DDBNet:Anchor-free新训练方法,边粒度IoU计算以及更准确的正负样本 | ECCV 2020
论文针对当前anchor-free目标检测算法的问题提出了DDBNet,该算法对预测框进行更准确地评估,包括正负样本以及IoU的判断。DDBNet的创新点主要在于box分解和重组模块(D&R)和语义一致性模块,分别用于解决中心关键点的回归不准问题以及中心关键点与目标语义不一致问题。从实验来看,DDBNet达到了SOTA,整篇论文可圈可点,但里面的细节还需要等源码公开才知道
来源:晓飞的算法工程笔记 公众号
论文: Dive Deeper Into Box for Object Detection

- 论文地址:https://arxiv.org/abs/2007.14350
Introduction
目前,越来越多的目标检测算法采用anchor-free的策略,尽管性能有一定的提升,但anchor-free方法依然会有准确率约束,主要由于当前bbox的回归方法。这里,论文列举了两个当前anchor-free方法存在的问题:

- 中心关键点与目标的语义不一致。在当前的anchor-free方法中,中心关键点是十分重要的,但如图1所示,目标对应的中心关键点区域更多的是无关的背景,这会不可避免地将噪声像素作为正样本。如果使用这种简单的策略来定义正样本像素,必定会导致明显的语义不一致,造成回归准确率下降。
- 局部特征的回归有局限性。由于卷积核的大小有限,每个中心关键点对应的有效感受域可能只覆盖了目标的部分信息,仅使用关键点进行bbox回归会造成性能的下降。如图2所示,虚线预测框为中心点预测的结果,每个框都是没有完美地对齐目标。
为了解决上面的两个问题,论文提出了新的目标检测算法DDBNet,包含box分解/组合模块以及语义一致模块,分别用于解决中心关键点的回归不准问题以及中心关键点与目标的语义不一致问题,结果如图2中的实线框。论文的主要贡献如下:
-
基于anchor-free架构提出新的目标检测算法DDBNet,能够很好地解决中心关键点的回归问题以及中心关键点的语义一致性。
-
验证了中心关键点和GT的语义一致性,能够帮助提升目标检测网络的收敛性。
-
DDBNet能够达到SOTA精度(45.5%),并且能够高效地拓展到其它anchor-free检测器中。
Our Approach
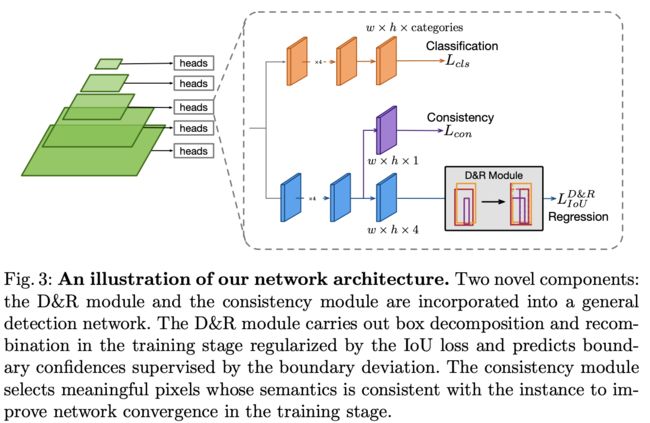
DDBNet基于FCOS搭建,如图3所示,创新点主要在于box分解和重组模块(D&R, decomposition and recombination)和语义一致性模块(semantic consistency):
- D&R模块,分解多个预测框为多个边界,然后组合成新的预测框,综合原来的预测框进行准确的训练,这个模块在预测时去掉。
- 语义一致性模块,根据像素对应的分类分数以及内在重要性,自适应地将其归为正样本像素和副样本像素。
Box Decomposition and Recombination
给定目标 I I I, I I I中的每个像素 i i i都回归一个预测框 p i = { l i , t i , r i , b i } p_i=\{l_i, t_i, r_i, b_i\} pi={li,ti,ri,bi},预测框的合集为 B I = { p 0 , p 1 , ⋯ , p n } B_{I}=\{p_0, p_1, \cdots, p_n\} BI={p0,p1,⋯,pn},4个元素分别为点到左边、上边、右边和下边的距离。常规情况下,IoU回归损失定义为:

N p o s N_{pos} Npos为所有目标区域的像素数量, p I ∗ p^{*}_{I} pI∗为回归目标,而D&R模块的目的是通过IoU损失进行优化,预测更准确的 p i p_i pi。
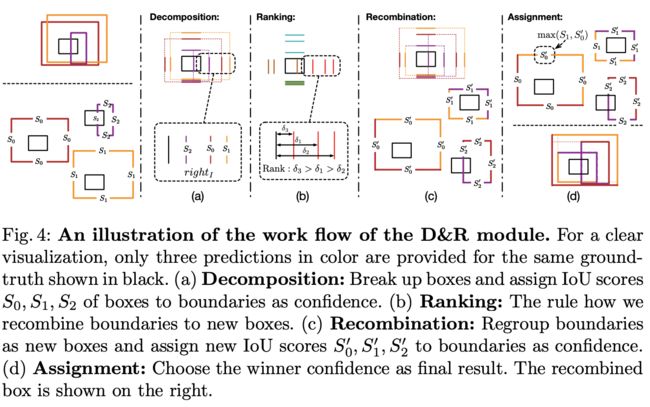
如图4所示,D&R模块基于IoU,包含四个步骤:
-
Decomposition:将预测框 p i p_i pi分解为边界 l i , t i , r i , b i l_i, t_i, r_i, b_i li,ti,ri,bi,然后将 p i p_i pi与 p I ∗ p^{*}_{I} pI∗的IoU s i s_i si赋予各边界。对于目标 I I I,边界的置信度表示为 N × 4 N\times 4 N×4矩阵 S I S_{I} SI,然后根据边界的类型组合成4个合集 l e f t I = { l 0 , l 1 , ⋯ , l n } left_{I}=\{l_0, l_1, \cdots, l_n\} leftI={l0,l1,⋯,ln}, r i g h t I = { r 0 , r 1 , ⋯ , r n } right_{I}=\{r_0, r_1, \cdots, r_n\} rightI={r0,r1,⋯,rn}, b o t t o m I = { b 0 , b 1 , ⋯ , b n } bottom_{I}=\{b_0, b_1, \cdots, b_n\} bottomI={b0,b1,⋯,bn}, t o p I = { t 0 , t 1 , ⋯ , t n } top_{I}=\{t_0, t_1, \cdots, t_n\} topI={t0,t1,⋯,tn}
-
Ranking:最优的预测框应该有最小的IoU损失,遍历目标 I I I的所有预测边界的组合来组合最优的预测框 B I ′ B^{'}_{I} BI′是个不错的选择,但直接遍历会带来巨大的计算复杂度 O ( n 4 ) \mathcal{O}(n^4) O(n4)。为了避免带来过大的计算量,论文提出了先对边界进行高效的排序。对于 I I I的每个边界集合,首先计算其与GT边界 p I ∗ = { l I , r I , b I , t I } p^{*}_I=\{ l_I, r_I, b_I, t_I\} pI∗={lI,rI,bI,tI}的偏差 δ I l \delta^{l}_{I} δIl, δ I r \delta^{r}_{I} δIr, δ I b \delta^{b}_{I} δIb, δ I t \delta^{t}_{I} δIt,然后根据其偏差值进行排序,与GT更接近的边界获得更高的排名。
-
Recombination:将不同集合中排名相同的边界组合成新预测框合集 B I ′ = { p 0 ′ , p 1 ′ , ⋯ , p n ′ } B^{'}_{I}=\{p^{'}_0, p^{'}_1, \cdots, p^{'}_n\} BI′={p0′,p1′,⋯,pn′},然后将新预测框 p i ′ p^{'}_i pi′与GT p I ∗ p^{*}_{I} pI∗的IoU赋予对应的边界,构成新的 N × 4 N\times 4 N×4矩阵 S I ′ S^{'}_{I} SI′。
-
Assignment:经过上面的步骤,得到了两组边界得分 S I S_{I} SI和 S I ′ S^{'}_{I} SI′,每个边界的最终得分为两者中的较大值。上述的分配策略直接取 S I ′ S^{'}_{I} SI′,主要考虑了以下情况:排位较低的边界组成的新预测框一般都与GT差异较大,其新分数 s i ′ s^{'}_i si′也会远低于原分数 s i s_i si,这种严重的分数偏差在训练阶段会导致回传梯度不稳定。
在模型训练时,通过IoU损失进行边界预测的优化,损失函数包含两部分:
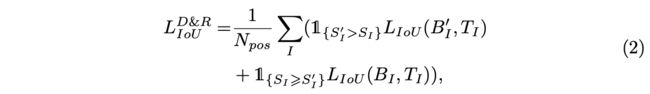
对于目标 I I I,每条边用其较高的分数进行回传梯度的计算,这里看完会有点疑问,例如 S I ′ > S I S^{'}_I > S_{I} SI′>SI是怎么对比的,原预测框的边界可能组合成了不同的新预测框。相对于原来的公式1,公式2则是以目标的角度进行优化(instance-wise fashion),综合考虑目标相关的box,也就是考虑了目标的上下文信息,而公式1是以box的角度进行优化(local-wise fashion),仅考虑每个box的局部信息。
Semantic Consistency Module
D&R模块的性能取决于使用了目标中的哪些像素作为正样本,目前的方法大都直接选择固定的中心区域像素作为正样本,而论文提出了自适应的语义一致性判断方法,能够帮助网络学习准确的像素标签空间,可公式化为:

R I R_I RI为目标 I I I的像素对应的预测框与GT的IoU分数合集, R I ‾ \overline{R_I} RI为 R I R_I RI的平均IoU分数, R I ↓ ‾ \overline{R_{I\downarrow}} RI↓为低于平均IoU分数的像素, R I ↑ ‾ \overline{R_{I\uparrow}} RI↑为高于平均IoU分数的像素。 c i ∈ C I c_i \in C_I ci∈CI为 i i i像素中分数最高的类别, g g g为总类别数, C I ↓ ‾ \overline{C_I\downarrow} CI↓为低于平均分类分数像素, C I ↑ ‾ \overline{C_I\uparrow} CI↑为低于平均分类分数像素,这里的判断是类不可知的。

根据公式3将像素归为正负样本,如图5所示,如果一个像素可归于多个目标,一般选择最小的目标。在自动地根据语义一致性对像素进行标签后,论文将每个正样本像素的内在重要性(inner significance)加入到网络训练中,用来提升语义一致性的学习,类似于FCOS的centerness。内在重要性由像素预测框与GT的IoU进行衡量,在网络中添加一个额外的语义一致性分支进行预测与学习,损失函数定义为:
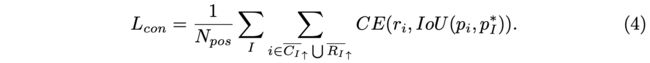
r i r_i ri为预测结果。至此,DDBNet的完整损失函数定义为:
![]()
Experiments
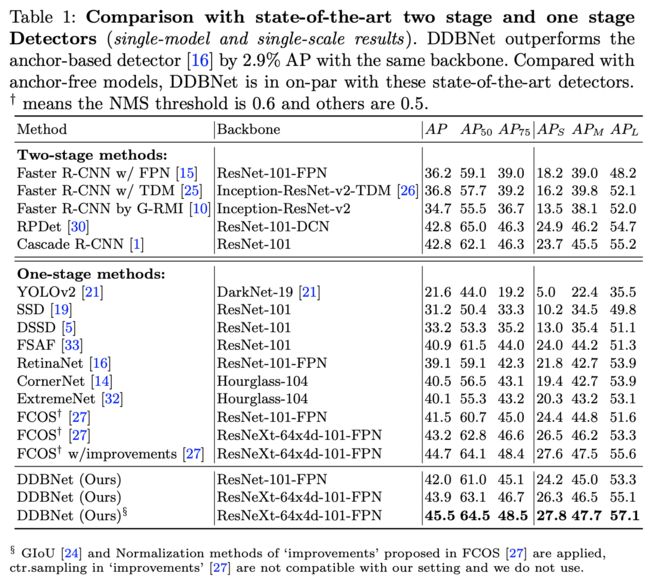
在COCO数据集上与其它方法进行对比。
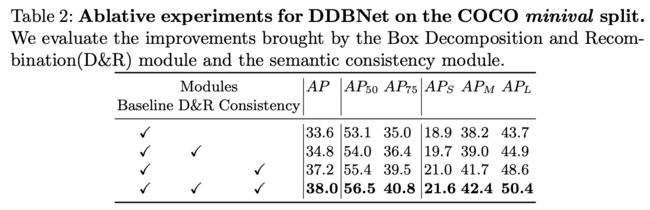
两个模块的对比实验。
CONCLUSION
论文针对当前anchor-free目标检测算法的问题提出了DDBNet,该算法对预测框进行更准确地评估,包括正负样本以及IoU的判断。DDBNet的创新点主要在于box分解和重组模块(D&R)和语义一致性模块,分别用于解决中心关键点的回归不准问题以及中心关键点与目标语义不一致问题。从实验来看,DDBNet达到了SOTA,整篇论文可圈可点,但里面的细节还需要等源码公开才知道。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
