自然语言处理(一):RNN
「循环神经网络」(Recurrent Neural Network,RNN)是一个非常经典的面向序列的模型,可以对自然语言句子或是其他时序信号进行建模。进一步讲,它只有一个物理RNN单元,但是这个RNN单元可以按照时间步骤进行展开,在每个时间步骤接收当前时间步的输入和上一个时间步的输出,然后进行计算得出本时间步的输出。
Why
- CNN 需要固定长度的输入、输出,RNN 的输入和输出可以是不定长且不等长的
- CNN 只有 one-to-one 一种结构,而 RNN 有多种结构,如下图:
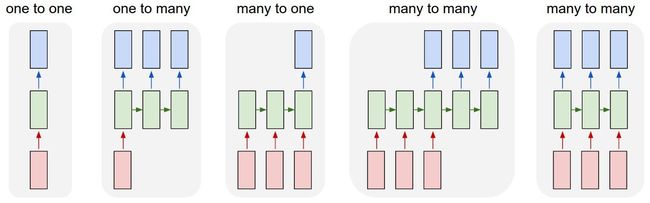
Model
-
简单模型示例

循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。「权重矩阵」 W就是「隐藏层」上一次的值作为这一次的输入的权重。
- RNN时间线展开
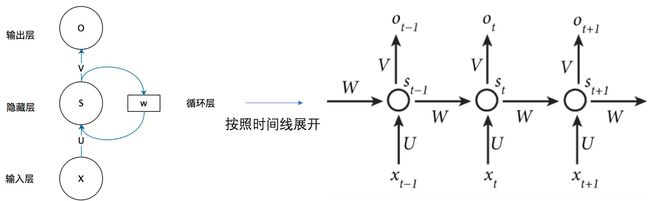
时刻的输入,不仅是 ,还应该包括上一个时刻所计算的 。
- 使用公式表示
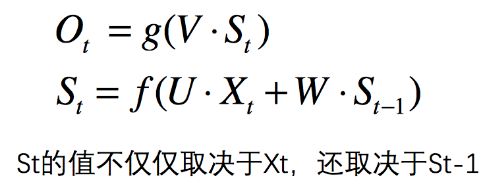
示例
下面我们举个例子来讨论一下,如图所示,假设我们现在有这样一句话:”我爱人工智能”,经过分词之后变成”我,爱,人工,智能”这4个单词,RNN会根据这4个单词的时序关系进行处理,在第1个时刻处理单词”我”,第2个时刻处理单词”爱”,依次类推。
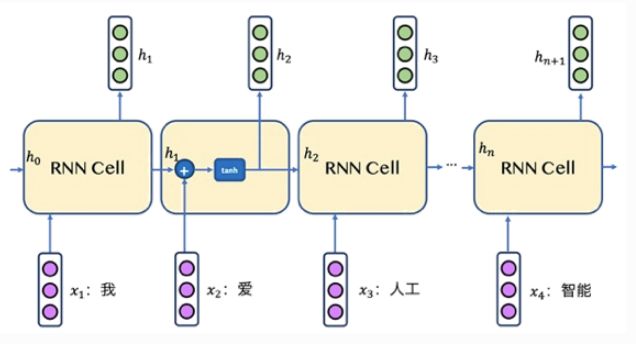
从图上可以看出,RNN在每个时刻 均会接收两个输入,一个是当前时刻的单词 ,一个是来自上一个时刻的输出 ,经过计算后产生当前时刻的输出 。例如在第2个时刻,它的输入是”爱”和 ,它的输出是 ;在第3个时刻,它的输入是”人工”和 , 输出是 ,依次类推,直到处理完最后一个单词。
总结一下,RNN会从左到右逐词阅读这个句子,并不断调用一个相同的RNN Cell来处理时序信息,每阅读一个单词,RNN首先将本时刻 的单词 和这个模型内部记忆的「状态向量」 融合起来,形成一个带有最新记忆的状态向量 。
- 「Tip」:当RNN读完最后一个单词后,那RNN就已经读完了整个句子,一般可认为最后一个单词输出的状态向量能够表示整个句子的语义信息,即它是整个句子的语义向量,这是一个常用的想法。
Code
- 数据准备
import torch
import torch.nn as nn
import numpy as np
torch.manual_seed(0) # 设置随机种子以实现可重复性
seq_length = 5
input_size = 1
hidden_size = 10
output_size = 1
batch_size = 1
time_steps = np.linspace(0, np.pi, 100)
data = np.sin(time_steps)
data.resize((len(time_steps), 1))
# Split data into sequences of length 5
x = []
y = []
for i in range(len(data)-seq_length):
_x = data[i:i+seq_length]
_y = data[i+seq_length]
x.append(_x)
y.append(_y)
x = np.array(x)
y = np.array(y)
- Model
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden):
out, hidden = self.rnn(x, hidden)
out = out.view(-1, self.hidden_size)
out = self.fc(out)
return out, hidden
- Train
model = RNN(input_size, hidden_size, output_size)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(100):
total_loss = 0
hidden = None
for i in range(len(x)):
optimizer.zero_grad()
input_ = torch.Tensor(x[i]).unsqueeze(0)
target = torch.Tensor(y[i])
output, hidden = model(input_, hidden)
hidden = hidden.detach()
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch % 10 == 0:
print(f'Epoch {epoch}, Loss: {total_loss}')
缺点
- 当阅读很长的序列时,网络内部的信息会逐渐变得越来越复杂,以至于超过网络的记忆能力,使得最终的输出信息变得混乱无用。
参考
- https://zhuanlan.zhihu.com/p/30844905
- https://paddlepedia.readthedocs.io/en/latest/tutorials/sequence_model/rnn.html
- https://saturncloud.io/blog/building-rnn-from-scratch-in-pytorch/
- https://pytorch.org/docs/stable/generated/torch.nn.RNN.html
本文由 mdnice 多平台发布