Pytorch深度学习-----完整神经网络模型训练套路
系列文章目录
PyTorch深度学习——Anaconda和PyTorch安装
Pytorch深度学习-----数据模块Dataset类
Pytorch深度学习------TensorBoard的使用
Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Compose,RandomCrop)
Pytorch深度学习------torchvision中dataset数据集的使用(CIFAR10)
Pytorch深度学习-----DataLoader的用法
Pytorch深度学习-----神经网络的基本骨架-nn.Module的使用
Pytorch深度学习-----神经网络的卷积操作
Pytorch深度学习-----神经网络之卷积层用法详解
Pytorch深度学习-----神经网络之池化层用法详解及其最大池化的使用
Pytorch深度学习-----神经网络之非线性激活的使用(ReLu、Sigmoid)
Pytorch深度学习-----神经网络之线性层用法
Pytorch深度学习-----神经网络之Sequential的详细使用及实战详解
Pytorch深度学习-----损失函数(L1Loss、MSELoss、CrossEntropyLoss)
Pytorch深度学习-----优化器详解(SGD、Adam、RMSprop)
Pytorch深度学习-----现有网络模型的使用及修改(VGG16模型)
Pytorch深度学习-----神经网络模型的保存与加载(VGG16模型)
文章目录
- 系列文章目录
- 一、完整神经网络训练一般步骤
-
- 1.数据集加载步骤
- 2.模型创建步骤
- 3.损失函数和优化器定义步骤
- 4.训练循环步骤
- 5.测试循环步骤
- 6.训练和测试过程的记录和输出步骤
- 7.结束训练步骤
- 二、代码演示
- 三、对上面代码进一步总结
一、完整神经网络训练一般步骤
1.数据集加载步骤
- 使用适当的库加载数据集,例如torchvision、TensorFlow的tf.data等。
- 将数据集分为训练集和测试集,并进行必要的预处理,如归一化、数据增强等。
2.模型创建步骤
- 创建机器学习模型,可以是深度神经网络、传统机器学习模型或其它模型类型。
- 定义模型架构,包括输入层、隐藏层和输出层的结构、激活函数、损失函数等。
3.损失函数和优化器定义步骤
- 定义适当的损失函数来计算模型预测结果于真实标签之间的差异。
- 选择适当的优化器算法来更新模型参数,如随机梯度下降(SGD)、Adam等。
4.训练循环步骤
- 从训练集中获取一批样本数据,并将其输入模型进行前向传播。
- 计算损失函数,并根据损失函数进行反向传播和参数更新。
- 重复以上步骤,直到达到预定的训练次数或达到收敛条件。
5.测试循环步骤
- 从测试集中获取一批样本数据,并将其输入模型进行前向传播。
- 计算损失函数或评估指标,用于评估模型在测试集上的性能。
6.训练和测试过程的记录和输出步骤
- 使用适当的工具或库记录训练过程中的损失值、准确率、评估指标等。
- 可以使用TensorBoard、matplotlib、CSV文件等方式记录和可视化训练和测试结果。
7.结束训练步骤
- 根据训练结束条件、例如达到预定的训练次数或收敛条件,结束训练。
- 可以保存模型参数或整个模型,以便日后部署和使用。
二、代码演示
创建model.py代码如下
import torch
from torch import nn
# 搭建神经网络
class Lgl(nn.Module):
def __init__(self):
super(Lgl, self).__init__()
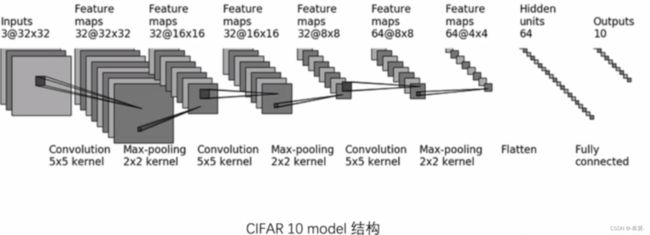
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=64*4*4, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model(x)
return x
上述模型的原图如下所示
trains.py文件开始对模型按步骤进行训练代码如下
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 加载自己搭建的神经网络
from model import *
"""
1.数据集加载
"""
# 准备训练数据集
train_data = torchvision.datasets.CIFAR10(root="dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True)
# 准备测试数据集
test_data = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 训练数据集的长度
train_data_sise = len(train_data)
print("训练数据集的长度为:{}".format(train_data_sise))
# 测试数据集的长度
test_data_sise = len(test_data)
print("测试数据集的长度:".format(test_data_sise))
# 加载数据集
train_dataloader = DataLoader(test_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
"""
2.模型的创建,这里直接from model import * 故下面直接调用
"""
# 实例化网络模型
lgl = Lgl()
"""
3.损失函数和优化器
"""
# 定义交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()
# 进行优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(lgl.parameters(), lr=learning_rate)
"""
4.训练循环步骤
4.1 为训练做的参数准备工作
"""
# 开始设置训练神经网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 记录是第几轮训练
epoch = 10
# 添加Tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("----第{}轮训练开始----".format(i))
"""
4.2 训练循环
"""
# 训练步骤
for data in train_dataloader:
imgs, targets = data
outputs = lgl(imgs)
loos_result = loss_fn(outputs, targets)
# 优化器优化模型
# 将上一轮的梯度清零
optimizer.zero_grad()
# 借助梯度进行反向传播
loos_result.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss:{}".format(total_train_step, loos_result.item()))
writer.add_scalar("train_loos", loos_result.item(), total_train_step)
"""
5.测试循环
"""
# 测试步骤开始
total_test_loos = 0
with torch.no_grad():
for imgs, targets in test_dataloader:
outputs = lgl(imgs)
loos_result = loss_fn(outputs, targets)
total_test_loos = total_test_loos + loos_result.item()
"""
6.测试过程的记录和输出
"""
print("整体测试集上损失函数loos:{}".format(total_test_loos))
writer.add_scalar("test_loos", total_test_loos, total_test_step)
total_test_step = total_test_step + 1
torch.save(lgl, "test_{}.pth".format(i))
print("模型已保存")
"""
7.结束训练步骤
"""
writer.close()
运行结果
训练数据集的长度为:50000
测试数据集的长度:
----第0轮训练开始----
训练次数:100, loss:2.2938857078552246
整体测试集上损失函数loos:359.07741928100586
模型已保存
----第1轮训练开始----
训练次数:200, loss:2.2591800689697266
训练次数:300, loss:2.263899087905884
整体测试集上损失函数loos:351.34613394737244
模型已保存
----第2轮训练开始----
训练次数:400, loss:2.175294876098633
整体测试集上损失函数loos:340.2291133403778
模型已保存
----第3轮训练开始----
训练次数:500, loss:2.096158981323242
训练次数:600, loss:1.9759657382965088
整体测试集上损失函数loos:344.92591202259064
模型已保存
----第4轮训练开始----
训练次数:700, loss:2.043778896331787
整体测试集上损失函数loos:333.33667516708374
模型已保存
----第5轮训练开始----
训练次数:800, loss:1.9719760417938232
训练次数:900, loss:1.8361881971359253
整体测试集上损失函数loos:318.2255847454071
模型已保存
----第6轮训练开始----
训练次数:1000, loss:1.832183599472046
整体测试集上损失函数loos:303.4973853826523
模型已保存
----第7轮训练开始----
训练次数:1100, loss:1.8691924810409546
训练次数:1200, loss:2.0134520530700684
整体测试集上损失函数loos:292.21254682540894
模型已保存
----第8轮训练开始----
训练次数:1300, loss:1.7631018161773682
训练次数:1400, loss:1.6039265394210815
整体测试集上损失函数loos:283.98761427402496
模型已保存
----第9轮训练开始----
训练次数:1500, loss:1.7172112464904785
整体测试集上损失函数loos:276.9621036052704
模型已保存
tensorboard中显示

三、对上面代码进一步总结
数据集加载步骤:
使用torchvision库加载CIFAR10数据集。
将训练集和测试集分别存放在train_data和test_data中。
模型创建步骤:
引用model.py文件,在其中创建名为"Lgl"的模型。
损失函数和优化器定义步骤:
定义损失函数为交叉熵损失(nn.CrossEntropyLoss)。
定义优化器为随机梯度下降(SGD)优化器,并将模型参数传递给优化器。
训练循环步骤:
从训练数据(train_dataloader)中迭代获取一个批次的图像和目标标签。
执行模型的前向传播,计算损失,执行反向传播,更新模型参数。
记录训练过程中的损失值。
每100个训练步骤后,打印当前的训练次数和损失值。
测试循环步骤:
使用torch.no_grad()上下文环境。
从测试数据(test_dataloader)中迭代获取一个批次的图像和目标标签。
执行模型的前向传播和损失计算,并累加测试集上的损失值。
损失记录和输出步骤:
使用SummaryWriter创建一个TensorBoard的日志写入器。
将训练过程中的损失值写入TensorBoard文件中。
在整个测试集上打印损失值。
结束训练步骤:
关闭TensorBoard写入器。