2021斯坦福CS224N课程笔记~5
5 语言模型(LM)与循环神经网络(RNN)
参考文档:
https://zhuanlan.zhihu.com/p/424671205
https://www.showmeai.tech/article-detail/239
https://zhuanlan.zhihu.com/p/147322049 [易懂]
https://zhuanlan.zhihu.com/p/61893429
讲座计划
\1. 神经依存解析(20 分钟,复习)
\2. 关于神经网络的更多信息(15 分钟)
\3. 语言建模 + RNN(45 分钟)
• 一项新的 NLP 任务: 语言模型(LM)
激发
• 一个新的 NN 系列:循环神经网络(RNN)
这是本课程此后最重要的两个概念!
5.1.神经网络的正则化技术
机器学习的一个核心问题是,如何使学习算法(learning algorithm)不仅在训练样本上表现良好,并且在新数据或测试集上同样奏效,这样一种表现我们称之为模型的“泛化性”或“泛化能力”(gen- eralization ability )。若某学习算法在训练集上表现优异,同时在测试集上依然工作良好,则可以说该学习算法有较强的泛化能力;若某算法在训练集上表现优异(训练误差越来越小),但在测试集上却非常糟糕(测试误差越来越大),则我们说这样的学习算法并没有泛化能力,这种现象也被称为过拟合(overfitting),见图 5.1。
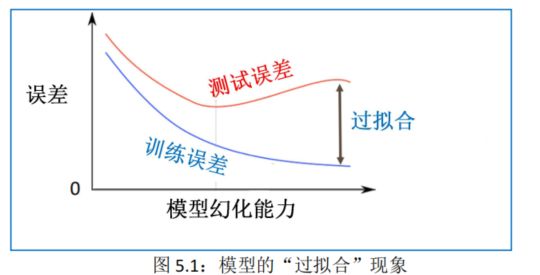
由于我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟含现象的发生,因而我们通常使用“正则化”(regularization)技术来防止过拟合情况。
正则化是机器学习中,在确保泛化能力的同时,通过显式地控制模型复杂度来避免模型过拟合。
“正则化能有效防止模型过拟合”的一种直观解释:如果将模型原始的假设空间比作“天空”,那么天空中自由飞翔的“鸟”就是模型可能收敛到的一个个最优解。在正则化后,就好比将原假设的无限空间范围(“天空”)缩小到有限的空间范围(“笼子”)。这样一来,可能得到的最优解(“鸟”)能搜寻的假设空间也变得相对有限,模型的表达能力也变得相对有限。【“天空”–>“笼子”】
许多浅层学习器(如支持向量机等)为了提高泛化性往往都要依赖模型正则化,深度学习更应如此。深度网络模型相比浅层学习器大得多的模型复杂度是把更锋利的双刃剑:保证模型更强大表示能力的同时也使模型蕴藏着更巨大的过拟合风险。深度模型的正则化可以说是整个深度模型搭建的最后一步,更是不可缺少的重要一步。
由于作为保证算法泛化的潜在工具的功能,对算法正则化的研究成为机器学习的主要研究课题。此外,在参数比训练数据集多的深度学习模型中,正则化成为非常关键的一步。正则化是一种避免算法过拟合并避免系数过拟合以随着模型复杂度增加而完美拟合的技术。当算法学习输入数据和噪声时,经常会发生过度拟合。在过去的几年里,机器学习算法提出并开发了许多==正则化方法,例如数据增强、L2正则化或权重衰减、L1正则化、dropout、drop connect、随机池化和提前停止==。
5.1.1. 数据增强(Data agumentation)
为了提高算法的性能以及满足深度学习模型对大量数据的要求,数据增强是一个需要实现的重要工具。数据增强是一种在不增加计算成本的情况下通过添加训练数据的变换或扰动来人为地增加训练集的技术。数据增强技术,例如水平或垂直翻转图像、裁剪、颜色抖动、缩放和旋转,通常用于视觉图像和图像分类应用程序。
5.1.2. L1和 L2正则化
最常用的正则化方法是 L1和 L2正则化方法。
- 在 L1正则化中,在目标函数中加入正则化项以减少参数的绝对值之和;
- 而在 L2正则化中,加入正则化项以减少参数的平方和。
从前面的论述中可以了解到,L1正则化中的许多参数向量是稀疏的,因为许多模型导致参数为零。因此,它已在需要避免或忽略许多特征的特征选择设置中实现。机器学习中最常用的正则化方法是对权重施加平方 L2 范数约束。它也被称为权重衰减(Tikhonov 正则化),因为将权重减少一个因子的净效应与梯度下降每次迭代的幅度成正比。通过权重衰减强制稀疏性是在所有较低权重上以绝对方式人为地引入零,而不是引用阈值。即使在这种情况下,稀疏性的影响也可以忽略不计。
一般说来,损失函数=误差函数+正则化项。因此,在交叉熵损失函数中引入正则化项,见图 5.2(a):
正式地说,标准正则化损失函数见图 5.2(b),其中包括 L1和 L2正则化项。
- L1正则化方法是惩罚权重的绝对大小,称为。
- L1正则化的公式在零时不可微,因此权重增加了一个接近于零的常数因子。在许多神经网络中,对于权重衰减公式应用一阶过程来解决非凸 L1正则化问题是很常见的。L1范数的近似变化由|W|1给出。
- 另一种正则化方法被认为是 L1 和 L2 正则化的混合,称为弹性净惩罚。
有了以上技术,当我们有一个“大”模型时,正则化产生的模型可以很好地泛化。我们不在乎我们的模型在训练数据上是否过拟合,即使它们非常过拟合。
5.1.3. 丢弃(Dropout)
- 大规模的神经网络有两个缺点:费时,过拟合。
- 这两个缺点真是深度学习的两个大包袱。为了解决过拟合问题,一般会采用集成(ensemble)方法,即训练多个模型做组合
- 此时,费时就成为一个大问题,不仅训练起来费时,测试起来多个模型也很费时。
总之,几乎形成了一个死锁。
Dropout 的出现很好的可以解决这个问题。
Dropout(丢弃,随机失活)是指**暂时丢弃神经元及其连接**。随机丢弃神经元可以防止过拟合,并提供了以指数方式高效组合许多不同网络架构的可能方式。
一般来说,对于一个有 N 个节点的神经网络,有了 dropout 后,就可以看做是 2n 个模型的集合了,但此时要训练的参数数目却是不变的,这就解脱了费时的问题。
每次做完 dropout,相当于从原始的网络中找到一个更瘦的网络。最常用的 dropout 方法是 Hinton 等人在 2012 年推出的 Standard dropout,见图 5.3:
为了防止训练阶段的过拟合,随机去掉神经元。在一个密集的(或全连接的)网络中,对于每一层,我们给出了一个 dropout 的概率 p。在每次迭代中,每个神经元被去掉的概率为 p。Hinton 等人的论文建议,输入层的 dropout 概率为“p=0.2”,隐藏层的 dropout 概率为“p=0.5”。显然,我们对输出层感兴趣,因为这是我们的预测。所以我们不会在输出层应用 dropout。
根据 Srivastava、Hinton、Krizhevsky、Sutskever 和 Salakhutdinov 等人(2012/JMLR 2014)的研究,得出如下结果:

5.1.4. 断开连接(Dropconnect)
Dropconnect 是另一种减少算法过拟合的正则化策略,它是 Dropout 的泛化。在 drop connect 中,将架构内随机选择的权重子集设置为零,而不是在每层内将随机选择的激活子集设置为零。 由于每个单元从前一层单元的随机子集接收输入,因此实现了 dropout 和 dropconnect 的有界泛化性能。
Dropconnect 与 dropout 类似,因为它涉及在模型中引入稀疏性,但不同之处在于权重的稀疏性而不是层的输出向量。
5.1.5. 提前停止(Early stopping)
- 提前停止提供了对需要执行的次数(迭代)的指导,以最小化成本函数。提前停止通常用于**防止过度表达模型在训练中泛化不良**。
- 如果使用的传递次数太少,算法往往会欠拟合(减少方差但鼓励偏差),如果使用的传递次数太高(增加方差但减少偏差),算法往往会过拟合。
- 提前停止技术用于通过确定传递次数和消除手动设置值来解决此问题。
- 背后的基本思想是,将可用数据分为三个子集,即训练集、验证集和测试集。
- 训练集用于通过梯度下降优化计算权重和偏差,其中验证测试用于监控训练过程。
- 随着训练集和验证集通过次数的增加,计算误差趋于减少。
- 但是,如果算法开始过度拟合数据,验证错误就会开始增加。
- 训练集用于通过梯度下降优化计算权重和偏差,其中验证测试用于监控训练过程。
- 背后的基本思想是,将可用数据分为三个子集,即训练集、验证集和测试集。
- 早期停止技术提供了**在验证错误偏差开始时停止传递(迭代)**并返回权重和偏差值的可能性。提前停止也用于提升非凸损失函数的优化和提升算法的泛化。
5.2.神经网络的优化算法
优化算法就是一种==能够帮我们最小化或者最大化目标函数(有时候也叫损失函数)==的一类算法。而目标函数往往是模型参数和数据的数学组合。
例如给定数据 X 和其对应的标签 Y,我们构建一个线性模型 f ( x ) = W x + b 。有了模型后,根据输入 x就可以得到预测输出 f ( x ),并且可以计算出预测值和真实值之间的差距( f ( x ) − Y)2 ,这个就是损失函数。我们的目的是找到合适的 W 和 b,使上述的损失函数的值达到最小。损失值越小,则说明我们的模型越接近于真实情况。
通过上面的描述可以知道,模型的内参(W , b)在模型中扮演着非常重要的角色,而这些内参的更新和优化就用到我们所说的优化算法。
所以优化算法也层出不穷,而一个好的优化算法往往能够更加高效、更加准确的训练模型的内参。
一般来说,根据优化算法在优化过程中使用的导数阶数。可以将优化算法可以分为两大类:一阶优化算法和二阶优化算法。
-
一阶优化算法是指使用参数梯度值来最小化或者最大化损失函数的优化算法。
- 最为广泛应用的就是**梯度下降法**,参数的一阶导能够清晰的告诉我们损失函数在某个特定点上是增加的还是减少的。
- 那**什么是梯度呢?简而言之,梯度就是函数输出关于y的偏导数**,只不过这里的输入和输出并不是简单的数值,而是向量。
- 梯度与导数的区别就是导数是单个变量的,而梯度是多个变量的。梯度往往采用雅克比矩阵(Jacobian Matrix)进行表达。
- 最为广泛应用的就是**梯度下降法**,参数的一阶导能够清晰的告诉我们损失函数在某个特定点上是增加的还是减少的。
-
二阶优化算法就是采用二阶导数进行优化算法。二阶导数,有时候也被成为海森矩阵(Hessian)。
- 因为二阶导数要求两次导数,尤其是在矩阵中进行求导,运算量会非常的大,所以二阶优化算法被用的比较少。
在技术上,我们把优化算法做成一个优化器。
一般来说,普通的 SGD 就可以正常工作!然而,获得好的结果通常需要手动调整学习率。
对于更复杂的网络和情况,已经研发出一系列更复杂的**“自适应”优化器**,它们通过累积梯度来缩放参数调整。下面介绍各种模型给出不同的每个参数学习率。
5.2.1. Momentum(动量)
随机梯度下降和小批量梯度下降最常用于机器学习算法来优化成本函数。然而,算法的学习有时在大规模应用上很低。 开发动量策略是为了加速学习过程,尤其是在高曲率的情况下。 动量算法利用先前梯度值的指数衰减移动平均值,并倾向于向该方向回落。该算法引入了一个变量 v 作为速度向量,参数在该速度向量中继续在参数空间中移动。 速度设置为负梯度的指数衰减平均值。 对于要最小化的给定成本函数,动量表示为:

其中,α是学习率,γ∈(0, 1]是动量系数。v 是速度向量,θ是与速度向量同向的参数。通常,随机梯度下降会将梯度下推到最陡峭长浅沟的一侧而不是沿着沟朝向最优。因此 SGD (Stochastic Gradient Descent | 随机梯度下降)算法变得非常慢的收敛。动量是将沿着沟的梯度推向最优的策略之一。
在实践中,γ最初设置为 0.5,直到初始学习稳定,然后增加到 0.9。 此外,由于梯度的幅度较大,α 被设置得非常小。
5.2.2. Nesterov accelerated gradient(NAG)
Nesterov 加速梯度(NGA)类似于经典动量算法,一阶优化,但梯度评估不同。 在 NAG 中,梯度是在执行速度之后计算的。 该 NAG 的更新由参数给出,与收敛速度更好的动量算法相同。在批量梯度下降中,对于平滑的凸函数,从 1/k 到 1/k 2 的收敛速度。 然而,在 SGD 中,Nesterov 加速梯度并没有提高收敛速度。 NAG 的更新由下式给出:

动量系数γ设为 0.9。 在经典动量算法中,首先计算当前梯度,然后针对更新的累积梯度。 相反,梯度指向更新的累积梯度并进行校正。这导致防止算法过快并提高响应能力。
5.2.3. Adagrad
Adagrad 被称为自适应梯度,允许学习率α根据参数进行调整,并消除调整学习率的必要性。
- 较大的更新对不频繁的参数进行,较小的更新对频繁的参数进行。
- 因此,它成为稀疏数据(如图像识别和自然语言处理)的自然候选者
- 然而,adagrad 最大的问题被认为是,在某些情况下,学习率变得太小,网络会随着学习率单调递减而停止学习过程。
- 在经典动量算法和 Nesterov 加速梯度参数更新中,对所有参数进行更新,并在学习上使用相同的学习率。
- 在 adagrad 中,每次迭代时对每个参数使用不同的学习率。

5.2.4. Adadelta

5.2.5. RMS prop

5.2.6. Adam★★
Adam 被称为自适应矩估计,是另一种计算参数自适应学习率的技术。 与 adadetla 和 RMS prop 类似,Adam 优化器存储先前平方梯度vi的指数衰减平均值,但也类似于动量,它保留先前历史梯度mi的指数衰减平均值,

5.2.7. Nadam
Nesterov 加速自适应动量估计器 (Nadam) 是 NAG 和 Adam 优化器的组合。 如果过去历史平方梯度的指数衰减平均值为vt,过去历史梯度的指数衰减平均值为mt,则经典动量更新规则为


5.2.8. 小结
总体上,Adam 在实践中表现良好,并且优于其他自适应技术。Adam 在许多情况下都是一个相当好的、安全的起点。
事实上,如果你的数据比较稀疏,那么像 SGD,NAG 以及 Momentum 的方法往往会表现的比较差,这是因为对于模型中的不同参数,他们均使用相同的学习率,这会导致那些应该更新快的参数更新的慢,而应该更新慢的有时候又会因为数据的原因的变得快。因此,对于稀疏的数据更应该使用 Adaptive 方法(
Adagrad、Adadelta、Adam)。同样,对于一些深度神经网咯或者非常复杂的神经网络,使用 Adam 或者其他的自适应(Adaptive)的方法也能够更快的收敛。
5.3.神经网络的更多细节
5.3.1. 词向量:矢量化
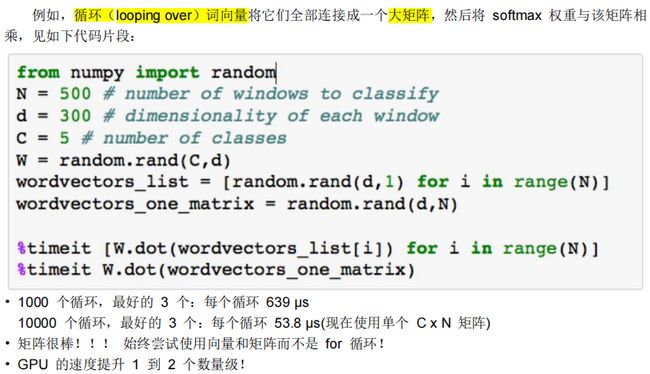
5.3.2. 激活函数:非线性★★
“激活函数”,又称**“非线性映射函数”**,是深度卷积神经网络中不可或缺的关键模块。可以说,深度网络模型强大的表示能力大部分是由激活函数的非线性带来的。
激活函数在神经元中非常重要,为了增强网络的表示能力和学习能力,激活函数需要具备以下性质:
(1) 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参数。
(2) 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
(3) 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
下面是当下深度卷积神经网络中常用的激活函数:Sigmoid 型函数、tanh(x)型函数、修正线性单元(ReLU)、Leaky ReLU、参数化 ReLU、Swish,见图 5.4


5.3.3. 网络参数:初始化
神经网络模型一般依靠随机梯度下降法 SGD进行模型训练和参数更新,网络的最终性能与收敛得到的最优解直接相关,而**收敛效果实际上又在很大程度上取决于网络参数最开始的初始化。理想的网络参数初始化可以使模型的训练事半功倍;糟糕的初始化方案不仅会影响网络收敛甚至会导致“梯度弥散”或“爆炸”致使训练失败。面对如此重要而充满技巧性的模型参数初始化,对于没有任何训练网络经验的使用者,他们往往不敢从头训练(from scratch)自己的神经网络。那么,关于网络参数初始化都有哪些方案?哪些又是相对有效、健壮的初始化方法?下面介绍和比较目前实践中常用的几种网络参数初始化方式**。
5.3.3.1. 全零初始化
当网络达到稳定状态时,参数(权值)在理想情况下应该保持正负各半(此时期望为 0)。因此一种看起来简单的方法,干脆将所有参数都初始化为 0, 因为这样可以使得初始化全零时参数的期望与网络稳定时参数期望一致。但是,如果把所有参数初始化为 0,那么每一层的神经元的东西都一样的(输出是一样的),而且 BP (反向传播)的时候,每一层的神经元也是一样的,这样会令更新后的参数仍然保持一样的状态。这是换句话说,如果参数进行了全零的参数化,那么网络神经元将无法训练模型。
5.3.3.2. 随机初始化
将参数随机化自然是打破上述“僵局”的一个有效手段,不过我们仍然希望所有参数的期望接近 0。遵循这个原则,可以将参数设置为接近 0 的很小的随机数(有正有负)。在实际应用中,随机参数服从高斯分布或者均匀分布(uniform distribution)都是有效的初始化方法。
5.3.3.3. Xavier 初始化

5.3.3.4. 何凯明初始化
-
但是上述方法有着自己的不完美之处,即只能用于线性映射,而没有考虑非线性映射对输入 s 的影响。
- 因为使用如 RELU 函数等非线性映射后,输出的期望往往不是 0。
-
因此 He(何凯明)想出改进方法:将非线性映射造成的影响考虑进参数初始化中。
-
它们提出原本 Xavier 方法中方差归一化分母应为 sqrt(n/2)而不
是 sqrt(n)。因此,这种初始化方法叫 He initialization。
5.3.4. 超参数设定:学习率α


5.4.语言模型(LM)★★★
5.4.1. 语言模型概述
语言模型最典型的应用就是“输入法联想”。 比如我在搜狗输入法里写一个“我”,输入法会给我推荐几个词:“女朋友”、“刚刚”、“的”等等。【预测下一个单词是什么】
为啥会推荐这些词呢,可能是搜狗对我曾经输入过的成百上千句话训练过语言模型,知道了我输入“我”之后,很大概率会接着输入“女朋友”,也有很大概率输入“刚刚”,因此输入法就把这些词给排到了前面。 在一些社交平台上,我们也会经常玩一个游戏:“给定一个初始词,不断通过自己输入法的联想词来造句,看看会造出什么句子来”,往往我们发现可以构成一个完整的说得通的句子,甚至还能暴露出我们个人的一些习惯。
- 问题 :如何学习一个语言模型?
- 回答 (pre-DeepLearning):学习一个 n-gram 语言模型 【 5.4.2. n-gram 语言模型】
语言模型计算特定序列中多个单词出现的概率。 m 个单词序列 {w1,…,wm} 的概率表示为P(w1,…,wm)。由于单词 wi 先前的单词数量取决于其在输入文档中的位置,因此 P(w1,…,wm)通常取决于 n个先前单词的窗口,而不是所有的先前单词:
![]()
方程 5.33 在语音识别和机器翻译系统对判断一个单词序列是否为一个输入句子的准确翻译起到了重要的作用。在现有的机器翻译系统中,对每个短语/句子翻译,系统生成一些候选的单词序列(例如,{I have,I has,I had,me have,me had}),并对其评分以确定最可能的翻译序列。
在机器翻译中,对一个输入短语,通过评判每个候选输出词序列的得分的高低,来选出最好的单词顺序。为此,模型可以在不同的单词排序或单词选择之间进行选择。它将通过一个概率函数运行所有单词序列候选项,并为每个候选项分配一个分数,从而实现这一目标。最高得分的序列就是翻译结果。例如,相比 small is the cat,翻译系统会给 the cat is small 更高的得分;相比 walking house after school,翻译系统会给 walking home after school 更高的得分。
通俗地说,定义一:语言模型(LM)的任务就是预测一段文字接下来会出现什么词:

翻译过来就是,在已知一句话的前t个词的基础上,通过LM可以计算出下一个词是某个词的概率。
理论上说,您还可以将语言模型==定义二:语言模型(LM)给一段文本赋予一个概率==。如果我们有一些文本,那么这个文本的概率(有语言模型提供)是:
即对于一段文字 x(1),x(2),…,x(T),LM可可以计算出这句话出现的概率
![]()
下面看两个例子:
例 1:手机屏幕上的文字输入。当你输入 I’ll meet you at the 时,手机就会自动计算概率分布,并且弹出单词 cafe、airport、officede 等等,供你选择,见图 5.6:
例 2:网页搜索上的文字输入。当你在输入框例输入 what is the 时,输入框下面就会弹出很多选项供你选择,见图 5.7:
5.4.2. n-gram 语言模型★★★
所谓的N-gram,就是指一堆连续的词,根据这一堆词的个数,我们可以分为unigram,bigram,trigram等等。
- 如果我们需要得到一个N-gram的LM,它的意思就是希望我们可以**通过N-1个词预测第N个词的概率**。
- 那么如何学习得到一个N-gram的LM呢?一个直接的思路就是,我们可以收集关于语料中的各个N-gram出现的频率信息。
- 收集关于不同n-gram出现频率的统计数据,并使用这些数据预测下一个单词。
- 对于一个N-gram的LM,我们需要做一个假设:
- 某个词出现的概率只由其前N-1个词决定。
- 比如我们想得到一个3-gram的LM,那么就是说想预测一段文本的下一个词是什么的话,只用看这个词前面2个词即可。
- N-gram的LM用公式表达即为:
- 如何计算得到这些概率值呢?————数它就完事儿了! 我们就在语料中去count,用频率来估计这些概率。
- LM的一些严重问题
- 「稀疏性问题」 **「存储问题」**N的取值
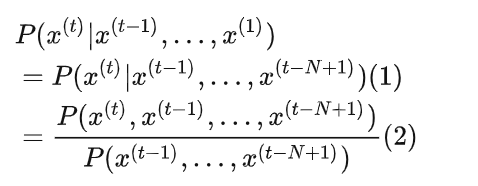
定义:一个 n-gram(n 元语法) 是一个**由 n 个连续单词组成的块**。

例如,如果选择 bi-gram 模型,每一个 bi-gram 的频率,通过将单词与其前一个单词相结合进行计算,然后除以对应的 uni-gram 的频率。下面两个方程展示了 bi-gram 模型和 tri-gram 模型的区别。

方程 5.36 的关系主要是基于一个固定的上下文窗口【其缺点–>RNN对此进行改进】(即前 n 个单词)预测下一个单词。
- 一般 n 的取值为多大才好呢?
- 在某些情况下,前面的连续的 n 个单词的窗口可能不足以捕获足够的上下文信息。
- 例如,考虑句子(类似完形填空,预测下一个最可能的单词)“As the proctor started the clock, the students opened their ”。如果窗口只是基于前面的三个单词“the students opened their”,那么基于这些语料计算的下划线中最有可能出现的单词就是“books”——但是如果 n 足够大,能包括"proctor"的上下文,那么下划线中最优可能出现的单词会是“exam”。
- 在某些情况下,前面的连续的 n 个单词的窗口可能不足以捕获足够的上下文信息。
那么问题来了:如何学习语言模型?


这就引出了 n-gram 语言模型的两个主要问题:稀疏性和存储。
5.4.2.1. n-gram 语言模型的稀疏性问题
我们前面提到过分子分母很容易为0,就是由于N-gram的稀疏性造成的,N越大,这种稀疏性的问题就越严重,可能你统计的大多数N-gram都不存在。
这些模型的稀疏性问题是由两个情况引起的,见图 5.10:

首先,注意公式 5.36 的分子。如果w1 , w2 , w3在语料中从未出现过,那么w3的概率就是 0。为了解决这个问题,在每个单词计数后面加上一个很小的δ,这就是**平滑(smoothing)**操作。
然后,考虑公式 5.36 的分母。如果w1, w2在语料中从未出现过,那么w3的概率将会无法计算。为了解决这个问题,这里可以只是单独考虑w2,这就是回退
(backoff)操作。注意:增加 n 会让稀疏问题更加严重,所以一般 n≤5。
5.4.2.2. n-gram 语言模型的存储问题
虽然这种基于计数的LM的很简单,但是我们必须穷举出预料中所有可能的N-gram,并逐一去计数、保存,N一旦大起来的话,模型的大小就会陡增。
N太大了会有过于稀疏、难以保存的问题,相反,N太小了,模型的预测**「准确率」**就会明显降低。
我们知道需要存储在语料库中看到的所有 n-gram 的统计数。随着 n 的增加(或语料库大小的增加),模型的大小也会增加,【但是在RNN中的权重序列W不会随着语料库的增加而变化】见图 5.11:

5.4.2.3. n-gram 语言模型的应用实例
您可以在几秒钟内在笔记本电脑上构建一个超过 170 万字的语料库(路透社)的简单三元语言模型,您可以自己尝试:https://nlpforhackers.io/language-models/。您还可以使用语言模型来生成文本,见图 5.12。

5.4.3. 基于窗口的神经语言模型 (NNLM)★★
Bengio 的论文《A Neural Probabilistic Language Model》中首次解决了上面所说的“维度灾难”,这篇论文提出一个自然语言处理的大规模的深度学习模型,这个模型能够通过学习单词的分布式表示,以及用这些表示来表示单词的概率函数。图 5.13 展示了对应的神经网络结构,在这个模型中,输入向量在隐藏层和输出层中都被使用。


例如构建一个基于固定窗口的神经语言模型。
首先,了解一下固定窗口的案例,见图 5.15:

然后,建立一个固定窗口神经语言模型,图 5.16:

Bengio 模型对 n-gram LM 的改进:
• 没有稀疏问题。
• 没有存储问题:不需要存储所有观察到的 n-gram。
遗留问题:
• 固定窗口太小
• 放大窗口放大 W
• 窗口永远不够大!
•x (1) 和 x (2) 乘以 W 中完全不同的权重。输入的处理方式不对称。
因此,我们需要一个可以处理任何长度输入的神经架构。
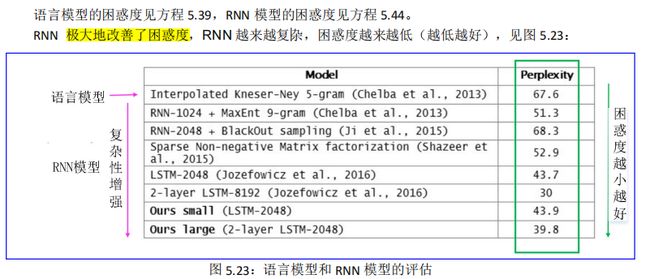
5.4.4. 语言模型的评估指标:困惑度

5.5.循环神经网络 (RNN)★★★★★
我们知道,==语言模型最直接的用途,就是文本联想,和文本生成==了。
对于文本联想,这种基于计数的LM也不是不能用,毕竟联想出来的词确实在统计意义上是更加频繁的,所以用户直接感受不出它的缺点。
但对于文本生成来说,这种基于计数的LM则有很大问题了。这里拿CS224N的PPT上的一个例子来说明:
today the price of gold per ton , while production of shoelasts and shoe industry , the bank intervened just after itconsidered and rejected an imf demand to rebuild depletedeuropean stocks , sept 30 end primary 76 cts a shai这段文字中高亮的"today the"是预先给定的文本,后面则是通过LM一个字一个字预测出来形成的文本。 这段文本,牛逼之处在于,它的语法基本没啥错,可以我们读完之后,完全不知道在讲啥,因为它说着说着就说偏了,再说一会又偏了,导致整个文本没有一个清晰的主题。很明显,这里训练的LM采用的N-gram一定不大。但是N一大起来,训练起来又很困难。这就是基于计数的LM的困境。
前面讲到的基于计数的LM的缺点,主要就是由它的N-gram的N不能太大又不能太小的限制造成的。 如果能有一个结构,可以处理任意长度的输入,而不是要固定一长度的话,那就可以解决这个问题了。
RNN即循环神经网络,为何叫循环呢?==因为不管RNN有多长,它实际上都是在「同一个神经网络中不断循环」,例如图中话的4个隐层神经网络,实际上都是同一个,因此他们的**「权重都是一样」**的,只是根据输入的不同,而产生不同的输出==。
5.5.5. RNN 的优点、缺点
- 当然,这些问题都是后话了,后面我们学习的GRU,LSTM乃至Transformer都是在不断改进RNN的种种缺点。
如何训练一个基于RNN的LM呢?
- 5.5.3. RNN 模型训练和反向传播
训练好RNN了之后,如何进行文本生成呢?
- 输入一个词,每一步的输出都作为下一步的输入,这样就可以通过一个词不断进行文本生成了。
- 5.5.6.4. 应用 4:生成文本
如何评价一个语言模型呢?
- 使用**「Perplexity」**(困惑度):5.5.2. RNN 的损失函数和困惑度
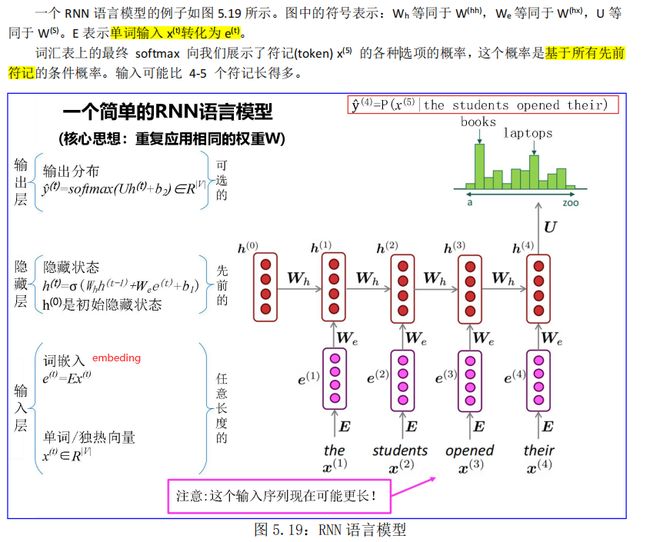
5.5.1. RNN 网络架构和 RNN 语言模型★★★
在传统翻译模型中,只考虑**==有限窗口(n)的先前单词**来调节语言模型。与传统的翻译模型不同,循环神经网络 (RNN) 能够根据语料库中的所有先前单词==来调节模型。
图 5.17 介绍了 RNN 架构,其中每个垂直矩形框都是时间步 t 处的隐藏层。
- 每个这样的层都有许多神经元,每个神经元对其输入执行线性矩阵运算,然后是非线性运算(例如 tanh())。
- 在每个时间步,隐藏层有两个输入:前一层 ht−1 的输出,以及该时间步 xt 的输入。
- 前者输入乘以权重矩阵 W(hh),后者乘以权重矩阵 W(hx) ,以产生输出特征 ht ,这些特征与权重矩阵 W(S) 相乘并通过词汇表的 softmax 运行获得下一个单词的预测输出ŷ(方程 5.40 和 5.41)。
每个单个神经元的输入和输出如图 5.18 所示。

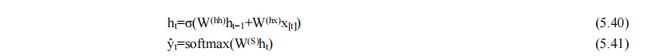
在这里一个有意思的地方是在每一个时间步使用相同的权重【并且这个权重不会随着语料库的变化而变化】 W(hh)和 W(hx)。这样模型需要学习的参数就变少了,这与输入序列的长度无关——从而解决了维度灾难。


5.5.2. RNN 的损失函数和困惑度★★
通过公式的变形,我们可以发现这个**困惑度,等价于交叉熵损失函数**:所以,我们在优化RNN LM的时候,就是在使劲降低perplexity。

5.5.3. RNN 模型训练和反向传播★★
首先,我们收集一大批语料,这些语料是由很多个序列(句子、短语等等)组成的。 我们把序列作为输入,输入到RNN网络中,每一步都可以得到一个输出,这个输出即为当前步的下一个词的概率分布。我们使用这个概率分布可以和真实的概率分布(其实就是一个one-hot向量)计算一个损失。明确了损失函数,我们就很容易去训练了。CS224N中的一张图描绘地很清晰:
RNN 模型训练的过程如图 5.20 所示:
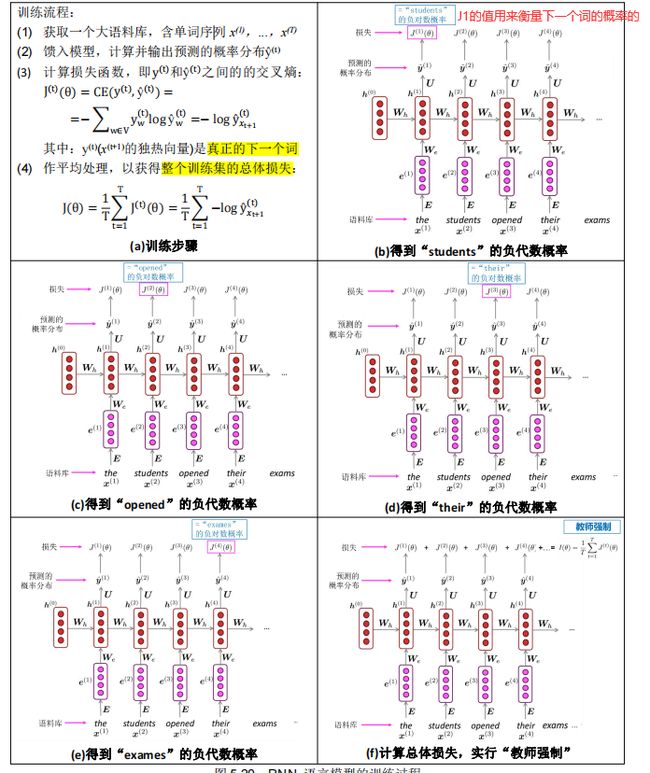
但是,上述过程要计算整个语料库 x(1),…,x(T)的总体损失和梯度,花费太昂贵了!
因此,在实践中,将 x(1),…,x(T)视为一个句子(或一个文档)。
我们回顾一下,前文提到随机梯度下降允许我们计算小块数据的损失和梯度,并进行更新。
因此,我们==只针对一个句子(实际上是一批句子)而不是整个语料库,计算梯度并更新权重。依此重复,则训练成本就会大幅下降==。
RNN 的反向传播牵涉两个问题:



5.5.4. RNN 模型的评估
5.5.5. RNN 的优点、缺点★
RNN 有以下优点:
(1) 它可以处理任意长度的序列
(2) 对更长的输入序列不会增加模型的参数大小
(3) 对时间步 t 的计算(在理论上)可以利用前面很多时间步的信息
(4) 对输入的每个时间步都应用相同的权重(wh、we),因此在处理输入时具有对称性
但是 RNN 也有以下缺点:
(1) 计算速度很慢——因为它每一个时间步需要依赖上一个时间步,所以不能并行化
(2) 在实际中因为梯度消失和梯度爆炸,很难利用到前面时间步的信息。
当输入过长的时候,难以捕捉长距离依赖。
运行一层 RNN 所需的内存量与语料库中的单词数成正比。例如,我们把一个句子是为一个 minibatch,那么一个有 k 个单词的句子在内存中就会占用 k 个词向量的存储空间。同时,RNN 必须维持两对 W 和 b矩阵。然而 W 的可能是非常大的,它的大小不会随着语料库的大小而变化(与传统的语言模型不一样)。对于具有 1000 个循环层的 RNN,矩阵 W 的大小为 1000×1000 而与语料库大小无关。
RNN 可以应用在很多任务,例如标注任务(词类标注、命名实体识别),句子分类(情感分类),编码模块(问答任务,机器翻译和其他很多任务)。在后面的两个任务,我们希望得到对句子的表示,这时可以通过**采用该句子中时间步的所有隐藏状态的逐元素的最大值或平均值来获得**。
RNN 模型有两种表达方式,见图 5.24:

5.5.6. RNN 的应用

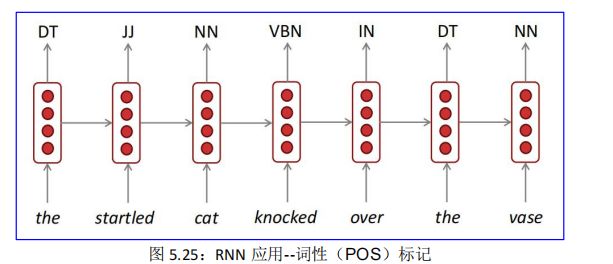
5.5.6.1. 应用 1:序列标注
序列标注问题包括自然语言处理中的分词,词性(POS)标注,命名实体识别,关键词抽取,词义角色标注,等等。我们只要在做序列标注时给定特定的标签集合,就可以进行序列标注。
序列标注问题是 NLP 中最常见的问题,因为绝大多数 NLP 问题都可以转化为序列标注问题,虽然很多NLP 任务看上去大不相同,但是如果转化为序列标注问题后其实面临的都是同一个问题。图 5.25 是词性(POS)标注的一个应用:
5.5.6.2. 应用 2:情感分类
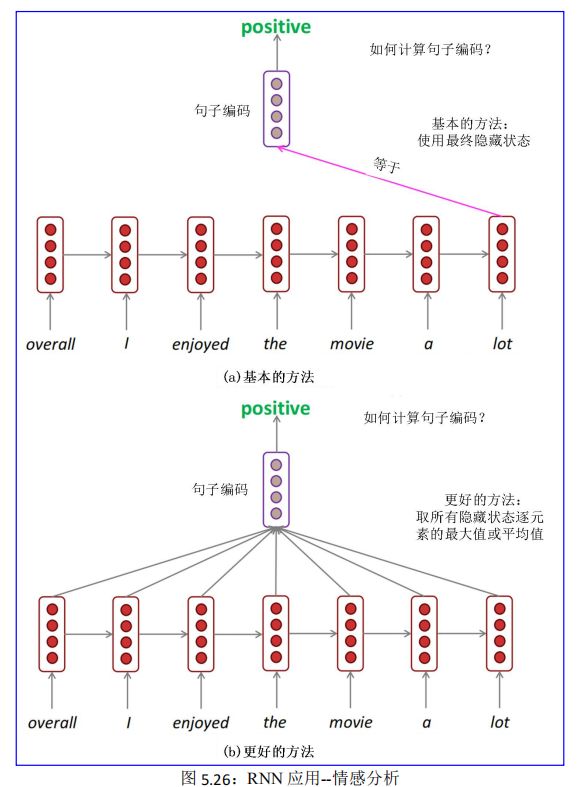
情感分类来分析文本作者的情绪,结果一般为以下三者之一:积极的(positive)、消极的(negative)或者中性的。
例如,我们可以分析用户对电影的评论并统计用户的满意度,如果一个评论句子是 overall I enjoyed the movie a lot,则结果是积极的(positive)。
利用 RNN 来作情感分析,关键技术是句子编码,那么如何计算句子编码?一般有两种方式:
基本的方式:使用最终隐藏状态,见图 5.26(a)。
更好的方式:取所有隐藏状态的元素最大值或平均值,见图 5.26(b)。
5.5.6.3. 应用 3:编码器模块
问答系统、机器翻译等许多 NLP 任务,都要用到编码器和解码器模块,这两个模块一般搭配使用,但是也可以单独使用,例如图 5.27 所示。其中 RNN 充当问题的编码器(隐藏状态代表问题)。编码器是更大的神经系统的一部分。

5.5.6.4. 应用 4:生成文本
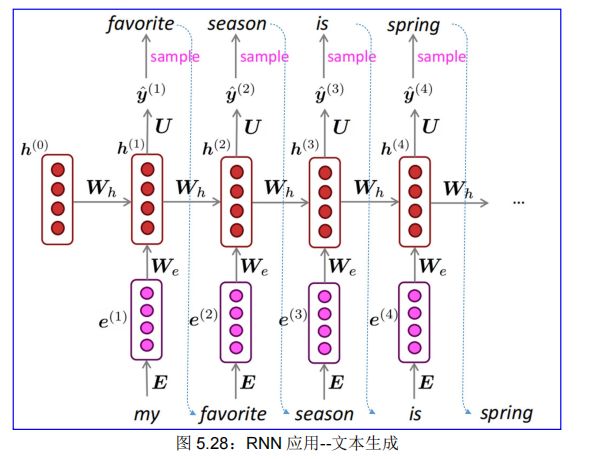
就像 n-gram 语言模型一样,您可以使用 RNN 语言模型通过重复采样来生成文本,当前采样得到的信息(单词)可以输出到下一步,成为下一步的输入信息(单词),如图 5.28 中的虚线箭头所示:
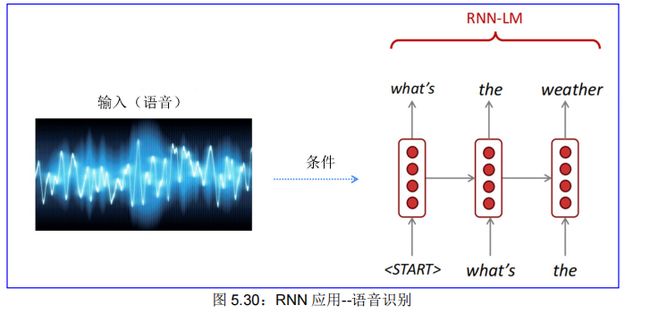
再如,RNN-LM 可以生成语音识别、机器翻译、摘要等文本,图 5.30 是 RNN 语语音识别的示意图。稍后(第七章)我们将更详细地介绍 RNN-LM 应用于机器翻译。
5.5.7. 回顾和展望
回顾:
(1)RNN 的知识要点:
• 语言模型:预测下一个单词的系统
• 循环神经网络:一系列神经网络:
• 获取任意长度的顺序输入
• 在每个步骤上应用相同的权重(Wh、We)
• 可以选择在每一步产生输出
• 循环神经网络≠语言模型
• 我们已经证明 RNN 是构建 LM 的好方法
• 但 RNN 的用途远不止于此!
(2)本讲座中描述的 RNN = simple/vanilla/Elman RNN。
展望:
下一讲,您将了解其他 RNN 风格,像 GRU 和 LSTM 以及多层 RNN。
到本课程结束时,您将理解诸如“具有残差连接和自注意力的堆叠双向 LSTM”之类的短语。