python基于ocr的视频字幕提取
导读
在无数次的996加班后的下午,忽然听见了QQ的震动,我发现有人居然给我发消息~原来是我的妹妹给我发来了消息,内容如下:
她现在正兼职帮学校帮老师配教学视频的字幕,他们配上去了,但是老师又有一个奇怪的想法。哎~ 能不能再从视频中读取字幕出来呢?
我有点为难,犹豫了。
她又说,gie~gie~ 你那么厉害肯定能做出来的!
那我只能路见不平一声吼啊~该出手时就出手,谁让我是gie~gie~呢 !?我来~~~
基本功能
根据其项目需求我们可列出下列功能:
- 可以读视频
- 识别视频中的文字区域
- 识别区域中的文字信息
由此我们可以得到如下的项目流程
项目整体流程
- 确定读取视频的手段,我整体采用的是 python+opencv
- 在字幕区域确认手段中使用 opencv的选区cv.selectROI()函数,手动确认字幕范围
- 在文字识别中我采用的是 pytesseract 技术
项目实现
环境搭建
须具有opencv开发环境,请自行上网搜寻
推荐搜索:opencv-python详细安装教教程
须具有 tesseract 开发环境,请自行上网搜寻
推荐搜索:pytesseract tesseract-ocr详细安装教教程
在使用tesseract环境时得具有中文识别数据,这个我可以提供。
下载地址:https://wwd.lanzouj.com/i0FRU01vqjoh 密码:c9oz
代码编写
包导入
from PIL import Image
import cv2 as cv
import pytesseract
import threading主处理函数
def video_handle():
while 1:
name = input("请将本软件与视频放在统一目录下并输入文件名,要有后缀例如 小明.mp4\n并且将会生成字幕文件。\n")
fxy = input("请输入视频显示时缩放程度,建议0.5-0.6 太小的数字识别度不高 例如:0.5\n")
if name == "" and fxy == "":
print("不允许为空")
continue
break
file_name = name
# 获取视频
cap = cv.VideoCapture(r"{}".format(name))
# 初始化帧率控制 左上右下
n = x = y = w = h = 0
# 区域
roi = None
while cap.isOpened():
# cap.read()
# 视频流读取
flag, frame = cap.read()
if flag is False:
break
# 根据输入重设大小
frame = cv.resize(frame, (0, 0), fx=float(fxy), fy=float(fxy))
# 以20的帧率识别
if n % 20 == 0:
# 初始化范围
if n == 0:
if input("输入1则自选区域,建议根据实际视频字幕区域选择,尽量区域选择全面\n") == "1":
# 选择范围框
roi = pic_range(frame)
# 保存位置
x, y, w, h = roi
else:
# 默认选区
x, y, w, h = 405, 971, 1194, 75
print("字幕范围", x, y, w, h)
# 长方形范围框
if n > 0:
cv.rectangle(img=frame, pt1=(x, y), pt2=(x + w, y + h), color=(0, 0, 255), thickness=2)
# 区域内图像裁剪
range_pic = frame[y:y + h, x:x + w]
# 高斯滤波降噪
throw_nosiy = cv.GaussianBlur(range_pic, (5, 5), 0)
# 灰度
GrayImage = cv.cvtColor(throw_nosiy, cv.COLOR_BGR2GRAY)
# 二值化
ret, thresh = cv.threshold(GrayImage, 127, 255, cv.THRESH_BINARY)
cv.imshow("word", thresh)
cv.imshow("pic", frame)
# 转化为pil图片模式
image = Image.fromarray(cv.cvtColor(thresh, cv.COLOR_BGR2RGB))
# 识别
pic_str(image, file_name)
# q键退出
if ord('q') == cv.waitKey(3):
break
n = n + 1
cv.destroyAllWindows()
# 释放摄像头
cap.release()文字识别
def pic_str(image, file_name):
# tesseract ocr
chi_text = pytesseract.image_to_string(image, lang="chi_sim")
# 移除多余的空格与换行
chi_text = chi_text.replace(" ", "").replace("\n", "")
if chi_text != "":
print(chi_text)
# 创建进程写入
thread = threading.Thread(target=file_save, args=(chi_text, file_name))
thread.start()字幕范围选择
在此处我原本想让他自动识别字幕的,看的人多的话我就做~~
def pic_range(img):
# 范围选择
roi = cv.selectROI(windowName="roi", img=img, showCrosshair=True, fromCenter=False)
cv.destroyAllWindows()
return roi字幕的存储
def file_save(chi_text, file_name):
with open("{}.txt".format(file_name), "a+") as f:
f.write(chi_text + "\n")效果
使用了pyinstaller将其打包成exe便于妹妹使用~
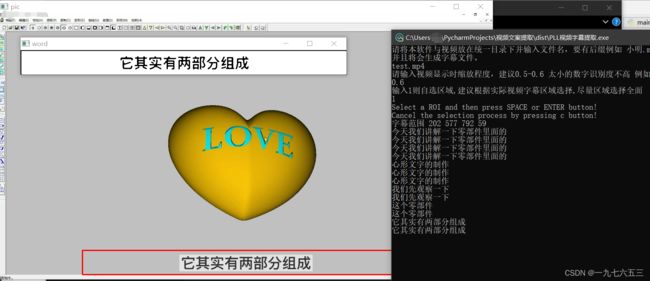
这才是最终效果!

这波效果直接拉满好吧~
最后
妹妹的鼓励才是生产的第一动力!!!
若是有代码方面的问题,评论区交流~~~看到了就会回。