固定光重叠可视化是确保没有过多重叠的好方法。
(5)限制后过程效果
后过程效果同样是代价很大的,禁用你不需要的效果也可以很大地提升性能。一些可以考虑禁用的后过程效果包括镜头闪光、土地深度和屏幕空间反射。为了提升性能,你可能也想要以低质量运行屏幕空间抗混叠,以更小的散景尺寸运行散景DOF(景深Depth of Field),因为这里的尺寸与性能是负相关的(更大的散景意味着更差的性能)。
如果最终你可以在其它系统中取得足够的性能提升,你可以之后选择性地把这些效果重新启用。
(5.1)高存储低质量影响
- 在后过程设置中禁用scene color fringe
- 禁用 ambient cubemap,用 LightmassEnvironmentColor代替
- 通过设置强度在后过程设置中禁用imagebased lens flares 。
(6)在单一镜头中限制贴花数量
如果在摄像头中同时有许多彼此接近的贴花,有时这样的代价是很大的。如果你有比如说50个贴花正同时被渲染,这对于性能可能有消极影响。试着稀释或扩散这些贴花,那么就不会有那么多贴花同时被渲染了。
贴花设置,参考:http://m.manew.com/thread-96950-1-1.html
(7)以更低分辨率和更少变形渲染
如果你想要试着以稍低的分辨率和稍少的变形进行渲染来节省性能,试着做、看看它看起来和运行起来效果如何是非常简单的。
当游戏运行时,你可以打开控制台输入“r.screenpercentage 90”,其中90是全屏尺寸和渲染的百分比。
更永久的设置方法是:选中你的后步骤列表里的“覆写屏幕百分比”框,之后将屏幕百分比设置成想要的百分比(小于等于100)。
(8)场景捕捉对象()
场景捕捉对象(如场景捕捉立方体)的默认设置是捕捉每帧。捕捉这些基本涉及到从不同视角渲染整个场景(对于一个场景捕捉立方体来说,会这做6次,每次渲染立方体的一个面),还有从玩家的视角来渲染。这样的代价明显是很大的(如果一个场景中有许多这样的对象尤其如此),所以,除非每帧都抓取它们是你的游戏的一个重要特点,抓取应该被禁用。
总体来讲,同样的原因,限制场景抓取物件的总数量是有道理的。
(9)其它涉及事项:
(9.1)设置最大和最小帧率
可以在DefaultConfig.ini文件中设置来控制这个变量,默认如下:
[/Script/Engine.Engine]bSmoothFrameRate=true MinSmoothedFrameRate=22
MaxSmoothedFrameRate=62
(9.2)禁用遮挡剔除()
对于一些特定类型的游戏,遮挡剔除可能会花费比它本身所节省的时间更多。比如:在打斗游戏中,通常场景中的所有内容都应该是被渲染的,不常见的情况是许多几何图形被其他对象遮挡,在这些情况下,使用全局预计算可见复选框也许有帮助;
(9.2.1)设置 (参考:https://docs.unrealengine.com/4.27/zh-CN/RenderingAndGraphics/VisibilityCulling/VisibilityCullingReference/)
- Project Settings -> Rendering -> Culling
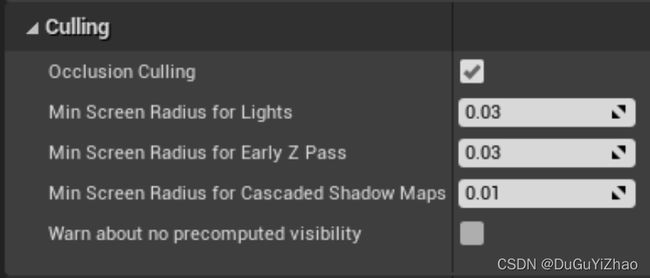
如果需要增大以屏占比基准的剔除强度(代价是剔除效果比较突兀)以提升渲染效率,将以上三个数值属性值增大;
- Actor:设置按实例距离,或者是否使用剔除距离体积来剔除Actor:
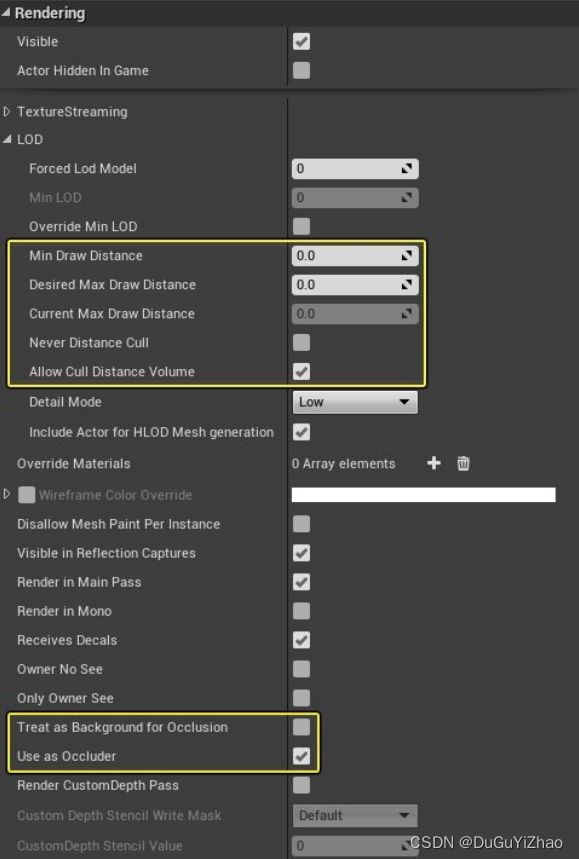
- 剔除距离体积
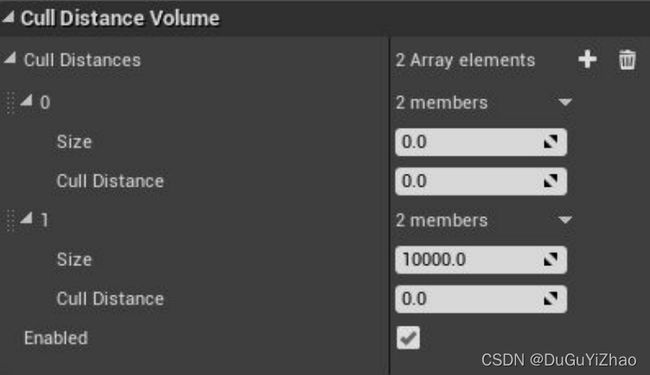
- 预计算可视性场景设置:(World Settings -> Precomputed Visibility)
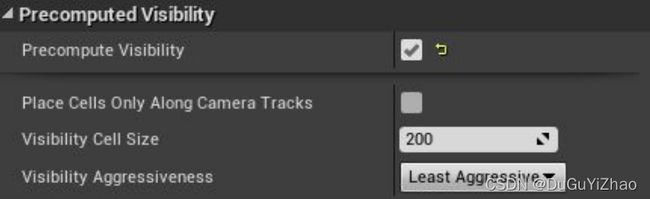
- 预计算可视性覆盖体积(通常用于移动平台)
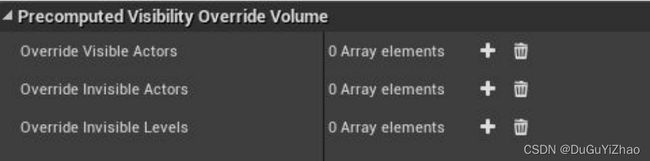
覆盖可见Actor(Override Visible Actors)
从该体积内部查看时,预计算可视性始终视为可见的Actor数组。
覆盖不可见Actor(Override Invisible Actors)
从该体积内部查看时,预计算可视性始终视为不可见的Actor数组。
覆盖不可见关卡(Override Invisible Levels)
从该体积内部查看时,预计算可视性始终视为不可见的Actor所属的关卡名称数组。
6. 代码编译优化
(1)蓝图和C++的性能差距不超过两倍。(Game模式)
蓝图转C++:参考:[UE4]蓝图转换成C++代码 - 一粒沙 - 博客园
(2)向量变换
尽量使用FTransform::TransformXXX()和FTransform::InverseTransformXXX,而不是FQuat::RotateVector和FQuat::UnrotateVector,因为前者使用了更多的当前硬件支持的矢量汇编指令,榨干了硬件性能,而后者是为了跨平台,老老实实使用C++代码来执行计算公式,虽然也调用了硬件汇编指令,但数量相对较少;
(3)VS2019:针对C++代码编译速度、以及CPUAVX/AVX2指令集下的矢量计算进行了更深入的优化;
(3.1)编译速度方面:完整编译速度,VS2019(16.2)是VS2017(15.9)的3.5倍,增量编译速度,VS2019(16.2)是VS2017(15.9)的1.6倍;
(3.2)代码优化方面:以游戏帧率作为测试标准,VS 16.2相对16.0提升了2%到3%,而16.0相对15.9最大可以提升2.8%,也就是说使用VS2019编译代码,相比VS2017,可以让游戏运行时帧率提升5%左右。
(4)断点调试UE4中的内联函数:用FORCEINLINE_DEBUGGABLE代替FORCEINLINE;
(5)代码算法优化:
(5.1)TArray清空:空间还要用时,用Reset()替代Empty(),因为前者不会销毁内存空间。
(5.2)TArray移除元素:元素顺序不关心时,用RemoveAtSwap()代替RemoveAt(),前者是用数组末尾的元素来填补内存空洞(移除元素后产生的无效内存空间),而后者是对空洞后的所有元素平移。
(5.3)单个生产者单个消费者(SPSC)的线程环境,可以使用TCircularQueue作为消息队列来保证数据安全,比使用FScopeLock消耗低,因为前者内部使用的是atomic,而非lock(虽然atomic也算一种轻量级lock)。
(6)视距裁剪(剔除)
(6.1)使用Cull Distance Volume进行细粒度的视距裁剪。Project Settings中的Occlusion Culling只能通过一个临界阀值来控制视距裁剪,而Cull Distance Volume可以设置多级裁剪参数。
7. 灯光优化
(7.1)Lightmass Importance Volume:大场景,不添加则全局构建光照贴图产生全局Indirect Lighting Cache;添加则在指定区域构建光照贴图Indirect Lighting Cache;
(7.2)Cast Volumetric Shadow
点光源和聚光灯尽量不要开启Cast Volumetric Shadow;默认只有平行光开启了此选项。开启后的性能消耗为不开启的性能消耗三倍。不开启表示阴影计算方式使用Shadow Mapping,开启表示使用Shadow Volume,前者的阴影计算没有后者精准,但是计算量小;
(7.3)体积雾与灯光配合
如果开启体积雾,建议将灯光改成静态光,这样在Build Lighting时会生成预计算的体积雾相关数据,这样可以显著提升体积雾性能。体积雾性能消耗巨大。
(7.4)静态光不用时禁用Static Lighting
(全是动态光 Movable Light 或者固定光 Stationary Light),则要禁用 Static Lighting,以节省 Static Lighting 相关的开销(比如 LightMaps和ShadowMaps的相关计算)。禁用方式:Project Settings -> Engine -> Rendering -> Lighting -> disableAllow Static Lighting。
当全动态灯光为性能瓶颈时,禁用Static Lighting可以提升性能。
(7.5)关闭Support Global clip plane for Planar Reflections,默认关闭,开启后消耗巨大。
(7.6)AO性能优化(Ambient Occlusion)
在超大型场景中,一般灯光会是性能瓶颈之一,特别是动态光场景下。此时关闭AO可以大幅提高帧率(AO默认为开启,早期版本默认是关闭的)。开启AO后(Project Settings -> Rendering -> Default Settings ->Ambient Occlusion),引擎默认的AO为SSAO(Screen Space Ambient Occlusion), SSAO无法进行预计算,所以GPU性能开销较大,可以修改为DFAO(Distance Field Ambient Occlusion)以提升性能,因为DFAO可以预计算,代价是增加显存开销;
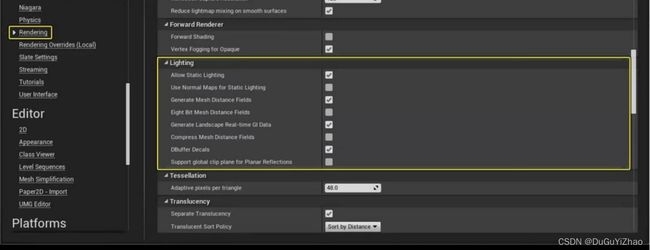
DFAO相关的两个优化选项:
- Compress Mesh Distance Fields: 通过压缩Distance Fields volume texture来减少显存占用,代价是当使用Level Streaming时会出现Hitch。
- Eight Bit Mesh Distance Fields: 将Distance Fields volume texture从16位格式压缩为8位格式,代价是AO视觉效果变粗糙;
8. 阴影优化
(8.1)使用非静态的Directional Light
(Stationary 或者 Movable),场景中有大量单位时,一定要开启Dynamic Shadow Distance(默认为0,表示关闭)。提升性能的原因:Dynamic Shadow Distance 表示在多少距离内使用动态阴影,超过这个距离之外Fade成静态阴影,而Fade成静态阴影后就可以提升性能。
(8.2)逻辑控制Cast Shadow
虽然灯光提供了属性DistanceField Shadow Distance来控制阴影根据摄像机距离投射,但是这种做法是一刀切。比如:假设性能瓶颈是大量怪物的阴影投射,远处山体和建筑的树木的阴影投射对性能影响很小,此时使用DistanceField Shadow就会导致场景的表现效果大打折扣。推荐做法是,程序逻辑上控制:如果是怪物对象,只对离摄像机一定距离内的怪物开启阴影。
物体投射阴影的开关:
void UPrimitiveComponent::SetCastShadow(bool NewCastShadow)。
9. 材质优化
(9.1)材质类型的性能,从快到慢:Opaque -> Masked -> Translucent。
(9.2)大量单位:比如500个,那么这些单位一定要做材质LOD,并尽可能多的去掉半透明材质(比如在最后两级直接去掉半透明效果),否则性能消耗呈指数级增长。
(9.3)GPUVisualizer的BasePass耗时较高,那么很大一部分原因是材质复杂度过高。
(9.4)贴花:Decal消耗和像素数量有关,程序功能绝对不要乱用贴花,美术铺场景除外。比如程序想用贴花做一个范围标记,如果当标记范围很大时绝对不要用贴花,可以改成划线或者不通透贴图。如果场景需要大量使用贴花,根据视距动态创建和销毁贴花,仅仅SetVisibility是不够的,隐藏后还是会有巨大的开销;(待验证)
(9.5)材质种类:场景中的材质种类要提前规划好,拼场景时只在规划好的材质中选择。如果同屏的材质种类较多,会增加draw call。特别是场景美术用网上素材东拼西凑,很容易导致材质种类数量急剧上涨。
/* Performance Guidelines for Artists and Designers
https://docs.unrealengine.com/latest/INT/Engine/Performance/Guidelines/ */
10. 植被优化
10.1 地形编辑时,使用Instanced Static Meshes。Intancing会增加GPU的开销,但是可以显著降低CPU的开销;注意:实际应用中,Instancing并不能作为减少CPU draw call次数的主要途径,因为实际的游戏场景不可能全是instanced mesh,即使是满屏的植被,也并非一定要用instanced mesh。要减少draw call次数,需要减少材质种类,提高材质复用率。
10.2 当Instanced Mesh的数量较多时(比如百万级),一帧内执行RemoveInstance或者UpdateInstanceTransform数次,帧率会狂泻。优化办法:
(1)操作Instanced Mesh之前,将UHierarchicalInstancedStaticMeshComponent::bAutoRebuildTreeOnInstanceChanges设置为false,然后执行你需要的各种Instanced Mesh操作;
(2)操作完之后,然后将bAutoRebuildTreeOnInstanceChanges设置为true;
(3)然后执行BuildTreeIfOutdated(true, false);,这样可以显著减少因操作百万级Instanced Mesh而导致的性能损失。
10.3 植被材质消耗成为瓶颈时,宁可增加面数,也不要使用 Translucent 材质,Masked酌情使用。比如一根草的面片,其整个形状全部使用三角面拼出来,而不要用一个三角面再加 Mask 或者 Translucent 材质的方式。
10.4 为Instanced Mesh设置合适的Cull Distance。
11. 物理与碰撞优化
11.1 BoxComponent的 Generate Overlap Events 设置为false。如果不需要Overlap事件,那么就将该属性设置设置为false,默认为true。当BoxCompont达到一定量级时,开启Generate Overlap Events的性能消耗是关闭情况下的两倍。
11.2 不需要物理,将 Simulate Physics 设置为false。
11.3 不需要Hit事件,将 Simulation Generates Hit Events 设置为false。
11.4 如果场景中物体类型(WorldStatic、WorldDynamic、Pawn等)很多,且每种数量也很多,则Collision 的 Object Response 通道设置的越少越好,把可以设置为 Ignore 的通道都设置为 Ignore 。如果场景中的物体类型比较单一,即使这种类型的物体在场景中有数百个,Object Response 即使都设置为Block 或者 Overlap,对性能也没有影响。
11.5 如果是大型RTS游戏,场景有海量单位时(比如星际2中大规模的虫族小狗),能不用UE4的 Collision 就不要用 Collision,否则帧数狂泻。
建议自己实现一个简易的自定义Collision,比如球形Collision,然后计算该 Collision 与单位之间的直线距离,来判断是否是否发生了碰撞,并且降低检测间隔,比如 0.1秒一次。用此种方式,如果单位数量较多时,还需要自己写一个类似Distance Filed的八叉树来缓存单位列表,以降低计算单位间距时遍历单位列表的循环次数。
12. 动画优化
12.1 打开角色蓝图 -》 MeshComponent -》 Detail 面板中的 Optimization 类别下 -》 勾选 Enable Update Rate Optimizations。
12.2 只对渲染的 SkinnedMesh执行 Tick 和 RefreshBoneTransforms
USkinnedMeshComponent::MeshComponentUpdateFlag = OnlyTickPoseWhenRendered;
默认是AlwaysTickPoseAndRefreshBones,表示不管是否被渲染(在可见区域内),都执行 Tick 和 RefreshBoneTransforms。
旧版本中MeshComponentUpdateFlag叫做SkinnedMeshUpdateFlag。
注意:如果关闭动画Tick,和Tick相关的逻辑就会失效,比如Transform (Modify) Bone。
12.3 动画蓝图的逻辑尽量直接访问成员变量,引擎默认开启了优化选项:动画蓝图中的成员变量在编译时会被复制到Native Code中,从而避免在运行时进入蓝图虚拟机(Blueprint Virtual Machine)执行蓝图代码,因为蓝图VM运行效率低。
默认会被编译优化的参数类型包括:
member variables;
negated boolean member variables;
members of a nested structure;
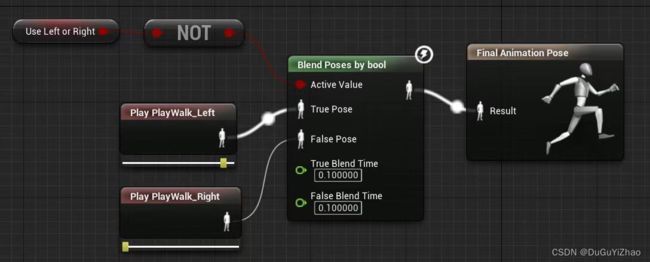
具体说明见官方文档:
Animation Optimization
https://docs.unrealengine.com/en-us/Engine/Animation/Optimization
Animation Fast Path Optimization
https://docs.unrealengine.com/en-us/Engine/Animation/Optimization/FastPath
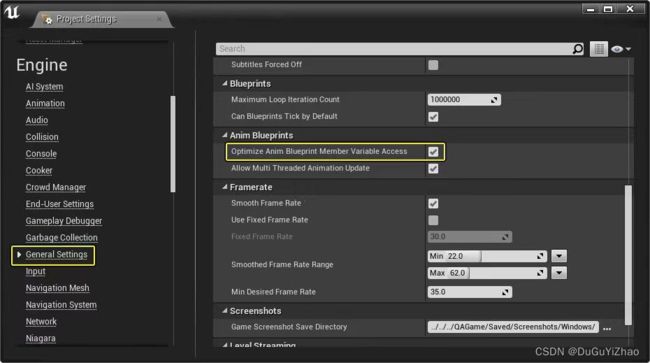
12.4线程动画更新
*Project Settings->General Settings-> Anim Blueprints: 启用 允许多线程动画更新(Allow Multi Threaded Animation Update)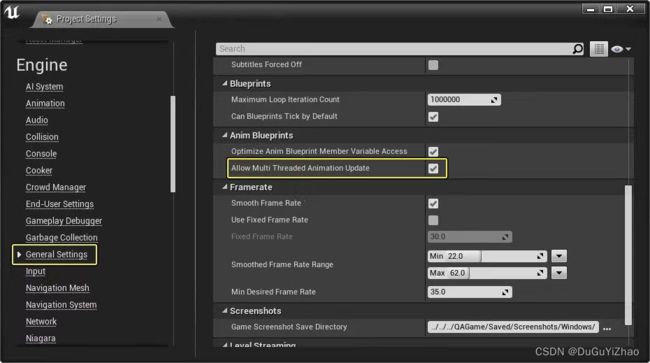
*动画蓝图(Animation Blueprints)中Class Settings下面,启用 使用多线程动画更新(Use Multi Threaded Animation Update)。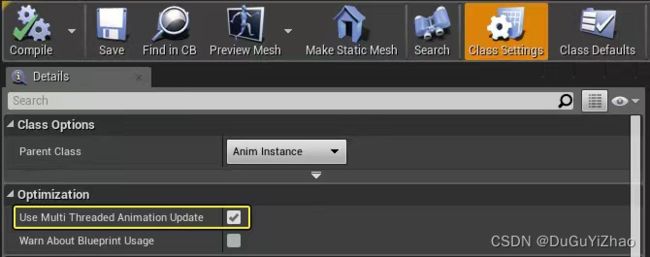
注:
(1) 建议最好不要从其他类直接访问动画实例。动画实例应从其他位置拉取数据。
(2)确保符合并行更新的条件
在`UAnimInstance::NeedsImmediateUpdate`中,您会看到为避免在游戏线程上运行动画更新阶段而必须满足的所有条件。 如果角色运动需要根运动,那么无法执行并行更新,因为角色运动并非多线程任务。???
(3)允许组件使用固定骨架边界
●在您的骨架网格体组件中,启用 组件使用骨架边界(Component Use Skel Bounds) 选项。
●这将跳过使用物理资源,改为使用骨架网格体中定义的固定边界。
●还将跳过重新计算为每一帧选择的包围体,从而提高性能。
13. UI优化
13.1 能用HUD解决的就不要用UMG,等到需要显示时才创建Widget对象,不显示时则销毁,UMG对象较多时性能消耗巨大。
比如场景内有一千个单位,每个单位上都创建有WidgetComponent,即使这些WidgetComponent没有显示任何东西,也会产生巨大的GPU开销。
13.2 不能使用UMG来修改鼠标光标,因为UMG来制作响应速度较高的显示逻辑时,会有肉眼可见的明显延迟(由此可见UMG的性能消耗有多高),可以使用Hardware Cursors来代替UMG制作光标。
* Epic Games工程师分享:如何在移动平台上做UE4的UI优化?
http://youxiputao.com/articles/11743
14. 位移优化
14.1 海量Pawn(比如500个)单位移动,如果是在 Tick 中使用 AddMovementInput 移动,帧率直接下降一半(比如从90帧下降到40多帧)。对于无法移动的单位,最好停止执行 AddMovementInput() ,以提升性能。
15. 特效优化
尽量不要使用 Volume domain,使用后会显著增加GPU开销。可以通过 profilegpu 检测 Volume 开销。
16. AI优化
如果角色不需要 Controller ,就不要给它 Spawn Controller。如果一个角色长时间停止,则先给他Unpossesed() ,等到可移动时再PossessedBy()。
测试:500个角色,AI Controller Class 设置为:null、 AIController、PlayerController 的帧数分别为 120 fps、 100 fps、75 fps。
17. Dedicated Server优化
17.1 服务端cook时剥离动画数据
Project Settings -> Engine -> Animation -> 勾选 Strip Animation Data on Dedicated Server。
如果在动画中添加了触发修改数据的 Notify Event,勾选此选项会有问题。请确保动画中挂载的 Notify 只是表现相关,不涉及游戏逻辑。
17.2 Server模式下禁用角色物理模拟
FBodyInstance->bSimulatePhysics 设置为false。默认为false。
SkeletalMeshComponent::bEnablePhysicsOnDedicatedServer 设置为 false , 默认为 true 。但这样会导致物理验算以客户端为准,有被外挂hack的风险。bEnablePhysicsOnDedicatedServer 在 run-time 修改不生效。
17.3 Server模式下禁用 Collision
UPrimitiveComponent->bGenerateOverlapEvents 设置为false,角色蓝图中的 CollisionComponent 默认为true。
17.4 Server模式下Detach角色身上所有的装饰性组件;
17.5 AnimInstance的Root Motion Mode不要修改为Root Motion from Everything,尽量使用默认值Root Motion from Montage Only,以减少服务器的动画同步计算量。
17.6 4.20提供了针对Dedicated Server优化的新特性:Replication Graph,可以初略地理解为针对网络通信的LOD(不过Replication Graph提供了不止网络层面的LOD,更多特性见官方文档)。没有这特特性之前,调用Multicast函数,几公里外的Actor也会触发Multicast,而实际上这种Actor可能不需要即时更新数据或者等到出现在视距内时再手动ForceNetUpdate()。有了Replication Graph之后,这种手动优化方式可以交给引擎自己管理。
常用命令:
stat initviews:统计信息窗口;
stat GPU:渲染最耗时分析;
stat Game:Game耗时分析;
stat unit:显示耗时情况,Frame下面哪个值高,哪个就是瓶颈;
stat unitgraph:图形化耗时情况;
stat RHI:Render hardware interface,主要看Draw Call和贴图内存情况,配合obj list ;Texture2D,可以列出当前场景所有贴图;
stat memory:内存使用情况;
FreezerRendering:冻结渲染,方便查看遮挡剔除情况;
stat ShadowRendering:阴影耗时分析;
stat SceneRendering:DrawCall,以及阴影,后处理等信息;
stat LightRendering:灯光耗时分析;
stat startfile:开启截取一段游戏运行记录;
stat stopfile:关闭,使用SessionFrontend打开查看详细信息;
r.VisualizeOccludedPrimitives 1:开启可视化剔除;
r.VisualizeOccludedPrimitives 0:关闭可视化剔除;