数据结构与算法学习笔记12:排序分析/快速排序/归并排序/堆排序/递归时间复杂度/STL及C++的Sort底层实现
数据结构与算法学习笔记12:排序分析/快速排序/归并排序/堆排序/递归时间复杂度/STL及C++的Sort底层实现
-
-
- 递归函数的时间复杂度
- 排序总结表
- 快速排序(QuickSort)
-
-
-
- [快速排序时间复杂度分析 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/341201904)
-
- 优化:
-
-
- 区间分割法
- 标准值上的优化
- 数据很小时不需要再分割
- 循环+堆空间形式取代递归
-
-
- 拓展:分割一组数据的奇偶/素数合数
- 归并排序(MergeSort)
- 堆排序(HeapSort)
-
-
- 详细图解分析
-
- STL里的Sort
- C++里的Sort
- [10亿数据找到前100大的数(Top K问题)](https://zhuanlan.zhihu.com/p/441597621)
-
递归函数的时间复杂度
T ( n ) = { O ( 1 ) , n = n 0 a T ( n b ) + f ( n ) , n > n 0 T(n)=\begin{cases} O(1), n=n_0\\ aT(\frac{n}{b})+f(n), n>n_0 \end{cases} T(n)={O(1),n=n0aT(bn)+f(n),n>n0
- f ( n ) < O ( n l o g b a ) f(n)
- f ( n ) = O ( n l o g b a ) f(n)=O(n^{log_ba}) f(n)=O(nlogba),则 T ( n ) = O ( n l o g b a l o g 2 n ) T(n)=O(n^{log_ba}log_2n) T(n)=O(nlogbalog2n)
- f ( n ) > O ( n l o g b a ) f(n)>O(n^{log_ba}) f(n)>O(nlogba),则 T ( n ) = O ( f ( n ) ) T(n)=O(f(n)) T(n)=O(f(n))
排序总结表
-
最好时间复杂度(理想情况下);最坏时间复杂度(时间消耗的上限)
-
空间复杂度(有无new、malloc、递归)
-
是否稳定(判断数值相同的两个元素在排序前后的相对位置是否发生变化)
稳定性的意义:为了排序完成之后维持与原数据的相对性
| 排序名称 | 最好时间复杂度 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|---|---|
| 冒泡排序(BubbleSort) | 有序的,不用交换,遍历一次就结束: O ( n ) O(n) O(n) | O ( n 2 ) O(n^2) O(n2) | 倒序的: O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 稳定 |
| 选择排序(SelectionSort) | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 不稳定 |
| 插入排序(InsertSort) | 有序情况,直接放后面: O ( n ) O(n) O(n) | O ( n 2 ) O(n^2) O(n2) | 倒序的: O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 稳定 |
| 希尔排序(ShellSort) | O ( n 1.3 ) O(n^{1.3}) O(n1.3) | \ | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | 不稳定 |
| 快速排序(QuickSort) | O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) | O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) | 有序: O ( n 2 ) O(n^2) O(n2) | 看递归深度: l o g 2 n log_2n log2n | 不稳定 |
| 归并排序(MergeSort) | O ( n l o g 2 n ) O( nlog_2n ) O(nlog2n) | O ( n l o g 2 n ) O( nlog_2n ) O(nlog2n) | O ( n l o g 2 n ) O( nlog_2n ) O(nlog2n) | O ( n ) O(n) O(n) | 稳定 |
| 堆排序(HeapSort) | O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) | O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) | O ( n l o g 2 n ) O(nlog_2n) O(nlog2n) | O ( 1 ) O(1) O(1) | 不稳定 |
| 计数排序(CountingSort) | O ( n + m ) O(n+m) O(n+m) | O ( n + m ) O(n+m) O(n+m) | O ( n + m ) O(n+m) O(n+m) | O ( m ) O(m) O(m)/ O ( n + m ) O(n+m) O(n+m) | 稳定 |
| 桶排序(BucketSort) | O ( N + C ) O(N+C) O(N+C) | O ( N ) O(N) O(N) | O ( n 2 ) O(n^2) O(n2) | O ( N + M ) O(N+M) O(N+M) | 稳定 |
| 基数排序(RadixSort) | O ( d ∗ ( n + r ) ) O(d∗(n+r)) O(d∗(n+r)) | O ( d ∗ ( n + r ) ) O(d∗(n+r)) O(d∗(n+r)) | O ( d ∗ ( n + r ) ) O(d∗(n+r)) O(d∗(n+r)) | O ( n + r ) O(n+r) O(n+r) | 稳定 |
- PS:每一次递归的实现中,系统都会重新为变量分配空间而不是覆盖原来的空间,所以递归是有空间消耗的,而且占用内存往往很大。
- 希尔虽然用的是插入的思想,但也不稳定,原因在于:希尔如果将两个相等的数据分为不同组,一组普遍大一组普遍小,那么数据一个往前一个往后,相对位置会变。
- 计数排序CountingSort是基于非比较的排序,没有最好最坏和平均的概念,其时间复杂度就是 O ( n + m ) O(n+m) O(n+m),其中n是元素个数,m是最大最小值的差值,在不考虑存储结果的数组空间申请情况下,其空间消耗为 O ( m ) O(m) O(m),如果考虑的话就是 O ( n + m ) O(n+m) O(n+m),计数排序稳定。
快速排序(QuickSort)
分治法的思想,快速排序是通过多次比较和交换来实现排序,在一趟排序中把将要排序的数据分成两个独立的部分,找一个标准值,将比标准值小的都放在标准值左侧,将比标准值大的都放在标准值右侧,左右两半部分分别重复以上步骤进行递归排序,最终实现所有数据有序。
快速排序时间复杂度分析 - 知乎 (zhihu.com)

-
过程:(挖坑填补)
1、确定标准值
2、从后往前遍历找到比标准值小的,放入前坑;从前往后遍历找到比标准值大的,放入后坑;如此重复,直到前后相遇,在该处放入标准值
3、在标准值位置进行分割成左右两部分,分别处理(重复1/2步骤)
-
代码:
#includeint DetermineLocation(int arr[], int nBegin,int nEnd){ int temp = arr[nBegin]; while (nBegin < nEnd) { //从后向前找比标准值小的 while (nEnd > nBegin) { if (arr[nEnd] < temp) { arr[nBegin] = arr[nEnd]; nBegin++; } nEnd--; } //从前向后找比标准值大的 while (nEnd > nBegin) { if (arr[nBegin] > temp) { arr[nEnd] = arr[nBegin]; nEnd--; } nBegin++; } } //标准值放入 arr[nBegin] = temp; return nBegin; } void QuickSort(int arr[], int nBegin,int nEnd){ if (arr == NULL ||nBegin > nEnd) return; //找标准值位置 int nTemp = DetermineLocation(arr, nBegin, nEnd); //分割 QuickSort(arr, nBegin, nTemp - 1); QuickSort(arr, nTemp + 1, nEnd); } void Print(int arr[],int nLength){ if(arr == NULL || nLength <= 0) return; for (int i = 0; i < nLength; i++) { printf("%d ",arr[i]); } printf("\n"); } int main(){ int arr[] = {90,87,98,89,92,91,96,94,98}; QuickSort(arr, 0 , sizeof(arr)/sizeof(arr[0]) - 1); Print(arr, sizeof(arr)/sizeof(arr[0])); return 0; }
优化:
区间分割法
(时间空间消耗是不变的,实际上是系统效率上的优化)
上面代码中的快速排序实现由while嵌套而成,但实际上,从前向后遍历+从后向前遍历直到相遇的这个过程仅仅为一次遍历,用上while嵌套实在是太麻烦。换一种思路,如果将小的挑出来放好,实际上大的也就自动归好了,所以没有必要进行一个个放置。

-
过程:
1、小值端标记i,i=遍历的起始位置-1
2、遍历,比较大小,若比标准值小则交换,若比标准值大则处理下一个元素
3、直到尾部,将标准值(通过交换)放入
-
代码:
//optimize优化版快排(区间分割法) int DetermineLocation1(int arr[], int nBegin,int nEnd){ int nSmall = nBegin - 1; for (nBegin; nBegin < nEnd; nBegin++) { if (arr[nBegin] < arr[nEnd]) { //小区间扩张 if (++nSmall != nBegin) { arr[nSmall] = arr[nSmall]^arr[nBegin]; arr[nBegin] = arr[nSmall]^arr[nBegin]; arr[nSmall] = arr[nSmall]^arr[nBegin]; }//使用异或交换时注意,不可以位于同一物理空间上,所以需要判断++nSmall != nBegin //当然也可以用swap函数,然后也可以用中间量temp啥的方法来换~ } } //标准值放入 if (++nSmall != nEnd) { arr[nSmall] = arr[nSmall]^arr[nEnd]; arr[nEnd] = arr[nSmall]^arr[nEnd]; arr[nSmall] = arr[nSmall]^arr[nEnd]; } return nSmall; }
标准值上的优化
快排是利用分割、分治来降低效率的,那么如果极端情况下,每次标准值都是极限值,全部分到一侧,那么其分割也就失去了本身的意义,效率会很低下。为了避免极端值,可以进行标准值三选一/前中后或标准值九选一(三选一后再三选一)。除此以外,还可以进行标准值相同值的聚集的优化,这样后续遍历处理的次数会下降。
数据很小时不需要再分割
快排虽然很快,但别忘了它是基于递归的,也会有消耗,所以一般情况下小于16直接切换成插入排序。
循环+堆空间形式取代递归
拓展:分割一组数据的奇偶/素数合数
-
一组数据,奇数放一块,偶数放一块。
快排是通过比较把大的放一起,小的放一起完成分割,这个题就是判断奇偶(判断二进制最后一位是否为1 或者 取余方式 等)然后分割,实际上差不多。
-
一组数据,素数放一块,合数放一块。
一样的,反正判断出素数放一块,剩下就是合数。素数(也就是质数,指的是在大于1的自然数中,除了1和它本身以外不再有其他因数)
-
判断素数的一些方法:
1、(从2到n-1每个数均整除判断)时间复杂度O(n)
-
int isPrime(int k) { int j; for ( j=2; j<k; j++ ) { if(k%j==0) // 如果不为素数返回0 { return 0; } } return 1; // 反之则返回1 }
2、开根号法:从2到 n \sqrt{n} n均整除判断,时间复杂度 O ( n ) O(\sqrt{n}) O(n)
-
原因:素数是因子为1和本身, 如果数c不是素数,则还有其他因子,其中的因子,假如为a,b,其中必有一个大于 c \sqrt{c} c ,一个小于 c \sqrt{c} c 。所以m必有一个小于或等于其平方根的因数,那么验证素数时就只需要验证到其平方根就可以了。即一个合数一定含有小于它平方根的质因子。)
-
int isPrime(int n) { int i; for ( i=2; i<=sqrt(n); i++ ) { if(n%i==0) // 如果不为素数返回0 { return 0; } } return 1; // 反之则返回1 }
-
-
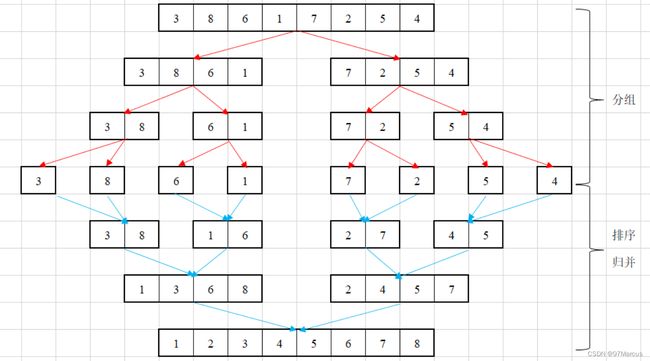
归并排序(MergeSort)
核心思想:多个有序数组合并成一个(分治法)
不管元素在什么情况下都要做这些步骤,所以花销的时间是不变的,所以该算法的最优时间复杂度和最差时间复杂度及平均时间复杂度都是一样的为: O ( n l o g 2 n ) O( nlog_2n ) O(nlog2n),归并的空间复杂度就是那个临时的数组和递归时压入栈的数据占用的空间: n + l o g 2 n n + log_2n n+log2n;所以空间复杂度为: O ( n ) O(n) O(n)。归并排序算法中,归并最后到底都是相邻元素之间的比较交换,并不会发生相同元素的相对位置发生变化,故是稳定性算法。
应用:排序、海量数据处理(分块排)、计算数组中有多少逆序对(合并的时候求取)
#include 堆排序(HeapSort)
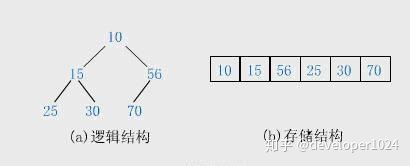
根据数值大小关系分为大根堆和小根堆。每个节点的值都大于或等于其子节点的值,也就是根节点为最大值,此为大根堆;反之为小根堆。
求前k个最大的,用小根堆;求前k个最小的,用大根堆
一般用数组来表示堆,下标为 i 的结点的父结点下标为 i − 1 2 \frac{i-1}{2} 2i−1;其左右子结点分别为 ( 2 i + 1 ) (2i + 1) (2i+1) 、 ( 2 i + 2 ) (2i + 2) (2i+2)
堆排序是一种选择排序,整体主要由构建初始堆+交换堆顶元素和末尾元素并重建堆组成。其中构建初始堆经推导复杂度为 O ( n ) O(n) O(n),在交换并重建堆的过程中需交换 n − 1 n-1 n−1次,重建堆的过程中根据完全二叉树的性质, l o g 2 ( n − 1 ) log_2(n-1) log2(n−1), l o g 2 ( n − 2 ) . . . 1 log_2(n-2)...1 log2(n−2)...1逐步递减,近似为 n l o g 2 n nlog_2n nlog2n。所以堆排序时间复杂度一般认为就是 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)级。
堆排序不稳定,原因是如果相同的数值分配在两个不同的叉上,可能一下下沉一个上升,这样相对位置有可能变。
详细图解分析
(源出处: http://www.cnblogs.com/chengxiao/)
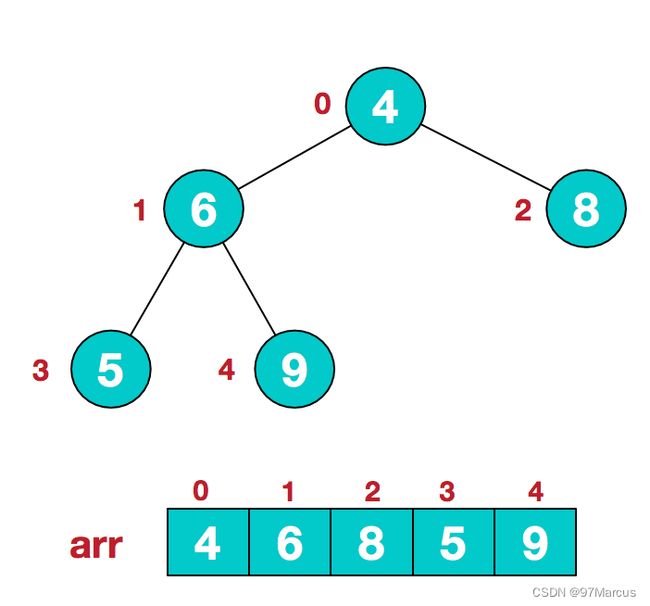
步骤一 构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。
a.假设给定无序序列结构如下
2.此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。
4.找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。
这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。
此时,我们就将一个无需序列构造成了一个大顶堆。
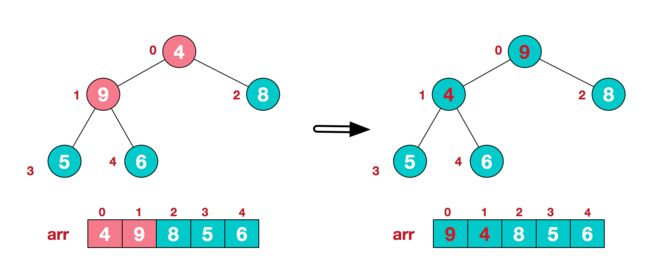
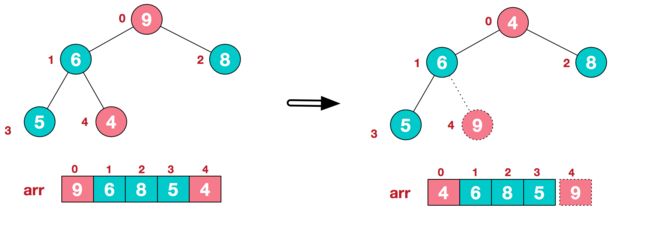
步骤二 将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
a.将堆顶元素9和末尾元素4进行交换
b.重新调整结构,使其继续满足堆定义
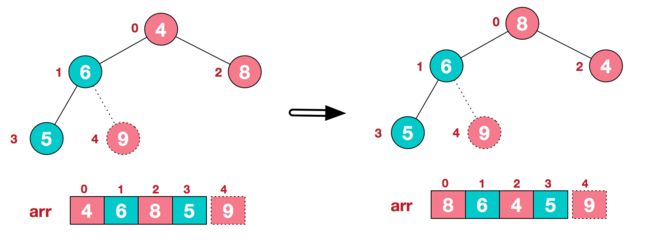
c.再将堆顶元素8与末尾元素5进行交换,得到第二大元素8.
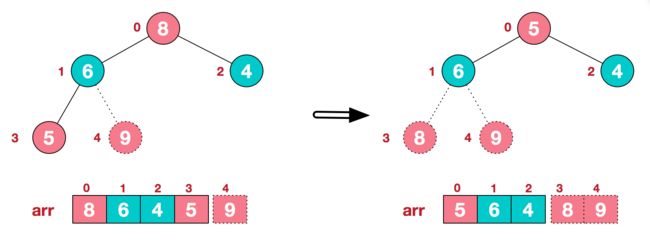
后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序。



-
步骤:
1、将无需序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
2、将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
3、重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
#include STL里的Sort
- n<16时使用插入排序
- n >16时使用快速排序(自平衡监测机制下如果分布不均匀则采用堆排序)
C++里的Sort
- n < 4时采用插入排序
- 较少的时候使用归并排序
- 较多的时候使用快速排序(用到了三选一的优化;同时,一旦递归层数过多,将会采用堆空间手动模拟递归(循环+空间消耗)的操作来进行快排的实现)