mysql 全文索引 排序_MySQL全文索引
MyISAM全文索引作用对象是"全文集合",它将需要索引的所有列拼接成字符串,然后进行索引.它是一类特殊的双BTree索引,共有两层,第一层是所有关键字,然后对于每一个关键字,是一组文档指针.
全文索引的词语过滤规则:
1. 停用词列表中的词不会被索引.默认停用词根据通用英语来设置,可以使用参数ft_stopword_file指定一组外部文件使用自定义停用词
2. 长度小于ft_min_word_len和长度小于ft_max_word_len词语,都不会被索引
全文索引不会存储关键字具体匹配哪一列,如果需要根据不同的列来进行组合查询,不需要对每一列来建立索引.所以在MATCH AGAINST子句中,所有列的相关性是同等重要的.
自然语言全文索引
相关度:索引中出现次数越少的词语,相关度就越高,当出现此处超过50%自然语言搜索则不会搜索这个词语.所以常见问题就是当数据集合很少的时候,全文索引查询返回不了结果
自然语言全文索引查询示例:
SELECT film_id, title, RIGHT(description, 25),
MATCH(title, description) AGAINST('factory casualties') ASrelevanceFROMsakila.film_textWHERE MATCH(title, description) AGAINST('factory casualties')
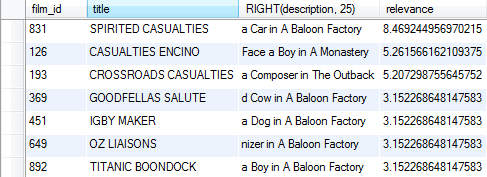
和普通查询不同,自然语言全文索引是按相关度排序的,在一次查询使用两次MATCH()不会有额外消耗,MySQL会自动识别值进行一次搜索.此外,MATCH()函数中指定的列必须和建立索引的列完全相同,否则无法使用全文索引
布尔全文索引
布尔全文索引可以通过特定的前缀修饰符来定制索引.功能如下图

使用示例
SELECT film_id, title, RIGHT(description, 25)FROMsakila.film_textWHEREMATCH(title, description)
AGAINST('+factory +casualties' IN BOOLEAN MODE)
结果是精确匹配,只有一条记录
![]()
全文索引的限制
1.全文索引只有完全读入内存速度才会快,否则速度会非常慢,因为会产生大量随机IO
2.全文索引的操作代价很大,修改一段文本的100个单词,需要100次索引操作
3.当使用了MATCH AGAINST的列上有全文索引时,一定会使用这个全文索引,而忽略其他可用索引,即使性能不好(似乎新版本已经改进了这个,如果有更好的索引,还是会使用的)
4.全文索引只能做全文匹配,任何其他WHERE条件都只能在全文搜索返回记录后才能进行
5.全文索引不存储索引列的实际值,所以不能做索引覆盖扫描
6.使用全文索引如果需要使用相关性以外的排序,都需要用到文件排序(filesort)
全文索引的优化
1.使用OPTIMIZE TABLE减少碎片问题
2.保证索引缓存足够大
3.使用一个好的停用词表,例如要索引和MySQL相关的文档,则最好将"MySQL"放入停用词表,因为在这类文档中这个词会出现的很频繁
4.忽略太短的词语可以提升全文索引效率,但同时搜索精度会下降,这个需要权衡
5.有全文索引的表需要导入大量数据时,先DISABLE KEYS停用索引,导入完成后在ENABLE KEY开启索引