数据科学库(六)pandas中的时间序列
文章目录
- (一)python数据科学库学习目录
- (二)不同类型的紧急情况的次数(改进版)
- (三)pandas中的时间序列
-
- 3.1 生成一段时间范围(5个常用)
-
- 3.1.1date_range(start="20171230",end="20180131",freq="D")
- 3.1.2date_range(start="20171230",end="20180131",freq="10D")
- 3.1.3 date_range(start="20171230",periods=10,freq="D")
- 3.1.4date_range(start="20171230",periods=10,freq="M")
- 3.1.5date_range(start="20171230",periods=10,freq="H")
- 3.2 在DataFrame中使用时间序列
- 3.3 pandas重采样
-
- 3.3.1 pandas重采样介绍
- (四) 统计出911数据中不同月份电话次数的变化情况
-
- 4.1 pd.to_datetime()
- 4.2 统计出911数据中不同月份电话次数的
- 4.3 统计出911数据中`title`不同月份电话次数的
- 4.4 画图
- 4.5 Python time strftime() 方法
- (5)统计出911数据中不同月份不同类型的电话的次数的变化情况
本文所有源码、资料下载:
链接: https://pan.baidu.com/s/10XCx8SKrduFXnkx998fi2Q
提取码:
ugwj
(一)python数据科学库学习目录
学习python数据科学库笔记的顺序:
pycharm设置背景图片
python数据科学库(一)
python数据科学库(二)matplotlib
python数据科学库笔记(三)Numpy
python数据科学库笔记(四)pandas
Python下载并安装第三方库(cvxpy)
解决importError :numpy.core.multiarrary failed to import
python数据科学库(五 · 一)数字的合并与分组聚合(太具有逻辑性)
数据科学库(五 · 二)数字的合并与分组聚合
数据科学库(五 · 三)索引和复合索引
python对导入文件数据进行(查看、分析、解题思路、流程)做详细分析
(二)不同类型的紧急情况的次数(改进版)
上一篇我们介绍了python对导入文件数据进行(查看、分析、解题思路、流程)做详细分析(适用于python初学者)但是代码还是相对复杂,现在我们改善一下代码如下:
# coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# 通过pandas库来控制显示窗口,为了多显示一些运行数据
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 1000)
df = pd.read_csv("./911.csv")
print(df.head(5))
#获取分类
# print()df["title"].str.split(": ")
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
# 表示把cate_list生成一个df.shape[0]行1列的DataFrame类型,并添加到df新增的cate标签一列中
'''
cate = np.array(cate_list).reshape((df.shape[0],1))
df["cate"] = pd.DataFrame(cate)
'''
# print(df.head(5))
print(df.groupby(by="cate").count()["title"])
# df.groupby()详细介绍链接https://blog.csdn.net/huguozhiengr/article/details/83384160
# 按照cate分组(cate一共就三种分类),再统计一下个数,统计个数是按照title标签这一列的数据统计的。
OUT:
lat lng desc zip title timeStamp twp addr e
0 40.297876 -75.581294 REINDEER CT & DEAD END; NEW HANOVER; Station ... 19525.0 EMS: BACK PAINS/INJURY 2015-12-10 17:10:52 NEW HANOVER REINDEER CT & DEAD END 1
1 40.258061 -75.264680 BRIAR PATH & WHITEMARSH LN; HATFIELD TOWNSHIP... 19446.0 EMS: DIABETIC EMERGENCY 2015-12-10 17:29:21 HATFIELD TOWNSHIP BRIAR PATH & WHITEMARSH LN 1
2 40.121182 -75.351975 HAWS AVE; NORRISTOWN; 2015-12-10 @ 14:39:21-St... 19401.0 Fire: GAS-ODOR/LEAK 2015-12-10 14:39:21 NORRISTOWN HAWS AVE 1
3 40.116153 -75.343513 AIRY ST & SWEDE ST; NORRISTOWN; Station 308A;... 19401.0 EMS: CARDIAC EMERGENCY 2015-12-10 16:47:36 NORRISTOWN AIRY ST & SWEDE ST 1
4 40.251492 -75.603350 CHERRYWOOD CT & DEAD END; LOWER POTTSGROVE; S... NaN EMS: DIZZINESS 2015-12-10 16:56:52 LOWER POTTSGROVE CHERRYWOOD CT & DEAD END 1
cate
EMS 320326
Fire 96177
Traffic 223395
Name: title, dtype: int64
(三)pandas中的时间序列
3.1 生成一段时间范围(5个常用)
pandas.date_range(start=None, end=None, periods=None, freq=’D’, tz=None)
# start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
# start和periods以及freq配合能够生成从start开始的频率为freq的periods个时间索引
start:string或datetime-like,默认值是None,表示日期的起点。
end:string或datetime-like,默认值是None,表示日期的终点。
periods:integer或None,默认值是None,表示你要从这个函数产生多少个日期索引值;如果是None的话,那么start和end必须不能为None。
freq:string或DateOffset,默认值是’D’,表示以自然日为单位,这个参数用来指定计时单位,比如’5H’表示每隔5个小时计算一次。
tz:string或None,表示时区,例如:’Asia/Hong_Kong’。

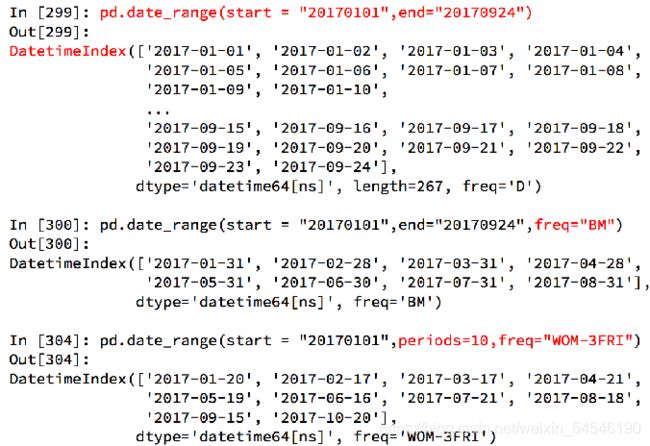
3.1.1date_range(start=“20171230”,end=“20180131”,freq=“D”)
a = pd.date_range(start="20171230",end="20180131",freq="D")
OUT
DatetimeIndex(['2017-12-30', '2017-12-31', '2018-01-01', '2018-01-02',
'2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06',
'2018-01-07', '2018-01-08', '2018-01-09', '2018-01-10',
'2018-01-11', '2018-01-12', '2018-01-13', '2018-01-14',
'2018-01-15', '2018-01-16', '2018-01-17', '2018-01-18',
'2018-01-19', '2018-01-20', '2018-01-21', '2018-01-22',
'2018-01-23', '2018-01-24', '2018-01-25', '2018-01-26',
'2018-01-27', '2018-01-28', '2018-01-29', '2018-01-30',
'2018-01-31'],
dtype='datetime64[ns]', freq='D')
3.1.2date_range(start=“20171230”,end=“20180131”,freq=“10D”)
b = pd.date_range(start="20171230",end="20180131",freq="10D")
OUT
DatetimeIndex(['2017-12-30', '2018-01-09', '2018-01-19', '2018-01-29'], dtype='datetime64[ns]', freq='10D')
3.1.3 date_range(start=“20171230”,periods=10,freq=“D”)
c = pd.date_range(start="20171230",periods=10,freq="D")
OUT
DatetimeIndex(['2017-12-30', '2017-12-31', '2018-01-01', '2018-01-02',
'2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06',
'2018-01-07', '2018-01-08'],
dtype='datetime64[ns]', freq='D')
3.1.4date_range(start=“20171230”,periods=10,freq=“M”)
d = pd.date_range(start="20171230",periods=10,freq="M")
OUT
DatetimeIndex(['2017-12-31', '2018-01-31', '2018-02-28', '2018-03-31',
'2018-04-30', '2018-05-31', '2018-06-30', '2018-07-31',
'2018-08-31', '2018-09-30'],
dtype='datetime64[ns]', freq='M')
3.1.5date_range(start=“20171230”,periods=10,freq=“H”)
e = pd.date_range(start="20171230",periods=10,freq="H")
OUT
DatetimeIndex(['2017-12-30 00:00:00', '2017-12-30 01:00:00',
'2017-12-30 02:00:00', '2017-12-30 03:00:00',
'2017-12-30 04:00:00', '2017-12-30 05:00:00',
'2017-12-30 06:00:00', '2017-12-30 07:00:00',
'2017-12-30 08:00:00', '2017-12-30 09:00:00'],
dtype='datetime64[ns]', freq='H')
3.2 在DataFrame中使用时间序列
import pandas as pd
import numpy as np
# 设置时间序列为dataframe的index
index=pd.date_range("20170101",periods=10)
df=pd.DataFrame(np.random.rand(10),index=index)
# 生成一个以时间序列为索引的dataframe
# 为什么时间序列可以作为索引呢?
# 因为时间序列在pandas中是一个DatetimeIndex这样一种类型 即是时间索引类型
print(index)
print("# # "*6)
print(df)
OUT
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04',
'2017-01-05', '2017-01-06', '2017-01-07', '2017-01-08',
'2017-01-09', '2017-01-10'],
dtype='datetime64[ns]', freq='D')
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
0
2017-01-01 0.807795
2017-01-02 0.150785
2017-01-03 0.068778
2017-01-04 0.823891
2017-01-05 0.233198
2017-01-06 0.018804
2017-01-07 0.202627
2017-01-08 0.072681
2017-01-09 0.330796
2017-01-10 0.755146
3.3 pandas重采样
3.3.1 pandas重采样介绍
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样.pandas提供了一个resample的方法来帮助我们实现频率转化
详解pandas.DataFrame.resample根据时间聚合采样
pandas.DataFrame.resample官网
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None,
label=None, convention='start', kind=None, loffset=None,
limit=None, base=0, on=None, level=None)
rule : 表示目标转换的偏移字符串或对象,一般是时间参数,比如“M”,“A”,“Q”,“BM”,“BA”,“BQ”和“W”;
axis : int, optional, default 0
closed : {‘right’, ‘left’};间隔的哪一侧是关闭的,对于除“M”,“A”,“Q”,“BM”,“BA”,“BQ”和“W”之外的所有频率偏移,默认值为“左”,其默认值均为“右”
label : {‘right’, ‘left’};用于标记bins,间隔的哪一侧是关闭的,对于除“M”,“A”,“Q”,“BM”,“BA”,“BQ”和“W”之外的所有频率偏移,默认值为“左”,其默认值均为“右”
convention : {‘start’, ‘end’, ‘s’, ‘e’}:For PeriodIndex only, controls whether to use the start or end of rule
kind: {‘timestamp’, ‘period’}, optional;Pass ‘timestamp’ to convert the resulting index to a DateTimeIndex or ‘period’ to convert it to a PeriodIndex. By default the input representation is retained.
loffset : 调整重新采样的时间标签
on : 对于DataFrame,要使用的列而不是索引进行重新采样。列必须与日期时间相似的数据。

(四) 统计出911数据中不同月份电话次数的变化情况
4.1 pd.to_datetime()
回到最开始的911数据的案例中,我们可以使用pandas提供的方法把时间字符串转化为时间序列
df["timeStamp"] = pd.to_datetime(df["timeStamp"],format="")
format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文。
# coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# 通过pandas库来控制显示窗口
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 1000)
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df.set_index("timeStamp",inplace=True)
print(df)
OUT
lat lng desc zip title twp addr e
timeStamp
2015-12-10 17:10:52 40.297876 -75.581294 REINDEER CT & DEAD END; NEW HANOVER; Station ... 19525.0 EMS: BACK PAINS/INJURY NEW HANOVER REINDEER CT & DEAD END 1
2015-12-10 17:29:21 40.258061 -75.264680 BRIAR PATH & WHITEMARSH LN; HATFIELD TOWNSHIP... 19446.0 EMS: DIABETIC EMERGENCY HATFIELD TOWNSHIP BRIAR PATH & WHITEMARSH LN 1
2015-12-10 14:39:21 40.121182 -75.351975 HAWS AVE; NORRISTOWN; 2015-12-10 @ 14:39:21-St... 19401.0 Fire: GAS-ODOR/LEAK NORRISTOWN HAWS AVE 1
2015-12-10 16:47:36 40.116153 -75.343513 AIRY ST & SWEDE ST; NORRISTOWN; Station 308A;... 19401.0 EMS: CARDIAC EMERGENCY NORRISTOWN AIRY ST & SWEDE ST 1
2015-12-10 16:56:52 40.251492 -75.603350 CHERRYWOOD CT & DEAD END; LOWER POTTSGROVE; S... NaN EMS: DIZZINESS LOWER POTTSGROVE CHERRYWOOD CT & DEAD END 1
... ... ... ... ... ... ... ... ..
2020-05-26 09:17:31 40.087810 -75.304726 SCARLET DR & COLWELL LN; PLYMOUTH; 2020-05-26 ... 19428.0 Fire: GAS-ODOR/LEAK PLYMOUTH SCARLET DR & COLWELL LN 1
2020-05-26 09:30:06 40.058569 -75.126960 COVENTRY AVE & VALLEY RD; CHELTENHAM; Station... 19027.0 EMS: RESPIRATORY EMERGENCY CHELTENHAM COVENTRY AVE & VALLEY RD 1
2020-05-26 09:35:44 40.151622 -75.120972 EASTON RD & ELLIS RD; UPPER MORELAND; 2020-05-... 19090.0 Fire: FIRE ALARM UPPER MORELAND EASTON RD & ELLIS RD 1
2020-05-26 09:40:28 40.175388 -75.108397 HARDING AVE & WILLIAMS LN; HATBORO; Station 3... 19040.0 EMS: UNRESPONSIVE SUBJECT HATBORO HARDING AVE & WILLIAMS LN 1
2020-05-26 09:36:34 40.079811 -75.293981 E 11TH AVE; CONSHOHOCKEN; 2020-05-26 @ 09:36:3... 19428.0 Fire: FIRE INVESTIGATION CONSHOHOCKEN E 11TH AVE 1
4.2 统计出911数据中不同月份电话次数的
#统计出911数据中不同月份电话次数的
count_by_month = df.resample("M").count()
# Pandas中的resample,重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。M:指按月不同分类。
print(count_by_month.head())
OUT
lat lng desc zip title twp addr e
timeStamp
2015-12-31 7916 7916 7916 6902 7916 7911 7916 7916
2016-01-31 13096 13096 13096 11512 13096 13094 13096 13096
2016-02-29 11396 11396 11396 9926 11396 11395 11396 11396
2016-03-31 11059 11059 11059 9754 11059 11052 11059 11059
2016-04-30 11287 11287 11287 9897 11287 11284 11287 11287
4.3 统计出911数据中title不同月份电话次数的
#统计出911数据title中不同月份电话次数的
count_by_month = df.resample("M").count()["title"]
print(count_by_month.head())
OUT:
timeStamp
2015-12-31 7916 # 这个总数包括2015年12月所有不同日出现紧急事件次数的和。
2016-01-31 13096
2016-02-29 11396
2016-03-31 11059
2016-04-30 11287
Freq: M, Name: title, dtype: int64
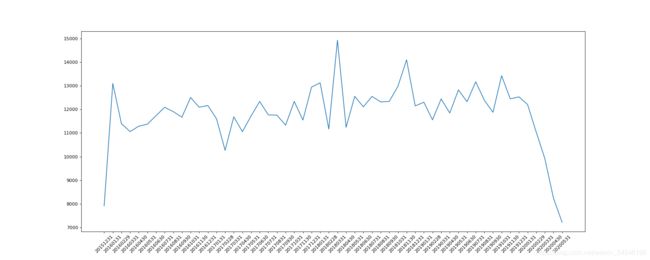
4.4 画图
#画图
_x = count_by_month.index
_y = count_by_month.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.show()

但是有一个问题,我们是不是不希望图中x的标签中含有00.00.00,那我们怎么把它去除呢!(用Datatime对其进行格式化)
_x = count_by_month.index
_y = count_by_month.values
for i in _x: # 查看_x的所有方法
print(dir(i))
break
OUT
['__add__', '__array_priority__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__pyx_vtable__', '__radd__', '__reduce__', '__reduce_cython__', '__reduce_ex__', '__repr__', '__rsub__', '__setattr__', '__setstate__', '__setstate_cython__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__weakref__', '_date_repr', '_repr_base', '_round', '_short_repr', '_time_repr', 'asm8', 'astimezone', 'ceil', 'combine', 'ctime', 'date', 'day', 'day_name', 'day_of_week', 'day_of_year', 'dayofweek', 'dayofyear', 'days_in_month', 'daysinmonth', 'dst', 'floor', 'fold', 'freq', 'freqstr', 'fromisocalendar', 'fromisoformat', 'fromordinal', 'fromtimestamp', 'hour', 'is_leap_year', 'is_month_end', 'is_month_start', 'is_quarter_end', 'is_quarter_start', 'is_year_end', 'is_year_start', 'isocalendar', 'isoformat', 'isoweekday', 'max', 'microsecond', 'min', 'minute', 'month', 'month_name', 'nanosecond', 'normalize', 'now', 'quarter', 'replace', 'resolution', 'round', 'second', 'strftime', 'strptime', 'time', 'timestamp', 'timetuple', 'timetz', 'to_datetime64', 'to_julian_date', 'to_numpy', 'to_period', 'to_pydatetime', 'today', 'toordinal', 'tz', 'tz_convert', 'tz_localize', 'tzinfo', 'tzname', 'utcfromtimestamp', 'utcnow', 'utcoffset', 'utctimetuple', 'value', 'week', 'weekday', 'weekofyear', 'year']
我们要用的是其中strftime的方法
4.5 Python time strftime() 方法
Python time strftime() 方法
Python内置的strftime( )函数:实现本地时间\日期的格式化(将任意格式的日期字符串按要求进行格式化)。
格式符 说明
%a 星期的英文单词的缩写:如星期一, 则返回 Mon
%A 星期的英文单词的全拼:如星期一,返回 Monday
%b 月份的英文单词的缩写:如一月, 则返回 Jan
%B 月份的引文单词的缩写:如一月, 则返回 January
%c 返回datetime的字符串表示,如03/08/15 23:01:26
%d 返回的是当前时间是当前月的第几天
%f 微秒的表示: 范围: [0,999999]
%H 以24小时制表示当前小时
%I 以12小时制表示当前小时
%j 返回 当天是当年的第几天 范围[001,366]
%m 返回月份 范围[0,12]
%M 返回分钟数 范围 [0,59]
%P 返回是上午还是下午–AM or PM
%S 返回秒数 范围 [0,61]。。。手册说明的
%U 返回当周是当年的第几周 以周日为第一天
%W 返回当周是当年的第几周 以周一为第一天
%w 当天在当周的天数,范围为[0, 6],6表示星期天
%x 日期的字符串表示 :03/08/15
%X 时间的字符串表示 :23:22:08
%y 两个数字表示的年份 15
%Y 四个数字表示的年份 2015
%z 与utc时间的间隔 (如果是本地时间,返回空字符串)
%Z 时区名称(如果是本地时间,返回空字符串)
#画图
_x = count_by_month.index
_y = count_by_month.values
#for i in _x:
# print(dir(i))
# break
_x = [i.strftime("%Y%m%d") for i in _x]
# %Y%m%d : 表示年月日
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.show()
(5)统计出911数据中不同月份不同类型的电话的次数的变化情况
首先看一个注意事项:df.set_index()一定写在pd.DataFrame()后面。
df.set_index() 使用现有列设置单(复合)索引,df.reset_index()还原索引.
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
'''
1. keys:label or array-like or list of labels/arrays,这个是需要设置为索引的列名,可以是单个列名,或者是多个列名
2. drop:bool, default True,删除要用作新索引的列
3. append:bool, default False,添加新索引
4. inplace:bool, default False,是否要覆盖数据集
5. verify_integrity:bool, default False,检查新索引是否重复。否则,将检查推迟到必要时进行。设置为False将改善此方法的性能
'''
# coding=utf-8
#911数据中不同月份不同类型的电话的次数的变化情况
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#把时间字符串转为时间类型设置为索引
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
#添加列,表示分类
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
# print(np.array(cate_list).reshape((df.shape[0],1)))
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1))) # DataFrame的索引是0,1,2,3,····
print(df.head())
df.set_index("timeStamp",inplace=True) # 这个索引是911.csv数据中timeStamp这一列
# DataFrame可以通过set_index方法,可以使用现有列设置单索引和复合索引
print("$ $ "*20)
print(df.head())
