我花 10 个小时,写出了小白也能看懂的阿里数据中台分析!
点击蓝色“架构文摘”关注我哟
加个“星标”,每天上午 09:25,干货推送!
数据中台被誉为大数据的下一站,由阿里兴起,核心思想是数据共享,2015年阿里提出“大中台,小前台”的策略。2018 年因为“腾讯数据中台论”,中台再度成为了人们谈论的焦点。
2019年,似乎人人都在提数据中台,但却不是所有人都清楚数据中台到底意味着什么。数据中台是只有大厂才需要考虑的高大上的概念吗?普通企业该不该做数据中台?数据中台的出现会给现有数据从业者们带来颠覆式的挑战吗?
数据中台不是大数据平台!
首先它不是一个平台,也不是一个系统,如果有厂商说他们有个数据中台卖给你,对不起,它是个骗子。
要回答数据中台是什么,首先要探讨一下中台到底是什么。虽然没有明确的定义,但是作为理工直男,我们可以先把中台看作是一种中间层。既然是一种中间层,那么中台确实是一种十足技术用语,我们可以完全从技术角度来探讨了。
我们可以应用 Gartner 的 Pace Layer 来理解为什么要有中间层,这样可以更好地理解中台的定位和价值。Pace Layer 里提到,可以按照事物变化的速度来分层,这样可以逐层分析并设计合理的边界与服务。
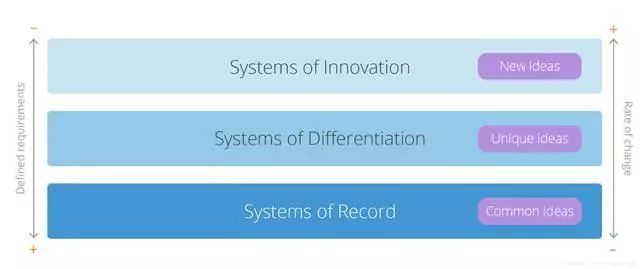
在数据开发中,核心数据模型的变化是相对缓慢的,同时,对数据进行维护的工作量也非常大;但业务创新的速度、对数据提出的需求的变化,是非常快速的。
数据中台的出现,就是为了弥补数据开发和应用开发之间,由于开发速度不匹配,出现的响应力跟不上的问题。
效率:为什么应用开发增加一个报表,就要十几天时间?为什么不能实时获得用户推荐清单?当业务人员对数据产生一点疑问的时候,需要花费很长的时间,结果发现是数据源的数据变了,最终影响上线时间。
协作问题:当业务应用开发的时候,虽然和别的项目需求大致差不多,但因为是别的项目组维护的,所以数据还是要自己再开发一遍。
能力问题:数据的处理和维护是一个相对独立的技术,需要相当专业的人来完成,但是很多时候,我们有一大把的应用开发人员,而数据开发人员很少。
这三类问题都会导致应用开发团队变慢。这就是中台的关键——让前台开发团队的开发速度不受后台数据开发的影响。
数据中台是聚合和治理跨域数据,将数据抽象封装成服务,提供给前台以业务价值的逻辑概念。
如下图所示:
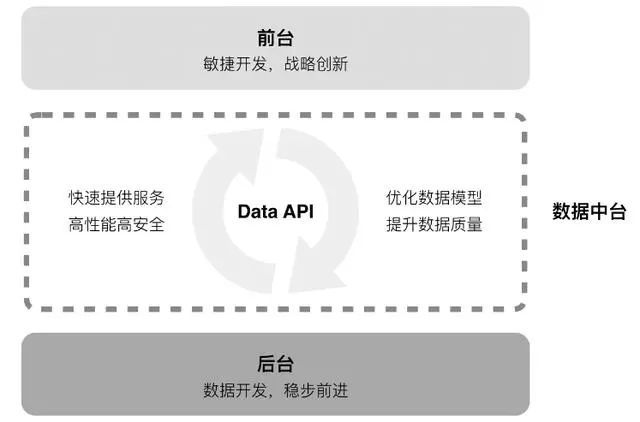
Data API 是数据中台的核心,它是连接前台和后台的桥梁,通过 API 的方式提供数据服务,而不是直接把数据库给前台、让前台开发自行使用数据。至于产生 DataAPI 的过程,怎么样让 DataAPI 产生得更快,怎么样让 DATA API 更加清晰,怎么样让 DATA API 的数据质量更好,这些是要围绕数据中台去构建的能力。
其实这些概念说多了是很虚的,那我们就结合阿里的例子来讲解。
阿里数据中台详解
阿里数据中台赋能业务全景图

在架构图中,看到最下面的内容主要是数据采集和接入,按照业态接入数据(比如淘宝、天猫、盒马等),把这些数据抽取到计算平台;通过OneData体系,以“业务板块+分析维度”为架构去构建“公共数据中心”。
基于公共数据中心在上层根据业务需求进行建设:消费者数据体系、企业数据体系、内容数据体系等。
经过深度加工后,数据就可以发挥其价值被产品、业务所用;最后通过统一的数据服务中间件“OneService”提供统一数据服务。
阿里数据中台三大体系
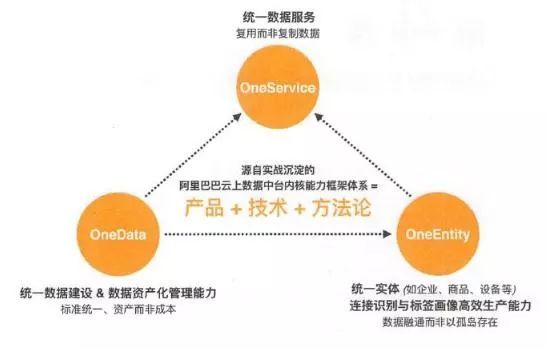
经过多年实战,沉淀出了阿里云上数据中台内核能力框架体系:产品+技术+方法论。
历经阿里生态内各种实战历练后,云上数据中台从业务视角而非纯技术视角出发,智能化构建数据、管理数据资产,并提供数椐调用、数据监控、数据分析与数据展现等多种服务。
承技术启业务,是建设智能数据和催生数据智能的引擎。在OneData、OneEntity、OneService三大体系,特别是其方法论的指导下,云上数据中台本身的内核能力在不断积累和沉淀。在阿里巴巴,几乎所有人都知道云上数据中台的三大体系,如上图所示。
OneData致力干统一数据标准,让数据成为资产而非成本;OneEntity致力于统一实体,让数据融通而以非孤岛存在;OneService致力于统一数据服务,让数据复用而非复制。
这三大体系不仅有方法论,还有深刻的技术沉淀和不断优化的产品沉淀,从而形成了阿里巴巴云上数据中台内核能力框架体系。
阿里数据中台及赋能业务模式支撑

阿里数据中台,经历了所有阿里生态内业务的考验,包括新零售、金融、物流、营销、旅游、健康、大文娱、社交等领域。
数据中台除了建立起自已的内核能力之外,向上赋能业务前台,向下与统一计算后台连接,融为一体。
数据中台六大数据技术领域

前文提到,在建设阿里数据公共层之初,规划了六大数据技术领域,即数据模型领域、存储治理领域、数据质量领域、安全权限领域、平台运维领域、研发工程领域。
而在阿里数据公共层建设项目第二阶段完成存储治理领域,已经被扩大到资源治理领域,进而升级到数据资产管理领域,安全权限领域,升级到数据信任领域,因为很多工作已经在产品中实现,平台运维领域不再作为一个数据技术领域被推进,数据模型领域与数据质量领域还在持续推进中,不过增加了许多新的内涵,智能黑盒领域则是新起之秀。
由此可见,数据技术领域不是一成不变的,而是随着业务的发展和技术的突破不断扩大、 升华的。
那么,实时的数据中台怎么做?
下面是实现实时数据中台的一种逻辑架构,方便你去理解,其实最关键的是实时模型那一层。
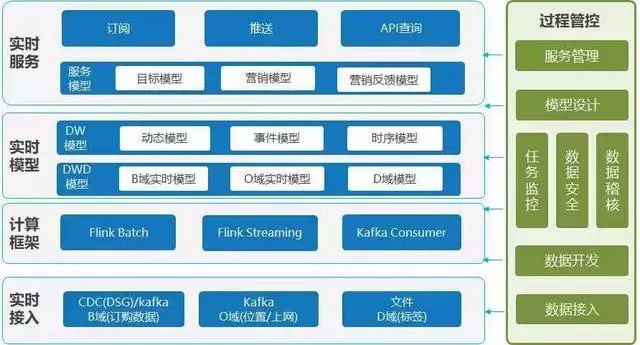
1、实时接入
不同类型的数据需要不同的接入方式,flume+kafka现在是标配,其他还有文件、数据库的DSG等等技术。比如运营商就有B域的订购、通话,O域的位置、上网等各类实时数据。
计算框架
这里只列出一种,基于Kappa架构实现实时/离线一体化业务开发能力,相对于传统Lambda架构,开发人员只需面对一个框架,开发、测试和运维的难度都相对较小,且能充分发挥Flink流式计算框架一点执行、高吞吐、毫秒级响应、批流融合的特点。
比如将流计算组件划分实时数据切片,批处理组件提供离线数据模型(驻留内存),两类数据在处理过程中实现批流关联。
实时模型
跟数据仓库模型一样,实时模型肯定首先是面向业务的,比如运营商有流量运营、服务提醒、竞争应对、放好拉新、厅店引流、语音消费、运营评估、实时关怀、实时预警、实时洞察、实时推荐等一系列的实时场景,你总是要基于你的实时业务提炼出具备共性的数据模型要素。
比如放号拉新中的外来务工实时营销,其中可能的触发场景是针对漫入到某个交通枢纽并驻留10分钟以上的用户进行营销投放,“在某个位置的驻留时长”这个公共要素可能就是一种可复用的实时模型。
实时模型纵向可以划分为DWD和DW两层,DWD模型做的其实是针对各类实时数据做命名的标准化和过滤字段的操作,方便进行数据的标准化管理,DW模型这里分成了三大类:动态模型、事件模型和时序模型,每种模型适合不同的场景,同时需要采用与之适配的存储格式。
动态模型:对实时的数据进行汇总统计,适合做实时的统计指标分析,比如实时的业务办理量,一般可存储于Kafka和Hbase。
事件模型:把实时的数据抽象成一系列业务事件,比如从位置日志轨迹中记录用户的位置变更事件,从而可以触发LBS的位置营销,以下是典型的位置事件模型设计,一般可存储于MQ和Redis:

你也可以设计滑动窗口模型,比如保存最新一小时的分钟级的滑动窗口位置信息:

时序模型:主要保存用户的在线的时空位置等信息,可以基于业务场景需要进行各种快速的计算,比如非常方便的计算驻留时长,存储于Hbase或TSDB(时序数据库):

4、实时服务
有了实时模型还不够,数据中台还需要提供图形化、流程化、可编排的数据开发工具,才能真正的降低实时数据开发成本。但由于离线和实时数据处理的技术手段不同,导致针对这两种类型的数据开发和管理大多是在不同的平台承载的。
比如以前我们的离线数据模型是通过DACP平台管理的,但实时数据则游离在DACP平台之外,其往往属于应用本身的一部分,应用需要通过编写特定脚本去消费和处理流处理引擎中的原生数据,这种处理的门槛不仅高,而且资源浪费也挺严重,每个实时应用其实都是流数据的孤岛。
站在应用的角度看,业务其实需要的是一个统一的数据开发管理平台,离线和实时数据应作为统一的对象进行管理,比如具备混合编排,混合关联等能力,用简单的类SQL定制化输出应用所需的各类数据,从而高效的对外提供实时/离线数据服务。

5、实时应用
数据中台如果能支持实时数据的快速编排,根据我们的测算,其实时场景应用的数据开发、测试、部署周期会由0.5-1个月降低为1-2天,效益是很高的。
阿里处理的数据量已达EB级,相当于10亿部高清电影的存储量。在 2016年双十一当天,实时计算处理的数据量达到9400万条/秒。而从用户产生数据源头采集、整合并构速数据、提供数据服务,到前台展现完成仅需2.5秒。
"友盟+”是阿里把收购的几家数据公司整合升级后,组成的一家数据公司。这里仅以2017年“友盟+”对外公开的部分指标为例,其中的数据覆盖14亿部活跃设备、685 万家网站、135万个应用程序,日均处理约280亿条数据,这一切都建立在阿里强大的数据处理技术底座之上。
如果实时数据足够多,场景足够丰富,建立实时数据中台的必要性还是非常高的。
随着大数据内外运营的深入,我们发现这种需求越来越多,你会惊奇的发现,很多时候需求是随着你技术能力的加强而增加的,很多时候,技术就是第一生产力。我们很多负责变现的产品、运营经理应是深有体会的。
从那个时候起,我就在想我们能否建立一个真正的实时数据中台,能够快速高效的创建海量的实时应用,从而将大数据的管理和应用水平提升到一个新的阶段,终于我们现在走到了这条路上。
作者:数据分析不是个事儿
https://www.jianshu.com/p/05a8db84e454
推荐阅读:
Nginx 核心架构设计,揭秘其为何能支持高并发?
万变不离其宗,高并发秒杀系统的设计思考!
技术总监的反思录,我是如何失去团队掌控的?
假如有人今天把支付宝的存储服务器炸了,支付宝里的钱是不是就没了。。。
再也不用担心被虐啦,高频率JVM面试题,都在这里!
饿了么千万级交易系统的重构设计思路
支付系统高可用架构设计实战,可用性高达99.999!
大型互联网公司分布式ID方案总结
-END-
架构文摘
ArchDigest
架构知识丨大型网站丨大数据丨机器学习

如有收获,点个在看,诚挚感谢