hadoop MapReduce 实战(java):单词计数
hadoop MapReduce 实战(java):单词计数
点击【File】—>【Project】,选择【Map/ReduceProject】,输入项目名称test,一直回车。
在WordCount项目里新建class,名称为WordCount,代码如下:
package test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/** * 计数的文件内容为: * I am a pretty girl * I am so cute ! * 1. * 2.通过map函数: * * */ publicclass WordCount { publicstaticclass MyMapper extends Mapper private Text k2 = new Text(); //K2 privatefinalstatic IntWritable v2 = new IntWritable(1); //v2
@Override publicvoid map(Object key, Text value, Mapper ) throws IOException, InterruptedException { String[] words=value.toString().split(" "); for(String wordstr:words){
k2.set(wordstr); context.write(k2, v2); } } }
/** * 上面map函数输出 * 通过reduce函数输出: * */ publicstaticclass MyReducer extends Reducer private IntWritable result = new IntWritable(); @Override //传入的数据value值是集合,所以用Iterable publicvoid reduce(Text key, Iterable Reducer ) throws IOException, InterruptedException { intsum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key,result); } }
publicstaticvoid main(String[] args) throws Exception { //固定写法,配置工作,针对args Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count -adai");//新建任务,并且命名任务 job.setJarByClass(WordCount.class); //FileInputFormat.setInputPaths(job, new Path("hdfs://master12:8020/user/root/test.txt")); job.setInputFormatClass(TextInputFormat.class); job.setMapperClass(MyMapper.class);//设置mapper逻辑 //job.setCombinerClass(IntSumReducer.class); job.setReducerClass(MyReducer.class);//设置reduce逻辑 job.setMapOutputKeyClass(Text.class);//设置map job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);//设置Reduce输出的格式 job.setOutputValueClass(IntWritable.class); job.setOutputFormatClass(TextOutputFormat.class);//TextOutputFormat FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); //FileOutputFormat.setOutputPath(job, new Path("hdfs://master12:8020/user/root/out00")); System.exit(job.waitForCompletion(true) ? 0 : 1);//正常退出:0 }
}
|

打包导出wordcount.jar,右键选择Export,选择JAR file,

在hadoop环境下运行:
hadoop jar /root/WordCount.jar test.WordCount /user/root/test.txt wc00 |
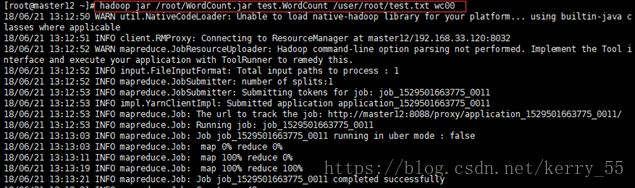
查看HDFS上的结果:
